Обсуждение статьи "Нейросети — это просто (Часть 2): Обучение и тестирование сети"
Статья интересная. Я раньше даже не пытался смотреть в сторону нейронных сетей, полагая что "тёмный лес" и всё, что читал на эту тему раньше отталкивало изобилием непонятных слов, но в этой статье, действительно, теория достаточно простая и понятная, за это автору спасибо!
А вот эту фразу хотелось бы уточнить: "Оба советника показали схожие результаты с уровнем попадания чуть более 6%." Правильно ли я понял, что после первого "прохода" обучения прогноз нейросети оправдался только на 6%.
А после 35 эпох обучения - только 12% ???
Такой низкий результат не мотивирует изучать тему дальше.
Какие существуют методы повышения точности прогноза?
Добрый день, Дмитрий.
Тема очень интересная и нужная. Спасибо за эти статьи).
1. У меня вопрос по коду метода Traine(... ):
TempData.Clear(); bool sell=(High.GetData(i+2)<High.GetData(i+1) && High.GetData(i)<High.GetData(i+1)); //в строчке ниже скорее всего не верно определяется Low фрактал bool buy=(Low.GetData(i+2)<Low.GetData(i+1) && Low.GetData(i)<Low.GetData(i+1)); //знаки сравнения нужно поменять наоборот buy=(Low.GetData(i+2)>Low.GetData(i+1) && Low.GetData(i)>Low.GetData(i+1));/
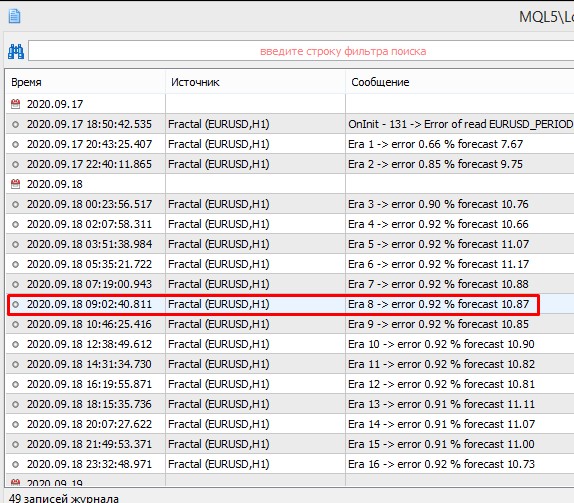
Когда я запустил измененный вариант на обучение результаты улучшились:
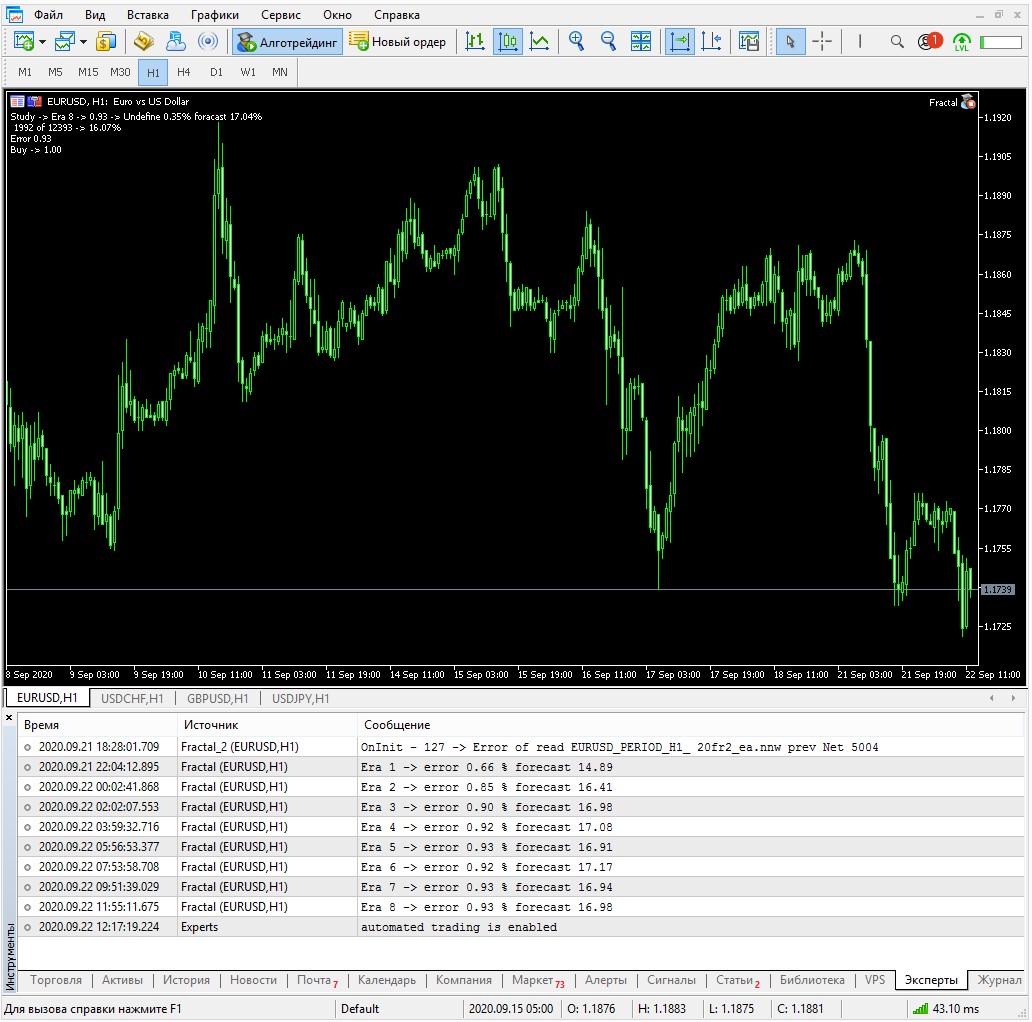
Уже на 8 эпохе точность была 16.98% против старого варианта на той же эпохе 10.87%
2. Почему все таки у многослойной нейро - сети такой низкий % точности,не дотягивает до 50% ?
Добрый день, Дмитрий.
Тема очень интересная и нужная. Спасибо за эти статьи).
1. У меня вопрос по коду метода Traine(... ):
Когда я запустил измененный вариант на обучение результаты улучшились:
Уже на 8 эпохе точность была 16.98% против старого варианта на той же эпохе 10.87%
Спасибо за замечание, Александр. Досадная ошибка с копипастом.
Добрый день, Дмитрий.
2. Почему все таки у многослойной нейро - сети такой низкий % точности,не дотягивает до 50% ?
Я писал в первой статье, что индикаторы взял случайные из стандартных с стандартными параметрами. А нейронная сеть хороший инструмент, но не что-то сверхъестественное. Она ищет закономерности там где они есть. Но если в исходных данных нет закономерностей, то она сама их не придумает. Точное попадание в фрактал довольно сложная задача и, если честно, я не ожидал получить точного попадания. Но то, что получилось дает почву для дальнейшей работы.
Спасибо за замечание, Александр. Досадная ошибка с копипастом.
Бывает)
Я писал в первой статье, что индикаторы взял случайные из стандартных с стандартными параметрами. А нейронная сеть хороший инструмент, но не что-то сверхъестественное. Она ищет закономерности там где они есть. Но если в исходных данных нет закономерностей, то она сама их не придумает. Точное попадание в фрактал довольно сложная задача и, если честно, я не ожидал получить точного попадания. Но то, что получилось дает почву для дальнейшей работы.
Логично).
Спасибо, ваша работа замечательная в любом случае )
Дмитрий, добрый день!
Очень интересный цикл статей про нейронные сети. На данный момент экспериментирую с различными наборами индикаторов и задачами для сети. Решил поставить перед сетью задачу определить вероятность появления следующего бара либо с уровнем Hight большем, чем уровень Open текущего бара на 100 пунктов, либо с уровнем Low меньшим, чем уровень Open текущего бара на 100 пунктов.
if(add_loop && i<(int)(bars-MathMax(HistoryBars,0)-1) && i>1 && Time.GetData(i)>dtStudied && dPrevSignal!=-2) { TempData.Clear(); double DiffMin=100; double DiffLow=Open.GetData(i+1)-Low.GetData(i); double DiffHigh=High.GetData(i)-Open.GetData(i+1); bool sell=(DiffLow>=DiffMin); bool buy=(DiffHigh>=DiffMin); TempData.Add((double)buy); TempData.Add((double)sell); TempData.Add((double)(!buy && !sell)); Net.backProp(TempData); ... }
При тестировании советника на график выводятся метки прогнозных фракталов, но статистика по правильно предсказанным и ненайденным фракталам не обновляется и всегда равно 0.00%. Можете указать мне на ошибку, которую я допустил?
if(DoubleToSignal(dPrevSignal)!=Undefine) { if(DoubleToSignal(dPrevSignal)==DoubleToSignal(TempData.At(0))) dForecast+=(100-dForecast)/Net.recentAverageSmoothingFactor; else dForecast-=dForecast/Net.recentAverageSmoothingFactor; dUndefine-=dUndefine/Net.recentAverageSmoothingFactor; } else { if(sell || buy) dUndefine+=(100-dUndefine)/Net.recentAverageSmoothingFactor; }

- www.mql5.com
Дмитрий, добрый день!
Очень интересный цикл статей про нейронные сети. На данный момент экспериментирую с различными наборами индикаторов и задачами для сети. Решил поставить перед сетью задачу определить вероятность появления следующего бара либо с уровнем Hight большем, чем уровень Open текущего бара на 100 пунктов, либо с уровнем Low меньшим, чем уровень Open текущего бара на 100 пунктов.
При тестировании советника на график выводятся метки прогнозных фракталов, но статистика по правильно предсказанным и ненайденным фракталам не обновляется и всегда равно 0.00%. Можете указать мне на ошибку, которую я допустил?
Добрый день,
Вы указали Diff=100, насколько я понимаю это в пунктах. А разница считается по цене. Т.е. для EURUSD посчитается как 1,16715-1,15615=0,01. В итоге, у Вас не сопоставимые данные и sell и buy всегда будут false.
Добрый день,
Вы указали Diff=100, насколько я понимаю это в пунктах. А разница считается по цене. Т.е. для EURUSD посчитается как 1,16715-1,15615=0,01. В итоге, у Вас не сопоставимые данные и sell и buy всегда будут false.
У меня вопрос: На кой черт изучать тему аж целого цикла мега заумных статей если у этой нейронной сети точность мизерная ... мне кажется тему надо либо прекратить либо усовершенствовать советник.
сразу добавлю, моя нейронная сеть намного "сложнее" вашей, но гарантированно дает 70-80% правильных входов и при этом она значительно проще по структуре ...
и еще добавлю что есть просто куча других нейронных сетей с гораздо большей точностью чем ваша
вообще сложилось впечатление что вам за статьи деньги платят а толку от них ноль ... уж извините
я также не согласен со названием "Нейросети - это просто", те кто занимается машинным обучением на больших данных знает - это очень не просто ... :-)
>Для оценки результатов работы сети можно использовать среднеквадратичную ошибку предсказания, процент правильного предсказания фракталов, процент пропущенных фракталов.
с этим не согласен вообще - результат только итоговый баланс, чистая прибыль и только и больше ничего ... вообще ничего, здесь не наука ради науки, здесь наука ради прибыли
и даже скажу почему: есть советники с точностью 60% ... но они благодаря хитрой системе дают большую прибыль чем советники с точностью 80% ...
а начинать надо с графика итогового стейта торговли вашего советника или читать смысла нет, я вот сразу вниз кручу если стейта нет или он не удовлетворяет моим требованиям то можно не читать вообще, ниже тест моей не очень умной нейронки

а начинать надо с графика итогового стейта торговли вашего советника или читать смысла нет, я вот сразу вниз кручу если стейта нет или он не удовлетворяет моим требованиям то можно не читать вообще, ниже тест моей не очень умной нейронки
тогда Вам не нужен раздел статьи
под Ваши требования - прибыльный стейт, подходят разделы кодобаза и Маркет
да, кстати, под Ваши требования даже Ваше сообщение не подходит, получается его тоже можно игнорировать? )))
статьи нужны, нужны, чтобы правильно протестировать советника работающего на основе нейросети, высока вероятность, что Ваш стейт из тестера, мало того, что из МТ4, так и возможно Вы не поделили обучающую выборку на трейн/тест/валидация
статьи нужны, чтобы учиться писать хороший структурированный и читаемый код - у автора, имхо, идеальный под эти требования код в статье
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Нейросети — это просто (Часть 2): Обучение и тестирование сети:
В данной статье мы продолжим изучение нейронных сетей, начатое в предыдущей статье и рассмотрим пример использования в советниках созданного нами класса CNet. Рассмотрены две модели нейронной сети, которые показали схожие результаты как по времени обучения, так и по точности предсказания.
Первая эпоха максимально зависима от случайно выбранных на начальном этапе весовых коэффициентов нейронной сети.
После 35 эпох обучения разрыв в статистических показателях немного увеличился в пользу регрессионной модели нейронной сети:
Результаты тестирования показывают, что оба варианта организации нейронной сети дают схожие результаты как по времени обучения, так и по точности предсказания. В тоже время полученные показатели говорят о необходимости дополнительных затрат времени и ресурсов на обучение. Желающие проанализировать динамику обучения нейронных сетей могут ознакомиться со скриншотами каждой эпохи обучения во вложении.
Автор: Dmitriy Gizlyk