Обсуждение статьи "Нейросети — это просто (Часть 57): Стохастический маргинальный актер-критик (SMAC)"
{kind=link}
Дмитрий, спасибо за ваш труд. Все работает.
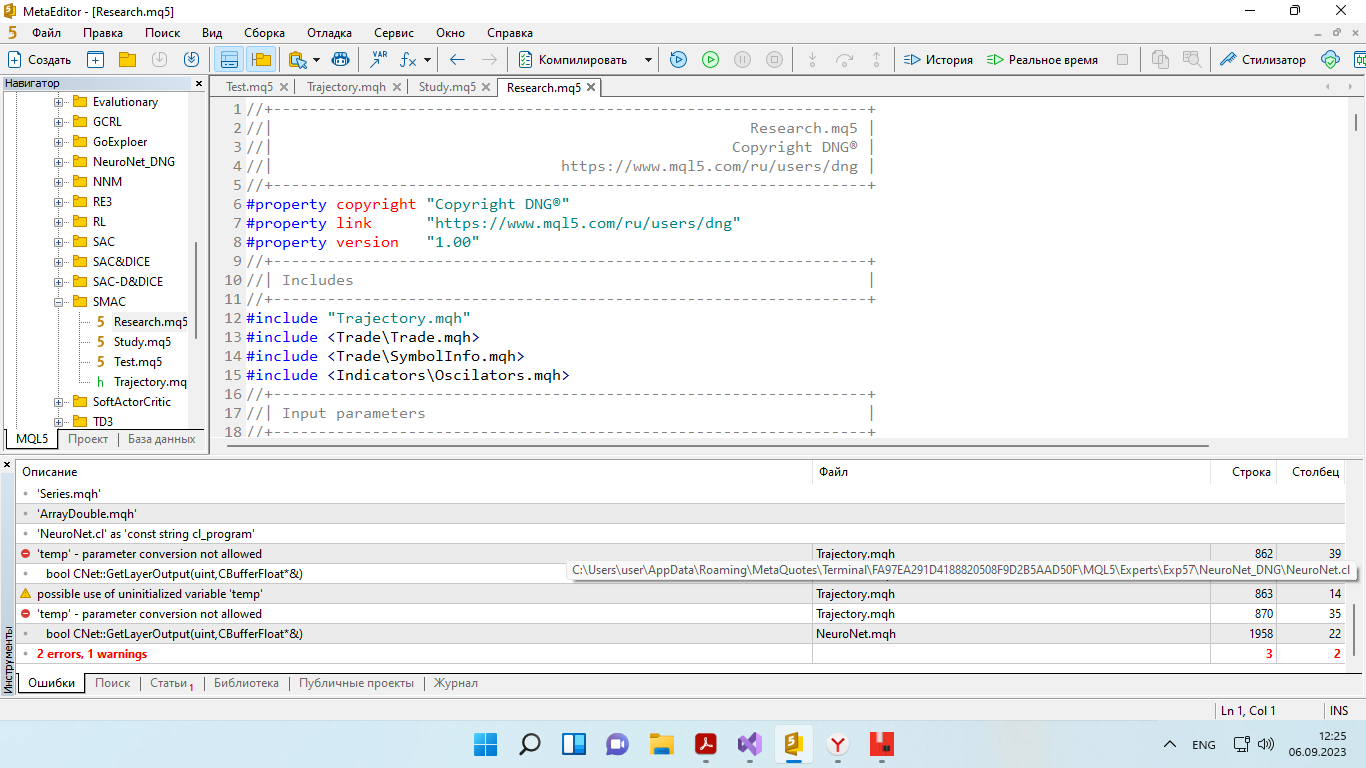
Собираю примеры советником Research на 100 проходов, обучаю модель советником Study, тестирую Test-ом. Далее 50 проходов собираю снова, обучаю на 10 000 итераций, опять тест.
И так пока модель не научится. Вот только у меня пока Test выдает постоянно разные результаты после цикла и не всегда положительные. Т е цикл прогнал, 2-3 теста и результаты разные.
На каком примерно цикле результат станет стабильный? Или это бесконечная работа и результат будет всегда разный?
Спасибо!
Дмитрий, спасибо за ваш труд. Все работает.
Собираю примеры советником Research на 100 проходов, обучаю модель советником Study, тестирую Test-ом. Далее 50 проходов собираю снова, обучаю на 10 000 итераций, опять тест.
И так пока модель не научится. Вот только у меня пока Test выдает постоянно разные результаты после цикла и не всегда положительные. Т е цикл прогнал, 2-3 теста и результаты разные.
На каком примерно цикле результат станет стабильный? Или это бесконечная работа и результат будет всегда разный?
Спасибо!
Советник обучает модель со стохастической политикой. Это означает, что модель учит вероятности получения максимальных вознаграждений за совершение конкретных действий в отдельных состояния системы. В процессе взаимодействия со средой происходит семплирование действий с выученной вероятностью. На начальном этапы вероятности всех действий одинаковые и модель выбирает действие случайным образом. В процессе обучения вероятности будут смещаться и выбор действий будет более осознанным.
Дмитрий здравствуйте. А сколько у вас заняло циклов как описал выше Николай до получения стабильного положительного результата?
И ещё интересно вот если выучится допустим советник за текущий период и если к примеру через месяц его нужно будет переобучать с учётом новых данных, то он будет переобучаться полностью или до обучаться? Те процесс обучения по длительности будет сопоставим с первоначальным или намного короче и быстрей? И ещё если мы допустим обучили модель на EURUSD, то для работы допустим на GBPUSD она будет переобучаться столько же сколько первоначальная или быстрей просто до обучится? Этот вопрос больше не про конкретную эту статью вашу, а про все ваши советники работающие по принципу обучения с подкреплением.
Доброго времени.
Дмитрий, спасибо за вашу работу.
Хочу уточнить для всех...
То что Дмитрий выкладывает это не "Грааль"
это Классический пример академической ЗАДАЧИ, которая предполагает подготовку к научно исследовательской деятельности теоретико-методического характера.
А все хотят видеть на своём счету, прямо здесь и сейчас, положительный результат...
Дмитрий учит нас, как решить (нашу/мою/твою/его) задачу всеми представленными, Дмитрием методами.
Популярные ИИ (GPT) имеют более 700 Миллионов параметров!!!! А сколько данная ИИ?
Если хотите получить хороший результат, обменивайтесь идеями (добавляйте параметры), приводите результаты тестирований и т.д.
Создайте отдельный ЧАТ и там "получайте" результат. Хвастаться можно тут :-), тем самым покажите эффективность работы Дмитрия...
Доброго времени.
Дмитрий, спасибо за вашу работу.
Хочу уточнить для всех...
То что Дмитрий выкладывает это не "Грааль"
это Классический пример академической ЗАДАЧИ, которая предполагает подготовку к научно исследовательской деятельности теоретико-методического характера.
А все хотят видеть на своём счету, прямо здесь и сейчас, положительный результат...
Дмитрий учит нас, как решить (нашу/мою/твою/его) задачу всеми представленными, Дмитрием методами.
Популярные ИИ (GPT) имеют более 700 Миллионов параметров!!!! А сколько данная ИИ?
Если хотите получить хороший результат, обменивайтесь идеями (добавляйте параметры), приводите результаты тестирований и т.д.
Создайте отдельный ЧАТ и там "получайте" результат. Хвастаться можно тут :-), тем самым покажите эффективность работы Дмитрия...
Друг, тут никто не ждёт грааля! Я вот просто хотел бы увидеть, что то что выкладывает Дмитрий в действительности работает. Не со слов Дмитрия в его статьях (у него во всех статьях практически положительный результат), а у себя на компе. Вот я скачал его советник допустим с этой статьи и провёл уже 63 цикла обучения (досбор данных -> тренировка). И она до сих пор льёт в минус. За все 63 цикла было только пара сборов данных, когда из 50 новых примеров было 5-6 положительных. Всё остальное в минус. Как мне увидеть что это действительно работает?
Я Дмитрия спросил выше сообщением, он ничего не ответил. Такая же проблема и в других статьях - сколько не тренируй результата нет....
Друг если у тебя получился стабильный результат, то напиши сколько ты сделал циклов до стабильного результата допустим в этой статье? Если изменять, то что изменять чтобы увидеть результат у себя на компе, просто в тестере? Не грааль, а хотя бы увидеть что это работает...?
Good time.
Dmitry, thank you for your work.
I want to clarify for everyone ...
The fact that Dmitry lays out this is not the "Grail"
This is a classic example of an academic TASK, which involves preparation for research activities of a theoretical and methodological nature.
And everyone wants to see a positive result on their account, right here and now...
Dmitry teaches us how to solve (our/my/your/his) problem with all the methods presented by Dmitry.
Popular AI (GPT) has more than 700 Million parameters!!! And how much is this AI?
If you want to get a good result, exchange ideas (add parameters), give test results, etc.
Create a separate CHAT and "get" the result there. You can brag here :-), thereby showing the effectiveness of Dmitry's work ...
Here are the Params: (based on Dmitry and some research.)
#include "FQF.mqh"
The length of the message should not exceed 64000 characters
===I CUT THE LAST PARTS as Comments are limited to 64000 Chars but you know what to do... =)
The length of the message should not exceed 64000 characters
{kind=link}
{kind=link}
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Нейросети — это просто (Часть 57): Стохастический маргинальный актер-критик (SMAC):
Предлагаем познакомиться с довольно новым алгоритмом Stochastic Marginal Actor-Critic (SMAC), который позволяет строить политики латентных переменных в рамках максимизации энтропии.
При построении автоматизированной торговой системы мы разрабатываем алгоритмы последовательного принятия решений. Именно на решение подобных задач направлены методы обучения с подкреплением. Одной из ключевых проблем в обучении с подкреплением является процесс исследования, когда Агент учится взаимодействовать с окружающей средой. В этом контексте часто используется принцип максимальной энтропии, который мотивирует Агента совершать действия с наибольшей степенью случайности. Однако на практике подобные алгоритмы обучают простых Агентов, которые изучают только локальные изменения вокруг одного действия. Это связано с необходимостью вычисления энтропии политики Агента и использования ее в качестве части цели обучения.
В то же время относительно простым подходом к увеличению выразительности политики Актера является использование латентных переменных, которые предоставляют Агенту собственную процедуру вывода для моделирования стохастичности в наблюдениях, окружающей среде и неизвестных вознаграждениях.
Введение латентных переменных в политику Агента позволяет охватить более разнообразные сценарии, совместимые с историей наблюдений. Здесь следует отметить, что политики с латентными переменными не допускают простого выражения для определения их энтропии. Наивная оценка энтропии может привести к катастрофическим сбоям при оптимизации политики. Кроме того, стохастические обновления с высокой дисперсией для максимизации энтропии не сразу различают между собой локальные случайные воздействия и многомодальное исследование.
Один из вариантов решения указанных недостатков политик с латентными переменными был предложен в статье "Latent State Marginalization as a Low-cost Approach for Improving Exploration". В ней авторы предлагают простой, но эффективный алгоритм оптимизации политики, который способен обеспечивать более эффективное и устойчивое исследование как в полностью наблюдаемых, так и в частично наблюдаемых средах.
Автор: Dmitriy Gizlyk