Market model: constant throughput - page 10
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
1. if we take the original idea as an axiom, then we need a perfect archiver to begin with, and we are as far away from that as the moon http://unseal.narod.ru/molekula_dnk.html,
Yes, the amount of information contained in the data is very difficult to even estimate. The existing compression algorithms (with and without loss) are far from perfect.
2. To check the idea, I think we should make a market model similar to tick-flow modeling in the tester, but for a decent time interval, build minute bars on the basis of this flow, compress it and compare the results with the real ones. At some point there may be a break in the purity of the experiment.
This has been done above. As a result it can be seen that the CvR is not a SB at all.
Markowitz and not only him in his reasoning for building an optimal portfolio keeps referring to the statement that price is random.
The main thing I am interested in here is the minimum number of pairs needed to analyse the market? If hrenfx can find these pairs, I will be very grateful to him. Referring to this topic https://www.mql5.com/ru/forum/114579 I want to say that this question is repeatedly raised, whether using majors is enough, or the maximum number of instruments in a cluster is required.
There is a method which easily finds majors among any set of BPs. It does not need names of BPs. It all comes from analysis of BPs themselves.
The method shows that in FOREX all information is contained in the majors. The majors are not uniquely defined, i.e. there are several sets of majors containing the same amount of information. For example:
Yes, the amount of information contained in the data is very difficult to even estimate. Existing compression algorithms (with and without loss) are far from perfect.
Compression algorithms are not algorithms for handling information, they are algorithms for optimal coding. The concept of information from coding theory is quite different from the conventional concept of information. With compression algorithms, you don't evaluate the amount of information, you only evaluate the optimality of the coding, i.e. how well this data corresponds to this coding method in this time interval. The (pseudo-)random data generated by you with a normal distribution correspond better to the chosen coding method (base - LZ) and correspondingly coded with a smaller resulting code volume, the information here is not even close to a hundred and fifty kilometres. And your corresponding conclusions comparing BP and SB are fundamentally wrong.
Several people have already written to you about it in other words. Even Mishek told you the same.
In the end it's a load of crap.
If you want to evaluate the amount of information, you have to do it. Evaluate the information. And not to compress quotations.
Compression algorithms are not algorithms for handling information, they are algorithms for optimal coding. The notion of information from coding theory is quite different from the conventional notion of information. With compression algorithms, you are not evaluating the amount of information, you are only evaluating the optimality of the coding, i.e. how well the data correspond to this coding method at this point in time. Random data generated by you with normal distribution correspond better to selected coding method (base - LZ) and correspondingly coded with less resulting code volume, information here is not even close to a hundred and fifty kilometres. And your corresponding conclusions comparing BP and SB are fundamentally wrong.
Several people have already written to you about it in other words. Even Mishek told you the same.
In the end it's a load of crap.
If you want to evaluate the amount of information, you have to do it. Evaluate the information. And not to compress quotations.
Yes, the amount of information contained in the data is very difficult to even estimate. Existing compression algorithms (with and without loss) are far from perfect.
What, by the way, about factor analysis?
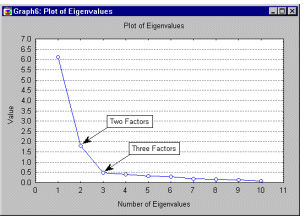
Do you remember this scheme?
.
.
It shows the degree of influence of the factors on the sample data.
I.e. according to the diagram: if the 1st, 2nd and 3rd factors together "weigh" 8.5 units,
then all the others weigh a lot less.
.
I may have seen another chart somewhere where
with a percentage scale on the left. That diagram showed
how much the N point on the factor curve cumulatively with the previous ones
explains the fluctuations.
.
And the humble question of what to do with it afterwards...
And the humble question of what to do with it afterwards...
They didn't know what to do with electricity either, however...
And the humble question of what to do with it afterwards...
No one will appreciate the creativity. Not only that, but there will be questions like: "What's the point of all this, what's the relevance of solving the "About a Salesman" problem directly to FX?"
Quietly cut your dough, why do you need this educational activity? - The question is rhetorical.
Creative is not creative. Of course, if you want and a little imagination, you can apply anything to anything, because the world is a closed and interconnected system.
The whole question is how to screen out low-constructive creativity, but simply pseudoscientific flooding? It is very simple. To do this in most cases, enough to try to answer a simple question - how does the solution to this problem directly to FX.
Well, if there is no reasonable answer, but instead there are accusations of brutalization of near-scientific creativity, then another natural question arises - who needs such outreach activities and for what purpose? :)
people!!! are we all here for the love of art, or does anyone want to argue with that?