OpenCL::Example with Image Blurring Algorithm ,Questions and Issues - page 3
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
2D mapping of work groups and work items . What it does :
it creates a fake work space of x by y dimensions .
It then logs all the coordinates that arrive in the kernel , the global ids the local ids and the work group ids.
The result is sent to a file after the kernel completes .
From a first glance it appears that the first dimension , x , determines the number of the work items in the work groups and , the second , the number of the works groups .
Now there is a maximum number of work items per work group (1024) in my gpu (don't read the mql5 docs on this they are wrong) and a 256 available work groups for the kernel (if that documentation is correct)
So , i can now test if the docs are correct by creating a -very annoying- 3D test and if it fails above 256 available groups then the docs are right on this one .
here is a snapshot of the output
it appears local id y and group id x are not used
So the output is telling us that the "slot" at position 511 was processed in group 31 by work item 15
Edit : if i supply the additional local_size_array in CLExecute and set it to 4,4 this happens :
Now we can investigate what on earth that does.
neat
Edit2 the CL_KERNEL_WORK_GROUP_SIZE matches the number of items openCL divides the full work load by . For instance , i get that value to be 256 (for the 1D kernel) .
The docs say ,lets skip the what but look at the that are , "that are available for the kernel" .
So to simplify the observation , on the 1D test , i throw 512 items it splits in 2 groups , 1024 items it splits in 4 groups ,2560 it splits in 10 groups and so on.
Now if i start increasing the items per that value and run the kernel each time i will be able to get the concurrency # , meaning how many groups run at the same time in parallel and that would be a very useful indication.How would we get the # of concurrent groups ? By measuring the execution time . Concurrent groups wont deviate that much in execution .Essentially it will tell us how to split the work load .
https://web.engr.oregonstate.edu/~mjb/cs575/Handouts/gpu101.1pp.pdf
SM/Multiprocessor = Compute Unit
Thread = Work Item
Cuda Core = Processing Element
Warp = ?
how to get info on your nVidia gear like this :
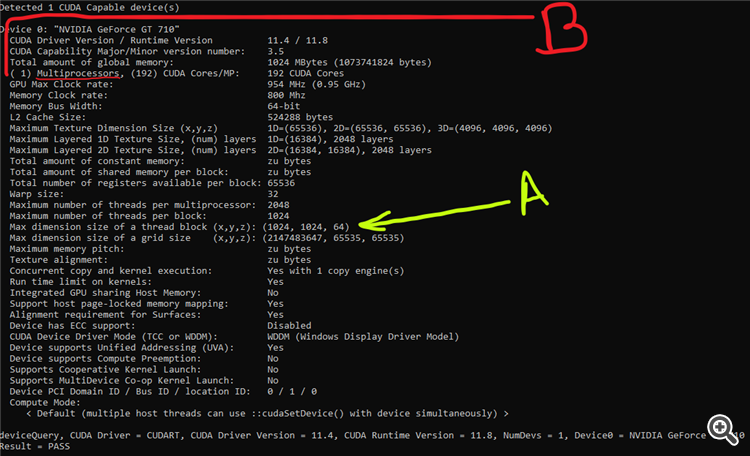
(B is the compute units , A matches the result of the querry CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS per dimension with https://www.mql5.com/en/docs/opencl/clgetdeviceinfo)Hi
consider these 2 kernels
Kernel A
Kernel B
Why is Kernel A not registering its private mem size but kernel B is reporting 40bytes ? If you know , thanks
They are both for testing there is no goal in the calculations . (i expect there may be errors)
Im attaching the source code of this small test , it does not execute anything on the device.
Also , when i change kernelB from double types to float it reports 32 bytes
alternate kernel B :
report with that :
OpenCL local memory , work groups , atomic and barrier
Code and Expalnation
Note : i'm allocating 8 bytes of local memory but the kernel reports 12 bytes , i still don't know why that is .