Discussion of article "Neural networks made easy (Part 13): Batch Normalization"
On another project I did a comparison of fast error calculation and classical one in a loop for 20-50 lines: (I assume that you also have the same accumulated errors at 50 thousand lines, at millions of lines even more)
.
I first compared by eye on 50 rows of data. There are no errors on them.
But errors are considered as accumulative sum. At each calculation we can have 1e-14 ... 1e-17 errors. Adding these errors many times, - the total error can exceed 1e-5.
I did a deeper comparison. Took 50,000 lines and then compared the errors, if the difference is large, I display them on the screen. What I got (see below).
There are individual accumulated errors above 1e-4 (i.e. differences in the 4th decimal place).
So speed is certainly good, but if the strings will be not 50 thousand, but 500 million? I'm afraid that the results will be absolutely incomparable with the exact calculation in the loop.
fast_error= 9.583545e+02 true_error= 9.582576e+02
fast_error= 9.204969e+02 true_error= 9.204000e+02
fast_error= 8.814563e+02 true_error= 8.813594e+02
fast_error= 8.411763e+02 true_error= 8.410794e+02
fast_error= 7.995969e+02 true_error= 7.995000e+02
fast_error= 7.566543e+02 true_error= 7.565574e+02
fast_error= 7.246969e+02 true_error= 7.246000e+02
fast_error= 6.916562e+02 true_error= 6.915593e+02
fast_error= 6.574762e+02 true_error= 6.573793e+02
fast_error= 6.220969e+02 true_error= 6.220000e+02
fast_error= 5.854540e+02 true_error= 5.853571e+02
fast_error= 5.588969e+02 true_error= 5.588000e+02
fast_error= 5.313562e+02 true_error= 5.312593e+02
fast_error= 5.027762e+02 true_error= 5.026792e+02
fast_error= 4.730969e+02 true_error= 4.730000e+02
fast_error= 4.422538e+02 true_error= 4.421569e+02
fast_error= 4.205969e+02 true_error= 4.205000e+02
fast_error= 3.980561e+02 true_error= 3.979592e+02
fast_error= 3.745761e+02 true_error= 3.744792e+02
fast_error= 3.500969e+02 true_error= 3.500000e+02
fast_error= 3.245534e+02 true_error= 3.244565e+02
fast_error= 3.072969e+02 true_error= 3.072000e+02
fast_error= 2.892560e+02 true_error= 2.891591e+02
fast_error= 2.703760e+02 true_error= 2.702791e+02
fast_error= 2.505969e+02 true_error= 2.505000e+02
fast_error= 2.298530e+02 true_error= 2.297561e+02
fast_error= 2.164969e+02 true_error= 2.164000e+02
fast_error= 2.024559e+02 true_error= 2.023590e+02
fast_error= 1.876759e+02 true_error= 1.875789e+02
fast_error= 1.720969e+02 true_error= 1.720000e+02
fast_error= 1.556525e+02 true_error= 1.555556e+02
fast_error= 1.456969e+02 true_error= 1.456000e+02
fast_error= 1.351557e+02 true_error= 1.350588e+02
fast_error= 1.239757e+02 true_error= 1.238788e+02
fast_error= 1.120969e+02 true_error= 1.120000e+02
fast_error= 9.945174e+01 true_error= 9.935484e+01
fast_error= 9.239691e+01 true_error= 9.230000e+01
fast_error= 8.485553e+01 true_error= 8.475862e+01
fast_error= 7.677548e+01 true_error= 7.667857e+01
fast_error= 6.809691e+01 true_error= 6.800000e+01
fast_error= 5.875075e+01 true_error= 5.865385e+01
fast_error= 5.409691e+01 true_error= 5.400000e+01
fast_error= 4.905524e+01 true_error= 4.895833e+01
fast_error= 4.357517e+01 true_error= 4.347826e+01
fast_error= 3.759691e+01 true_error= 3.750000e+01
fast_error= 3.104929e+01 true_error= 3.095238e+01
fast_error= 2.829691e+01 true_error= 2.820000e+01
fast_error= 2.525480e+01 true_error= 2.515789e+01
fast_error= 2.187468e+01 true_error= 2.17777878e+01
fast_error= 1.809691e+01 true_error= 1.800000e+01
fast_error= 1.384691e+01 true_error= 1.375000e+01
fast_error= 1.249691e+01 true_error= 1.240000e+01
fast_error= 1.095405e+01 true_error= 1.085714e+01
fast_error= 9.173829e+00 true_error= 9.076923e+00
fast_error= 7.096906e+00 true_error= 7.000000e+00
fast_error= 4.642360e+00 true_error= 4.545455e+00
fast_error= 4.196906e+00 true_error= 4.100000e+00
fast_error= 3.652461e+00 true_error= 3.555556e+00
fast_error= 2.971906e+00 true_error= 2.875000e+00
fast_error= 2.096906e+00 true_error= 2.0000000000e+00
fast_error= 9.302390e-01 true_error= 8.33333333e-01
fast_error= 8.96909057e-01 true_error= 8.000000e-01
fast_error= 8.469057e-01 true_error= 7.500000e-01
fast_error= 7.635724e-01 true_error= 6.66666667e-01
fast_error= 5.969057e-01 true_error= 5.000000e-01
fast_error= 4.546077e+00 true_error= 4.545455e+00
fast_error= 4.100623e+00 true_error= 4.100000e+00
fast_error= 3.556178e+00 true_error= 3.555556e+00
fast_error= 2.875623e+00 true_error= 2.875000e+00
fast_error= 2.000623e+00 true_error= 2.000000e+00
fast_error= 8.339561e-01 true_error= 8.333333e-01
fast_error= 8.006228e-01 true_error= 8.000000e-01
fast_error= 7.506228e-01 true_error= 7.500000e-01
fast_error= 6.672894e-01 true_error= 6.66666667e-01
fast_error= 5.006228e-01 true_error= 5.000000e-01
What is the problem?
During training the terminal crashes and gives an error not always, it's like some kind of poltergeist.
N 0 22:58:20.933 Core 1 2021.02.01 00:00:00 program string is NULL or empty
MP 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OpenCL program create failed. Error code=4003
CD 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OnInit - 153 -> Error of reading EURUSD_PERIOD_H1_ 20AttentionMLMH_d.nnw prev Net 5015
RD 0 22:58:20.933 Core 1 2021.02.01 00:00:00 program string is NULL or empty
QN 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OpenCL program create failed. Error code=4003
IO 0 22:58:20.933 Core 1 final balance 10000.00 USD
LE 2 22:58:20.933 Core 1 2021.02.19 23:54:59 invalid pointer access in 'NeuroNet.mqh' (2271,16)
MS 2 22:58:20.933 Core 1 OnDeinit critical error
NG 0 22:58:20.933 Core 1 EURUSD,H1: 863757 ticks, 360 bars generated. Environment synchronised at 0:00:00.018. Test passed in 0:00:00.256.
QD 0 22:58:20.933 Core 1 EURUSD,H1: total time from login to stop testing 0:00:00.274 (including 0:00:00.018 for history data synchronisation)
LQ 0 22:58:20.933 Core 1 321 Mb memory used including 0.47 Mb of history data, 64 Mb of tick data
JF 0 22:58:20.933 Core 1 log file "C:\Users\Buruy\AppData\Roaming\MetaQuotes\Tester\36A64B8C79A6163D85E6173B54096685\Agent-127.0.0.0.1-3000\logs\20210410.log" written
PP 0 22:58:20.939 Core 1 connection closed
Thank you in advance for your help!!!
Dmitry hello! during a couple of months I observe a strong discrepancy between the OOS run and the final work on the same interval, but already an Expert Advisor. All signals are unity (I unload into a file for each bar all signals and compare) The network naturally has all the same settings. There is a suspicion that the process of saving and reading the training does not work correctly. In the NeuroNet.mph file for each network is configured an individual way of saving training
bool CNeuronProof::Save(const int file_handle)
bool CNeuronBase::Save(int file_handle)
bool CNeuronConv::Save(const int file_handle)
bool CNeuronLSTM::Save(const int file_handle)
bool CNeuronBaseOCL::Save(const int file_handle)
bool CNeuronAttentionOCL::Save(const int file_handle)
etc.
and saving is used
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true)
Can you please explain the difference, and is it possible to match the saved data with training from memory after an epoch?
Output signal data TempData and outgoing neurons ResultData at the moment of training
and separately at the moment of testing. I compared both files in the WinMerge programme.
{kind=link}
Dmitry hello! during a couple of months I observe a strong discrepancy between the OOS run and the final work on the same interval, but already an Expert Advisor. All signals are unity (I unload into a file for each bar all signals and compare) The network naturally has all the same settings. There is a suspicion that the process of saving and reading the training does not work correctly. In the NeuroNet.mph file for each network is configured an individual way of saving training
bool CNeuronProof::Save(const int file_handle)
bool CNeuronBase::Save(int file_handle)
bool CNeuronConv::Save(const int file_handle)
bool CNeuronLSTM::Save(const int file_handle)
bool CNeuronBaseOCL::Save(const int file_handle)
bool CNeuronAttentionOCL::Save(const int file_handle)
etc.
and saving is used
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true)
Can you please explain the difference, and is it possible to match the saved data with training from memory after an epoch?
Output signal data TempData and outgoing neurons ResultData at the moment of training
and separately at the moment of testing. I compared both files in the WinMerge programme.
Good day, Dmitry.
Let's look at the CNet::Save(...) method. After recording the variables characterising the training state of the network, the Save method of the array of neural layers layers (CArrayLayer inherited from CArrayObj) is called
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true) { if(MQLInfoInteger(MQL_OPTIMIZATION) || MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_FORWARD) || MQLInfoInteger(MQL_OPTIMIZATION)) return true; if(file_name==NULL) return false; //--- int handle=FileOpen(file_name,(common ? FILE_COMMON : 0)|FILE_BIN|FILE_WRITE); if(handle==INVALID_HANDLE) return false; //--- if(FileWriteDouble(handle,error)<=0 || FileWriteDouble(handle,undefine)<=0 || FileWriteDouble(handle,forecast)<=0 || FileWriteLong(handle,(long)time)<=0) { FileClose(handle); return false; } bool result=layers.Save(handle); FileFlush(handle); FileClose(handle); //--- return result; }
The CArrayLayer class has no Save method, so the method of the parent class CArrayObj::Save(const int file_handle) is called . The body of this method contains a loop to enumerate all nested objects and call the Save method for each object.
//+------------------------------------------------------------------+ //| Writing array to file| //+------------------------------------------------------------------+ bool CArrayObj::Save(const int file_handle) { int i=0; //--- check if(!CArray::Save(file_handle)) return(false); //--- write array length if(FileWriteInteger(file_handle,m_data_total,INT_VALUE)!=INT_VALUE) return(false); //--- write array for(i=0;i<m_data_total;i++) if(m_data[i].Save(file_handle)!=true) break; //--- result return(i==m_data_total); }
In other words, the principle of a nesting doll is used here: we call the Save method for the top-level object, and inside the method all nested objects are searched and the same-named method is called for each object.
Loading data from a file is organised in a similar way.
Regarding, different evaluations during training and operation. I don't know how your neural network is organised in the operation mode, but in the training mode the parameters of the neural network are constantly changing. Accordingly, the same input data will produce different results.
Regards,
Dmitry.
P.S. You can check the correctness of saving and reading data by making a small test programme, in which you can read the neural network from a file and immediately save it to a new file. And then compare the two files. If you notice any discrepancies, write me and I will check.
Good afternoon, Dmitry.
Let's look at the CNet::Save(...) method. After recording the variables characterising the training state of the network, the Save method of the array of neural layers layers (CArrayLayer inherited from CArrayObj) is called
The CArrayLayer class has no Save method, so the method of the parent class CArrayObj::Save(const int file_handle) is called . The body of this method contains a loop to enumerate all nested objects and call the Save method for each object.
In other words, the principle of a nesting doll is used here: we call the Save method for the top-level object, and inside the method all nested objects are searched and the same-named method is called for each object.
Loading data from a file is organised in a similar way.
Regarding, different evaluations during training and operation. I don't know how your neural network is organised in the operation mode, but in the training mode the parameters of the neural network are constantly changing. Accordingly, the same input data will produce different results.
Regards,
Dmitry.
P.S. You can check the correctness of saving and reading data by making a small test programme, in which you can read the neural network from a file and immediately save it to a new file. And then compare the two files. If you notice any discrepancies, write me and I will check it.
Accepted, I will try to check the following way. On the first bar I will save TempData (Signals) and OUTPUT Neurons to the file. First without loading the file but with training, then with loading training from the same first bar but without training in the process. only one bar in both cases and compare. I will write back.
p/s/ since in the process of training really learn neuronka on each bar, in the process of the tester implemented the same process, but with minus N bars.The impact should not be significant. But I agree it should be.
Dear Dmitry!
In the process of long work with the help of your library I managed to create a trading advisor with a good result of 11% drawdown to almost 100% gain for 5 years EURUSD.
Alpari:
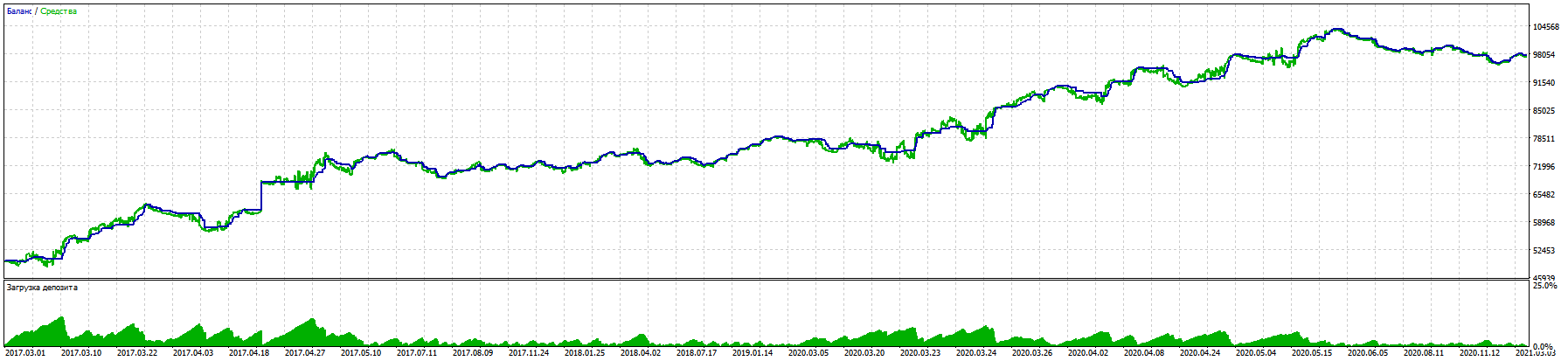
Testing on a real account follows the same logic.
It is noteworthy that even on BKS futures RURUSD gives even better results with the same inputs. (I haven't tested on other pairs yet).
The key victory was testing blind trading (training only on the past periods) and mandatory Stoploss without martingales and other tricks, except for the right to open several trades in any direction depending on the signal.
Of course, I had to study and supplement a lot from the five-week courses at WSE and Stanford Universities, and a lot of articles on neural networks, especially in understanding what to teach, what to teach, and how to teach.
Thank you so much!
Please do not stop and continue to develop the library.
What I would like to ask you to think about
1. Still on the preservation of training. It as I have already written does not work. You have to learn every time and "off the bat" without switching off trading. This is not a problem, training is fast, but there is a second problem.
2. At the start, you have set the Randomise logic to create primary neurons. This leads to up to three versions of training. (I think the key point is that the primary neuron is initially positive or negative).
Yes this can be dealt with too, so to speak, forcing retraining, from scratch, if you don't get to the right metrics.
But I'm sure you can start with a conditional 0.01 weight on each neuron. (Unfortunately overtraining becomes more pronounced).
Or still learn to keep the best copy of the education, then it's point 1.
Dear Dimitri!
In the process of long work with the help of your library I managed to create a trading advisor with a good result of 11% drawdown to almost 100% gain for 5 years EURUSD.
Alpari:
Testing on a real account follows the same logic.
It is noteworthy that even on BKS futures RURUSD gives even better results with the same inputs. (I have not tested on other pairs yet).
The key victory was testing blind trading (training only on past periods) and mandatory Stoploss without martingales and other tricks, except for the right to open several trades in any direction depending on the signal.
Of course, I had to study and supplement a lot of things from the five-week courses at WSE and Stanford Universities, and a lot of articles on neural networks, especially in understanding what to teach, what to teach, and how to teach.
Thank you so much!
Please don't stop and continue the development of the library.
What I would like to ask you to think about
1. Still on the preservation of training. As I have already written, it does not work. You have to learn every time and "off the bat" without switching off trading. This is not a problem, training is fast, but there is a second problem.
2. At the start, you have set the Randomise logic to create primary neurons. This leads to up to three versions of training. (I think the key point is that the primary neuron is initially positive or negative).
Yes, you can fight this too, so to speak, force retraining, from scratch, if you have not reached the required metrics.
But I'm sure you can start with a conditional 0.01 weight on each neuron. (Unfortunately the overtraining becomes more pronounced)
Or still learn to keep the best copy of the education, then it's point 1.
Thank you Dimitri for your kind words. Initiating all weights with a constant value is bad practice. In such a case, during learning all neurons work synchronously as one. And the whole neural network degenerates into one neuron on each layer.
....
What I would like to ask you to think about
1. Still on keeping the training. As I have already written, it does not work. You have to learn every time and "off the bat" without switching off trading. This is not a problem, training is fast, but there is a second problem.
2. At the start, you have set the Randomise logic to create primary neurons. This leads to up to three versions of training. (I think the key point is that the primary neuron is initially positive or negative).
Yes, you can fight this too, so to speak, force retraining, from scratch, if you have not reached the required metrics.
But I'm sure you can start with a conditional 0.01 weight on each neuron. (Unfortunately the overtraining becomes more pronounced)
Or still learn to keep the best copy of the education, then it's point 1.
Dimitri, I tested this as the author advised you.
1. Train several epochs, after each epoch the network file is saved.
2. Delete from the graph. Run again with the parameter testSaveLoad enabled - after reading the previously trained network, the Expert Advisor writes it again, repeats the cycle read-write again and unloads, and we get three files, in addition to the original network with the prefixes _check and _check2.
3. We compare the three files. We go a) to learn programming through testing b) to look for errors in ourselves.

Thanks Alexei, I didn't post the results here.
The problem turned out to be elsewhere.
The save/load process works.
The solution was found in the line of creating neuron network elements using Randomize.
bool CArrayCon::CreateElement(int index) { if(index<0 || index>=m_data_max) return false; //--- xor128; double weigh=(double)rnd_w/UINT_MAX-0.5; m_data[index]=new CConnection(weigh); if(!CheckPointer(m_data[index])!=POINTER_INVALID) return false; //--- return (true); }
I replaced it with a more stable function of creating neurons, and it is important to create an equal number of positive and negative neurons, so that the network would not be predisposed towards sales or purchases.
double weigh=(double)MathMod(index,0)?sin(index):sin(-index);
I did the same with the function of creating initial weights just in case.
double CNeuronBaseOCL::GenerateWeight(void) { xor128; double result=(double)rnd_w/UINT_MAX-0.5; //--- return result; } //+----
Now the backtest gives the same result when testing the trained network after loading the training file.
The inputs are unity per second.
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
New article Neural networks made easy (Part 13): Batch Normalization has been published:
In the previous article, we started considering methods aimed at improving neural network training quality. In this article, we will continue this topic and will consider another approach — batch data normalization.
Various approaches to data normalization are used in neural network application practice. However, all of them are aimed at keeping the training sample data and the output of the hidden layers of the neural network within a certain range and with certain statistical characteristics of the sample, such as variance and median. This is important, because network neurons use linear transformations which in the process of training shift the sample towards the antigradient.
Consider a fully connected perceptron with two hidden layers. During a feed-forward pass, each layer generates a certain data set that serves as a training sample for the next layer. The result of the output layer is compared with the reference data. Then, during the feed-backward pass, the error gradient is propagated from the output layer through hidden layers towards the initial data. Having received an error gradient at each neuron, we update the weight coefficients, adjusting the neural network for the training samples of the last feed-forward pass. A conflict arises here: the second hidden layer (H2 in the figure below) is adjusted to the data sample at the output of the first hidden layer (H1 in the figure), while by changing the parameters of the first hidden layer we have already changed the data array. In other words, we adjust the second hidden layer to the data sample which no longer exists. A similar situation occurs with the output layer, which adjusts to the second hidden layer output which has already changed. The error scale will be even greater if we consider the distortion between the first and the second hidden layers. The deeper the neural network, the stronger the effect. This phenomenon is referred to as internal covariate shift.
Classical neural networks partly solve this problem by reducing the learning rate. Minor changes in weights do not entail significant changes in the sample distribution at the output of the neural layer. But this approach does not solve the scaling problem which appears with an increase in the number of neural network layers, and it also reduces the learning speed. Another problem of a small learning rate is that the process can get stuck on local minima, which we have already discussed in article 6.
Author: Dmitriy Gizlyk