Bayesian regresyon - Bu algoritmayı kullanarak Uzman Danışman yapan var mı? - sayfa 40
Ticaret fırsatlarını kaçırıyorsunuz:
- Ücretsiz ticaret uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Kayıt
Giriş yap
Gizlilik ve Veri Koruma Politikasını ve MQL5.com Kullanım Şartlarını kabul edersiniz
Hesabınız yoksa, lütfen kaydolun
Ve ruhum hala sözde normal olarak dağılmış alıntı artışları konusunu kazmak istiyor.
Birisi "için" konuşursa, bu sürecin neden normal olamayacağına dair argümanlar vereceğim. Ayrıca bunlar, CLT ile koordine edilecek, herkes tarafından anlaşılabilir argümanlar olacaktır. Ve bu argümanlar o kadar banal ki, hiçbir şüphe olmamalı.
Ve olasılık ne ifade edecek, en yakın çubuk için tahmin veya en yakın çubukların hareket vektörü?
Olasılık, bir sonraki tik (artış) tahminini ifade edecektir. Sadece istiyorum:
- Bayes formülüne göre olasılığın maksimum olacağı gelecekteki Ybayes kenelerinin değerlerini hesaplayın.
- Ybay'leri gelen gerçek Yreal keneleriyle karşılaştırın. İstatistikleri toplayın ve işleyin.
Değerler arasındaki fark makul ise, kodu göndereceğim ve bundan sonra ne yapacağımı soracağım. Gerileme? Vektör? Krivulka mı? kafa derisi soyma?
Olasılık, bir sonraki tik (artış) tahminini ifade edecektir. Sadece istiyorum:
Ve neden kenelere inelim? 5 dakikada %70 doğrulukla kenelerin yönünü tahmin etmeyi öğrenebilirsiniz, ancak 100 tık ileride, anlıyorsunuz, doğruluk düşecek.
Yarım saat veya bir saat ilerideki artışları deneyin. Bu benim için ilginç, belki bir konuda yardımcı olabilirim.
Olasılık, bir sonraki tik (artış) tahminini ifade edecektir. Sadece istiyorum:
- Bayes formülüne göre olasılığın maksimum olacağı gelecekteki Ybayes kenelerinin değerlerini hesaplayın.
- Ybay'leri gelen gerçek Yreal keneleriyle karşılaştırın. İstatistikleri toplayın ve işleyin.
Değerler arasındaki fark makul ise, kodu göndereceğim ve bundan sonra ne yapacağımı soracağım. Gerileme? Vektör? Krivulka mı? kafa derisi soyma?
ARIMA'nın nesi var? Gruplar halinde, giriş akışına bağlı olarak türevlerin sayısı (artış artışları) otomatik olarak hesaplanır. Durağanlıkla ilgili pek çok incelik paketin içinde saklı.
Gerçekten daha derine inmek istiyorsanız, o zaman biraz ARCH?
Bir kez denendi. Sorun şu. Artış kolayca hesaplanabilir. Ancak bu artışın güven aralığını artışın kendisine eklersek, önceki fiyat değeri güven aralığı içinde kaldığından AL veya SAT.
Evet, SanSanych'in yazdığı gibi klasik yaklaşım, veri analizi, veri gereksinimleri ve sistem hatalarını hatırlamaktır.
Ama bu konu Bayes ile ilgili ve ben Bayesci düşünmeye çalışıyorum, siperdeki o asker gibi arka (deneyimden sonra) olasılığı hesaplıyor. Yukarıda bir askerle ilgili örnek verdim.
Ana sorulardan biri, a priori olasılık için ne alınması gerektiğidir. Başka bir deyişle, geleceğin perdesinin arkasına kim koyacak, sıfır çubuğunun sağında. Gauss? Laplace? Sosis mi? Profesyonel matematikçiler burada ne yazıyor (benim için karanlık "orman")?
Gauss'u seçtim çünkü ilk önce normal dağılım hakkında bir fikrim var ve ikinci olarak buna inanıyorum. “Ateş etmezse”, diğer yasaları alıp Bayes formülüne Gauss yerine veya Gauss ile birlikte iki olasılığın bir ürünü olarak koyabilirsiniz. Doğru anladıysam bir Bayes ağı oluşturmaya çalışın.
Tabii ki, bunu tek başıma yapamam. Buketin altında formüle ettiğim görevde Gauss ile başa çıkacaktım. Gönüllü olarak katılmak isteyen varsa - bekliyoruz. İşte güncel bir soruna bir örnek.
Verilen: Normal MT4 rastgele sayı üreteci.
Gerekli: Normal RNG tarafından oluşturulan MT4[] dizisini normal dağılımlı ND[] dizisine dönüştürmek için MQL4 kodunu FP() işlevi biçiminde yazın.
Dönüşüm formülleri https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/ Vasily (soy adını bilmiyorum) Sokolov tarafından gösterildi.
Nezaket ve fedakarlığın yüksekliği, sonuçların grafiksel bir gösterimi olacaktır, ancak hesaplanan diziler için grafikler doğrudan MT4 penceresinde ölçeklenebilir ve ben de ölçekleyebilirim. Projelerimde bunu yaptım.
Buradaki birçok kişinin bu sorunu iki tıklama ile bir matta çözeceğini anlıyorum. paketler, ancak genellikle tüccarlar, programcılar, ekonomistler ve filozoflar için erişilebilir olan MQL4 dilini konuşmak istiyorum.
Evet, SanSanych'in yazdığı gibi klasik yaklaşım, veri analizi, veri gereksinimleri ve sistem hatalarını hatırlamaktır.
Ama bu konu Bayes ile ilgili ve ben Bayesci düşünmeye çalışıyorum, siperdeki o asker gibi arka (deneyimden sonra) olasılığı hesaplıyor. Yukarıda bir askerle ilgili örnek verdim.
Ana sorulardan biri, a priori olasılık için ne alınması gerektiğidir. Başka bir deyişle, geleceğin perdesinin arkasına kim koyacak, sıfır çubuğunun sağında. Gauss? Laplace? Sosis mi? Profesyonel matematikçiler burada ne yazıyor (benim için karanlık "orman")?
Gauss'u seçtim çünkü ilk önce normal dağılım hakkında bir fikrim var ve ikinci olarak buna inanıyorum. “Ateş etmezse”, diğer yasaları alıp Bayes formülüne Gauss yerine veya Gauss ile birlikte iki olasılığın bir ürünü olarak koyabilirsiniz. Doğru anladıysam bir Bayes ağı oluşturmaya çalışın.
Tabii ki, bunu tek başıma yapamam. Buketin altında formüle ettiğim görevde Gauss ile başa çıkacaktım. Gönüllü olarak katılmak isteyen varsa - bekliyoruz. İşte güncel bir soruna bir örnek.
Verilen: Normal MT4 rastgele sayı üreteci.
Gerekli: Normal RNG tarafından oluşturulan MT4[] dizisini normal dağılımlı ND[] dizisine dönüştürmek için MQL4 kodunu FP() işlevi biçiminde yazın.
Dönüşüm formülleri https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/ Vasily (soy adını bilmiyorum) Sokolov tarafından gösterildi.
Nezaket ve fedakarlığın yüksekliği, sonuçların grafiksel bir görüntüsü olacaktır, ancak hesaplanan diziler için grafikler doğrudan MT4 penceresinde ölçeklenebilir ve ölçeklenebilir. Projelerimde bunu yaptım.
Buradaki birçok kişinin bu sorunu iki tıklama ile bir matta çözeceğini anlıyorum. paketler, ancak genellikle tüccarlar, programcılar, ekonomistler ve filozoflar için erişilebilir olan MQL4 dilini konuşmak istiyorum.
Normal dağılım da dahil olmak üzere farklı dağılımlara sahip bir jeneratör:
https://www.mql5.com/en/articles/273
R dilinde dağılımın kısa bir analizi:
# load data fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv' , sep= ',' , header = T , na.strings = 'NULL') fx_dat <- subset(fx_data, Volume > 0) # create open price returns dat_return <- diff(x = fx_dat[, 2], lag = 1) # check summary for the returns summary(dat_return) Min. 1st Qu. Median Mean 3rd Qu. Max. -2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02 # generate random normal numbers with parameters of original data norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return)) #check summary for generated data summary(norm_generated) Min. 1st Qu. Median Mean 3rd Qu. Max. -8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03 # test normality of original data shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)]) Shapiro-Wilk normality test data: dat_return[sample(length(dat_return), 4999, replace = F)] W = 0.86826, p-value < 2.2e-16 # test normality of generated normal data shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)]) Shapiro-Wilk normality test data: norm_generated[sample(length(norm_generated), 4999, replace = F)] W = 0.99967, p-value = 0.6189Saatlik çubukların açılış fiyatlarındaki mevcut artışlar için normal dağılım parametrelerini tahmin ettik ve orijinal seri ve aynı dağılımlarla normal için frekans ve yoğunluğu karşılaştırmak için gösterdik. Gözle bile görebileceğiniz gibi, orijinal saatlik çubuk artışları dizisi normalden çok uzaktır.
Ve bu arada, Tanrı'nın tapınağında değiliz. İnanmak isteğe bağlıdır ve hatta zararlıdır.
İşte yukarıdaki yazıdan, yukarıda yazdıklarımı yansıtan ilginç bir satır
-2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02
Kadranlarda anladığım kadarıyla, tüm saatlik artışların %50'si 7 pipten az! Ve daha iyi artışlar kalın kuyruklarda, yani. iyinin ve kötünün diğer tarafında.
Ve TS nasıl görünecek? Bütün sorun bu, Bayes değil vesaire...
Yoksa başka bir şekilde mi anlaşılmalı?
İşte yukarıdaki yazıdan, yukarıda yazdıklarımı yansıtan ilginç bir satır
-2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02
Kadranlarda anladığım kadarıyla, tüm saatlik artışların %50'si 7 pipten az! Ve daha iyi artışlar kalın kuyruklarda, yani. iyinin ve kötünün diğer tarafında.
Ve TS nasıl görünecek? Bütün sorun bu, Bayes değil vesaire...
Yoksa başka bir şekilde mi anlaşılmalı?
San Sanych, evet!
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')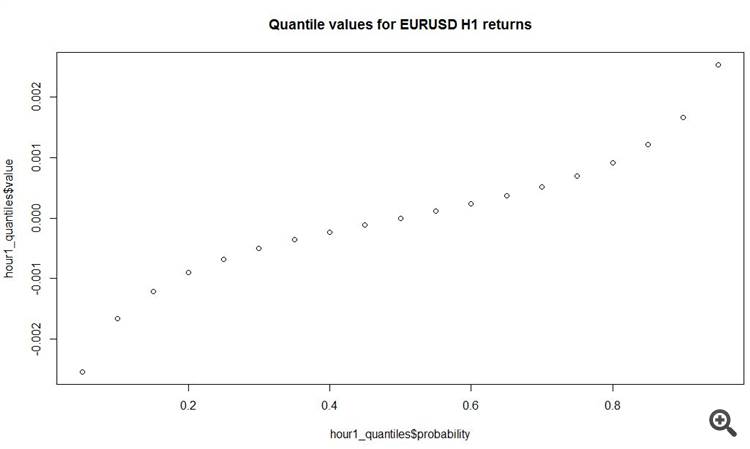
Ve bir ilginç şey daha - saatlik çubuklardaki ortalama mutlak artış 11 puandır! Toplam.
Hastalanmak uzun zaman alacak, çünkü hem yeniden dönüşüme ihtiyacınız var hem de ..., ama Box-Cox'tan gerçekten hoşlanmıyorum))) Olmazsa üzücü
normal tahminciler, bunun nihai sonuç üzerinde çok az etkisi olacaktır ...