Алгоритм объединения диапазонов отрезка - помогите создать - страница 5
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
)
1. Совсем непонятно и уже что-то совсем другое.
А что за задача вообще? Какова практическая цель? Может, она вообще по-другому решается.
Ну, если интересно, давайте расскажу более детально. В алгоритме машинного обучения CatBoost перебор множества значений переменной (предиктора), полученных при наблюдениях (массив), для установки сплита решается путем построения предварительной сетки (квантования), таким образом числа разбиваются на отрезки (периоды/диапазоны) и перебор значений происходит не по всем числам, а только по этим границам. Есть разные встроенные методы для построения сеток, в том числе с разным желаемым числом границ. Визуально вариант сетки выглядит так, как на рисунке ниже, тут каждые 100 значений массива поднимают на единицу значение по шкале y - так видно повторяемость значений.
Задачей является построение сетки наиболее благоприятной для обучения, т.е. такой сетки, в которой информация между интервалами (в отрезке) будет больше принадлежать одной из целевой (0/1), при этом будет соблюдаться постоянство зависимости и достаточности наблюдений.
Сейчас я получаю разные сетки, отбираю их отрезки по заданным критериям (писал ранее), и мне нужно скомпоновать между собой отобранные отрезки для объединения их в одну сетку.
)
Если я могу помочь, то я помогаю, а если нет, то не стесняюсь просить помощи.
К тому же задачки тут в последнее время редко появляются, и думал, людям будет интересно поучаствовать в решении.
///
Сейчас я получаю разные сетки, отбираю их отрезки по заданным критериям (писал ранее), и мне нужно скомпоновать между собой отобранные отрезки для объединения их в одну сетку.
Вот об этом был вопрос. Как вы хотите это делать?
Вот об этом был вопрос. Как вы хотите это делать?
Хммм... так скрипт, что Вы написали и может делать почти всю работу. Есть иные варианты? Я предложил вариант снижения числа комбинаций.
Рассматриваю ещё этот вариант :)
Хммм... так скрипт, что Вы написали и может делать почти всю работу. Есть иные варианты? Я предложил вариант снижения числа комбинаций.
Рассматриваю ещё этот вариант :)
Может, когда мало отрезков. А когда много, как быть?
В каком смысле вы предложили вариант снижения числа комбинаций? Достаточно не всех комбинаций, или есть критерий?
Может, когда мало отрезков. А когда много, как быть?
В каком смысле вы предложили вариант снижения числа комбинаций? Достаточно не всех комбинаций, или есть критерий?
Когда много - надо думать...
Как вариант я предлагаю так же начинать с каждого отрезка, но ограничится числом комбинаций от каждой точки.
Вот на рисунке показаны отрезки в виде круга и их оценка в виде длины стрелки, на рисунке выбирается только две самые короткие стрелки, остальные "пути" отсекаются (исключаются). В виде таких стрелок (графов по сути) может быть оценочный коэффициент (показатель).
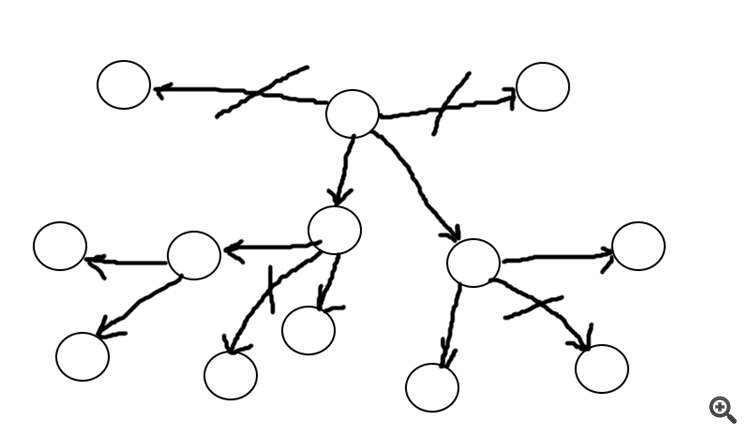
Таким образом, предполагаю, мы отберем не самые худшие варианты, при этом сократив затраты на вычисление.Когда много - надо думать...
Как вариант я предлагаю так же начинать с каждого отрезка, но ограничится числом комбинаций от каждой точки.
Вот на рисунке показаны отрезки в виде круга и их оценка в виде длины стрелки, на рисунке выбирается только две самые короткие стрелки, остальные "пути" отсекаются (исключаются). В виде таких стрелок (графов по сути) может быть оценочный коэффициент (показатель).
Таким образом, предполагаю, мы отберем не самые худшие варианты, при этом сократив затраты на вычисление.Это для ситуации что от точки выходят примерно в одинаковом соотношении длинный короткий и нет областей с только длинными или короткими отрезками.
Какая разница, какие отрезки длинные или короткие, или речь об оценке (длине стрелки по аналогии с рисунком)?
У нас желание - шагнуть по двум лучшим путям в примере, если их меньше то путь один.
Поясните, пожалуйста, почему может возникнуть сложность.
Ещё можно уменьшить число комбинаций за счет разделения отрезков на сегменты (группы) по диапазонам.
На рисунки 4 группы с границами диапазонами, делаем перебор только внутри групп, а потом объединяем лучшие варианты внутри группы между другими группами.
Разделить ровно сложно, поэтому отрезки по границам группы можно выделить отдельно и использовать при комбинации межгрупповых результатов.