Machine learning in trading: theory, models, practice and algo-trading - page 3008
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
You'll be too old to wait.
you'll be too old to wait.
I don't hold out much hope, just peeking in every now and then. After all gpt I predict stagnation and stagnation in this topic. No breakthroughs are visible. Purely a hype flash, like with crypto.
I have the opposite view.
I generally believe that a strong AI has long been created (just not for us), and the entire cryptoindustry (the whole world) has been working on its training, without knowing it.
I have the opposite view.
I generally believe that a strong AI has long been created (just not for us), and the entire cryptoindustry (the whole world) has been working on its training, without knowing it.
Not wise, I don't need help. The forum is even more of a distraction than it is a clue. Just stating my experience in general terms. Sometimes I sell it :) whoever hears it will save time by inheriting it.
Overshooting signs is a flawed tactic very ineffective, this is already as an axiom for me. I'd like to say IMHO, but it's more like an axiom.
And I need help - I think up more and faster than I can check it in the code.
You don't need to search for features - you need to select them and set them up correctly.
And I need help - coming up with more and faster than I can test it in code.
You don't need an overabundance of features - you need to select them and set them up correctly.
Then the logical question is: on what technology. If it's on Transformers, it's not AI at all and never will be.
Who's to say?
But technogolia must be so bad if you need the computing power of the whole world, from mobile phones to a crypto farm connected to a power plant...
But there's no better technology at this point.
It sounds simple and trivial to me.
1. I myself have worked and work: there is a teacher and to it it is necessary to pick up/process the signs.
2. As mytarmailS states, you can set the opposite task: there are signs and to match/create a teacher to them. There is something about this that I don't like. I don't try to go this way.
In reality, both ways are the same: the classification error on the available teacher-trait pair should not exceed 20% out-of-sample. But most importantly, there should be theoretical proof that the predictive power of the available features does not change, or weakly changes in the future. In all steamrolling, this is the most important thing.
I will note that my reasoning does not include model selection. It is my belief that the model plays an extremely minor role, as it has nothing to do with the stability of the predictive ability of the features: the stability of the predictive ability is a property of the teacher-trait pair.
1. Does anyone else have a teacher-trait pair with less than 20% classification error?
2. Does anyone else have actual evidence of variability in predictive ability for the used features less than 20%?
Does anyone? Then there is something to discuss
No? Everything else is blah, blah, blah.
Seems simple and trivial to me.
1. I myself have worked and work: there is a teacher and it is necessary to pick up/process the signs.
2. As mytarmailS states, it is possible to set the opposite task: there are attributes and to match/create a teacher to them. There is something about this that I don't like. Not trying to go that way.
In reality, both ways are the same: the classification error on the available teacher-trait pair should not exceed 20% out-of-sample. But most importantly, there should be theoretical proof that the predictive power of the available features does not change, or weakly changes in the future. In all steamrolling, this is the most important.
I will note that my reasoning does not include model selection. It is my belief that the model plays an extremely minor role, since it has nothing to do with the stability of the predictive ability of the traits: the stability of the predictive ability is a property of the teacher-trait pair.
1. Does anyone else have a teacher-trait pair with less than 20% classification error?
2. Does anyone have actual evidence of variability in predictive ability for the used features less than 20%?
Does anyone? Then there is something to discuss
No? Everything else is blah blah blah blah.
But most importantly, there must be a theoretical proof that the predictive power of the available features does not change, or changes weakly in the future. In the whole steamroller, this is the most important thing.
Unfortunately no one has found this, otherwise he would not be here but on tropical islands))))
Yes. Even 1 tree or regression can find a pattern if it is there and doesn't change.
1. Does anyone else have a teacher-trait pair with less than 20% classification error?
Easy. I can ungenerate dozens of datasets. I'm just now investigating TP=50 and SL=500. There's an average of 10% error in the teacher's markup. If it is 20%, it will be a plum model.
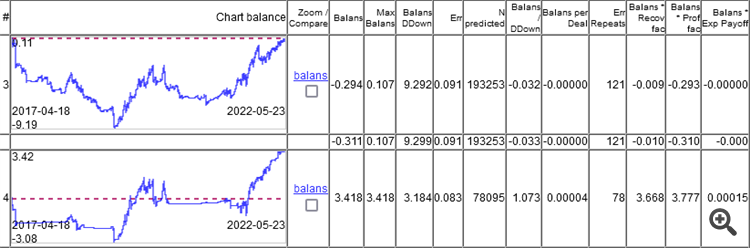
So the point is not in the classification error, but in the result of adding up all the profits and losses.
As you can see, the top model has an error of 9.1%, and you can earn something with an error of 8.3%.
The charts show only OOS, obtained by Walking Forward with retraining once a week, a total of 264 retraining over 5 years.
It is interesting that the model worked at 0 with a classification error of 9.1%, and 50/500 = 0.1, i.e. 10% should be. It turns out that 1% ate the spread (minimum per bar, the real one will be bigger).