Machine learning in trading: theory, models, practice and algo-trading - page 951
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
I'll add a few more predictors and move on to ensembles.... and then the tambourines and dancing will begin.
it's better not to start )) it sucks
when there's no strategy in your head and no fundamental confirmation that it can even work, it's all just kurvafitting
cull predictors, don't cull, cull models, don't cull... it could take forever
Being fully aware of this phenomenon, I just made a curvafitter and a regularizer. It eats everything on the input, spits out random stuff on the feedback, but after regularization it works for some time.
It's better not to start )) it sucks so badly
when there's no strategy in your head and no fundamental confirmation that it can work at all, it's all curvafitting
Pick the predictors, don't pick them, pick models, don't per...
If the Expert Advisor works well with this data, there are some regularities that are described in it, and it doesn't matter if it is a fitting or not, so let's at least use the MO model on them!
Here's no need, if the advisor works well on this data, then there are patterns that are described in it, and it doesn't matter if it's a fit or not, so let the MO model come out on it, at least!
Awareness is a complicated thing that comes through suffering
Awareness is a complex thing that comes through suffering
Awareness that MO can't replicate the clear logic of the algorithm?
The realization that MO cannot replicate the clear logic of the algorithm?
That makes no sense at all.
and it doesn't make any sense at all.
Then yes, I'm disappointed.
For the last file I had this with the tree :
2016, training
2015, test:
when predicting "-1": -1 will actually occur slightly more often than 1. But 0 will be the most frequent, and it will probably all end in losses. Similarly for the "1" class.
Trouble came out with the tree. Genetics chose the tree parameter cp = 0, and this gives the tree permission for a bunch of branches. That's not good, we should have restricted this parameter to some small non-zero value.
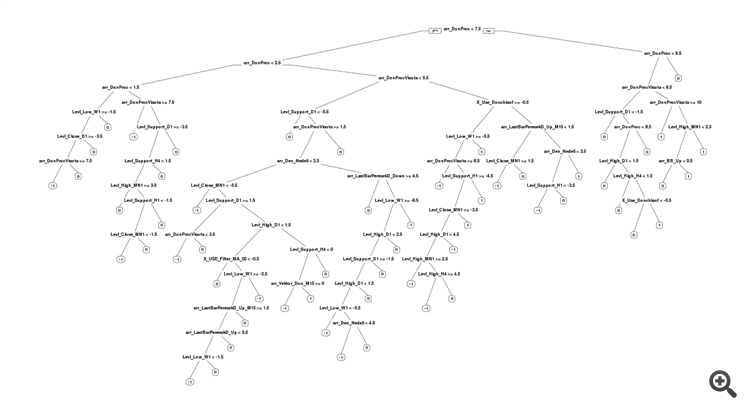
I think there are not enough predictors in the data to classify "0". We need some indicators of flat, for example.
In general it is bad with the tree. SanSanych's timber is much cooler.
What is this retraining, wrong settings or a drastically different market?
Bad model settings, and retraining as a consequence.
SanSanych's timber is much cooler.
What coolness is there - retraining and nothing else, he does not have a single predictor that would relate to his target variable - all noise. And he sits in rattle, and instead of checking for noise, he puts garbage files here.