
Python, ONNX e MetaTrader 5: Montando um modelo RandomForest com pré-processamento de dados via RobustScaler e PolynomialFeatures

Qual base utilizaremos? O que é uma floresta aleatória?
A invenção do método de floresta aleatória remonta a contribuições significativas de diversos cientistas nas áreas de aprendizado de máquina e estatística ao longo dos anos. Para entender melhor como ele funciona, imagine um grande conjunto de "pessoas" (árvores de decisão) que se juntam para resolver um problema complexo.
As raízes da floresta aleatória estão nas árvores de decisão. Essas são representações gráficas de um processo de tomada de decisões, onde cada nó simboliza um teste realizado em um atributo, cada ramificação indica o resultado desse teste e as folhas representam as previsões feitas. As árvores de decisão surgiram em meados do século XX e rapidamente se popularizaram como ferramentas de classificação e regressão.
A próxima etapa significativa foi a introdução do conceito de bagging por Leo Breiman em 1996. O bagging consiste em gerar múltiplas subamostras (bootstrap samples) a partir do conjunto de dados de treino, e cada subamostra é usada para treinar um modelo separado. Os resultados desses modelos são então combinados, seja por média ou outro método, para produzir previsões que são tanto estáveis quanto precisas. Esse método foi fundamental para diminuir a variância dos modelos e aumentar sua capacidade de generalização.
O método da floresta aleatória, por sua vez, foi desenvolvido por Leo Breiman e Adele Cutler no início dos anos 2000. Ele se baseia na estratégia de agregar várias árvores de decisão através do bagging, adicionando uma camada extra de aleatoriedade. Durante a construção de cada árvore, uma subamostra aleatória dos dados é selecionada, e um conjunto diferente de características é escolhido para cada nó, tornando cada árvore distinta e diminuindo a correlação entre elas, o que melhora a generalização do modelo.
As florestas aleatórias se popularizaram rapidamente como uma das técnicas mais eficazes no campo do aprendizado de máquina, destacando-se tanto em tarefas de classificação quanto de regressão. Na classificação, elas ajudam a determinar a que categoria um objeto pertence, enquanto na regressão, são utilizadas para prever valores numéricos.
Atualmente, a técnica de floresta aleatória é amplamente empregada em vários setores, como finanças, medicina e análise de dados, destacando-se pela sua robustez e capacidade de gerenciar tarefas complexas em aprendizado de máquina.
A floresta aleatória, também conhecida como RandomForest, constitui uma ferramenta essencial no campo do aprendizado de máquina. Para compreender seu funcionamento, podemos imaginar um grande grupo de indivíduos tomando decisões coletivas — no entanto, ao invés de pessoas, cada membro deste grupo é um classificador independente ou um avaliador da situação vigente. Nesse coletivo, os indivíduos são árvores de decisão, cada uma analisando características específicas para tomar suas decisões. A tomada de decisão na floresta aleatória segue um processo democrático de votação, onde cada árvore contribui com seu voto para formar a decisão final baseada na maioria.
Devido à sua versatilidade, a floresta aleatória é extensivamente aplicada em diversas áreas, sendo particularmente útil tanto para classificação quanto para regressão. Em tarefas de classificação, por exemplo, o modelo pode determinar a que categoria pertence uma situação específica, como no mercado financeiro, onde decide se uma ação deve ser comprada (classe 1) ou vendida (classe 0), com base em um conjunto de características.
Neste artigo, vamos explorar mais a fundo a tarefa de regressão. A regressão em aprendizado de máquina visa prever valores numéricos futuros, como preços de ações ou temperaturas, baseando-se em dados históricos. Diferente da classificação, que distribui objetos em categorias fixas, a regressão busca estimar valores numéricos específicos. Isso pode ser, por exemplo, prever os preços das ações no mercado financeiro, prever a temperatura ou qualquer outra variável numérica.
Criando o modelo básico de RF
Para construir nosso modelo inicial de floresta aleatória, utilizaremos a biblioteca Scikit-learn do Python. Aqui está um exemplo básico de código para treinar um modelo de regressão usando floresta aleatória. Antes de começar, certifique-se de instalar todas as bibliotecas necessárias, incluindo aquelas para trabalhar com o sklearn e o MetaTrader 5, utilizando o gerenciador de pacotes do Python.
pip install onnx
pip install skl2onnx
pip install MetaTrader5 Por fim, vamos nos dedicar à importação das bibliotecas e configuração dos parâmetros. Importaremos ferramentas essenciais como pandas, para manipulação de dados, e gdown, para o download de dados do Google Drive. Além disso, ajustaremos o número de etapas temporais (n_steps) na sequência de dados, de acordo com as necessidades específicas do projeto.
import pandas as pd import gdown import numpy as np import joblib import random import onnx import os import shutil from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score from sklearn.utils import shuffle from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler, MinMaxScaler, PolynomialFeatures, PowerTransformer import MetaTrader5 as mt5 from datetime import datetime # Задать количество временных шагов по требованиям n_steps = 100
A próxima etapa é carregar e processar os dados. Nesta parte do código, carregamos os dados de cotações do MetaTrader 5 e os processamos. Configuramos o índice de tempo e selecionamos apenas os preços de fechamento (é com isso que trabalharemos):
Aqui está a parte do código responsável por dividir nossos dados em conjuntos de treinamento e teste, bem como por rotular as etiquetas para treinar o modelo. Dividimos os dados em conjuntos de treinamento e teste. Em seguida, criamos rótulos para regressão, o que significa que cada rótulo representa o valor futuro real do preço. A função labelling_relabeling_regression é usada para criar dados rotulados.mt5.initialize() SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_H1 START_DATE = datetime(2000, 1, 1) STOP_DATE = datetime(2023, 1, 1) # Задаем количество временных шагов по вашим требованиям n_steps = 100 # Обрабатываем данные data = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START_DATE, STOP_DATE), columns=['time', 'close']).set_index('time') data.index = pd.to_datetime(data.index, unit='s') data = data.dropna() data = data[['close']] # Работаем только с закрытием
# Определить train_data_initial training_size = int(len(data) * 0.70) train_data_initial = data.iloc[:training_size] test_data_initial = data.iloc[training_size:] # Функция для создания и присвоения меток для регрессии (изменения внесены для регрессии, а не классификации) def labelling_relabeling_regression(dataset, min_value=1, max_value=1): future_prices = [] for i in range(dataset.shape[0] - max_value): rand = random.randint(min_value, max_value) future_pr = dataset['close'].iloc[i + rand] future_prices.append(future_pr) dataset = dataset.iloc[:len(future_prices)].copy() dataset['future_price'] = future_prices return dataset # Применить функцию labelling_relabeling_regression к исходным данным, чтобы получить маркированные данные train_data_labeled = labelling_relabeling_regression(train_data_initial) test_data_labeled = labelling_relabeling_regression(test_data_initial)
Primeiramente, montamos conjuntos de dados de treinamento utilizando sequências específicas. É importante que o modelo incorpore todos os preços de fechamento presentes na sequência como características. Utilizamos o mesmo tamanho de sequência para os dados de entrada do modelo ONNX, e optamos por não normalizar nesta etapa inicial – essa normalização acontecerá mais adiante, no decorrer do pipeline de treinamento.
# Создаем наборы данных признаков и целевых переменных для тестирования
x_test = np.array([test_data_labeled['close'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(test_data_labeled))])
y_test = test_data_labeled['future_price'].iloc[n_steps:].values
# После создания x_train и x_test, можно определить n_features так:
n_features = x_train.shape[1]
# Теперь можно использовать n_features для определения типа входных данных ONNX
initial_type = [('float_input', FloatTensorType([None, n_features]))]
Escrevendo o pipeline Pipeline para pré-processamento de dados
A próxima etapa envolve a criação do modelo, especificamente um modelo de floresta aleatória. É essencial integrar este modelo dentro de um pipeline configurado adequadamente.
O uso de Pipeline na biblioteca scikit-learn (sklearn) facilita a criação de uma sequência ordenada de transformações e modelos. Essa ferramenta permite a combinação de múltiplas fases de processamento de dados e modelagem em um único objeto consolidado, garantindo que as operações sejam executadas de maneira conveniente e uniforme.
No exemplo de código que desenvolvemos, o pipeline é estruturado da seguinte maneira:
# Создаем конвейер с MinMaxScaler, RobustScaler, PolynomialFeatures и RandomForestRegressor
pipeline = Pipeline([
('MinMaxScaler', MinMaxScaler()),
('robust', RobustScaler()),
('poly', PolynomialFeatures()),
('rf', RandomForestRegressor(
n_estimators=20,
max_depth=20,
min_samples_split=5000,
min_samples_leaf=5000,
random_state=1,
verbose=2
))
])
# Обучение конвейера
pipeline.fit(x_train, y_train)
# Сделать прогнозы
predictions = pipeline.predict(x_test)
# Оценка модели с помощью R2
r2 = r2_score(y_test, predictions)
print(f'R2 score: {r2}') O Pipeline se configura como uma cadeia de etapas de processamento de dados e modelagem. Utilizando a biblioteca scikit-learn (sklearn), nosso pipeline compreende as etapas abaixo:
-
MinMaxScaler: Esta função ajusta os dados para que fiquem dentro de uma escala de 0 a 1, uniformizando as características.
-
RobustScaler: Diferentemente do MinMaxScaler, o RobustScaler oferece uma abordagem que tolera melhor os valores atípicos, ajustando os dados com base na mediana e no intervalo interquartil.
-
PolynomialFeatures: Aplicamos uma transformação polinomial às características, adicionando variáveis polinomiais para melhor captura de dependências não lineares nos dados.
-
RandomForestRegressor: Definimos o modelo de floresta aleatória com um conjunto específico de hiperparâmetros:
- n_estimators (Número de árvores na floresta): Imagine que você possui um grupo de "especialistas", cada um perito em prever os movimentos do mercado financeiro. O parâmetro n_estimators define quantos desses "especialistas" você tem em seu time. Quanto mais árvores, maior a diversidade de opiniões e previsões ao tomar decisões pelo modelo.
- max_depth (Profundidade máxima de cada árvore): Este parâmetro estabelece o limite de profundidade que cada "especialista" (árvore) pode alcançar ao analisar os dados. Por exemplo, uma profundidade máxima de 20 significa que cada árvore analisará até 20 características ou aspectos.
- min_samples_split (Número mínimo de amostras necessárias para dividir um nó da árvore): Este parâmetro determina quantas amostras são necessárias em um nó para que o processo de divisão em nós menores continue. Digamos que você escolha um mínimo de 5000 amostras para divisão; nesse caso, somente nós com mais de 5000 observações serão divididos.
- min_samples_leaf (Número mínimo de amostras em um nó folha da árvore): Esse critério especifica o número mínimo de amostras que um nó folha deve ter antes de ser considerado uma "folha", ou seja, um nó que não será mais dividido. Configurando, por exemplo, 5000 amostras como mínimo, cada folha terá pelo menos 5000 observações.
- random_state (Define o estado inicial para a geração aleatória, garantindo a reprodutibilidade dos resultados): Esse parâmetro ajuda a controlar a aleatoriedade dentro do modelo. Fixando um número, como 1, você garante que os resultados sejam consistentes a cada execução do modelo, o que é vital para testes e validação de resultados.
- verbose (Ativa a saída de informações sobre o processo de treinamento do modelo): O treinamento de um modelo pode ser mais instrutivo se você puder acompanhar o que está acontecendo. O parâmetro verbose ajusta o quanto de informação sobre o processo é exibido. Com um valor mais alto, como 2, mais detalhes são mostrados durante o treinamento.
Depois de montar o pipeline, utilizamos o método fit para treinar com os dados. A seguir, aplicamos o método predict para fazer previsões com base nos dados de teste. Por fim, avaliamos a eficácia do modelo usando a métrica R2, que avalia o quão adequadamente o modelo se adapta aos dados.
O pipeline é treinado e, em seguida, sua eficácia é medida pela métrica R2. Aplicamos técnicas como normalização e remoção de outliers, além de gerar características polinomiais. Esses representam os métodos fundamentais de pré-processamento de dados. Nos próximos artigos, planejamos explorar como desenvolver nossa própria função de pré-processamento através do uso do Function Transformer.
Usamos a exportação do modelo para ONNX, escrevemos uma função de exportação
Depois de treinar o pipeline, salvamos o modelo no formato joblib. Com o suporte da biblioteca skl2onnx, também o salvamos em formato ONNX.
# Сохраняем конвейер
joblib.dump(pipeline, 'rf_pipeline.joblib')
# Конвертация конвейера в ONNX
onnx_model = convert_sklearn(pipeline, initial_types=initial_type)
# Сохраняем модель в формате ONNX
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Сохраняем модель в формате ONNX
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Подключить Google Диск (если работаете в Colab и это необходимо)
from google.colab import drive
drive.mount('/content/drive')
# Указать путь к Google Диск, куда вы хотите переместить модель
drive_path = '/content/drive/My Drive/' # Убедитесь, что путь указан правильно
rf_pipeline_onnx_drive_path = os.path.join(drive_path, 'rf_pipeline.onnx')
# Переместить модель ONNX на Google Диск
shutil.move(model_onnx_path, rf_pipeline_onnx_drive_path)
print('Модель rf_pipeline сохранена в формате ONNX на Google Drive:', rf_pipeline_onnx_drive_path) Aqui está um vislumbre do processo de treinamento do modelo e como ele é armazenado em ONNX. Essa imagem será exibida ao concluirmos o treinamento:
O modelo é armazenado na pasta raiz do Google Drive, no formato ONNX. O ONNX pode ser comparado a um "disquete" de modelos de aprendizado de máquina. Esse formato é útil para armazenar modelos treinados e adaptá-los para uso em diferentes aplicativos. É como se você guardasse arquivos em um pen drive para depois acessá-los em diversos dispositivos. No nosso caso, o modelo ONNX será empregado no ambiente MetaTrader 5 para realizar previsões de preços nos mercados financeiros. O "disquete" ONNX pode ser acessado, por exemplo, no MetaTrader 5, que é o que faremos a seguir.
Verificamos o funcionamento do modelo no testador do MetaTrader 5
O modelo ONNX, que foi salvo no Google Drive, foi por nós baixado de lá. Após obter o modelo ONNX do Google Drive, procedemos ao seu uso no MetaTrader 5 criando um "especialista" (EA) que irá interpretar e aplicar esse modelo para fazer decisões de trading. No código do especialista, estipulamos os parâmetros de trading, como o volume de lotes e o uso de ordens stop, além de definir os níveis de Take Profit e Stop Loss. Aqui está o código do especialista que utilizará nosso modelo ONNX:
//+------------------------------------------------------------------+ //| ONNX Random Forest.mq5 | //| Copyright 2023 | //| Evgeniy Koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com" #property version "0.90" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; input double InpLots = 1.0; // Объем лота для открытия позиции input bool InpUseStops = true; // Использовать стоп-заказы при торговле input int InpTakeProfit = 500; // Уровень Take Profit input int InpStopLoss = 500; // Уровень Stop Loss #resource "Python/rf_pipeline.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 100 long ExtHandle=INVALID_HANDLE; int ExtPredictedClass=-1; datetime ExtNextBar=0; datetime ExtNextDay=0; CTrade ExtTrade; #define PRICE_UP 1 #define PRICE_SAME 2 #define PRICE_DOWN 0 // Функция для закрытия всех позиций void CloseAll(int type=-1) { for(int i=PositionsTotal()-1; i>=0; i--) { if(PositionSelectByTicket(PositionGetTicket(i))) { if(PositionGetInteger(POSITION_TYPE)==type || type==-1) { trade.PositionClose(PositionGetTicket(i)); } } } } // Инициализация эксперта int OnInit() { if(_Symbol!="EURUSD" || _Period!=PERIOD_H1) { Print("Модель должна работать с EURUSD, H1"); return(INIT_FAILED); } ExtHandle=OnnxCreateFromBuffer(ExtModel,ONNX_DEFAULT); if(ExtHandle==INVALID_HANDLE) { Print("Ошибка при создании модели OnnxCreateFromBuffer ",GetLastError()); return(INIT_FAILED); } const long input_shape[] = {1,100}; if(!OnnxSetInputShape(ExtHandle,ONNX_DEFAULT,input_shape)) { Print("Ошибка при установке формы входных данных OnnxSetInputShape ",GetLastError()); return(INIT_FAILED); } const long output_shape[] = {1,1}; if(!OnnxSetOutputShape(ExtHandle,0,output_shape)) { Print("Ошибка при установке формы выходных данных OnnxSetOutputShape ",GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Деинициализация эксперта void OnDeinit(const int reason) { if(ExtHandle!=INVALID_HANDLE) { OnnxRelease(ExtHandle); ExtHandle=INVALID_HANDLE; } } // Обработка тиковой функции void OnTick() { if(TimeCurrent()<ExtNextBar) return; ExtNextBar=TimeCurrent(); ExtNextBar-=ExtNextBar%PeriodSeconds(); ExtNextBar+=PeriodSeconds(); PredictPrice(); if(ExtPredictedClass>=0) if(PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); } // Проверка условий открытия позиции void CheckForOpen(void) { ENUM_ORDER_TYPE signal=WRONG_VALUE; if(ExtPredictedClass==PRICE_DOWN) signal=ORDER_TYPE_SELL; else { if(ExtPredictedClass==PRICE_UP) signal=ORDER_TYPE_BUY; } if(signal!=WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price,sl=0,tp=0; double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); if(signal==ORDER_TYPE_SELL) { price=bid; if(InpUseStops) { sl=NormalizeDouble(bid+InpStopLoss*_Point,_Digits); tp=NormalizeDouble(ask-InpTakeProfit*_Point,_Digits); } } else { price=ask; if(InpUseStops) { sl=NormalizeDouble(ask-InpStopLoss*_Point,_Digits); tp=NormalizeDouble(bid+InpTakeProfit*_Point,_Digits); } } ExtTrade.PositionOpen(_Symbol,signal,InpLots,price,sl,tp); } } // Проверка условий закрытия позиции void CheckForClose(void) { if(InpUseStops) return; bool tsignal=false; long type=PositionGetInteger(POSITION_TYPE); if(type==POSITION_TYPE_BUY && ExtPredictedClass==PRICE_DOWN) tsignal=true; if(type==POSITION_TYPE_SELL && ExtPredictedClass==PRICE_UP) tsignal=true; if(tsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { ExtTrade.PositionClose(_Symbol,3); CheckForOpen(); } } // Функция для получения текущего спреда double GetSpreadInPips(string symbol) { double spreadPoints = SymbolInfoInteger(symbol, SYMBOL_SPREAD); double spreadPips = spreadPoints * _Point / _Digits; return spreadPips; } // Функция для прогнозирования цены void PredictPrice() { static vectorf output_data(1); static vectorf x_norm(SAMPLE_SIZE); double spread = GetSpreadInPips(_Symbol); if (!x_norm.CopyRates(_Symbol, _Period, COPY_RATES_CLOSE, 1, SAMPLE_SIZE)) { ExtPredictedClass = -1; return; } if (!OnnxRun(ExtHandle, ONNX_NO_CONVERSION, x_norm, output_data)) { ExtPredictedClass = -1; return; } float predicted = output_data[0]; if (spread < 0.000005 && predicted > iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_UP; } else if (spread < 0.000005 && predicted < iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_DOWN; } else { ExtPredictedClass = PRICE_SAME; } }
É especialmente importante notar que a dimensão dos dados de entrada:
const long input_shape[] = {1,100};
Deve coincidir com a dimensão usada no nosso modelo Python:
# Задаем количество временных шагов по вашим требованиям n_steps = 100
Em seguida, passamos a testar o modelo no ambiente do MetaTrader 5. Usamos as previsões do modelo para decidir a direção dos movimentos de preço no mercado. Se o modelo antecipa uma alta nos preços, nos preparamos para abrir uma posição longa (compra); e se prevê uma baixa, uma posição curta (venda). Testamos o modelo estabelecendo um take profit de 1000 e um stop loss de 500:
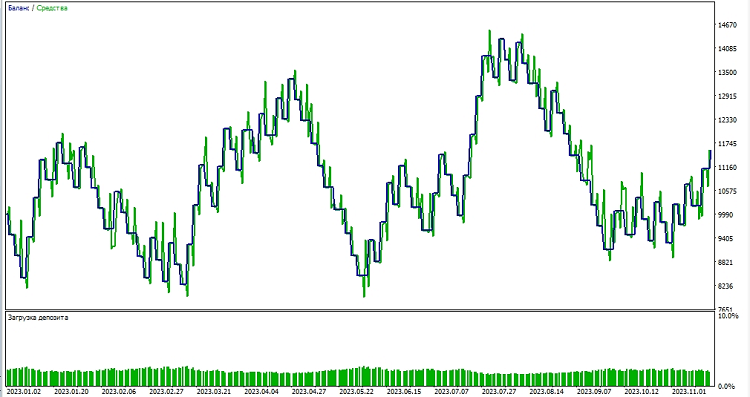
Considerações finais
Dessa forma, exploramos a criação e o treinamento de um modelo de floresta aleatória em Python, o pré-processamento dos dados diretamente no modelo e sua exportação para o formato ONNX, seguido pela sua ativação e uso no MetaTrader 5.
O ONNX é um sistema extremamente eficaz e simples para a importação e exportação de modelos. Salvar modelos em ONNX é surpreendentemente fácil, assim como é o pré-processamento dos dados.
É importante mencionar que nosso modelo, com apenas 20 árvores de decisão, é bastante básico, e o próprio modelo de floresta aleatória é um método já bastante antigo, originário do século passado. No futuro, planejamos desenvolver modelos mais complexos e modernos, e aplicar técnicas de pré-processamento de dados mais avançadas. Gostaria de ressaltar também a possibilidade de integrar um conjunto de modelos diretamente como um pipeline do sklearn, juntamente com o pré-processamento. Isso deverá ampliar significativamente nossas capacidades, inclusive para tarefas de classificação.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13725
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso