
Neuronale Netze leicht gemacht (Teil 9): Dokumentation der Arbeit

Inhalt
- Einführung
- 1. Die Grundprinzipien der Dokumentationserstellung
- 2. Die Auswahl der Instrumente
- 3. Dokumentieren im Code
- 4. Vorbereitung in der Code-Quelldatei
- 5. Generieren der Dokumentation
- Schlussfolgerungen
- Referenzen
- Die Programme dieses Artikels
Einführung
Im Laufe des Jahres haben wir neue Objekte hinzugefügt und die Funktionalität der bestehenden erweitert. All diese Ergänzungen haben unsere Bibliothek erweitert. Wir haben auch eine OpenCL-Programmdatei hinzugefügt. Jetzt ist der Code 10 Mal größer als der erste. Es wird immer schwieriger, die Beziehungen zwischen den Objekten im Code nachzuvollziehen. Für die Leser ist der Code möglicherweise sehr verwirrend und schwer zu verstehen. Ich versuche, in jedem Artikel eine detaillierte Beschreibung der Aktionslogik zu geben. Aber die Demonstration von einzelnen Aktionsketten vermittelt kein allgemeines Verständnis des Programms.
Deshalb habe ich mich entschlossen, die Erstellung einer Dokumentation zum Code zu demonstrieren, die es erlaubt, den Code aus einer anderen Perspektive zu betrachten. Der Zweck der Dokumentation besteht darin, alle Objekte und Methoden in der Bibliothek zu verallgemeinern und eine Hierarchie der Vererbung von Objekten und Methoden aufzubauen. Dies soll uns einen Überblick über unsere Arbeit geben.
1. Die Grundprinzipien der Dokumentationserstellung
Was ist der Zweck der technischen Dokumentation in IT-Entwicklungen? In erster Linie vermittelt die Dokumentation einen Überblick über die Programmarchitektur und die Funktionsweise. Eine ordnungsgemäße Dokumentation ermöglicht es den Entwicklungsteams, Verantwortungsbereiche korrekt abzugrenzen, alle Änderungen im Code zu verfolgen und deren Einfluss auf den gesamten Algorithmus und die Integrität der Architektur zu bewerten. Außerdem erleichtert sie den Wissensaustausch. Das Verständnis der Integrität der Programmarchitektur macht es möglich, Wege der Projektentwicklung zu analysieren und auszuarbeiten.
Richtig geschriebene technische Dokumentation sollte die Qualifikationen des Zielbenutzers berücksichtigen. Die Informationen sollten klar sein und übermäßige Erklärungen vermeiden. Die Dokumentation sollte alle Informationen enthalten, die der Benutzer benötigt. Gleichzeitig sollte sie prägnant und leicht zu lesen sein. Übermäßiger Inhalt nimmt zusätzliche Zeit zum Lesen in Anspruch und verärgert den Leser. Noch ärgerlicher ist es, wenn der Nutzer eine langatmige Dokumentation liest und die benötigten Informationen nicht findet. Dies führt zur nächsten Regel: Die Dokumentation muss über komfortable Werkzeuge zur Informationssuche verfügen. Eine nutzerfreundliche Oberfläche und Querverweise erleichtern das Auffinden der benötigten Informationen.
Die Dokumentation sollte die komplette Architektur der Lösung und eine Beschreibung der implementierten technischen Lösungen enthalten. Die vollständige und detaillierte Lösungsbeschreibung erleichtert die Entwicklung und den weiteren Support. Und es ist sehr wichtig, die Dokumentation immer auf dem neuesten Stand zu halten. Veraltete Informationen können zu widersprüchlichen Managemententscheidungen führen und damit die gesamte Entwicklung aus dem Gleichgewicht bringen.
Außerdem muss die Dokumentation unbedingt die Schnittstellen zwischen den Komponenten beschreiben.
2. Die Auswahl der Instrumente
Es gibt einige spezialisierte Programme, die bei der Erstellung von Dokumentation helfen können. Ich denke, die gebräuchlichsten sind Doxygen, Sphinx, Latex (es gibt auch einige andere Instrumente). Alle zielen darauf ab, den Arbeitsaufwand für die Erstellung von Dokumentation zu reduzieren. Natürlich wurde jedes Programm von Entwicklern geschaffen, um bestimmte Probleme zu lösen. Doxygen zum Beispiel ist ein Programm zur Erstellung von Dokumentation für C++-Programme und ähnliche Programmiersprachen. Sphinx wurde für die Dokumentation von Python erstellt. Das bedeutet aber nicht, dass sie hochspezialisiert auf Programmiersprachen sind. Beide Programme arbeiten gut mit verschiedenen Programmiersprachen zusammen. Auf den jeweiligen Websites der Programme finden Sie ausführliche Hinweise zu ihrer Verwendung, so dass Sie das für Sie passende Programm auswählen können.
Dokumentation für MQL5 wurde bereits früher besprochen, im Artikel "Automatisch generierte Dokumentation für den MQL5-Code". In diesem Artikel wurde die Verwendung von Doxygen vorgeschlagen. Ich verwende dieses Programm auch für meine Entwicklungen. Die MQL5-Syntax ist C++ sehr ähnlich und daher ist Doxygen für MQL5-Programme gut geeignet. Mir gefällt die Tatsache, dass man zur Erstellung der Dokumentation nur entsprechende Kommentare zum Programmcode hinzufügen muss, während die spezialisierte Software den Rest erledigt. Außerdem erlaubt Doxygen das Einfügen von Hyperlinks und mathematischen Formeln, was angesichts des Themas der Artikel wichtig ist. Wir werden in diesem Artikel anhand konkreter Beispiele weiter auf die Besonderheiten der Funktionsnutzung eingehen.
3. Dokumentieren im Code
Wie bereits erwähnt, müssen Sie zur Erstellung der Dokumentation Kommentare in den Programmcode einfügen. Doxygen erstellt die Dokumentation auf der Grundlage dieser Kommentare. Natürlich sollten nicht alle Code-Kommentare in die Dokumentation aufgenommen werden. Einige der Kommentare können Entwicklerhinweise enthalten, irgendwo werden Kommentare für nicht verwendeten Code hinzugefügt. Die Doxygen-Entwickler haben Möglichkeiten bereitgestellt, Kommentare zu markieren, die in die Dokumentation aufgenommen werden sollen. Es gibt mehrere Optionen, und Sie können diejenige wählen, die für Sie bequem ist.
Ähnlich wie bei MQL5 können Kommentare für die Dokumentation ein- und mehrzeilig sein. Um die direkte Verwendung des Codes in Zukunft nicht zu stören, werden wir die Standardoptionen für das Einfügen von Kommentaren verwenden, und wir werden einen zusätzlichen Schrägstrich für einzeilige Kommentare oder ein Sternchen für mehrzeilige Kommentare verwenden. Optional kann ein Ausrufezeichen verwendet werden, um Kommentarblöcke für die Dokumentation zu kennzeichnen.
/// A single-line comment for documentation /** A multi-line block for documentation */ //! An alternative single-line comment for documentation /*! An alternative multi-line block for documentation */
Bitte beachten Sie, dass ein mehrzeiliger Kommentarblock nicht bedeutet, dass dieselbe mehrzeilige Darstellung auch in der Dokumentation verwendet wird. Wenn Sie die kurze und ausführliche Beschreibung eines Programmobjekts trennen müssen, können Sie verschiedene Kommentarblöcke hinzufügen oder spezielle Befehle verwenden, die durch das Zeichen "\" oder "@" gekennzeichnet sind. Der Befehl "\n" kann für einen erzwungenen Zeilenumbruch verwendet werden.
Option 1: Separate blocks /// Short description /** Detailed description */ Option 2: Use of special commands /** \brief Brief description \details Detailed description */
Im Allgemeinen wird davon ausgegangen, dass sich das Dokumentationsobjekt in der Datei neben dem Kommentarblock befindet. In der Praxis kann es jedoch erforderlich sein, das Objekt zu kommentieren, das sich vor dem Kommentarblock befindet. In diesem Fall verwenden Sie das Zeichen "<", das Doxygen mitteilt, dass sich das kommentierte Objekt vor dem Block befindet. Um Querverweise in Kommentaren zu erzeugen, stellen Sie dem Referenzobjekt das Zeichen "#" voran. Nachfolgend sehen Sie ein Beispiel für Code und einen daraus generierten Block in der Dokumentation. In der generierten Vorlage ist "CConnection" ein Verweis, der auf die Dokumentationsseite der entsprechenden Klasse zeigt.
#define defConnect 0x7781 ///<Connection \details Identified class #CConnection
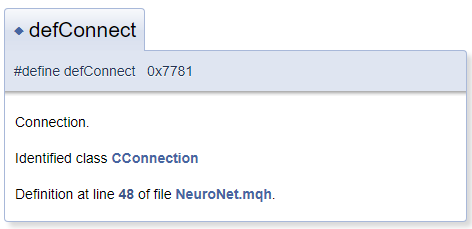
Die Fähigkeiten von Doxygen sind umfangreich. Die vollständige Liste der Befehle und ihre Beschreibungen finden Sie auf der Programmseite unter dem Abschnitt Dokumentation. Außerdem versteht Doxygen HTML- und XML-Markup. All diese Funktionen ermöglichen die Lösung einer Vielzahl von Aufgaben bei der Dokumentationserstellung.
4. Vorbereitung in der Code-Quelldatei
Nachdem wir nun die Fähigkeiten des Instruments kennengelernt haben, können wir mit der Arbeit an der Dokumentation beginnen. Lassen Sie uns zunächst unsere Dateien beschreiben.
/// \file /// \brief NeuroNet.mqh /// Library for creating Neural network for use in MQL5 experts /// \author [DNG](https://www.mql5.com/en/users/dng) /// \copyright Copyright 2019, DNG
und
/// \file /// \brief NeuroNet.cl /// Library consist OpenCL kernels /// \author <A HREF="https://www.mql5.com/en/users/dng"> DNG </A> /// \copyright Copyright 2019, DNG
Achten Sie darauf, dass im ersten Fall dem Zeiger \author das von Doxygen bereitgestellte Markup folgt und im zweiten Fall das HTML-Markup verwendet wird. Dies wird hier verwendet, um verschiedene Möglichkeiten zur Erstellung von Hyperlinks zu demonstrieren. Das Ergebnis ist in beiden Fällen das gleiche - es wird ein Link zu meinem Profil bei MQL5.com erstellt.
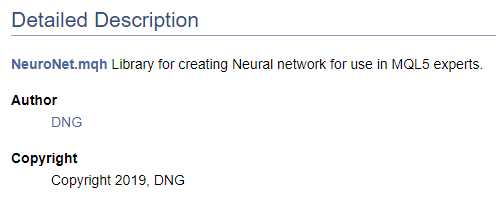
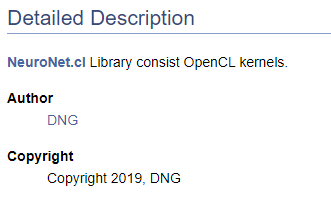
Wenn man mit der Erstellung von Code-Dokumentation beginnt, ist es natürlich notwendig, zumindest eine High-Level-Struktur des gewünschten Ergebnisses zu haben. Das Verständnis der endgültigen Struktur ermöglicht eine korrekte Gruppierung der Dokumentationsobjekte. Lassen Sie uns die erstellten Aufzählungen in einer eigenen Gruppe zusammenfassen. Um eine Gruppe zu deklarieren, verwenden Sie den Befehl "\defgroup". Die Grenzen der Gruppe werden durch die Zeichen "@{" und "@}" gekennzeichnet.
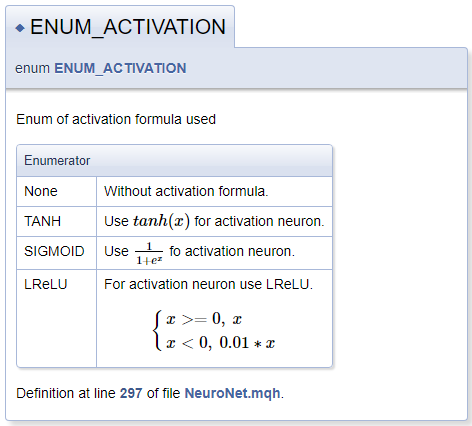
///\defgroup enums ENUM ///@{ //+------------------------------------------------------------------+ /// Enum of activation formula used //+------------------------------------------------------------------+ enum ENUM_ACTIVATION { None=-1, ///< Without activation formula TANH, ///< Use \f$tanh(x)\f$ for activation neuron SIGMOID, ///< Use \f$\frac{1}{1+e^x}\f$ fo activation neuron LReLU ///< For activation neuron use LReLU \f[\left\{ \begin{array} a x>=0, \ x \\x<0, \ 0.01*x \end{array} \right.\f] }; //+------------------------------------------------------------------+ /// Enum of optimization method used //+------------------------------------------------------------------+ enum ENUM_OPTIMIZATION { SGD, ///< Stochastic gradient descent ADAM ///< Adam }; ///@}
Bei der Beschreibung von Aktivierungsfunktionen habe ich die Funktionalität zur Deklaration von mathematischen Formeln mit Hilfe von MathJax demonstriert. Die Beschreibungen solcher Formeln sollten zwischen einem Paar von "\f$"-Befehlen platziert werden, wenn die Formel in einer Textzeile angezeigt werden soll, oder zwischen den Befehlen "\f[" und "\f]", wenn die Formel in einer eigenen Zeile erscheinen soll. Der Befehl "\frac" erlaubt es, einen Bruch zu beschreiben. Dem Befehl folgen Zähler und Nenner des Bruches in geschweiften Klammern.
Bei der Beschreibung von LReLU benötigten wir eine vereinheitlichende linke geschweifte Klammer. Um diese zu erzeugen, verwendeten wir die Befehle "\left\{" and "\right\.". Dem "\right"-Befehl folgt ein "\.", weil die rechte Klammer in der Formel nicht benötigt wird. Ansonsten würde der Punkt durch eine schließende geschweifte Klammer ersetzt werden. Ein Array von Strings wird innerhalb des Blocks mit den Befehlen "\begin{array} a" und "\end{array}" deklariert, die Trennung der Array-Elemente erfolgt durch den Befehl "\\". Die Zeichen "\ " ermöglichen das Hinzufügen eines erzwungenen Leerzeichens.
Der generierte Dokumentationsblock ist unten abgebildet.
Im nächsten Schritt legen wir in der Bibliothek eine eigene Gruppe für Klassenbezeichner an. Innerhalb der Gruppe werden wir Untergruppen für Arrays, Neuronen, die Operationen auf der CPU berechnen, und Neuronen, die Operationen auf der GPU berechnen, zuordnen. Eine Verknüpfung zu der entsprechenden Klasse wird wie zuvor erklärt hinzugefügt.
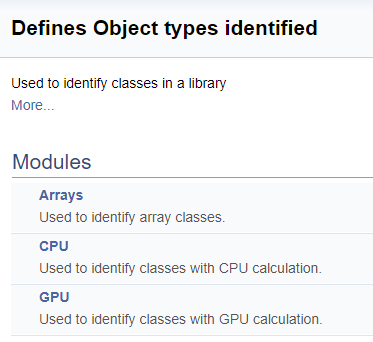
///\defgroup ObjectTypes Defines Object types identified ///Used to identify classes in a library ///@{ //+------------------------------------------------------------------+ ///\defgroup arr Arrays ///Used to identify array classes ///\{ #define defArrayConnects 0x7782 ///<Array of connections \details Identified class #CArrayCon #define defLayer 0x7787 ///<Layer of neurons \details Identified class #CLayer #define defArrayLayer 0x7788 ///<Array of layers \details Identified class #CArrayLayer #define defNet 0x7790 ///<Neuron Net \details Identified class #CNet ///\} ///\defgroup cpu CPU ///Used to identify classes with CPU calculation ///\{ #define defConnect 0x7781 ///<Connection \details Identified class #CConnection #define defNeuronBase 0x7783 ///<Neuron base type \details Identified class #CNeuronBase #define defNeuron 0x7784 ///<Full connected neuron \details Identified class #CNeuron #define defNeuronConv 0x7785 ///<Convolution neuron \details Identified class #CNeuronConv #define defNeuronProof 0x7786 ///<Proof neuron \details Identified class #CNeuronProof #define defNeuronLSTM 0x7791 ///<LSTM Neuron \details Identified class #CNeuronLSTM ///\} ///\defgroup gpu GPU ///Used to identify classes with GPU calculation ///\{ #define defBufferDouble 0x7882 ///<Data Buffer OpenCL \details Identified class #CBufferDouble #define defNeuronBaseOCL 0x7883 ///<Neuron Base OpenCL \details Identified class #CNeuronBaseOCL #define defNeuronConvOCL 0x7885 ///<Convolution neuron OpenCL \details Identified class #CNeuronConvOCL #define defNeuronProofOCL 0x7886 ///<Proof neuron OpenCL \details Identified class #CNeuronProofOCL #define defNeuronAttentionOCL 0x7887 ///<Attention neuron OpenCL \details Identified class #CNeuronAttentionOCL ///\} ///@}
Die Einteilung in Gruppen sieht in der generierten Dokumentation wie folgt aus.
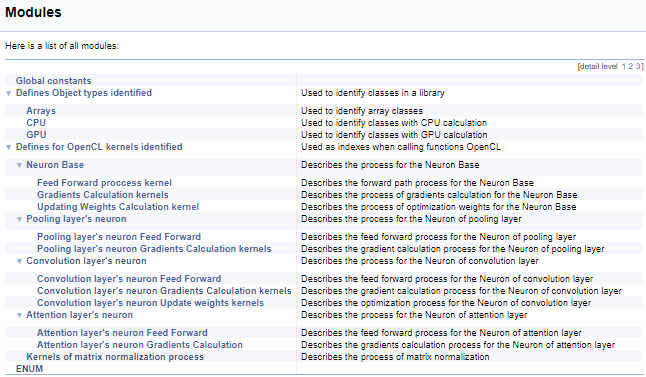
Als Nächstes wird eine große Gruppe von Definitionen für die Arbeit mit OpenCL-Kerneln bearbeitet. In diesem Block werden den Kernel-Indizes und ihren Parametern mnemotechnische Namen zugeordnet, die beim Aufruf von Kerneln aus dem Hauptprogramm verwendet werden. Mit der obigen Technik werden wir diese Gruppe nach der Klasse der Neuronen aufteilen, von denen der Kernel aufgerufen wird, und dann nach dem Inhalt der Operationen im Kernel (feed-forward, gradient back propagation, Aktualisierung der Gewichtskoeffizienten). Ich werde hier nicht den vollständigen Code bereitstellen - er ist im Anhang unten verfügbar. Die Logik zur Konstruktion von Untergruppen ist ähnlich wie im obigen Beispiel. Der Screenshot unten zeigt die komplette Gruppenstruktur.
Fahren wir mit den Kerneln fort und gehen wir zur Kommentierung des OpenCL-Programms über. Um eine zusammenhängende Dokumentationsstruktur zu erstellen und einen Überblick zu bekommen, werden wir einen weiteren Doxygen-Befehl "\ingroup" verwenden, der es erlaubt, neue Dokumentationsobjekte zu bereits erstellten Gruppen hinzuzufügen. Wir verwenden ihn, um Kernel zu den zuvor erstellten Gruppen von Indizes für die Arbeit mit Kernel hinzuzufügen. Fügen Sie in der Kernel-Beschreibung einen Link zur aufrufenden Klasse und zu einem Artikel auf dieser Site mit einer Beschreibung des Prozesses hinzu. Als Nächstes wollen wir die Kernel-Parameter beschreiben. Die Verwendung der Zeiger "[in]" und "[out]" zeigt die Richtung des Informationsflusses. Querverweise zeigen das Format der Daten an.
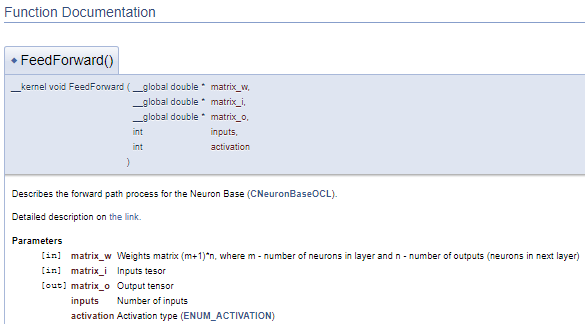
///\ingroup neuron_base_ff Feed forward process kernel /// Describes the forward path process for the Neuron Base (#CNeuronBaseOCL). ///\details Detailed description on <A HREF="https://www.mql5.com/de/articles/8435#para41">the link.</A> //+------------------------------------------------------------------+ __kernel void FeedForward(__global double *matrix_w,///<[in] Weights matrix (m+1)*n, where m - number of neurons in layer and n - number of outputs (neurons in next layer) __global double *matrix_i,///<[in] Inputs tesor __global double *matrix_o,///<[out] Output tensor int inputs,///< Number of inputs int activation///< Activation type (#ENUM_ACTIVATION) )
Der obige Code erzeugt den folgenden Dokumentationsblock.
Im obigen Beispiel wird die Beschreibung der Parameter direkt nach deren Deklaration angegeben. Dieser Ansatz kann den Code jedoch unhandlich machen. In solchen Fällen empfiehlt es sich, den Befehl "\param" zur Beschreibung der Parameter zu verwenden. Durch die Verwendung dieses Befehls können wir die Parameter an einer beliebigen Stelle der Datei beschreiben, aber wir müssen den Parameternamen direkt angeben.
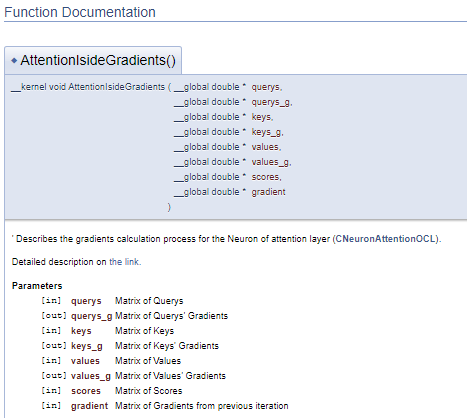
///\ingroup neuron_atten_gr Attention layer's neuron Gradients Calculation kernel /// Describes the gradients calculation process for the Neuron of attention layer (#CNeuronAttentionOCL). ///\details Detailed description on <A HREF="https://www.mql5.com/ru/articles/8765#para44">the link.</A> /// @param[in] querys Matrix of Querys /// @param[out] querys_g Matrix of Querys' Gradients /// @param[in] keys Matrix of Keys /// @param[out] keys_g Matrix of Keys' Gradients /// @param[in] values Matrix of Values /// @param[out] values_g Matrix of Values' Gradients /// @param[in] scores Matrix of Scores /// @param[in] gradient Matrix of Gradients from previous iteration //+------------------------------------------------------------------+ __kernel void AttentionIsideGradients(__global double *querys,__global double *querys_g, __global double *keys,__global double *keys_g, __global double *values,__global double *values_g, __global double *scores, __global double *gradient)
Dieser Ansatz erzeugt einen ähnlichen Dokumentationsblock, ermöglicht es aber, den Block mit den Kommentaren vom Programmcode zu trennen. Dadurch wird der Code einfacher zu lesen.
Die Hauptarbeit betrifft die Dokumentation für unsere Bibliotheksklassen und ihre Methoden. Wir müssen alle verwendeten Klassen und deren Methoden beschreiben. Dazu werden wir alle oben beschriebenen Befehle in verschiedenen Variationen verwenden und einige neue hinzufügen. Zunächst fügen wir die Klasse der entsprechenden Gruppe hinzu, so wie wir es zuvor mit den Kerneln gemacht haben (der Befehl \ingroup). Der Befehl "Klasse" teilt Doxygen mit, dass die unten stehende Beschreibung für die Klasse gilt. Geben Sie in den Befehlsparametern den Klassennamen an, um die Beschreibung mit dem richtigen Objekt zu verknüpfen.
Geben Sie mit den Befehlen "\brief" und "\details" eine kurze und eine erweiterte Klassenbeschreibung an. Fügen Sie in der ausführlichen Beschreibung einen Hyperlink auf den entsprechenden Artikel ein. Hier fügen wir einen Anker-Link zu einem bestimmten Abschnitt des Artikels ein, der es dem Benutzer ermöglicht, die benötigten Informationen schneller zu finden.
Fügen Sie die Beschreibungen direkt in die Zeile der Variablendeklaration ein. Fügen Sie bei Bedarf Links zu erklärenden Objekten hinzu. Es ist nicht nötig, in den Kommentaren Verweise auf die Klassen der deklarierten Objekte zu setzen, Doxygen fügt sie automatisch hinzu.
Beschreiben Sie in ähnlicher Weise die Methoden der Klassen. Im Gegensatz zu den Variablen sollte jedoch eine Beschreibung der Parameter in den Kommentaren hinzugefügt werden. Verwenden Sie dazu die bereits beschriebenen "\param"-Befehle zusammen mit den Zeigern "[in]", "[out]", "[in,out]". Beschreiben Sie das Ergebnis der Methodenausführung mit dem Befehl "\return".
Es ist auch möglich, einzelne Methoden durch bestimmte Merkmale zu Gruppen zusammenzufassen. Zum Beispiel können sie nach Funktionalität zusammengefasst werden.
Der folgende Code zeigt alle oben genannten Schritte.
///\ingroup neuron_base ///\class CNeuronBaseOCL ///\brief The base class of neuron for GPU calculation. ///\details Detailed description on <A HREF="https://www.mql5.com/ru/articles/8435#para45">the link.</A> //+------------------------------------------------------------------+ class CNeuronBaseOCL : public CObject { protected: COpenCLMy *OpenCL; ///< Object for working with OpenCL CBufferDouble *Output; ///< Buffer of Output tenzor CBufferDouble *PrevOutput; ///< Buffer of previous iteration Output tenzor CBufferDouble *Weights; ///< Buffer of weights matrix CBufferDouble *DeltaWeights; ///< Buffer of last delta weights matrix (#SGD) CBufferDouble *Gradient; ///< Buffer of gradient tenzor CBufferDouble *FirstMomentum; ///< Buffer of first momentum matrix (#ADAM) CBufferDouble *SecondMomentum; ///< Buffer of second momentum matrix (#ADAM) //--- const double alpha; ///< Multiplier to momentum in #SGD optimization int t; ///< Count of iterations //--- int m_myIndex; ///< Index of neuron in layer ENUM_ACTIVATION activation; ///< Activation type (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Optimization method (#ENUM_OPTIMIZATION) //--- ///\ingroup neuron_base_ff virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///< \brief Feed Forward method of calling kernel ::FeedForward().@param NeuronOCL Pointer to previos layer. ///\ingroup neuron_base_opt virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); ///< Method for updating weights.\details Calling one of kernels ::UpdateWeightsMomentum() or ::UpdateWeightsAdam() in depends of optimization type (#ENUM_OPTIMIZATION).@param NeuronOCL Pointer to previos layer. public: /** Constructor */CNeuronBaseOCL(void); /** Destructor */~CNeuronBaseOCL(void); virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object. #param[in] numNeurons Number of neurons in layer @param optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. virtual void SetActivationFunction(ENUM_ACTIVATION value) { activation=value; } ///< Set the type of activation function (#ENUM_ACTIVATION) //--- virtual int getOutputIndex(void) { return Output.GetIndex(); } ///< Get index of output buffer @return Index virtual int getPrevOutIndex(void) { return PrevOutput.GetIndex(); } ///< Get index of previous iteration output buffer @return Index virtual int getGradientIndex(void) { return Gradient.GetIndex(); } ///< Get index of gradient buffer @return Index virtual int getWeightsIndex(void) { return Weights.GetIndex(); } ///< Get index of weights matrix buffer @return Index virtual int getDeltaWeightsIndex(void) { return DeltaWeights.GetIndex(); } ///< Get index of delta weights matrix buffer (SGD)@return Index virtual int getFirstMomentumIndex(void) { return FirstMomentum.GetIndex(); } ///< Get index of first momentum matrix buffer (Adam)@return Index virtual int getSecondMomentumIndex(void) { return SecondMomentum.GetIndex();} ///< Get index of Second momentum matrix buffer (Adam)@return Index //--- virtual int getOutputVal(double &values[]) { return Output.GetData(values); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getOutputVal(CArrayDouble *values) { return Output.GetData(values); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getPrevVal(double &values[]) { return PrevOutput.GetData(values); } ///< Get values of previous iteration output buffer @param[out] values Array of data @return number of items virtual int getGradient(double &values[]) { return Gradient.GetData(values); } ///< Get values of gradient buffer @param[out] values Array of data @return number of items virtual int getWeights(double &values[]) { return Weights.GetData(values); } ///< Get values of weights matrix buffer @param[out] values Array of data @return number of items virtual int Neurons(void) { return Output.Total(); } ///< Get number of neurons in layer @return Number of neurons virtual int Activation(void) { return (int)activation; } ///< Get type of activation function @return Type (#ENUM_ACTIVATION) virtual int getConnections(void) { return (CheckPointer(Weights)!=POINTER_INVALID ? Weights.Total()/(Gradient.Total()) : 0); } ///< Get number of connections 1 neuron to next layer @return Number of connections //--- virtual bool FeedForward(CObject *SourceObject); ///< Dispatch method for defining the subroutine for feed forward process. @param SourceObject Pointer to the previous layer. virtual bool calcHiddenGradients(CObject *TargetObject); ///< Dispatch method for defining the subroutine for transferring the gradient to the previous layer. @param TargetObject Pointer to the next layer. virtual bool UpdateInputWeights(CObject *SourceObject); ///< Dispatch method for defining the subroutine for updating weights.@param SourceObject Pointer to previos layer. ///\ingroup neuron_base_gr ///@{ virtual bool calcHiddenGradients(CNeuronBaseOCL *NeuronOCL); ///< Method to transfer gradient to previous layer by calling kernel ::CalcHiddenGradient(). @param NeuronOCL Pointer to next layer. virtual bool calcOutputGradients(CArrayDouble *Target); ///< Method of output gradients calculation by calling kernel ::CalcOutputGradient().@param Target target value ///@} //--- virtual bool Save(int const file_handle);///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle);///< Load method @param[in] file_handle handle of file @return logical result of operation //--- virtual int Type(void) const { return defNeuronBaseOCL; }///< Identifier of class.@return Type of class };
Um die Arbeit mit dem Code abzuschließen, lassen Sie uns eine Titelseite erstellen. Der Befehl "\mainpage" wird verwendet, um den Deckblattblock zu identifizieren. Dem Befehl sollte der Titel des Deckblatts folgen. Im Folgenden fügen wir die Projektbeschreibung hinzu und erstellen eine Liste der Referenzen. Die Listenelemente werden durch das Zeichen "-" gekennzeichnet. Um Links zu früher erstellten Gruppen zu erstellen, verwenden Sie den Befehl "\ref". Wenn Doxygen Dokumentation generiert, werden Seiten der Klassenhierarchie (hierarchy.html) und der verwendeten Dateien (files.html) erzeugt. Fügen Sie Links zu den angegebenen Seiten in die Liste ein. Der endgültige Code für die Titelseite ist unten dargestellt.
///\mainpage NeuronNet /// Library for creating Neural network for use in MQL5 experts. /// - \ref const /// - \ref enums /// - \ref ObjectTypes /// - \ref group1 /// - [<b>Class Hierarchy</b>](hierarchy.html) /// - [<b>Files</b>](files.html)
Die folgende Seite wird basierend auf dem obigen Code generiert.
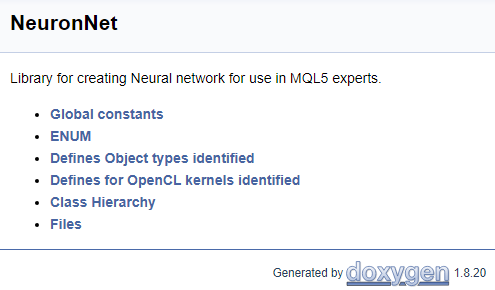
Der vollständige Code mit allen Kommentaren ist im Anhang zu finden.
5. Generieren der Dokumentation
Nachdem Sie die Arbeit mit dem Code abgeschlossen haben, fahren Sie mit dem nächsten Schritt fort. Die Installation und Einrichtung von Doxygen ist im Artikel [9] ausführlich beschrieben. Betrachten wir das Einrichten einiger Programmparameter. Zunächst teilen Sie Doxygen mit, mit welchen Dateien es arbeiten soll: auf der Registerkarte "Experte", im Bereich "Eingabe", fügen Sie dem Parameter "FILE_PATTERNS" die erforderlichen Dateimasken hinzu. In diesem Fall habe ich "*.mqh" und "*.cl" hinzugefügt.
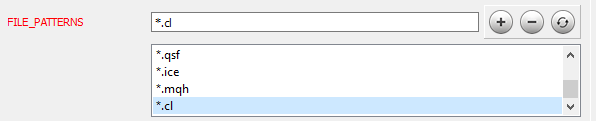
Nun müssen wir Doxygen mitteilen, wie es die hinzugefügten Dateien parsen soll. Gehen Sie zum Thema "Projekt" auf der gleichen Registerkarte "Experte" und bearbeiten Sie den Parameter EXTENSION_MAPPING wie in der Abbildung unten gezeigt.

Um Doxygen in die Lage zu versetzen, mathematische Formeln zu generieren, aktivieren Sie die Verwendung von MathJax. Aktivieren Sie dazu den Parameter USE_MATHJAX im HTML-Thema der Registerkarte Expert, wie in der folgenden Abbildung dargestellt.

Nachdem Sie das Programm konfiguriert haben, wechseln Sie auf die Registerkarte Assistent und geben den Namen des Projekts, den Pfad zu den Quelldateien und den Pfad für die Anzeige der generierten Dokumentation an (alle diese Schritte werden im Artikel [9] gezeigt). Gehen Sie auf die Registerkarte Run (Ausführen) und führen Sie das Dokumentationserstellungsprogramm aus.
Sobald das Programm abgeschlossen ist, erhalten Sie eine fertige Dokumentation. Einige Screenshots sind unten abgebildet. Die vollständige Dokumentation finden Sie im Anhang.
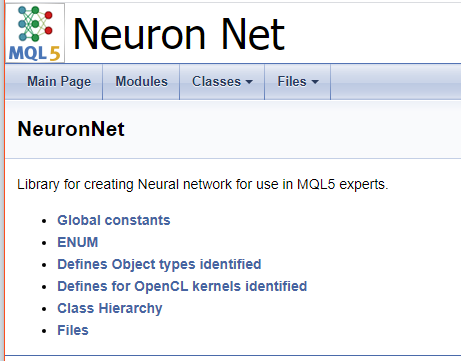
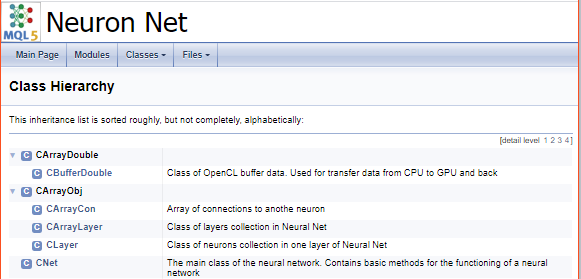
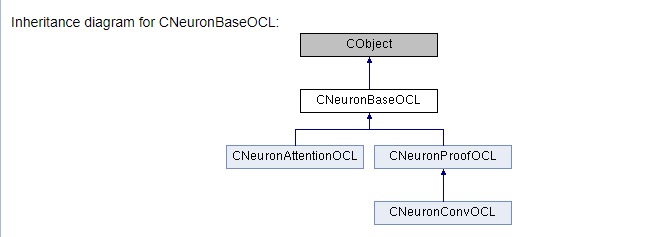
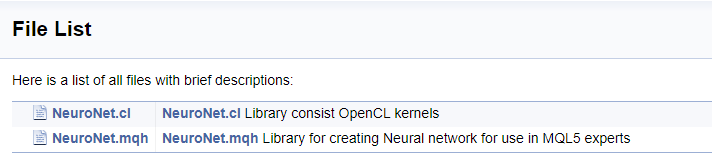
Schlussfolgerungen
Die Dokumentation von entwickelten Programmen ist nicht die Hauptaufgabe des Programmierers. Bei der Entwicklung komplexer Projekte ist eine solche Dokumentation jedoch unerlässlich. Sie hilft bei der Verfolgung der Umsetzung von Aufgaben, bei der Koordination der Arbeit eines Entwicklungsteams und bietet einfach eine ganzheitliche Sicht auf die Entwicklung. Dokumentation ist ein Muss, wenn Wissen geteilt werden soll.
Der Artikel beschreibt einen Mechanismus zur Dokumentation von Entwicklungen in der Sprache MQL5. Er bietet eine detaillierte Beschreibung aller Schritte des Mechanismus. Die Ergebnisse der durchgeführten Arbeiten sind im Anhang verfügbar, so dass jeder sie bewerten kann.
Ich hoffe, meine Erfahrungen sind hilfreich.
Referenzen
- Neuronale Netze leicht gemacht
- Neuronale Netze leicht gemacht (Teil 2): Netzwerktraining und Tests
- Neuronale Netze leicht gemacht (Teil 3): Convolutional Neurale Netzwerke
- Neuronale Netze leicht gemacht (Teil 4): Rekurrente Netze
- Neuronale Netze leicht gemacht (Teil 5): Parallele Berechnungen mit OpenCL
- Neuronale Netze leicht gemacht (Teil 6): Experimentieren mit der Lernrate des neuronalen Netzwerks
- Neuronale Netze leicht gemacht (Teil 7): Adaptive Optimierungsverfahren
- Neuronale Netze leicht gemacht (Teil 8): Attention-Mechanismen
- Automatisch generierte Dokumentation für den MQL5-Code
- Doxygen
Die Programme dieses Artikels
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek mit Klassen zum Erstellen eines neuronalen Netzwerks |
| 2 | NeuroNet.cl | Bibliothek | Die Bibliothek mit dem Programm-Code für OpenCL |
| 3 | html.zip | ZIP-Archive | Mit Doxygen generiertes Dokumentationsarchiv |
| 4 | NN.chm | HTML Hilfe | Die konvertierte HTML-Hilfedatei. |
| 5 | Doxyfile | Doxygen Parameter-Datei |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/8819
 Der Markt und die Physik seiner globalen Muster
Der Markt und die Physik seiner globalen Muster
 Entwicklung eines selbstanpassenden Algorithmus (Teil I): Finden eines Grundmusters
Entwicklung eines selbstanpassenden Algorithmus (Teil I): Finden eines Grundmusters
 Über das Finden von zeitlicher Mustern im Devisenmarkt mit dem CatBoost-Algorithmus
Über das Finden von zeitlicher Mustern im Devisenmarkt mit dem CatBoost-Algorithmus
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.