Bu kaosun bir düzeni var mı? Hadi bulmaya çalışalım! Belirli bir örnek üzerinde makine öğrenimi. - sayfa 11
Alım-satım fırsatlarını kaçırıyorsunuz:
- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Kayıt
Giriş yap
Gizlilik ve Veri Koruma Politikasını ve MQL5.com Kullanım Şartlarını kabul edersiniz
Hesabınız yoksa, lütfen kaydolun
Mesele de bu zaten, 5000+ özelliklere kıyasla 2 kat daha iyi.
Diğer tüm 5000+ çiplerin sadece sonucu kötüleştirdiği ortaya çıkıyor. Yine de onları seçerseniz, kesinlikle bazı iyileştirici olanlar bulacaksınız.
Modelinizin bu 2'de ne göstereceğini karşılaştırmak ilginçtir.
Matım var. beklenti birden biraz fazla, 5 bin içinde kar, doğruluk% 51 yazıyor - yani sonuçlar açıkça daha kötü.
Evet ve test örneğinde 100 modelin hepsinde zarar ettim.Matım var. beklenti birden biraz fazla, 5 bin içinde kar, doğruluk% 51 diyor - yani sonuçlar açıkça daha kötü.
Evet ve test örneğinde 100 modelin hepsinde bir kayıp vardı.Ama ilkinde de kaybediyor.
İkinci H1 örneğinde mi? Onda ilerleme kaydediyorum.
Ve ilkinde de kaybediyorum.
Evet, H1 örneğinden bahsediyorum. Başlangıçta train.csv üzerinde eğitildim, test.csv üzerinde durdum ve exam.csv üzerinde bağımsız kontrol yaptım, bu nedenle iki sütunlu varyant test.csv üzerinde başarısız oldu. Dünkü varyantlar da dökülüyordu, ancak biraz para kazananlar da vardı.
Elinizde ne tür mucize grafikler var?Ve bu, 10000 satırda 20000 satırda eğitim ile valvingin nasıl ilerlediğidir. Yani, grafik 2 yılı değil, 5 yılı göstermektedir. Bunların 2 yılı düşüşte oturmak zorunda kalacak, ardından karsız bir yıl daha, çünkü ortalama kazanç yine işlem başına 0.00002'ye düştü. Ticaret için de iyi değil.
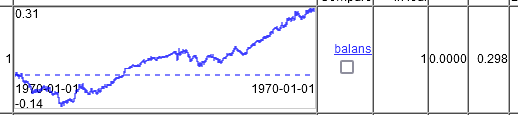
Sadece 2 zaman sütununda.
5000+ sütunun tamamında aynı ayarlar. Biraz daha iyi. İşlem başına 0,00003.
İşlem başına ortalama 0,00004 olmak üzere 0,20600 kâr. Spread ile orantılı
Evet, rakam zaten etkileyici. Bununla birlikte, hedef satmak için işaretlenmiştir ve orada büyük bir TF'deki tüm dönem satılmaktadır, bence sonucu da yapay olarak iyileştirmektedir.
Tüm sütunlarda 0.00002'den fazladır, ancak daha önce de söylediğim gibi "Spread, kaymalar vb. tüm kazancı yiyecektir". Teriminal, çubuk başına minimum spread'i gösterir (yani tüm saat boyunca), ancak bir ticaret anında 5 - 10 pts olabilir ve haberlerde 20 ve daha yüksek olabilir.
Yani elimdeki işaretleme dakika çubuklarında alınıyor, spreadler genellikle belirli bir süre boyunca genişliyor, yani bir dakika içinde muhtemelen her zaman büyük bir spread olacak, yoksa şimdi öyle değil mi? 5'te spread'in nasıl çalıştığını bile anlamadım - 4'teki testler için daha uygun buluyorum.
İşlem başına ortalama kazancı en az 0,00020 olan modeller aramalısınız. O zaman gerçek ticarette 0.00010 alabilirsiniz. Bu EURUSD içindir, AUD NZD gibi diğer çiftlerde 50 pts bile yeterli olmayacaktır, spreadler 20-30 pts'dir.
Katılıyorum. Bu konudaki ilk örnek 30 piplik bir mat beklentisi veriyor. Bu yüzden hala işaretlemenin akıllı olması gerektiği fikrine bağlıyım.
Yine sınav örneğindeki en iyi grafik bu. Sınavda en iyi dengeyi sağlayacak ayarların trayne tarafından nasıl seçileceği, çözümü olmayan bir sorudur. Teste göre seçim yaparsınız. Ben traine+test üzerine eğitim aldım. Temel olarak, sizin bir sınavınız varsa, benim de bir testim var.
Bence örneklemin çoğunluğunun seçim eşiğini geçmesini sağlayarak başlamalısınız. Ayrıca, en az eğitilmiş modeli seçmek mantıklı olabilir - daha az uyuma sahiptir.
Ve bu, 10000 satırda 20000 satır üzerinde eğitim ile ileriye doğru yuvarlanma şeklidir. Yani grafikte 2 yıl değil, 5 yıl. Bunların 2 yılı düşüşte oturmak zorunda kalacak, ardından karsız bir yıl daha, bu nedenle ortalama kazanç yine işlem başına 0.00002'ye düştü. Ticaret için de iyi değil.
Sadece 2 zaman sütununda.
5000+ sütunun tamamında aynı ayarlar. Biraz daha iyi. İşlem başına 0,00003.
Yine de, diğer tahmin edicilerin de yararlı olabileceği ortaya çıkıyor. Bunları gruplar halinde eklemeyi deneyebilir, önce korelasyon için eleme yapabilir ve bunları biraz azaltabilirsiniz.
Beklenti matrisi ile ilgili olarak, belki de bu stratejide mum açılışıyla değil, açılış fiyatından aynı 30 pip ile girmek daha karlı - kuyruksuz mumlar nadirdir.
Yani elimdeki işaretleme dakika çubukları üzerinden alınıyor, spreadler genellikle belirli bir süre içinde genişliyor, yani bir dakika içinde muhtemelen her zaman büyük bir spread olacak, yoksa şimdi öyle değil mi? 5'te spread'in nasıl çalıştığını bile anlamadım - benim için 4'teki testler için daha uygun.
Ve M1'de de çubuk süresi için minimum spread tutulur. ECH hesaplarında neredeyse tüm M1 çubukları 0.00001...0.00002 nadiren daha fazlasına sahiptir. Tüm üst düzey çubuklar M1'den oluşturulur, yani aynı minimum yayılma olacaktır. Tur başına 4 pts. komisyon eklemeniz gerekir (diğer aracı kurum merkezlerinin başka komisyonları olabilir).
Yine de, diğer tahmin edicilerin de yararlı olabileceği ortaya çıkıyor. Bunları gruplar halinde eklemeyi deneyebilir, önce korelasyon için eleyebilir ve biraz azaltabilirsiniz.
Belki de onları seçmeliyiz. Ancak 2'ye 5000+ eklemek küçük bir iyileştirme katıyorsa, model eğitimi ile tam kaba kuvvetle 10 adet seçmek daha hızlı olabilir. Korelasyon için 24 saat beklemekten daha hızlı olacağını düşünüyorum. Sadece yeniden eğitimi bir döngü içinde doğrudan terminalden otomatikleştirmek gerekiyor.
Katbusta'nın DLL versiyonu yok mu? DLL doğrudan terminalden çağrılabilir. Burada örnekleri olan bir makale vardı. https://www.mql5.com/ru/articles/18 ve https://www.mql5.com/ru/articles/5798.
Belki de seçmeliyiz. Ancak 2'lere 5000+ eklemek küçük bir iyileşme sağlarsa, model eğitimi ile tam kaba kuvvetle 10 parça seçmek daha hızlı olabilir. Bence 24 saat boyunca korelasyon beklemekten daha hızlı olacaktır.
Evet, başlangıçta gruplar halinde yapmak daha iyidir - örneğin 10 grup yapabilir ve bunların kombinasyonlarıyla eğitebilir, modelleri değerlendirebilir, en başarısız grupları eleyebilir ve kalanları yeniden gruplandırabilirsiniz, yani gruptaki tahminci sayısını azaltabilir ve tekrar eğitebilirsiniz. Bu yöntemi daha önce kullandım - etkisi var, ancak yine hızlı değil.
Yalnızca doğrudan terminalden bir döngü içinde yeniden eğitimi otomatikleştirmeniz gerekir.
Catbust'ın DLL sürümü yok mu? DLL doğrudan terminalden çağrılabilir. Burada örnekleri olan bir makale vardı. https://www.mql5.com/ru/articles/18 ve https://www.mql5.com/ru/articles/5798.
Heh, terminal üzerinden tam öğrenme kontrolü elde etmek güzel olurdu, ancak anladığım kadarıyla hazır bir çözüm yok. Sadece modeli uygulayan bir catboostmodel.dll kütüphanesi var, ancak MQL5'te nasıl uygulanacağını bilmiyorum. Teorik olarak, elbette, eğitim için bir kütüphane şeklinde bir arayüz yapmak mümkün - kod açık, ancak bunu karşılayamam.
Evet, gruplarla başlamak daha iyidir - örneğin 10 grup oluşturabilir ve bunları kombinasyonlar halinde eğitebilir, modelleri değerlendirebilir, en başarısız grupları eleyebilir ve kalanları yeniden gruplandırabilirsiniz, yani gruptaki tahminci sayısını azaltabilir ve tekrar eğitebilirsiniz. Bu yöntemi daha önce kullandım - etkisi var, ancak yine hızlı değil.
Ben başka bir şey öneriyorum. Özellikleri modele tek tek ekliyoruz. Ve en iyilerini seçiyoruz.
1) 5000+ modeli bir özellik üzerinde eğitin: 5000+ özelliğin her biri. Testten en iyisini alın.
2) 2 özellik üzerinde (5000+ -1) model eğitin: 1. en iyi özellik ve( 5000+ -1) kalanlar. En iyi ikinci özelliği bulun.
3) (5000+ -2) modeli 3 özellik üzerinde eğitin: 1., 2. en iyi özellik ve( 5000+ -2) kalanlar. Üçüncü en iyiyi bulun.
Model gelişene kadar tekrarlayın.
Genellikle 6-10 özellik ekledikten sonra modeli geliştirmeyi bıraktım. Siz de 10-20'ye veya eklemek istediğiniz özellik sayısına kadar çıkabilirsiniz.
Ancak teste göre özellik seçmenin, modeli verilerin test bölümüne uydurmak olduğunu düşünüyorum. Ağırlığı 0,3 olan trayne ve ağırlığı 0,7 olan test ile seçimin bir çeşidi vardır. Ancak bunun da bir uyum olduğunu düşünüyorum.
Ruloyu ileriye doğru yapmak istedim, o zaman montaj birçok test bölümü için olacak, saymak daha uzun sürecek, ama bana öyle geliyor ki bu en iyi seçenek.
Catbusters'ı çalıştırmak için otomasyonunuz olmasa da.... 50+ bin kez 10 özellik elde etmek için modelleri manuel olarak yeniden eğitmek zor olacaktır.Kabaca bu yüzden kendi teknemi catbust'a tercih ediyorum. Cutbust'tan 5-10 kat daha yavaş çalışmasına rağmen. Senin 3 dakika boyunca bir modelin vardı, benim 22.
Benim önerdiğim bu değil. Özellikleri modele teker teker ekliyoruz. Ve en iyilerini seçiyoruz.
1) 5000+ modeli bir özellik üzerinde eğitin: 5000+ özelliğin her biri. Testten en iyisini alın.
2) 2 özellik üzerinde (5000+ -1) model eğitin: 1. en iyi özellik ve( 5000+ -1) kalanlar. En iyi ikinci özelliği bulun.
3) (5000+ -2) modeli 3 özellik üzerinde eğitin: 1., 2. en iyi özellik ve( 5000+ -2) kalanlar. Üçüncü en iyiyi bulun.
Model gelişene kadar tekrarlayın.
Genellikle 6-10 özellik ekledikten sonra modeli geliştirmeyi bıraktım. Siz de 10-20'ye veya eklemek istediğiniz özellik sayısına kadar çıkabilirsiniz.
Yaklaşımlar farklı olabilir - özleri genel olarak aynıdır, ancak dezavantaj elbette ortaktır - çok yüksek hesaplama maliyetleri.
Ancak teste göre özellik seçiminin, modelin verilerin test bölümüne uydurulması olduğunu düşünüyorum. Ağırlığı 0,3 olan trayne ve ağırlığı 0,7 olan test ile seçimin bir çeşidi vardır. Ancak bunun da bir uyum olduğunu düşünüyorum.
Valfleri ileriye doğru yapmak istiyorum, o zaman bağlantı birçok test bölümü için olacak, hesaplanması daha uzun sürecek, ancak bana en iyi seçenek bu gibi görünüyor.
Bu nedenle, özelliğin seçimini haklı çıkarmak için içinde bazı rasyonel taneler arıyorum. Şimdiye kadar olayların tekrarlanma sıklığına ve sınıf olasılığını değiştirmeye karar verdim. Ortalama olarak, etki olumludur, ancak bu yöntem, korelasyonlu tahmin edicileri dikkate almadan, aslında ilk bölünmeye göre değerlendirir. Ancak bence aynı yöntemi ikinci bölünme için de denemelisiniz, güçlü negatif yatkınlığa sahip tahminci puanları üzerindeki satırları örneklemden çıkararak.
Her ne kadar catbusters.... çalıştırmak için otomasyonunuz olmasa da 10 özellik elde etmek için modelleri 50+ bin kez manuel olarak yeniden eğitmek zor olurdu.
Kabaca bu yüzden zanaatımı catbust'a tercih ediyorum. Cutbust'tan 5-10 kat daha yavaş çalışmasına rağmen. Senin sayması 3 dakika süren bir modelin vardı, benimse 22.
Yine de yazımı okuyun.... Şimdi her şey yarı otomatik olarak çalışıyor - görevler oluşturuluyor ve bootnik başlatılıyor (eğitimde kullanılacak özelliklerin sayısı için görevler dahil, yani tüm varyantları bir kerede oluşturabilir ve başlatabilirsiniz). Özünde, terminale bat dosyasını çalıştırmayı öğretmek gerekir, ki bence bu mümkün ve eğitimin sonunu kontrol etmek, ardından sonucu analiz etmek ve sonuçlara göre başka bir görev çalıştırmak.
Sadece öğrenme oranını değiştirerek 100 modelden kriter setini karşılayan iki model elde edebildi.
Birincisi.
İkincisi.
Evet, CatBoost'un çok şey yapabildiği ortaya çıktı, ancak ayarları daha agresif bir şekilde ayarlamak gerekli görünüyor.
Bu modelleri sınavda en iyi olanlara göre mi seçiyorsunuz?
Yoksa sınavda en iyi olanlardan oluşan bir set arasından mı?