Discussion of article "Applying Monte Carlo method in reinforcement learning"
New article Applying Monte Carlo method in reinforcement learning has been published:
Author: Maxim Dmitrievsky
Thank you. Is it possible to make the training using the GPU instead of CPU?
Thank you Maxim.
I have been playing with the code and introduced different types of data for the feature input vectors. I have tried Close, Open, High, Low, Price Typical, Tick Volumes and derivatives of these.
I was having problems with the Optimiser complaining about "some error after the pass completed", but I finally managed to track this down: the optimiser errors occur if the input vector data has any zero values.
Where I was building a derivative, e.g. Close[1]-Close[2], sometimes the close values are the same giving a derivative of zero. For these types of input vector values I found the simplest fix was to add a constant, say 1000, to all vector values. This cured the optimiser errors and yet allowed the RDF to function.
I have also noticed the unintended consequence of running the same tests over and over, the amount of curve fitting increases for the period tested. Sometimes it is better to delete the recorded RDF files and run the optimisation again.
I am still experimenting and have more ideas for other types of feature.
Thank you Maxim.
I have been playing with the code and introduced different types of data for the feature input vectors. I have tried Close, Open, High, Low, Price Typical, Tick Volumes and derivatives of these.
I was having problems with the Optimiser complaining about "some error after the pass completed", but I finally managed to track this down: the optimiser errors occur if the input vector data has any zero values.
Where I was building a derivative, e.g. Close[1]-Close[2], sometimes the close values are the same giving a derivative of zero. For these types of input vector values I found the simplest fix was to add a constant, say 1000, to all vector values. This cured the optimiser errors and yet allowed the RDF to function.
I have also noticed the unintended consequence of running the same tests over and over, the amount of curve fitting increases for the period tested. Sometimes it is better to delete the recorded RDF files and run the optimisation again.
I am still experimenting and have more ideas for other types of feature.
Hi, Mark. Depends of feature selection algorithm (in case of this article it's 1 feature/another feature (using price returns) in "recursive elimination func"), so if you have "0" in divider this "some error" can occur if you are using cl[1]-cl[2].
Yes, different optimizer runs can differ, because its used a random sampling, also RDF random algorithm. To fix this you can use MathSrand(number_of_passes) in expert OnInint() func, or another fixed number.
Yes, if you rewrite all logic (RF include) on open cl kernels :) also random forest has worst gpu feasibility and parallelism
Hey maxim, i was just looking at your code. i noticed that even though the files with best model , features and parameter values are saved during optimization (" OFFLINE") . The Update agent policy and Update agent reward are also " OFFLINE " if you decide to run your EA , so how are the rewards and policy being updated while the EA is running live since MQLInfoInteger(MQL_OPTIMIZATION) == true in offline mode and when running on a demo or live account with your EA MQLInfoInteger(MQL_OPTIMIZATION) == false . Am missing something ????
//+------------------------------------------------------------------+ //|Update agent policy | //+------------------------------------------------------------------+ CRLAgent::updatePolicy(double action,double &featuresValues[]) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { numberOfsamples++; RDFpolicyMatrix.Resize(numberOfsamples,features+2); //input variables for(int i=0;i<features;i++) RDFpolicyMatrix[numberOfsamples-1].Set(i,featuresValues[i]); //output variables RDFpolicyMatrix[numberOfsamples-1].Set(features,action); RDFpolicyMatrix[numberOfsamples-1].Set(features+1,1-action); } } //+------------------------------------------------------------------+ //|Update agent reward | //+------------------------------------------------------------------+ CRLAgent::updateReward(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(getLastProfit()>0) return; double randomReward = (getLastOrderType()==0) ? 1 : 0; RDFpolicyMatrix[numberOfsamples-1].Set(features,randomReward); RDFpolicyMatrix[numberOfsamples-1].Set(features+1,1-randomReward); } }
Hey maxim, i was just looking at your code. i noticed that even though the files with best model , features and parameter values are saved during optimization (" OFFLINE") . The Update agent policy and Update agent reward are also " OFFLINE " if you decide to run your EA , so how are the rewards and policy being updated while the EA is running live since MQLInfoInteger(MQL_OPTIMIZATION) == true in offline mode and when running on a demo or live account with your EA MQLInfoInteger(MQL_OPTIMIZATION) == false . Am missing something ????
Hi, policy and rewards are not updated in real trading, it is only needed for learning random forest in the optimizer.
New article Applying Monte Carlo method in reinforcement learning has been published:
Author: Maxim Dmitrievsky
there is this file which is missing, " #include <MT4Orders.mqh> " and the fonctions look like MT4 fonction.
So is it an MT4 expert or an MT5 expert?
there is this file which is missing, " #include <MT4Orders.mqh> " and the fonctions look like MT4 fonction.
So is it an MT4 expert or an MT5 expert?
This library allows you to use mt4 orders style in mt5

- www.mql5.com
ok thank you
Hi Maxim, thank u for your work, i was trying to test your code, however it shows me some errors in the mq4 file with the following text
'getRDFstructure' - function already defined and has different type RL_Monte_Carlo.mqh 76 11
'RecursiveElimination' - function already defined and has different type RL_Monte_Carlo.mqh 133 11
'updatePolicy' - function already defined and has different type RL_Monte_Carlo.mqh 221 11
'updateReward' - function already defined and has different type RL_Monte_Carlo.mqh 236 11
'setAgentSettings' - function already defined and has different type RL_Monte_Carlo.mqh 361 12
'updatePolicies' - function already defined and has different type RL_Monte_Carlo.mqh 373 12
'updateRewards' - function already defined and has different type RL_Monte_Carlo.mqh 380 12
Do you know how to solve that issue?
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
New article Applying Monte Carlo method in reinforcement learning has been published:
In the article, we will apply Reinforcement learning to develop self-learning Expert Advisors. In the previous article, we considered the Random Decision Forest algorithm and wrote a simple self-learning EA based on Reinforcement learning. The main advantages of such an approach (trading algorithm development simplicity and high "training" speed) were outlined. Reinforcement learning (RL) is easily incorporated into any trading EA and speeds up its optimization.
After stopping the optimization, simply enable the single test mode (since the best model is written to the file and only that model is to be uploaded):
Let's scroll the history for two months back and see how the model works for the full four months:
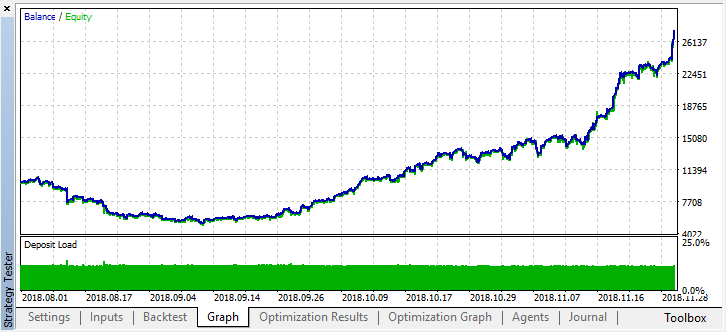
We can see that the resulting model lasted another month (almost the entire September), while breaking down in August.Author: Maxim Dmitrievsky