Алгоритм оптимизации на основе мозгового штурма — Brain Storm Optimization (Часть I): Кластеризация

Содержание:
1. Введение
2. Описание алгоритма
3. K-Means
1. Введение
BSO (Brain Storm Optimization) — это один из захватывающих и инновационных популяционных алгоритмов оптимизации, который вдохновлен природным явлением - "мозговым штурмом". Этот метод оптимизации представляет собой эффективный подход к решению сложных задач, используя принципы коллективного интеллекта и коллективного поведения. BSO имитирует процесс генерации новых идей и решений, подобный тому, как это происходит в групповых обсуждениях, что делает его уникальным и перспективным инструментом для поиска оптимальных решений в различных областях. В данной статье мы рассмотрим основные принципы работы BSO, его преимущества и области применения.Методы, основанные на популяции, являются важным инструментом для решения сложных задач оптимизации. Однако в контексте многомодальных задач, где требуется нахождение нескольких оптимальных решений, существующие подходы сталкиваются с ограничениями. В данной статье представлен новый метод оптимизации, названный методом оптимизации мозгового штурма.
Существующие подходы, такие как методы ниширования и кластеризации, обычно разделяют популяцию на подпопуляции для поиска нескольких решений. Однако эти методы страдают от необходимости предварительно определить количество подпопуляций, что может быть сложной задачей, особенно когда количество оптимальных решений неизвестно заранее. BSO компенсирует этот недостаток, переводя целевое пространство в пространство, где индивиды кластеризуются и обновляются на основе их координат. В отличие от существующих методов, которые стремятся к одному глобальному оптимуму, предложенный метод BSO направляет процесс поиска к нескольким "значимым" решениям.
Давайте подробно рассмотрим метод BSO и его применимость к многомодальным задачам оптимизации. Алгоритм оптимизации на основе мозгового штурма (BSO) был разработан Ши и др. в 2015 году и вдохновлен природным процессом мозгового штурма, когда люди собираются, чтобы генерировать и обмениваться идеями для решения проблемы.
Существует несколько вариантов алгоритма, таких как Hypo Variance Brain Storm Optimization, где оценка функции объекта основана на гипо- или подварианте, а не на гауссовой дисперсии. Есть и другие варианты, например, Global-best Brain Storm Optimization, где глобальный лучший включает схему повторной инициализации, которая активируется текущим состоянием популяции, в сочетании с обновлениями по переменным и группировкой на основе приспособленности.
Важно отметить, что каждый индивид в алгоритме BSO представляет не только решение проблемы, которую нужно оптимизировать, но и точку данных, которая раскрывает ландшафт проблемы. Техники коллективного интеллекта и анализа данных могут быть объединены, чтобы получить преимущества, превышающие то, что каждый метод мог бы достичь в одиночку.
2. Описание алгоритма
Алгоритм BSO работает, моделируя этот процесс, где популяция кандидатных решений (называемых "индивидами" или "идеями") итеративно обновляется, чтобы сходиться к оптимальному решению. Алгоритм состоит из следующих основных этапов:
1. Инициализация:
- Алгоритм начинает с генерации начальной популяции индивидов, где каждый индивид представляет потенциальное решение оптимизационной задачи.
- Каждый индивид представлен набором переменных решения, которые определяют характеристики решения.
2. Мозговой штурм:
- На этом этапе алгоритм моделирует процесс мозгового штурма, где индивиды генерируют новые идеи (т.е. новые кандидатные решения) путем комбинирования и модификации своих собственных идей и идей других индивидов.
- Процесс мозгового штурма направляется набором правил, которые определяют, как генерируются новые идеи. Эти правила вдохновлены человеческим процессом мозгового штурма включают:
- Случайную генерацию новых идей
- Комбинацию идей от разных индивидов
- Модификацию существующих идей
3. Оценка:
- Вновь созданные идеи (т.е. новые кандидатные решения) оцениваются с использованием целевой функции оптимизационной задачи.
- Целевая функция измеряет качество или пригодность каждого кандидатного решения, и алгоритм стремится найти решение, которое минимизирует (или максимизирует) эту функцию.
4. Отбор:
- После этапа оценки алгоритм выбирает лучших индивидов из популяции, чтобы сохранить их для следующей итерации.
- Процесс отбора основан на значениях пригодности индивидов, при этом более пригодные индивиды имеют более высокую вероятность быть выбранными.
5. Завершение:
- Алгоритм продолжает итерировать через этапы мозгового штурма, оценки и отбора, пока не будет выполнен критерий завершения, такой как максимальное число итераций или достижение целевого качества решения.
Перечислим отдельные характерные методы BSO, особенности алгоритма, которые отличают его от других популяционных методов оптимизации:
1. Кластеризация. Индивиды группируются в кластеры на основе их сходства расположения в пространстве поиска. Это реализовано с помощью алгоритма кластеризации K-means.
2. Сходимость (Convergence). На этом этапе индивиды внутри каждого кластера группируются вокруг центроида кластера. Это имитирует фазу мозгового штурма, когда участники собираются вместе, чтобы обсудить идеи.
3. Расходимость (Divergence). На этом этапе генерируются новые индивиды. Новые индивиды могут быть сгенерированы на основе одного или двух индивидов в кластере. Этот процесс имитирует фазу мозгового штурма, когда участники начинают думать вне рамок и предлагают новые идеи.
4. Выбор (Selection). После генерации новых индивидов они помещаются в основную родительскую группу, после чего производится сортировка группы. Соответственно на следующей итерации будет вестись работа с обновлёнными улучшенными идеями.
5. Мутация. После комбинирования идей и создания новых, все вновь созданные идеи подвергаются мутации, чтобы добавить дополнительное разнообразие в популяцию и предотвратить преждевременную сходимость.
Представим логику алгоритма BSO в виде псевдокода:
1. Инициализация параметров и генерация начальной популяции
2. Вычисление приспособленности каждого индивида в популяции
3. Пока не выполнены критерии остановки:
4. Вычисление приспособленности каждого индивида в популяции
5. Определение лучшего индивида в популяции
6. Разделение популяции на кластеры, установка лучшего решения в кластере в качестве центра кластера
7. Для каждого нового индивида в популяции:
|7.1. Если выполнена вероятность pReplace:
| |генерируется новый смещенный центр случайно выбранного кластера (центр кластера смещается)
|7.2. Если выполнена вероятность pOne:
| |Выбрать случайный кластер
| |Если выполнена вероятность pOne_center:
| | |7.2.a выбирается центр кластера
| |Иначе:
| |7.2.b выбирается случайный индивид из этого кластера
|7.3 Иначе:
| |Выбрать два кластера
| |Если выполнена вероятность pTwo_center:
| |7.3.a Новый индивид образуется путём слияния двух центров кластеров
| |Иначе:
| |7.3.b Создать нового индивида, путём слияния позиций выбранных двух индивидов из каждого выбранного кластера (кластеры должны быть разными)
|7.4 Мутация: Добавить случайное гауссово отклонение к позиции нового индивида
|7.5 Если новый индивид выходит за границы пространства поиска, отразить его обратно в пространство поиска
8. Обновить текущую популяцию новыми индивидами
9. Вернуться к шагу 4 до выполнения критерия останова
10. Вернуть лучшего индивида в популяции как решение
11. Конец работы BSO
Разберём операции на 7-м шаге в псевдокоде.
Самая первая операция 7.1, по сути, не создаёт нового индивида, но смещает центр кластера, от которого впоследствии могут быть созданы новые индивиды на других операциях алгоритма. Смещение происходит случайно по каждой координате с нормальным распределением на заданное во внешних параметрах расстояние от исходной позиции.
Операция 7.2 выполняет выбор либо центр кластера, либо индивида в выбранном кластере, с которым будет выполнена мутация на шаге 7.4 для создания нового индивида.
Операция 7.3 предназначена для создания нового индивида путём слияния либо центров двух случайно выбранных кластеров, либо двух индивидуумов из этих выбранных кластеров. Кластеры должны быть разными, но в случае, когда в наличии только один непустой кластер (кластеры могут быть пустыми), то операция слияния производится над двумя выбранными индивидуумами в этом единственном непустом кластере. Эта операция задумана как обмен идеями между кластерами идей.
Операция слияния заключается в следующем:
![]()
где:
Xf - новая особь после слияния,
v - случайное число от 0 до 1,
X1 и X2 - две случайные особи (или два центра кластеров), которые должны быть объединены.
Значение формулы слияния состоит в том, что будет создана идея в случайном месте между двумя другими идеями.
Операция мутации можем описать следующей формулой:
![]()
где:
Xm - новый индивид после мутации,
Xs - выбранный индивид, подлежащий мутации,
n(µ, σ) - гауссово случайное число со средним значением µ и дисперсией σ,
ξ - коэффициент мутации, выраженный математическим выражением.
Коэффициент мутации вычислим по формуле:
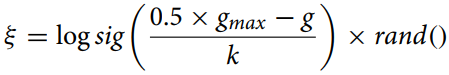
где:
gmax - максимальное количество итераций,
g - номер текущей итерации,
k - корректирующий коэффициент.
Эта формула (коэффициент мутации) используется для расчета сужающегося расстояния между индивидами в алгоритме оптимизации для адаптивного изменения параметра мутации. Функция "logsig()" обеспечивает плавное нелинейное уменьшение значения, а умножение на "rand" добавляет стохастический элемент, который может быть полезен для избежания преждевременной сходимости и поддержания разнообразия популяции.
Коэффициент коррекции "k" в алгоритме Brain Storm Optimization (BSO) играет важную роль в контролировании скорости изменения коэффициента "ξ" с течением времени. Значение "k" может варьироваться в зависимости от конкретной задачи и данных и вычисляется эмпирически или с помощью методов настройки гиперпараметров.
В общем случае, "k" должен быть выбран таким образом, чтобы обеспечить баланс между исследованием (exploration) и использованием (exploitation) в алгоритме. Если "k" слишком большой, то "ξ" будет изменяться очень медленно, что может привести к преждевременной сходимости алгоритма. Если "k" слишком маленький, то "ξ" будет изменяться очень быстро, что может привести к чрезмерному исследованию пространства поиска и замедлению сходимости.
Логарифмическая сигмоидная функция, также известная как логистическая функция, обычно обозначается как σ(x) или sig(x). Она вычисляется по следующей формуле:

где:
exp(-x) - обозначает экспоненту в степени -x.
1 / (1 + exp(-x)) обеспечивает выходное значение в диапазоне от 0 до 1.
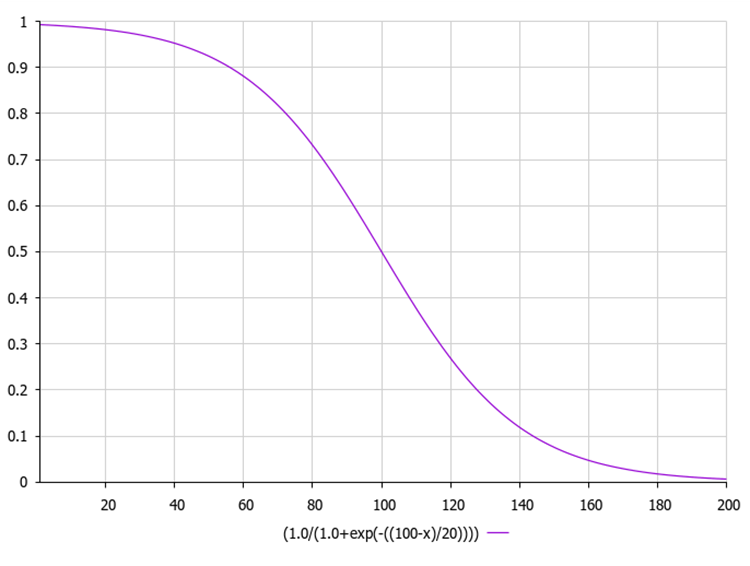
Ниже на рисунке представлен график сигмоидной функции. Неравномерное уменьшение функции обеспечивает исследование на ранних итерациях и уточнение на более поздних.
Ниже пример кода для расчета коэффициента мутации вместе с сигмоидной функцией, рассчитанной через экспоненту.
В этом коде функция "sigmoid" вычисляет сигмоидное значение входного числа "x", а функция "xi" вычисляет значение "ξ" согласно формуле выше. Здесь "gmax" - это максимальное количество итераций, "g" - это текущий номер итерации, и "k" - это коэффициент коррекции. Функция "MathRand" генерирует случайное число от 0 до 32767, поэтому мы делим его на 32767.0, чтобы получить случайное число от 0 до 1. Затем вычисляем сигмоидное значение этого случайного числа. Это значение возвращается функцией "xi".
double sigmoid(double x) { return 1.0 / (1.0 + MathExp(-x)); } double xi(int gmax, int g, double k) { double randNum = MathRand() / 32767.0; // Генерируем случайное число от 0 до 1 return sigmoid (0.5 * (gmax - g) / k) * randNum; }
3. Метод кластеризации K-Means
В алгоритме BSO для разделения идей на отдельные группы применяется метод кластерного анализа с использованием K-средних (K-Means). Текущее множество из "n" решений для ввода в итерацию разделяется на "m" категорий с целью имитировать поведение участников группового обсуждения и повысить эффективность поиска.
Отдельный кластер опишем структурой "S_Cluster", который реализует алгоритм K-средних, и является популярным методом кластеризации.
Давайте разберем структуру:
- centroid[] - массив, представляющий центроид кластера.
- f - Значение приспособленности центроида.
- count - количество точек в кластере.
- ideasList[] - список идей.
Функция "Init" инициализирует структуру, изменяя размер массивов "centroid" и "ideasList" и устанавливая начальное значение "f".
//—————————————————————————————————————————————————————————————————————————————— struct S_Cluster { double centroid []; //cluster centroid double f; //centroid fitness int count; //number of points in the cluster int ideasList []; //list of ideas void Init (int coords) { ArrayResize (centroid, coords); f = -DBL_MAX; ArrayResize (ideasList, 0, 100); } }; //——————————————————————————————————————————————————————————————————————————————
Класс C_BSO_KMeans представляет собой реализацию алгоритма K-средних для кластеризации агентов в алгоритме оптимизации BSO. Вот что делает каждый метод:
- KMeansInit - метод инициализирует центроиды кластеров, выбирая случайные агенты из данных. Для каждого кластера выбирается случайный агент, и его координаты копируются в центроид кластера.
- VectorDistance - метод вычисляет евклидово расстояние между двумя векторами. Он принимает два вектора в качестве аргументов и возвращает их евклидово расстояние.
- KMeans - метод выполняет основную логику алгоритма k-средних для кластеризации данных. Он принимает массив данных и массив кластеров в качестве аргументов.
- Назначение точек данных ближайшему центроиду.
- Обновление центроидов на основе среднего значения точек, назначенных каждому кластеру.
- Повторение этих двух шагов до тех пор, пока центроиды не перестанут меняться или не будет достигнуто максимальное количество итераций.
Центроид в методе кластеризации K-средних - это центральная точка кластера. В контексте метода K-средних центроид представляет собой среднее арифметическое всех точек данных, принадлежащих к данному кластеру.
В каждой итерации алгоритма K-средних центроиды пересчитываются, после чего точки данных снова группируются в кластеры в соответствии с тем, какой из новых центроидов оказался ближе по выбранной метрике.
Таким образом, центроиды играют ключевую роль в методе K-средних, определяя форму и положение кластеров.
Этот класс представляет собой ключевую часть алгоритма оптимизации BSO, обеспечивая кластеризацию агентов для улучшения процесса поиска. Алгоритм K-средних выполняет итеративное назначение точек кластерам и пересчет центроидов до тех пор, пока изменения не перестанут происходить или не будет достигнуто максимальное количество итераций.
//—————————————————————————————————————————————————————————————————————————————— class C_BSO_KMeans { public: //-------------------------------------------------------------------- void KMeansInit (S_BSO_Agent &data [], int dataSizeClust, S_Clusters &clust []) { for (int i = 0; i < ArraySize (clust); i++) { int ind = MathRand () % dataSizeClust; ArrayCopy (clust [i].centroid, data [ind].c, 0, 0, WHOLE_ARRAY); } } double VectorDistance (double &v1 [], double &v2 []) { double distance = 0.0; for (int i = 0; i < ArraySize (v1); i++) { distance += (v1 [i] - v2 [i]) * (v1 [i] - v2 [i]); } return MathSqrt (distance); } void KMeans (S_BSO_Agent &data [], int dataSizeClust, S_Clusters &clust []) { bool changed = true; int nClusters = ArraySize (clust); int cnt = 0; while (changed && cnt < 100) { cnt++; changed = false; //Assigning data points to the nearest centroid for (int d = 0; d < dataSizeClust; d++) { int closest_centroid = -1; double closest_distance = DBL_MAX; if (data [d].f != -DBL_MAX) { for (int cl = 0; cl < nClusters; cl++) { double distance = VectorDistance (data [d].c, clust [cl].centroid); if (distance < closest_distance) { closest_distance = distance; closest_centroid = cl; } } if (data [d].label != closest_centroid) { data [d].label = closest_centroid; changed = true; } } else { data [d].label = -1; } } //Updating centroids double sum_c []; ArrayResize (sum_c, ArraySize (data [0].c)); for (int cl = 0; cl < nClusters; cl++) { ArrayInitialize (sum_c, 0.0); clust [cl].count = 0; ArrayResize (clust [cl].ideasList, 0); for (int d = 0; d < dataSizeClust; d++) { if (data [d].label == cl) { for (int k = 0; k < ArraySize (data [d].c); k++) { sum_c [k] += data [d].c [k]; } clust [cl].count++; ArrayResize (clust [cl].ideasList, clust [cl].count); clust [cl].ideasList [clust [cl].count - 1] = d; } } if (clust [cl].count > 0) { for (int k = 0; k < ArraySize (sum_c); k++) { clust [cl].centroid [k] = sum_c [k] / clust [cl].count; } } } } } }; //——————————————————————————————————————————————————————————————————————————————
В алгоритме Brain Storm Optimization (BSO), приспособленность индивида определяется как качество решения, которое он представляет и в задаче оптимизации приспособленность может быть равна значению оптимизируемой функции.
Конкретный метод кластеризации может варьироваться. Один из распространенных подходов - это использование метода k-средних, где центроиды кластеров инициализируются случайным образом, а затем итеративно обновляются, чтобы минимизировать сумму квадратов расстояний от каждой точки до центроида ее кластера.
Важно отметить, что хотя приспособленность играет ключевую роль в процессе кластеризации, она не является единственным фактором, который влияет на формирование кластеров. Другие аспекты, такие как расстояние между индивидами в пространстве решений, также могут играть важную роль. Это помогает алгоритму поддерживать разнообразие в популяции и предотвращать преждевременную сходимость к неподходящим решениям.
Количество итераций, необходимых для сходимости алгоритма K-means, сильно зависит от различных факторов, таких как начальное состояние центроидов, распределение данных и количество кластеров. Однако в общем случае, K-means обычно сходится за несколько десятков до нескольких сотен итераций.
Также стоит учесть, что K-means минимизирует сумму квадратов расстояний от точек до их ближайших центроидов, что может быть не всегда оптимально в зависимости от конкретной задачи и формы кластеров в данных. В некоторых случаях другие алгоритмы кластеризации могут быть более подходящими.
K-means++ это улучшенная версия алгоритма K-means, предложенная в 2007 году Дэвидом Артуром и Сергеем Васильвицким. Основное отличие K-means++ от стандартного K-means заключается в способе инициализации центроидов. Вместо случайного выбора начальных центроидов, K-means++ выбирает их таким образом, чтобы максимизировать расстояние между ними. Это помогает улучшить качество кластеризации и ускоряет сходимость алгоритма.
Для информации приведу основные шаги инициализации в K-means++:
- Случайным образом выбрать первый центроид из точек данных.
- Для каждой точки данных вычислить ее расстояние до ближайшего, ранее выбранного центроида.
- Выбрать следующий центроид из точек данных таким образом, чтобы вероятность выбора точки в качестве центроида была прямо пропорциональна ее расстоянию до ближайшего, ранее выбранного центроида. (то есть точка, имеющая максимальное расстояние до ближайшего центроида, наиболее вероятно будет выбрана следующим центроидом).
- Повторите шаги 2 и 3, пока не будет выбрано k центроидов.
После инициализации центроидов, K-means++ продолжает работать так же, как стандартный алгоритм K-means. Этот метод инициализации помогает улучшить качество кластеризации и ускоряет сходимость алгоритма. Однако этот метод является затратным по вычислениям.
Если у вас есть 1000 координат для каждой точки, то это создаст дополнительные вычислительные затраты для алгоритма K-means++, поскольку он должен вычислять расстояния в пространстве с большой размерностью. Однако, K-means++ все еще может быть эффективным (необходимо проводить эксперименты для подтверждения предположения), поскольку он обычно приводит к более быстрой сходимости и лучшему качеству кластеров.
Стоит отметить, что при работе с данными высокой размерности (такими как 1000 координат) могут возникнуть дополнительные проблемы, связанные с "проклятием размерности". Это может сделать расстояния между точками менее значимыми и затруднить кластеризацию. В таких случаях может быть полезно использовать методы уменьшения размерности, такие как PCA (Principal Component Analysis), перед применением K-means или K-means++. Это может помочь уменьшить размерность данных и сделать кластеризацию более эффективной.
Уменьшение размерности данных - это важный шаг в обработке данных, особенно при работе с большим количеством координат или признаков. Это помогает упростить данные, уменьшить вычислительные затраты и улучшить производительность алгоритмов кластеризации. Вот некоторые методы уменьшения размерности, которые часто используются в кластеризации:
- Метод главных компонент (PCA). Этот метод преобразует набор данных с большим количеством переменных в набор данных с меньшим количеством переменных, сохраняя при этом максимальное количество информации.
- Многомерное шкалирование (MDS). Метод пытается найти структуру низкой размерности, которая сохраняет расстояния между точками, как в исходном пространстве высокой размерности.
- t-распределение стохастического соседа (t-SNE). Это нелинейный метод уменьшения размерности, который особенно хорош для визуализации данных высокой размерности.
- Автоэнкодеры. Это нейронные сети, которые используются для уменьшения размерности данных. Они работают, обучаясь кодировать входные данные в компактное представление, а затем декодировать это представление обратно в исходные данные.
- Метод независимых компонент (ICA). Это статистический метод, который преобразует набор данных в независимые компоненты, которые могут быть более информативными (могут лучше отражать структуру или важные аспекты данных, например, они могут делать видимыми некоторые скрытые факторы или позволять лучше разделить классы в задаче классификации), чем исходные данные.
- Линейный дискриминантный анализ (LDA). Метод используется для поиска линейных комбинаций признаков, которые хорошо разделяют два или более класса.
Так что, хотя K-means++ может быть более вычислительно затратным на этапе инициализации, особенно для данных высокой размерности, он все еще может быть оправдан в некоторых случаях. Но всегда стоит провести эксперименты и сравнить различные подходы, чтобы определить, что работает лучше всего для вашей конкретной задачи и набора данных.
Для тех, кто хотел бы поэкспериментировать дополнительно с методом K-means++, приведу метод инициализации для этого алгоритма (остальная часть кода не отличается от кода простого K-means).
Код ниже представляет собой реализацию инициализации алгоритма K-means++. Функция принимает массив точек данных, представленных структурой S_BSO_Agent, размер данных (dataSizeClust), и массив кластеров, представленных структурой S_Cluster. Метод инициализирует первый центроид случайным образом из точек данных. Затем для каждого последующего центроида алгоритм вычисляет расстояние от каждой точки данных до ближайшего центроида и выбирает следующий центроид с вероятностью, пропорциональной расстоянию. Это делается путем генерации случайного числа "r" в диапазоне от 0 до суммы всех расстояний, а затем прохода по всем точкам данных, уменьшая "r" на расстояние каждой точки, пока "r" не станет меньше или равным расстоянию текущей точки. В этом случае текущая точка выбирается в качестве следующего центроида. Этот процесс повторяется до инициализации всех центроидов.
В целом, реализована инициализация K-Means++, которая является улучшенной версией инициализации в стандартном алгоритме K-Means. Центроиды выбираются таким образом, чтобы минимизировать потенциальную сумму квадратов расстояний между центроидами и точками данных, что ведет к более эффективной и стабильной кластеризации.
void KMeansPlusPlusInit (S_BSO_Agent &data [], int dataSizeClust, S_Cluster &clust []) { // Choose the first centroid randomly int ind = MathRand () % dataSizeClust; ArrayCopy (clust [0].centroid, data [ind].c, 0, 0, WHOLE_ARRAY); for (int i = 1; i < ArraySize (clust); i++) { double sum = 0; // Compute the distance from each data point to the nearest centroid for (int j = 0; j < dataSizeClust; j++) { double minDist = DBL_MAX; for (int k = 0; k < i; k++) { double dist = VectorDistance (data [j].c, clust [k].centroid); if (dist < minDist) { minDist = dist; } } data [j].minDist = minDist; sum += minDist; } // Choose the next centroid with a probability proportional to the distance double r = MathRand () * sum; for (int j = 0; j < dataSizeClust; j++) { if (r <= data [j].minDist) { ArrayCopy (clust [i].centroid, data [j].c, 0, 0, WHOLE_ARRAY); break; } r -= data [j].minDist; } } }
Продолжение следует...
В данной статье мы рассмотрели логическую структуру алгоритма BSO, а также методы кластеризации и способы снижения размерности задачи оптимизации. В следующей статье мы завершим изучение алгоритма BSO и подведём итоги его производительности.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования