Ökonometrie: Bibliographie
Zum Thema "Grundlagen der Regressionsanalyse" sind die folgenden Referenzen verfügbar.
Davidson,Russell und James G. MacKinnon (1993). Estimation and Inference inEconometrics, Oxford: Oxford University Press.
Greene, William H. (2008). Econometric Analysis, 6. Auflage, Upper Saddle River, NJ: Prentice-Hall.
Johnston, Jack und John Enrico DiNardo (1997). Ökonometrische Methoden, 4. Auflage, New York: McGraw-Hill.
Pindyck, Robert S. und Daniel L. Rubinfeld (1998). Econometric Models and Economic Forecasts, 4. Auflage, New York: McGraw-Hill.
Wooldridge, Jeffrey M. (2000). Einführung in die Ökonometrie: Ein moderner Ansatz. Cincinnati, OH: South-Western College Publishing.
Ich möchte Ihnen ein Beispiel für eine Regression geben, die nichts anderes als eine Funktion (abhängige Variable) ist, die von ihren Argumenten (unabhängige Variablen, Regressoren) abhängt. Bei der Berechnung einer Regression sind mehrere Schritte zu beachten:
1. Es muss eine Gleichung aufgeschrieben werden.
Ich nehme den heiß begehrten MA, aber gewichtet, also für mich verzeihend, und berechne ihn anhand der letzten 5 Balken (Lag-Werte). Ich schreibe die Formel in der Form:
EURUSD = C(1)*EURUSD(-1) + C(2)*EURUSD(-2) + C(3)*EURUSD(-3) + C(4)*EURUSD(-4) + C(5)*EURUSD(-5)
2. Schätzung
Es ist notwendig, den Koeffizienten c(i) dieser Gleichung so zu schätzen, dass die Kurve unserer MA der ursprünglichen EURUSD_H1-Jahresreihe so gut wie möglich entspricht. Wir erhalten das Ergebnis der Auswertung der unbekannten Koeffizienten.
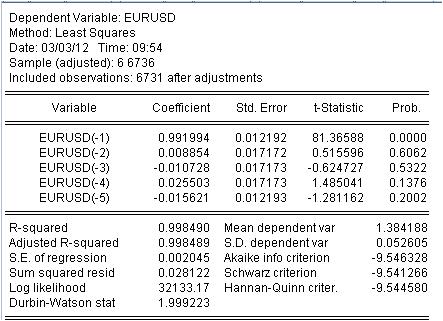
Wir haben die Werte unserer gewichteten MA erhalten. Wir haben die Gleichung:
EURUSD = 0,991993934254*EURUSD(-1) + 0,00885362355538*EURUSD(-2) - 0,0107282369642*EURUSD(-3) + 0,0255027160774*EURUSD(-4) - 0,0156205779585*EURUSD(-5)
3. Ergebnisse.
Welche Ergebnisse sehen wir?
3.1 Zunächst einmal die Mach-Gleichung selbst. Ich möchte auf eine kleine Nuance hinweisen. Bei der Berechnung einer einfachen Maske, die den Durchschnitt berechnet, wird dieser aus irgendeinem Grund nicht in der Mitte des Intervalls, sondern an dessen Ende erfasst. Die Regression wird verwendet, um den neuesten Wert auf der Grundlage der vorherigen Werte zu berechnen.
3.2 Es zeigt sich, dass Verhältnisse keine Konstanten sind, sondern Zufallsvariablen mit eigener Abweichung.
3.3 Die letzte Spalte besagt, dass es eine von Null verschiedene Wahrscheinlichkeit gibt, dass die angegebenen Koeffizienten überhaupt Null sind.
4. Arbeiten mit der Gleichung
Werfen wir einen Blick auf unsere gewichtete Mischung.

Die Mashka hat das Kotier so dicht bedeckt, dass es nicht zu sehen ist, aber es gibt immer noch Diskrepanzen zwischen dem Kotier und der Mashka. Hier sind die statistischen Angaben zu diesen Diskrepanzen

Wir sehen eine große Streuung von -137 Punkten bis 215 Punkten. Obwohl Standardabweichung = 20 Punkte.
Schlussfolgerung.
Wir haben eine ungewöhnlich hohe Qualität der Maske mit den bekannten statistischen Merkmalen durch Regression erhalten.
Die letzte. Yusuf! Gehen Sie nicht unter die Straßenbahn, bringen Sie das Publikum nicht mit einem weiteren Thema zum Lachen.
Bereit, die Literatur und die Anwendung des Regressionsthemas zu diskutieren.
3. Ergebnisse.
Welche Ergebnisse sehen wir?
3.1 Zunächst einmal die Mach-Gleichung selbst. Ich möchte hier auf eine Kleinigkeit hinweisen. Wenn wir eine einfache Maske berechnen, indem wir den Durchschnitt ermitteln, platzieren wir diesen Durchschnitt aus irgendeinem Grund nicht in der Mitte des Intervalls, sondern an dessen Ende. Die Regression wird verwendet, um den neuesten Wert auf der Grundlage der vorherigen Werte zu berechnen.
3.2 Es stellt sich heraus, dass Verhältnisse keine Konstanten, sondern Zufallsvariablen sind!
3.3 Die letzte Spalte besagt, dass die Wahrscheinlichkeit, dass die gegebenen Koeffizienten Null sind, nicht Null ist.
1. Entschuldigung für das zusätzliche Salz in der Wunde - die ursprüngliche Serie ist ohnehin nicht stationär.
2) Diese Wahrscheinlichkeit ist fast immer ungleich Null.
3. Haben Sie auf Multikollinearität geprüft? Wenn man die Multikollinearität eliminiert, bleibt IMHO nur noch eine Variable übrig. Haben Sie die wesentlichen Faktoren ermittelt?
4. Wie viele Beobachtungen haben Sie für 5 Variablen?
Wie können Sie so belesen sein?
1. Entschuldigung für das zusätzliche Salz in der Wunde - die ursprüngliche Serie ist ohnehin nicht stationär.
Natürlich sind wir an den anderen nicht interessiert.
2. diese Wahrscheinlichkeit ist fast immer ungleich Null.
Das stimmt nicht. Ist der Wert ungleich Null, handelt es sich um einen Fehler in der Funktionsform.
3. Haben Sie auf Multikollinearität geprüft? Wenn man die Multikollinearität eliminiert, bleibt IMHO nur noch eine Variable übrig. Haben Sie die wesentlichen Faktoren ermittelt?
Was "signifikante Faktoren" sind, verstehe ich nicht, aber schauen Sie sich bitte die Korrelationskoeffizienten an.
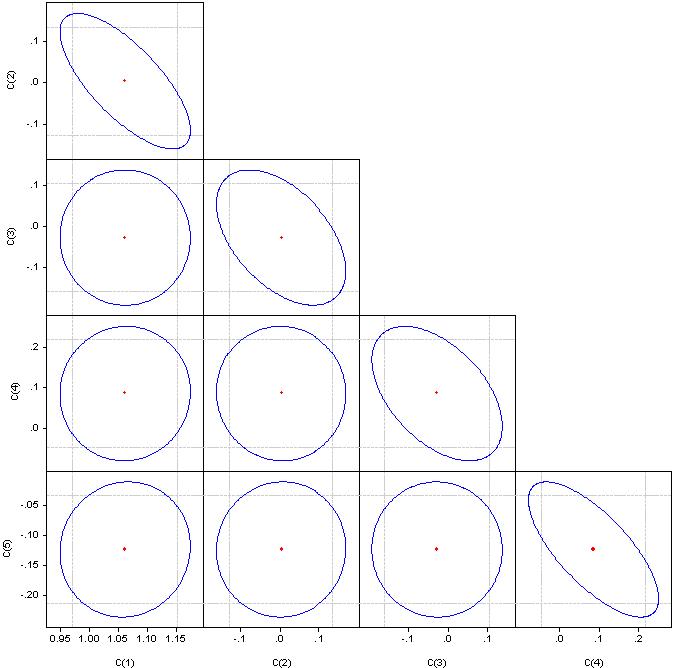
Wenn es ein Kreis ist, ist die Korrelation gleich Null. Wenn sie zu einer Geraden verschmolzen werden, beträgt die Korrelation zwischen dem entsprechenden Koeffizientenpaar 100 %.
4. Wie viele Beobachtungen haben Sie für 5 Variablen?
6736 Beobachtungen
Der erste Schritt in jedem Regressionsmodell ist die Faktorenauswahl. Wenn Sie keine schrittweise Regression (mit Einschlüssen oder Ausnahmen) anwenden, müssen Sie diese manuell auswählen.
Multikollinearität - enge Abhängigkeit zwischen den in das Modell einbezogenen Faktorvariablen. Nicht die Korrelation der Koeffizienten, sondern die Korrelation der Faktoren.
Das Vorhandensein von Multikollinearität führt zu:
- Verzerrung des Wertes von der Parameter des Modells, die tendenziell überbewerten;
- schwache Konditionierung des Systems der normalen Gleichungen;
- Komplikation von der Prozess der Bestimmung der wichtigsten Faktorenmerkmale.
Ein Indikator für Multikollinearität ist, dass die paarweisen Korrelationskoeffizienten den Wert von 0,8 überschreiten. Hier besteht eindeutig eine starke Korrelation zwischen den Faktoren. Um sie zu beseitigen, müssen wir redundante Faktoren entfernen. Entweder manuell oder durch schrittweise Regression.
Schauen Sie in das Paket - Stufenregression oder Ridge-Regression.
Und 6736/4 sind zu viele Beobachtungen. Wir müssen googeln - ich weiß nicht mehr, wie man die optimale Anzahl von Beobachtungen auf der Grundlage der Anzahl von Faktoren bestimmt.
Seien Sie so nett und beteiligen Sie sich an meinen Ökonometrie-Themen.
Fahren wir mit der Literaturauswahl fort.
Das nächste Thema sind die Almon'schen Verzögerungen.
Wie bereits erwähnt, gibt es Schwierigkeiten mit Regressionskoeffizienten, die nach der Methode der kleinsten Quadrate berechnet werden. Es wurde die Idee entwickelt, den Regressionskoeffizienten zusätzliche Beschränkungen aufzuerlegen, bei denen die abhängige Variable durch mehrere Verzögerungen der unabhängigen Variable bestimmt wird, wie in der obigen Gleichung.
Die Idee besteht darin, den Koeffizienten bei den Verzögerungswerten Beschränkungen aufzuerlegen, so dass sie einer polynomialen Verteilung gehorchen. EViews nennt diesen Ansatz "distributed lag polynomials (PDL)". Die Wahl des jeweiligen Polynomgrades wird experimentell bestimmt.
Dieser Ansatz wird hier beschrieben.
Hier ein praktisches Beispiel.
Konstruieren wir ein Analogon einer Skala mit einer Periode von 5, aber die Balkenkoeffizienten sollten auf einem Polynom 3ter Ordnung liegen.
In EViews wird sie für EURUSD wie folgt geschrieben
EURUSD PDL(EURUSD(-1), 5,3)
In einer vertrauteren Form:
EURUSD = + C(5)*EURUSD(-1) + C(6)*EURUSD(-2) + C(7)*EURUSD(-3) + C(8)*EURUSD(-4) + C(9)*EURUSD(-5) + C(10)*EURUSD(-6)
Wir schätzen die Koeffizienten mittels OLS und erhalten das Ergebnis der Koeffizientenschätzung:
EURUSD = + 0,934972661616*EURUSD(-1) + 0,139869148138*EURUSD(-2) - 0,093599954464*EURUSD(-3) - 0,0264992987207*EURUSD(-4) + 0,0801064628352*EURUSD(-5) - 0,0348473223286*EURUSD(-6)
Die Statistik zur Schätzung der Gleichung lautet wie folgt:
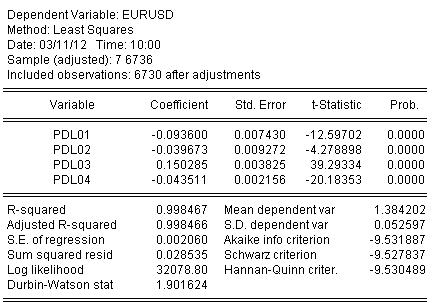
Aus den Statistiken können wir ein sehr gutes Niveau der Abbildung des ursprünglichen Quotienten durch unser Winken von Almon erkennen R-Quadrat = 0,998467
Grafisch sieht es so aus:

Die Regression (Almon's Waving) hat den ursprünglichen Quotienten vollständig abgedeckt.
Und ein letzter Löffel Honig.
Mal sehen, wie hoch der Rest ist, d.h. der Unterschied zwischen unserer Almon's Maische und dem Original-Kotier. Die Stationarität/Nicht-Stationarität dieses Residuums ist sehr wichtig.

Der Einheitswurzeltest besagt, dass das Residuum stationär ist.
Die von uns verwendeten Mash-Ups haben nicht diesen Grad an Anpassung an den ursprünglichen Quotienten und die Eigenschaft der Stationarität des Anpassungsfehlers.
Ich möchte die Links aus einem benachbarten Thread verschieben.
Diese Links beziehen sich auf den problematischsten Bereich - die Prognose.
Der erste ist ein Anhang. Er enthält eine Liste von Referenzen.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie das Wort "Ökonometrie" googeln, erhalten Sie eine riesige Liste von Literatur, die selbst für einen Experten schwer zu verstehen ist. Ein Buch sagt das eine, ein anderes das andere, das dritte ist nur eine Zusammenstellung der ersten beiden mit einigen Ungenauigkeiten. Aber der Ansatz "aus den Büchern" verbindet nicht die Klarheit der Anwendung dieser Bücher in der Praxis. Ich bin nicht daran interessiert, dass Intellektuelle in nerdigen Unsinn verfallen.
Ähnlich wie bei anderen Bücherlisten in diesem Forum, z. B. über Statistik, schlage ich vor, dass wir gemeinsam eine Liste von Lehrbüchern, Monographien, Dissertationen, Artikeln, Internetressourcen und Softwarepaketen zusammenstellen, die nach Meinung der Teilnehmer für die Messung von Wirtschaftsdaten - für die Ökonometrie - relevant sind. Wir sollten jedoch nicht vergessen, dass die mathematische Statistik die ältere Schwester der Ökonometrie ist. Ich schlage vor, alles, was mit technischer Analyse zu tun hat, nicht in diese Liste aufzunehmen .
Um ein Abgleiten in die Botanik auszuschließen, schlage ich einen besonderen Ansatz für die Liste der Bücher vor. Wir posten Links (Bücher selbst) nur, wenn ich Software kenne, die Algorithmen aus diesen Büchern umsetzt. Ich habe es auf EViews eingegrenzt. Dieses Programm hat keinen Vorteil gegenüber anderen, es hat Vor- und Nachteile, aber ich sehe es als eine Rubrik für Ökonometrie. Ich habe das Inhaltsverzeichnis des zweiten Bandes des Benutzerhandbuchs beigefügt, um auf einen Blick eine möglichst breite Palette von Problemen zu skizzieren. Aufgrund des vorgeschlagenen Ansatzes sind mehrere Bereiche, die in der Ökonometrie verwendet werden, aber nicht in EVIEWS enthalten sind, z. B. NS, Wavelets usw., ausgeschlossen. Natürlich sind auch Hinweise auf solche Programme und Bücher willkommen.
Wenn wir nicht nur einen Link zur Quelle des Algorithmus angeben, sondern auch konkrete Berechnungen anstellen können, wird dieser Thread keinen Wert haben.
Ich schlage vor, die Kapitelnummern aus dem Anhang für die Gruppierung der Bücher zu verwenden.
Also, bitte unterstützen Sie uns.