이 조건을 자동으로 재현하고 싶습니다. 때문에 찾을 필요가 없습니다. 나는 이미 그를 알고 있다. 그러나 예를 들어, 몇 가지 가중치 계수가 필요합니다. 특정 조합이 있을 때 높은 확률로 이 조건에 빠질 수 있습니다(다항식 또는 NS - 잘 모르겠습니다. 0) A, B, C를 대입하면 실행 원래 조건을 얻습니다.
가중치를 통해 이러한 원래의 조건을 재현할 수 있도록 원하는 함수는 어떤 입력 가중치를 갖고 있는지, 몇 개까지 입력할 수 있는지 궁금합니다.
이 조건을 자동으로 재현하고 싶습니다. 때문에 찾을 필요가 없습니다. 나는 이미 그를 알고 있다. 그러나 예를 들어, 몇 가지 가중치 계수가 필요합니다. 특정 조합이 있을 때 높은 확률로 이 조건에 빠질 수 있습니다(다항식 또는 NS - 잘 모르겠습니다. 0) A, B, C를 대입하면 실행 원래 조건을 얻습니다.
가중치를 통해 이러한 원래의 조건을 재현할 수 있도록 원하는 함수는 어떤 입력 가중치를 갖고 있는지, 몇 개까지 입력할 수 있는지 궁금합니다.
옵션으로
(A > B) && (A - B < C) && (A + 3 * C > 2 * B)
국회 입력에서 - 값 A, B, C n 번 (1000이라고 가정 해 봅시다), 출력에서 이러한 값에 대한 공식의 답은 0; 1입니다. 노력하다. 그리고 모델이 조건을 얼마나 잘 재현하는지 분류 오류를 확인하십시오.
어떤 보기와 해석을 정확히 확인해야 하는 경우 나무를 통해
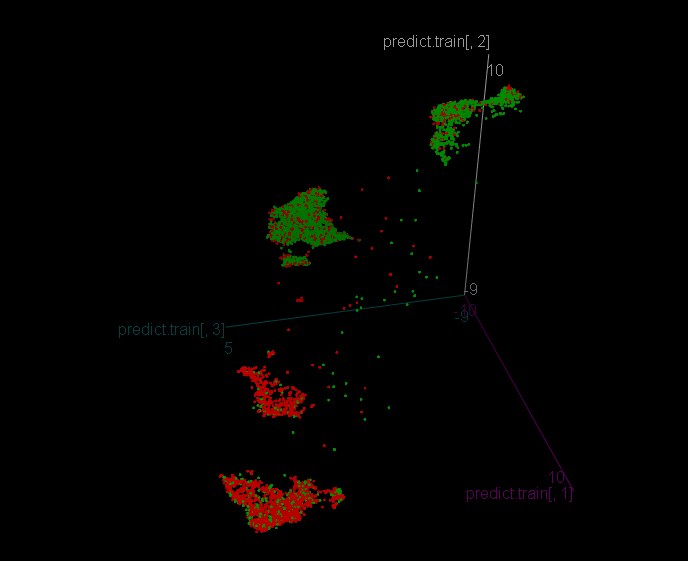
옵션 2(첫 번째 옵션이 제대로 작동하지 않은 경우) - A, B, AB, C, A + 3 * C, 2B - 변수, 모든 것은 첫 번째 옵션에서 트리로 운전하는 것과 동일합니다. 그리고 위의 사진에서 Alexei와 같은 구조를 볼 수 있습니다.
개인적인 대화에서
당신의 선택
일반 버전
값이 완전히 다른 것을 볼 수 있으므로 직접 확인할 수 있습니다.
나는 모델에
열이 하나뿐이므로 실제로는 중요하지 않습니다.
====================UPD
젠장, umap_tranform 실행할 때마다 다르며 동일해서는 안됩니다.
관심을 기울이지 않았다. 오래전 일이죠...
개인적인 대화에서
당신의 선택
일반 버전
값이 완전히 다른 것을 볼 수 있으므로 직접 확인할 수 있습니다.
나는 모델에
열이 하나뿐이므로 실제로는 중요하지 않습니다.
====================UPD
젠장, umap_tranform 실행할 때마다 다르며 동일해서는 안됩니다.
일반적으로 반복성을 위해 Seed(내장 RNG)를 일부 값으로 설정합니다. 그렇지 않은 경우 무작위로 가져옵니다. 이 패키지에는 Seed도 포함되어 있을 수 있습니다. 확인해 보세요.
예, 있다고 생각하지만 결론은 RNG가 없어도 항상 동일해야한다는 것입니다. 아날로그 패키지 "umap"에서 동일한 결과는 항상 동일합니다
특히 당신을 위해, 당신이 r-ku를 배울 것이라는 단 하나의 희망으로)
두 가지 기능이 있습니다
get .ind그리고
get .target첫 번째는 표시기에서 날짜 세트를 만들고 두 번째 것은 지그재그에서 대상 날짜를 만듭니다.
종가가 10k인 데이터를 로드하고 clos 변수에 쓰기만 하면 됩니다.
대상에서 umap을 가져옵니다.
https://github.com/jlmelville/uwot특히 당신을 위해, 당신이 r-ku를 배울 것이라는 단 하나의 희망으로)
두 가지 기능이 있습니다
그리고
첫 번째는 표시기에서 날짜 세트를 만들고 두 번째 것은 지그재그에서 대상 날짜를 만듭니다.
종가가 10k인 데이터를 로드하고 clos 변수에 쓰기만 하면 됩니다.
대상에서 umap을 가져옵니다.
https://github.com/jlmelville/uwot매우 즐거웠습니다. 감사합니다!
더 많은 의견이 좋을 것입니다 :)
여기서 질문은 파일의 예측자를 수신된 대상과 동기화하는 방법입니다.
매우 즐거웠습니다. 감사합니다!
더 많은 의견이 좋을 것입니다 :)
여기서 질문은 파일의 예측자를 수신된 대상과 동기화하는 방법입니다.
글쎄, 목표는 가격으로 구축되기 때문에 이미 동기화되어 있으며 동일한 장면에 대해 예측자가 구축되면 의미도 있습니다)
또는 질문을 이해하지 못했습니다
주석 없이 명확하게 변수의 이름을 지정하려고 했습니다.
멍청이의 질문입니다.
A, B, C의 세 가지 변수가 있습니다. 일부 조건은 손으로 구성됩니다. 예를 들어.
이 조건을 자동으로 재현하고 싶습니다. 때문에 찾을 필요가 없습니다. 나는 이미 그를 알고 있다. 그러나 예를 들어, 몇 가지 가중치 계수가 필요합니다. 특정 조합이 있을 때 높은 확률로 이 조건에 빠질 수 있습니다(다항식 또는 NS - 잘 모르겠습니다. 0) A, B, C를 대입하면 실행 원래 조건을 얻습니다.
가중치를 통해 이러한 원래의 조건을 재현할 수 있도록 원하는 함수는 어떤 입력 가중치를 갖고 있는지, 몇 개까지 입력할 수 있는지 궁금합니다.
그래서, 클러스터에서 나무를 훈련시키는 것이 어떻게 밝혀 졌는지 말하고 보여줍니다.
클래스 인식을 위한 결과 모델
기록에 따르면 정확도는 0.9196756으로 매우 정확합니다. 클러스터 논리는 매우 재현 가능합니다.
그런 다음 모델에 따라 각 클러스터에 대해 학습
클러스터 1
클러스터 2
클러스터 3
클러스터 4
모든 클러스터의 정확도는 대략 0.53입니다.
그리고 이것은 클러스터로 분할되지 않은 모델의 모습입니다.
정확도 0.5293815 - 클러스터와 거의 동일합니다.
클러스터 모델과 하나의 트리 모델을 전체 샘플과 비교하면 클러스터 트리에 목표 1과 -1이 있는 일반화된 샘플 정보가 있는 더 많은 잎이 있음을 알 수 있습니다. 이는 이론적으로 좋습니다.
테스트 결과를 살펴보겠습니다. 먼저 교육 기간을 살펴보겠습니다.
클러스터링이 없는 모델:
클러스터링 모델:
클러스터가 없는 모델의 정확도가 더 좋지만 클러스터의 모델에 대해 더 많은 거래가 있으므로 더 나은 재무 성과를 달성할 수 있습니다.
이제 훈련 외부의 샘플을 살펴보겠습니다.
다음은 클러스터입니다.
클러스터가 없는 모델:
여기에서 상황이 역전된 것으로 보입니다. 4월 이후 시장이 요동치기 시작했을 때 많은 거래가 해로운 영향을 미쳤습니다.
클러스터가 없는 경우 히스토그램에서 내림차순으로 클러스터 모델의 잎을 별도로 보기로 결정했습니다.
일반적으로 수익성이 없는 목록은 6개뿐입니다(제로 대상을 제거했습니다. 이것은 진입 금지입니다). 우리가 원하는 클러스터에 속하지 않는 것으로 나타났습니까?
글쎄, 목표는 가격으로 구축되기 때문에 이미 동기화되어 있으며 동일한 장면에 대해 예측자가 구축되면 의미도 있습니다)
또는 질문을 이해하지 못했습니다
주석 없이 명확하게 변수의 이름을 지정하려고 했습니다.
예측자와 종가 가 있는 날짜 집합을 가져와서 종가가 있는 열로 로드하고 R에서 표시기 생성 옵션을 사용하지 않는 방법은 무엇입니까?
내가 이해하는 것처럼 대상은 ZZ 정점이므로 예측자가 있는 샘플의 일부를 필터링해야 합니다. 따라서 예측자를 제공하려면 예측자가 있는 테이블도 필터링해야 합니다.
멍청이의 질문입니다.
A, B, C의 세 가지 변수가 있습니다. 일부 조건은 손으로 구성됩니다. 예를 들어.
이 조건을 자동으로 재현하고 싶습니다. 때문에 찾을 필요가 없습니다. 나는 이미 그를 알고 있다. 그러나 예를 들어, 몇 가지 가중치 계수가 필요합니다. 특정 조합이 있을 때 높은 확률로 이 조건에 빠질 수 있습니다(다항식 또는 NS - 잘 모르겠습니다. 0) A, B, C를 대입하면 실행 원래 조건을 얻습니다.
가중치를 통해 이러한 원래의 조건을 재현할 수 있도록 원하는 함수는 어떤 입력 가중치를 갖고 있는지, 몇 개까지 입력할 수 있는지 궁금합니다.
옵션으로
국회 입력에서 - 값 A, B, C n 번 (1000이라고 가정 해 봅시다), 출력에서 이러한 값에 대한 공식의 답은 0; 1입니다. 노력하다. 그리고 모델이 조건을 얼마나 잘 재현하는지 분류 오류를 확인하십시오.
어떤 보기와 해석을 정확히 확인해야 하는 경우 나무를 통해
옵션 2(첫 번째 옵션이 제대로 작동하지 않은 경우) - A, B, AB, C, A + 3 * C, 2B - 변수, 모든 것은 첫 번째 옵션에서 트리로 운전하는 것과 동일합니다. 그리고 위의 사진에서 Alexei와 같은 구조를 볼 수 있습니다.