Машинное обучение в трейдинге: теория, модели, практика и алготорговля - страница 3008
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
А по мне все просто и банально.
1. Сам работал и работаю: есть учитель и к нему надо подобрать/обработать признаки.
2. Как утверждает mytarmailS можно поставить обратную задачу: есть признаки и к ним подобрать/создать учителя. Что-то в этом мне не нравится. Не пытаюсь пойти этим путем.
В реальности оба пути одинаковы: ошибка классификации по имеющейся паре "учитель-признаки" не должна превосходить 20% вне выборки. Но самое важное, должно быть теоретическое доказательство, что предсказательная способность имеющихся признаков не меняется, или слабо меняется в будущем. Во все пароходе это самое важное.
Замечу, что в моих рассуждениях отсутствует выбор модели. По моему убеждению модель играет крайне малую роль, так как она не имеет отношения к стабильности предсказательной способности признаков: стабильность предсказательной способности - это свойство пары "учитель-признаки".
1. У кого-то еще есть пара "учитель-признаки" с ошибкой классификации менее 20%?
2. У кого-то есть фактическое доказательство изменчивости предсказательной способности для использованных признаков менее 20%?
Есть? Тогда есть ЧТО обсуждать
Нет? Все остальное бла-бла-бла.
А по мне все просто и банально.
1. Сам работал и работаю: есть учитель и к нему надо подобрать/обработать признаки.
2. Как утверждает mytarmailS можно поставить обратную задачу: есть признаки и к ним подобрать/создать учителя. Что-то в этом мне не нравится. Не пытаюсь пойти этим путем.
В реальности оба пути одинаковы: ошибка классификации по имеющейся паре "учитель-признаки" не должна превосходить 20% вне выборки. Но самое важное, должно быть теоретическое доказательство, что предсказательная способность имеющихся признаков не меняется, или слабо меняется в будущем. Во все пароходе это самое важное.
Замечу, что в моих рассуждениях отсутствует выбор модели. По моему убеждению модель играет крайне малую роль, так как она не имеет отношения к стабильности предсказательной способности признаков: стабильность предсказательной способности - это свойство пары "учитель-признаки".
1. У кого-то еще есть пара "учитель-признаки" с ошибкой классификации менее 20%?
2. У кого-то есть фактическое доказательство изменчивости предсказательной способности для использованных признаков менее 20%?
Есть? Тогда есть ЧТО обсуждать
Нет? Все остальное бла-бла-бла.
Но самое важное, должно быть теоретическое доказательство, что предсказательная способность имеющихся признаков не меняется, или слабо меняется в будущем. Во все пароходе это самое важное.
К сожалению этого никто не нашел, иначе был бы не тут а на тропических островах))
Да. Даже 1 дерево или регрессия может найти закономерность, если она есть и не меняется.
1. У кого-то еще есть пара "учитель-признаки" с ошибкой классификации менее 20%?
Легко. Могу негенерить десятки датасетов. Вот как раз сейчас исследую ТП=50 и СЛ=500. Там и в разметке учителя в среднем 10% ошибки. Если будет 20% то это будет сливная модель.
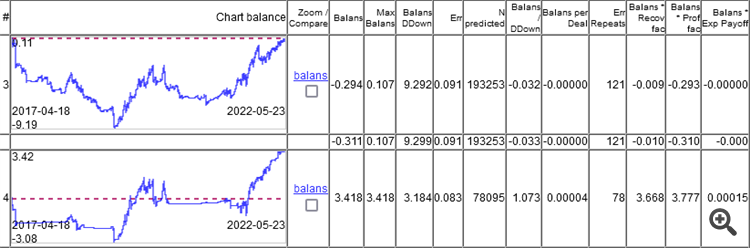
Так что не в ошибке классификации суть, а в результате сложения всех прибылей и убытков.
Как видите, у верхней модели ошибка 9,1%, а заработать что-то можно при ошибке 8,3%.
На графиках только ООС, получено валкинг-форвардом с переобучением раз в неделю, всего 264 переобучений за 5 лет.
Интересно, что модель отработала в 0 при ошибке классификации 9,1%, а 50/500 = 0,1, т.е. 10% должно быть. Получается что 1%съел спред (минимальный на бар, реальный будет больше).
Для начала надо понять что в модели полно мусора внутри..
Если разложыть обученую деревяную модель на правила внутри и статистику по этим правилам
типа :
и проанализоровать зависимость ошибки правила err от частоты freq его появления в выборке
то получим
То нам интересна вот эта область
Где правила работают очень хорошо , но попадаються на столько редко что есть смысл сомниваться в подлиности статистики по ним, ведь 10-30 наблюдений это не статистика
Для начала надо понять что в модели полно мусора внутри..
Если разложыть обученую деревяную модель на правила внутри и статистику по этим правилам
типа :
и проанализоровать зависимость ошибки правила err от частоты freq его явления в выборке
то получим
Просто лучик солнца во мгле последних постов
об этом будет статья , если будет..
об этом будет статья , если будет..
Норм, моя последняя статья про это же. Но если твой способ быстрее, это плюс.
в каком смысле быстрее?
в каком смысле быстрее?
По скорости
гдето секунд 5-15 на 5к выборке