Обсуждение статьи "Нейросети — это просто (Часть 13): Пакетная нормализация (Batch Normalization)"
По другому проекту я делал сравнение быстрого расчета ошибки и классического в цикле на 20-50 строк: (предполагаю, что у вас тоже при 50 тыс строк будут такие же накопленные погрешности, при миллионах строк еще больше)
Вначале сравнивал глазами на 50 строках данных. На них ошибок нет.
Но ошибки считаются накопительной суммой. При каждом вычислении мы можем иметь 1е-14 .. 1е-17 погрешности. Складывая эти погрешности много раз, - суммарная погрешность может превысить 1е-5.
Сделал более глубокое сравнение. Взял 50 000 строк и затем сравнивал ошибки, если разница большая, то я их вывожу на экран. Что получилось (см. ниже).
Есть отдельные накопленные погрешности выше 1е-4 (т.е. отличия в 4м знаке после запятой).
Так что скорость конечно хорошо, но если строк будет не 50 тыс, а 500 миллионов? Боюсь что результаты будут совершенно несопоставимы с точным расчетом в цикле.
fast_error= 9.583545e+02 true_error= 9.582576e+02
fast_error= 9.204969e+02 true_error= 9.204000e+02
fast_error= 8.814563e+02 true_error= 8.813594e+02
fast_error= 8.411763e+02 true_error= 8.410794e+02
fast_error= 7.995969e+02 true_error= 7.995000e+02
fast_error= 7.566543e+02 true_error= 7.565574e+02
fast_error= 7.246969e+02 true_error= 7.246000e+02
fast_error= 6.916562e+02 true_error= 6.915593e+02
fast_error= 6.574762e+02 true_error= 6.573793e+02
fast_error= 6.220969e+02 true_error= 6.220000e+02
fast_error= 5.854540e+02 true_error= 5.853571e+02
fast_error= 5.588969e+02 true_error= 5.588000e+02
fast_error= 5.313562e+02 true_error= 5.312593e+02
fast_error= 5.027762e+02 true_error= 5.026792e+02
fast_error= 4.730969e+02 true_error= 4.730000e+02
fast_error= 4.422538e+02 true_error= 4.421569e+02
fast_error= 4.205969e+02 true_error= 4.205000e+02
fast_error= 3.980561e+02 true_error= 3.979592e+02
fast_error= 3.745761e+02 true_error= 3.744792e+02
fast_error= 3.500969e+02 true_error= 3.500000e+02
fast_error= 3.245534e+02 true_error= 3.244565e+02
fast_error= 3.072969e+02 true_error= 3.072000e+02
fast_error= 2.892560e+02 true_error= 2.891591e+02
fast_error= 2.703760e+02 true_error= 2.702791e+02
fast_error= 2.505969e+02 true_error= 2.505000e+02
fast_error= 2.298530e+02 true_error= 2.297561e+02
fast_error= 2.164969e+02 true_error= 2.164000e+02
fast_error= 2.024559e+02 true_error= 2.023590e+02
fast_error= 1.876759e+02 true_error= 1.875789e+02
fast_error= 1.720969e+02 true_error= 1.720000e+02
fast_error= 1.556525e+02 true_error= 1.555556e+02
fast_error= 1.456969e+02 true_error= 1.456000e+02
fast_error= 1.351557e+02 true_error= 1.350588e+02
fast_error= 1.239757e+02 true_error= 1.238788e+02
fast_error= 1.120969e+02 true_error= 1.120000e+02
fast_error= 9.945174e+01 true_error= 9.935484e+01
fast_error= 9.239691e+01 true_error= 9.230000e+01
fast_error= 8.485553e+01 true_error= 8.475862e+01
fast_error= 7.677548e+01 true_error= 7.667857e+01
fast_error= 6.809691e+01 true_error= 6.800000e+01
fast_error= 5.875075e+01 true_error= 5.865385e+01
fast_error= 5.409691e+01 true_error= 5.400000e+01
fast_error= 4.905524e+01 true_error= 4.895833e+01
fast_error= 4.357517e+01 true_error= 4.347826e+01
fast_error= 3.759691e+01 true_error= 3.750000e+01
fast_error= 3.104929e+01 true_error= 3.095238e+01
fast_error= 2.829691e+01 true_error= 2.820000e+01
fast_error= 2.525480e+01 true_error= 2.515789e+01
fast_error= 2.187468e+01 true_error= 2.177778e+01
fast_error= 1.809691e+01 true_error= 1.800000e+01
fast_error= 1.384691e+01 true_error= 1.375000e+01
fast_error= 1.249691e+01 true_error= 1.240000e+01
fast_error= 1.095405e+01 true_error= 1.085714e+01
fast_error= 9.173829e+00 true_error= 9.076923e+00
fast_error= 7.096906e+00 true_error= 7.000000e+00
fast_error= 4.642360e+00 true_error= 4.545455e+00
fast_error= 4.196906e+00 true_error= 4.100000e+00
fast_error= 3.652461e+00 true_error= 3.555556e+00
fast_error= 2.971906e+00 true_error= 2.875000e+00
fast_error= 2.096906e+00 true_error= 2.000000e+00
fast_error= 9.302390e-01 true_error= 8.333333e-01
fast_error= 8.969057e-01 true_error= 8.000000e-01
fast_error= 8.469057e-01 true_error= 7.500000e-01
fast_error= 7.635724e-01 true_error= 6.666667e-01
fast_error= 5.969057e-01 true_error= 5.000000e-01
fast_error= 4.546077e+00 true_error= 4.545455e+00
fast_error= 4.100623e+00 true_error= 4.100000e+00
fast_error= 3.556178e+00 true_error= 3.555556e+00
fast_error= 2.875623e+00 true_error= 2.875000e+00
fast_error= 2.000623e+00 true_error= 2.000000e+00
fast_error= 8.339561e-01 true_error= 8.333333e-01
fast_error= 8.006228e-01 true_error= 8.000000e-01
fast_error= 7.506228e-01 true_error= 7.500000e-01
fast_error= 6.672894e-01 true_error= 6.666667e-01
fast_error= 5.006228e-01 true_error= 5.000000e-01
Подскажите в чём проблема?
Во время обучения вылетает терминал и выдаёт ошибку при этом не всегда, прям полтергейст какой-то.
N 0 22:58:20.933 Core 1 2021.02.01 00:00:00 program string is NULL or empty
MP 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OpenCL program create failed. Error code=4003
CD 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OnInit - 153 -> Error of read EURUSD_PERIOD_H1_ 20AttentionMLMH_d.nnw prev Net 5015
RD 0 22:58:20.933 Core 1 2021.02.01 00:00:00 program string is NULL or empty
QN 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OpenCL program create failed. Error code=4003
IO 0 22:58:20.933 Core 1 final balance 10000.00 USD
LE 2 22:58:20.933 Core 1 2021.02.19 23:54:59 invalid pointer access in 'NeuroNet.mqh' (2271,16)
MS 2 22:58:20.933 Core 1 OnDeinit critical error
NG 0 22:58:20.933 Core 1 EURUSD,H1: 863757 ticks, 360 bars generated. Environment synchronized in 0:00:00.018. Test passed in 0:00:00.256.
QD 0 22:58:20.933 Core 1 EURUSD,H1: total time from login to stop testing 0:00:00.274 (including 0:00:00.018 for history data synchronization)
LQ 0 22:58:20.933 Core 1 321 Mb memory used including 0.47 Mb of history data, 64 Mb of tick data
JF 0 22:58:20.933 Core 1 log file "C:\Users\Buruy\AppData\Roaming\MetaQuotes\Tester\36A64B8C79A6163D85E6173B54096685\Agent-127.0.0.1-3000\logs\20210410.log" written
PP 0 22:58:20.939 Core 1 connection closed
Заранее благодарен за помощь!!!
Дмитрий здравствуйте! в течении пары месяцев наблюдаю сильное расхождение между OOS пробегом и итоговой работатой на том же промежутке но уже советника. Все сигналы единтичный (выгружаю в файл по каждому бару все сигналы и сравниваю) Сеть естественно имеет все те же настройки. Есть подозрение, что процесс сохранения и считывания обучения работает не верно. В файле NeuroNet.mph для каждой сети настроен индивидуальный способ сохранения обучения
bool CNeuronProof::Save(const int file_handle)
bool CNeuronBase::Save(int file_handle)
bool CNeuronConv::Save(const int file_handle)
bool CNeuronLSTM::Save(const int file_handle)
bool CNeuronBaseOCL::Save(const int file_handle)
bool CNeuronAttentionOCL::Save(const int file_handle)
и т.д.
а используется сохранение
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true)
Поясните пожалуйста в чем разница, и возможно ли сопоставить сохраненные данные с обучением из памяти после эпохи?
Вывел данные сигналов TempData и исходящие нейроны ResultData в момент обучения
и отдельно в момент тестирования. Сравнил оба файла в программа WinMerge.
{kind=link}
Дмитрий здравствуйте! в течении пары месяцев наблюдаю сильное расхождение между OOS пробегом и итоговой работатой на том же промежутке но уже советника. Все сигналы единтичный (выгружаю в файл по каждому бару все сигналы и сравниваю) Сеть естественно имеет все те же настройки. Есть подозрение, что процесс сохранения и считывания обучения работает не верно. В файле NeuroNet.mph для каждой сети настроен индивидуальный способ сохранения обучения
bool CNeuronProof::Save(const int file_handle)
bool CNeuronBase::Save(int file_handle)
bool CNeuronConv::Save(const int file_handle)
bool CNeuronLSTM::Save(const int file_handle)
bool CNeuronBaseOCL::Save(const int file_handle)
bool CNeuronAttentionOCL::Save(const int file_handle)
и т.д.
а используется сохранение
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true)
Поясните пожалуйста в чем разница, и возможно ли сопоставить сохраненные данные с обучением из памяти после эпохи?
Вывел данные сигналов TempData и исходящие нейроны ResultData в момент обучения
и отдельно в момент тестирования. Сравнил оба файла в программа WinMerge.
Добрый день, Дмитрий.
Давайте посмотрим на метод CNet::Save(...). После записи переменных, характеризующих состояние обучения сети, осуществляется вызов метода Save массива нейронных слоев layers (CArrayLayer унаследованного от CArrayObj)
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true) { if(MQLInfoInteger(MQL_OPTIMIZATION) || MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_FORWARD) || MQLInfoInteger(MQL_OPTIMIZATION)) return true; if(file_name==NULL) return false; //--- int handle=FileOpen(file_name,(common ? FILE_COMMON : 0)|FILE_BIN|FILE_WRITE); if(handle==INVALID_HANDLE) return false; //--- if(FileWriteDouble(handle,error)<=0 || FileWriteDouble(handle,undefine)<=0 || FileWriteDouble(handle,forecast)<=0 || FileWriteLong(handle,(long)time)<=0) { FileClose(handle); return false; } bool result=layers.Save(handle); FileFlush(handle); FileClose(handle); //--- return result; }
Класс CArrayLayer не имеет метода Save, поэтому вызывается метод родительского класса CArrayObj::Save(const int file_handle). В теле данного метода организован цикл по перебору всех вложенных объектов и вызов метода Save для каждого объекта.
//+------------------------------------------------------------------+ //| Writing array to file | //+------------------------------------------------------------------+ bool CArrayObj::Save(const int file_handle) { int i=0; //--- check if(!CArray::Save(file_handle)) return(false); //--- write array length if(FileWriteInteger(file_handle,m_data_total,INT_VALUE)!=INT_VALUE) return(false); //--- write array for(i=0;i<m_data_total;i++) if(m_data[i].Save(file_handle)!=true) break; //--- result return(i==m_data_total); }
Иными словами, здесь используется принцип матрешки: вызываем метод Save для объекта верхнего уровня, а внутри метода перебираются все вложенные объекты и вызывается одноименный метод для каждого объекта.
Загрузка данных их файла организована аналогичным способом.
Касательно, различных оценок в процессе обучения и эксплуатации. Я не знаю, как у Вас организована работа нейронной сети в режиме эксплуатации, но в режиме обучения идет постоянное изменение параметров нейронной сети. Соответственно, на одни и те же входные данные будут выдаваться различные результаты.
С уважением,
Дмитрий.
P.S. Проверить правильность сохранения и считывания данных можно сделав небольшую тестовую программу, в которой считать нейронную сеть из файла и сразу сохранить в новый файл. А потом сравнить два файла. Если заметите расхождения, напишите, проверю.
Добрый день, Дмитрий.
Давайте посмотрим на метод CNet::Save(...). После записи переменных, характеризующих состояние обучения сети, осуществляется вызов метода Save массива нейронных слоев layers (CArrayLayer унаследованного от CArrayObj)
Класс CArrayLayer не имеет метода Save, поэтому вызывается метод родительского класса CArrayObj::Save(const int file_handle). В теле данного метода организован цикл по перебору всех вложенных объектов и вызов метода Save для каждого объекта.
Иными словами, здесь используется принцип матрешки: вызываем метод Save для объекта верхнего уровня, а внутри метода перебираются все вложенные объекты и вызывается одноименный метод для каждого объекта.
Загрузка данных их файла организована аналогичным способом.
Касательно, различных оценок в процессе обучения и эксплуатации. Я не знаю, как у Вас организована работа нейронной сети в режиме эксплуатации, но в режиме обучения идет постоянное изменение параметров нейронной сети. Соответственно, на одни и те же входные данные будут выдаваться различные результаты.
С уважением,
Дмитрий.
P.S. Проверить правильность сохранения и считывания данных можно сделав небольшую тестовую программу, в которой считать нейронную сеть из файла и сразу сохранить в новый файл. А потом сравнить два файла. Если заметите расхождения, напишите, проверю.
Принял, попробую проверить следующим образом. На первом же баре сохраню в файл TempData (Сигналы) и OUTPUT Neurons. Сначала без загрузки файла но с обучением, потом с с загрузкой обучения с этого же первого бара, но без обучения в процессе. всего один бар и в том и в том случае и сраваню. Отпишусь.
p/s/ так как в процессе обучения действительно учится нейронка на каждом баре, в процессе тестера реализовал тот же процесс, но с на минус N баров.Влияние должно быть не существенным. Но согласен оно должно быть.
Уважаемый Дмитрий!
В процессе долгой работы с помощью Вашей библиотеки получилось создать торговый советник с неплохим результатом 11% просадки к почти 100% прироста за 5 лет EURUSD.
Alpari:
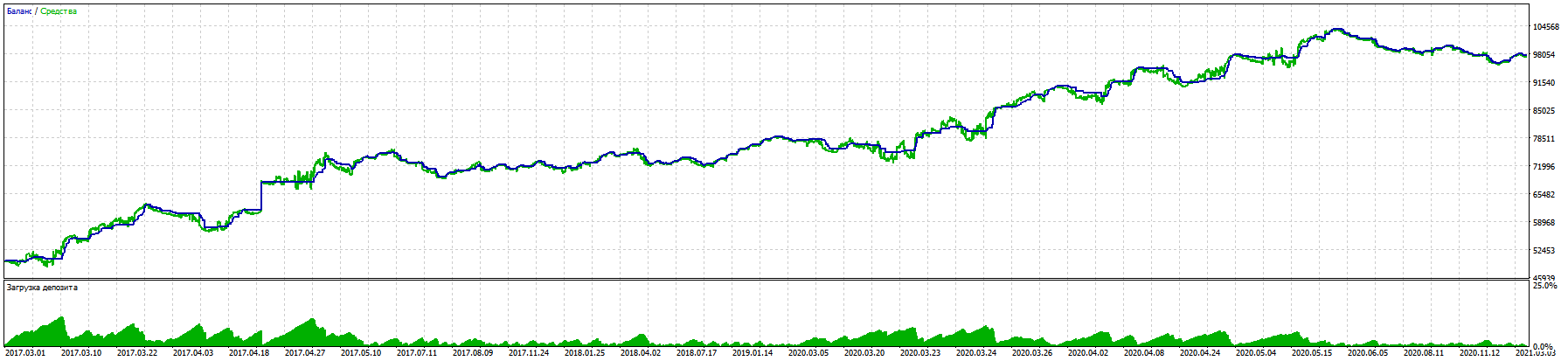
Тестирование на реальном счете идёт в той же логике.
Примечательно, что даже на фьючерсах БКС RURUSD даёт ещё лучший результат с теми же вводными. (На других парах еще не тестировал)
Ключевой победой стало тестирование торговли вслепую (обучение только на прошлых периодах) и обязательными Stoploss без мартингейлов и прочих ухищрений, кроме права открывать несколько сделок в любом направлении в зависимости от сигнала .
Конечно пришлось многое изучить и дополнить из пятинедельных курсов Университетов ВЩЭ и Stanford, и кучи статей по нейронным сетям, особенно в понимании, на чём учить, чему учить, и как учить.
Огромное Вам спасибо!
Прошу Вас не останавливаться и продолжить развитие библиотеки.
Над чем хотел бы Вас попросить подумать
1. Все же над сохранением обучения. Оно как я уже писал не работает. Приходится учить каждый раз и "слёту" не выключая торговать. Это не проблема, обучение проходит быстро, но есть вторая проблема.
2. При старте Вы заложили логику Randomize на создание первичных нейронов. Это приводить к тому, что возникает до трех версий обучения. (ключевое думаю в том, что первичный нейрон то изначально положительный, то отрицательный)
Да с этим тоже можно бороться, так сказать, заставлять переучиваться, с нуля, если не вышел на нужные показатели метрики.
Но я уверен, что можно стартовать с условных 0,01 веса на каждом нейроне. (К сожалению переобученность становится более яркой)
Или все же научиться сохранять лучшую копию образования, тогда это пункт 1.
Уважаемый Дмитрий!
В процессе долгой работы с помощью Вашей библиотеки получилось создать торговый советник с неплохим результатом 11% просадки к почти 100% прироста за 5 лет EURUSD.
Alpari:
Тестирование на реальном счете идёт в той же логике.
Примечательно, что даже на фьючерсах БКС RURUSD даёт ещё лучший результат с теми же вводными. (На других парах еще не тестировал)
Ключевой победой стало тестирование торговли вслепую (обучение только на прошлых периодах) и обязательными Stoploss без мартингейлов и прочих ухищрений, кроме права открывать несколько сделок в любом направлении в зависимости от сигнала .
Конечно пришлось многое изучить и дополнить из пятинедельных курсов Университетов ВЩЭ и Stanford, и кучи статей по нейронным сетям, особенно в понимании, на чём учить, чему учить, и как учить.
Огромное Вам спасибо!
Прошу Вас не останавливаться и продолжить развитие библиотеки.
Над чем хотел бы Вас попросить подумать
1. Все же над сохранением обучения. Оно как я уже писал не работает. Приходится учить каждый раз и "слёту" не выключая торговать. Это не проблема, обучение проходит быстро, но есть вторая проблема.
2. При старте Вы заложили логику Randomize на создание первичных нейронов. Это приводить к тому, что возникает до трех версий обучения. (ключевое думаю в том, что первичный нейрон то изначально положительный, то отрицательный)
Да с этим тоже можно бороться, так сказать, заставлять переучиваться, с нуля, если не вышел на нужные показатели метрики.
Но я уверен, что можно стартовать с условных 0,01 веса на каждом нейроне. (К сожалению переобученность становится более яркой)
Или все же научиться сохранять лучшую копию образования, тогда это пункт 1.
Спасибо, Дмитрий, за теплые слова. Инициировать все веса константным значением плохая практика. В таком случае, при обучении все нейроны работают синхронно как один. И вся нейросеть вырождается в один нейрон на каждом слое.
....
Над чем хотел бы Вас попросить подумать
1. Все же над сохранением обучения. Оно как я уже писал не работает. Приходится учить каждый раз и "слёту" не выключая торговать. Это не проблема, обучение проходит быстро, но есть вторая проблема.
2. При старте Вы заложили логику Randomize на создание первичных нейронов. Это приводить к тому, что возникает до трех версий обучения. (ключевое думаю в том, что первичный нейрон то изначально положительный, то отрицательный)
Да с этим тоже можно бороться, так сказать, заставлять переучиваться, с нуля, если не вышел на нужные показатели метрики.
Но я уверен, что можно стартовать с условных 0,01 веса на каждом нейроне. (К сожалению переобученность становится более яркой)
Или все же научиться сохранять лучшую копию образования, тогда это пункт 1.
Дмитрий, я проверил это как тебе и советовал автор.
1. Поводим обучение несколько эпох, после каждой эпохи сохраняется файл сети.
2. Удаляем с графика. Снова запускаем с включенным параметром testSaveLoad - советник после считывания ранее обученной сети, снова записывает её, контрольно повторяет цикл считал-записал ещё раз и выгружается, и получаем в итоге три файла, помимо изначальной сети еще с приставками _check и _check2
3. Сравниваем три файла. идём а) учиться программированию через тестирование б) искать ошибки у себя.

Спасибо Алексей, да не выкладывал сюда результаты.
Проблема оказалась в другом месте.
Процесс сохранения/загрузки работает.
Решение нашлось в строке создания елментов нейроннос сети с использрванием Randomize
bool CArrayCon::CreateElement(int index) { if(index<0 || index>=m_data_max) return false; //--- xor128; double weigh=(double)rnd_w/UINT_MAX-0.5; m_data[index]=new CConnection(weigh); if(!CheckPointer(m_data[index])!=POINTER_INVALID) return false; //--- return (true); }
Заменил на более стабильную функцию сосздания нейроннов при чем важно в равном кол-ве отризательных и пооложительных, чтобы у сети не было предрасположенности в сторону продаж или покупок.
double weigh=(double)MathMod(index,0)?sin(index):sin(-index);
то же на всяки случая сделал с функцией создания первоначальных весов.
double CNeuronBaseOCL::GenerateWeight(void) { xor128; double result=(double)rnd_w/UINT_MAX-0.5; //--- return result; } //+----
Теперь бэктест выдает один и тот же результат при тестирования обученной сети после загрузки файла обучения.
Входы единтичны посекундно.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Нейросети — это просто (Часть 13): Пакетная нормализация (Batch Normalization):
В предыдущей статье мы начали рассматривать методы повышения качества обучения нейронной сети. В данной статье предлагаю продолжить эту тему и рассмотреть такой поход, как пакетная нормализация данных.
В практике использования нейронных сетей используются различные подходы к нормализации данных. Но все они направлены на удержание данных обучающей выборки и выходных данных скрытых слоев нейронной сети в заданном диапазоне и с определенными статистическими характеристиками выборки, такими как дисперсия и медиана. Почему же это так важно, ведь мы помним, что в нейронах сети применяются линейные преобразования, которые в процессе обучения смещают выборку в сторону антиградиента.
Рассмотрим полносвязный перцептрон с 2-мя скрытыми слоями. При прямом проходе каждый слой генерирует некую совокупность данных, которые служат обучающей выборкой для последующего слоя. Результат работы выходного слоя сравнивается с эталонными данными и на обратном проходе распространяется градиент ошибки от выходного слоя через скрытые слои к исходным данным. Получив на каждом нейроне свой градиент ошибки мы обновляем весовые коэффициенты, подстраивая нашу нейронную сеть под обучающие выборки последнего прямого прохода. И здесь возникает конфликт: мы подстраиваем второй скрытый слой (H2 на рисунке ниже) под выборку данных на выходе первого скрытого слоя (на рисунке H1), в то время, как, изменив параметры первого скрытого слоя мы уже изменили массив данных. Т. е. мы подстраиваем второй скрытый слой под уже несуществующую выборку данных. Аналогичная ситуация и с выходным слоем, который подстраивается под уже измененный выход второго скрытого слоя. А если еще учесть искажение между первым и вторым скрытыми слоями, то масштабы ошибки увеличиваются. И чем глубже нейронная сеть, тем сильнее проявление этого эффекта. Это явление было названо внутренним ковариационным сдвигом.
В классических нейронных сетях указанная проблема частично решалась уменьшением коэффициента обучения. Небольшие изменения весовых коэффициентов не сильно изменяют распределение выборки на выходе нейронного слоя. Но такой подход не решает масштабирования проблемы с ростом количества слоев нейронной сети и снижал скорость обучения. Еще одна проблема маленького коэффициента обучения — застревание в локальных минимумах, об этом мы уже говорили в статье [6].
Автор: Dmitriy Gizlyk