"Новый нейронный" - проект Open Source движка нейронной сети для платформы MetaTrader 5. - страница 56
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Да, именно это и хотел узнать.
to mql5
ЗЫ сейчас больше всего волнует нужно ли будет копировать данные в специальные процессорные массивы или будут поддерживаться передача массива как параметр в обычной функции. Этот вопрос может принципиально изменить весь проект.
ЗЗЫ можете ответить в планах просто дать API OpenCL, или планируете оборачивать его в свои обёртки?
2) Будет обёртка, поддерживаться будут только HW GPU (с поддержкой OpenCL 1.1).
Выбор из нескольких GPU если будет, то только через настройки терминала.
OpenCL будет использоваться синхронно.
Да, именно это и хотел узнать.
to mql5
ЗЫ сейчас больше всего волнует нужно ли будет копировать данные в специальные процессорные массивы или будут поддерживаться передача массива как параметр в обычной функции. Этот вопрос может принципиально изменить весь проект.
ЗЗЫ можете ответить в планах просто дать API OpenCL, или планируете оборачивать его в свои обёртки?
Судя по:
mql5:
Фактически можно будет пользоваться функциями библиотеки OpenCL.dll напрямую, без необходимости подключать сторонние DLL.
можно будет пользоваться функциями OpenCL.dll так, как будто это родные функции MQL5, а компилятор сам будет осуществлять перенаправления вызовов.
Исходя из этого можно сделать вывод, что функции OpenCL.dll можно закладывать уже сейчас (вызовы-пустышки).
Renat и mql5, правильно ли я понял "обстановку"?
Судя по:
можно будет пользоваться функциями OpenCL.dll так, как будто это родные функции MQL5, а компилятор сам будет осуществлять перенаправления вызовов.
Исходя из этого можно сделать вывод, что функции OpenCL.dll можно закладывать уже сейчас (вызовы-пустышки).
Renat и mql5, правильно ли я понял "обстановку"?
Пока что у меня вырисовывается вот такая схема проекта:
Объекты прямоугольники, методы эллипсы.методы процессинга разделяются на 4 категории:
этими четырьмя методами описывается весь процессинг по всем слоям, методы импортируются в процессинг через объекты методов, которые наследуются от базового класса и перегружаются по необходимости в зависимости от типа нейрона.
Николай, знаешь такую крылатую фразу -- преждевременная оптимизация -- это корень всех зол.
Забудь про OpenCL пока, без него бы что-нибудь достойное написать. Переложить всегда успеется, тем более штатной возможности пока нет.
Николай, знаешь такую крылатую фразу -- преждевременная оптимизация -- это корень всех зол.
Забудь про OpenCL пока, без него бы что-нибудь достойное написать. Переложить всегда успеется, тем более штатной возможности пока нет.
Да фраза крылатая, и я уже почти согласился с ней в прошлый раз, но сделав анализ понял что не получится просто так планировать а потом когда нужно переделать под GPU, уж больно у него специфические потребности.
если планировать без GPU то логичным сделать объект Neuron, который будет отвечать как за операции внутри нейрона так и за присвоение данных расчёта в нужные ячейки памяти, удаследовав класс от общего предка можно было бы легко подключать нужный тип нейрона и так далее,
но немного пораскинув мозгами, тут же понял что такой подход напрочь перечеркнёт GPU расчёты, те ещё не родившийся ребёнок уже обречён ползать.
Но я подозреваю что тебя сбил с толку мой пост выше, там под "метод параллельных расчётов" подразумевается вполне конкретная операция перемножения входов с весами in*wg, под метод последовательных расчётов подразумевается sum+=a[i] ну и так далее.
Просто для лучшей последующей совместимости с GPU, я предлагаю вывести операции из нейронов и объединить их в один ход в объекте слой, а нейроны будут лишь поставлять информацию откуда брать куда девать.
Лекция 1 здесь https://www.mql5.com/ru/forum/4956/page23
Лекция 2 здесь https://www.mql5.com/ru/forum/4956/page34
Лекция 3 здесь https://www.mql5.com/ru/forum/4956/page36
Лекция 4 здесь https://www.mql5.com/ru/forum/4956/page46
Лекция 5 (последняя). Sparse Coding
Эта тема наиболее инетересная. Буду писать эту лекцию постепенно. Так что не забывайте заглядывать в этот пост время от времени.
В общих чертах, наша задача это представить ценовую котировку (вектор x) на последних N барах в виде линейного разложения на базисные функции (ряды матрицы A):
где s это коэффициенты нашего линейного преобразования, которые мы хотим найти и использовать в качестве входов на следующий слой нейроной сети (например, SVM). В большинстве случаев, базисные функции A нам известны, т.е. мы их заранее выбираем. Ими могут быть синусы и косинусы разных частот (получаем преобразование Фурье), функции Габора, Гамматоны, вейвлеты, кёрвлеты, полиномы или другие какие-либо функции. Если эти функции нам заранее известны, то sparse coding сводится к нахождению вектора коэффициентов s таким образом, что большое количество этих коэффициентов равны нулю (sparse vector). Идея тут состоит в том что большинство информационных сигналов имеют структуру, которая описывается меньшим количеством базисных функций чем количество выборок сигнала. Эти базисные функции входящие в разряжённое описание сигнала являются его необходимыми фиччами (features), которые можно использовать для классификации сигнала.
Задача нахождения разряжённого линейного преобразования исходной информации получило название Compressed Sensing (http://ru.wikipedia.org/wiki/Compressive_sensing). В общем случае, задача формулируется таким образом:
minimize L0 norm of s, subject to As = x
где L0 норма равняется количеству ненулевых значений вектора s. Самым распространённым методом решения этой задачи является замена L0 нормы на L1 норму, что составляет основу метода basis pursuit (https://en.wikipedia.org/wiki/Basis_pursuit):
minimize L1 norm of s, subject to As = x
где L1 норма вычисляется как |s_1|+|s_2|+...+|s_L|. Эта задача сводится к линейной оптимизации
Другой распространённый метод нахождения sparse vector s это matching pursuit (https://en.wikipedia.org/wiki/Matching_pursuit). Суть этого метода заключается в нахождении первой базисной функции a_i из заданной матрицы A таким образом что она вписывается во входной вектор x с наибольшим коеффициентом s_i по сравнению с другими базисными функциями. После вычитания a_i*s_i из входного вектора, к полученному остатку вписываем следующую базисную функцию, и т.д. пока не достигнем заданной ошибки. Примером метода matching pursuit является слудующий индикатор, который вписывает одну синусоиду за другой во входную коритовку с наименьшим остатком: https://www.mql5.com/ru/code/130.
Если базисные функции A (словарь, dictionary) нам заранее неизвестны, то их нам нужно найти из входных данных x используя методы под общим названием dictionary learning. Это наиболее сложная (и для меня самая интересная) часть метода sparse coding. В предыдущей лекции я показал как эти функции можно например найти по правилу Оджи, что делает эти функции принципиальными векторами входной котировки. К сожалению, такой вид базисных функций не приводит к разряжённому описанию входных данных (т.е. вектор s - nonsparse).
Существующие методы dictionary learning, приводящие к разряжённым линейным преобразованиям, делятся на
Вероятностные методы нахождения базисных функций сводятся к максимизации максимального правдоподобия:
maximize P(x|A) over A.
Обычно делается предположение что ошибка аппроксимации имеет Гауссовское распределение, что приводит нас к решению следующей задачи оптимизации:
(1)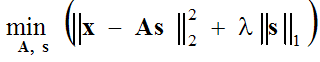 ,
,
которая решается в двух шагах: (1-sparse coding step) при фиксированных базисных функциях А, выражение в круглых скобках минимизируется по отношению к вектору s, и (2-dictionary update step) найденный вектор s фиксируется и выражение в круглых скобках минимизируется по отношению к базисным функциям А используя метод градиентного спуска:
(2)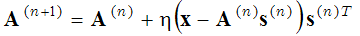
где (n+1) и (n) в суперскрипте обозначают номера итераций. Эти два шага (sparse coding step and dictionary learning step) повторяются пока не достигнут локальный минимум. Этот вероятностный метод нахождения базисных функций используется например в
Olshausen, B. A., & Field, D. J. (1996). Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature, 381(6583), 607-609.
Lewicki, M. S., & Sejnowski, T. J. (1999). Learning overcomplete representations. Neural Comput., 12(2), 337-365.
Метод Оптимальных Направлений (MOD) использует те же два шага оптимизации (sparse coding step and dictionary learning step), но на втором шагу оптимизации (dictionary update step) базисные функции вычисляются путём приравнивания производной выражения в скобках (1) по отношению к А к нулю:
откуда получаем
(3)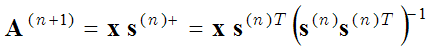 ,
,
где s+ - псевдообратная матрица. Это более точное вычисление базисной матрицы чем по методу градиентного спуска (2). Более подробно MOD метод описан здесь:
K. Engan, S.O. Aase, and J.H. Hakon-Husoy. Method of optimal directions for frame design. IEEE International Conference on Acoustics, Speech, and Signal Processing., vol. 5, pp. 2443-2446, 1999.
Вычисление псевдообратных матриц трудоёмко. Метод k-SVD избегает их вычисления. Пока в этом методе сам не разобрался. О нём можно прочитать здесь:
M. Aharon, M. Elad, A. Bruckstein. K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation. IEEE Trans. Signal Processing, 54(11), November 2006.
С кластерными и он-лайн методами нахождения словаря тоже пока не разобрался. Интересующихся направляю к следующему обзору:
R. Rubinstein, A. M. Bruckstein and M. Elad, “Dictionaries for sparse representation modeling,” Proc. of IEEE , 98(6), pp. 1045-1057, June 2010.
Вот интересные видеолекции на эту тему:
http://videolectures.net/mlss09us_candes_ocsssrl1m/
http://videolectures.net/mlss09us_sapiro_ldias/
http://videolectures.net/nips09_bach_smm/
http://videolectures.net/icml09_mairal_odlsc/
Пока всё. По мере своих возможностей а также интереса от посетителей этого форума, буду расширять эту тему в следующих постах.
Николай, знаешь такую крылатую фразу -- преждевременная оптимизация -- это корень всех зол.
Это настолько частая фраза прикрытия раздолбайства у разработчиков, что можно за каждое ее употребление бить по рукам.
Фраза в корне вредная и абсолютно ошибочная, если речь идет о разработке качественного софта с долгим сроком жизни и прямой ориентации на скорострельность и высокие нагрузки.
Я это проверил многократно на своей многолетней практике управления проектами.
Это настолько частая фраза прикрытия раздолбайства у разработчиков, что можно за каждое ее употребление бить по рукам.
Т.е. надо учитывать какие-то возможности, которые хрен знает когда появятся с хрен знает каким интерфейсом заранее из-за того, что это дает прирост производительности??
Я это проверил многократно на своей многолетней практике управления проектами.