Индикаторы: Moving Avarage Map
Moving Average пишется через E! grammar nazi в треде )))
На самом деле очень прикольно и свежо выглядит, спасибо за работу!
однако не совсем понятно чем вызваны такие характерные наклоны как бы полосы/штрихи и проблески или рябь как бы...
Moving Average пишется через E! grammar nazi в треде )))
На самом деле очень прикольно и свежо выглядит, спасибо за работу!
однако не совсем понятно чем вызваны такие характерные наклоны как бы полосы/штрихи и проблески или рябь как бы...
однако не совсем понятно чем вызваны такие характерные наклоны как бы полосы/штрихи и проблески или рябь как бы...
часть ряби обусловлена тем, что для каждого периода MA рассчитывается в видимости экрана градиент меняется от красного до зеленого с максимальным цветовым диапазоном. Другими словами, цветовое приращение на единицу наклона для каждого периода отличается.
Для чего так сделано?
Максимальный наклон может быть только для MA с периодом 1, для MA с периодом, скажем 200 наклоны будут гораздо меньше ввиду большей сглаженности. Чем больше период, тем меньше наклоны. Поэтому, если не менять силу градиента, то картина была бы такая:

т.е. моментально все бы затухало.
но эта рябь не сильно видна:

А наклоны, полосы и штрихи - это очевидно, почему.
Т.к. каждая строка - это горизонтальная линия МА с периодом 1 в самом
вверху и дальше вниз период увеличивается на единицу на каждый пиксель вниз.
МА становится горизонтальной линией, т.к. наклон меняется на градиент от красного до зеленого.
Т.е. любой всплеск цены превращается в диагональное затухание, т.к. период меняется линейно.
Возможно нужно будет вставить
для наглядности текущую реальную МА в том месте где находится указатель мыши. Сделаю как появиться чуток времени.
Спасибо
Привет, Николай! Как всегда, на высоте. Самое быстрое рисование на МТ5, это простое заполнение массива размером количества пикселей монитора. Интересно, сколько это. Не замерял? Далее, накладывается задержка вызываемая работой конкретного алгоритма. Следовательно, чем лучше алгоритм, тем она меньше. Ну, это очевидные вещи... Интересно, что если поверх полотна ты будешь выводить неменяющийся текст, то при его выведении нужно всегда очищать ту область на которую он накладывается, дабы текст не становился смазанным. Поэтому, вывод текста на рисованное полотно дольше, чем просто перерисовка такого же участка полотна. Просто из личного опыта...
Привет, Петр!
Простое заполнение массива 1920x1080 ( 2 073 600 элементов) методом поэлементного копирования из другого
сформированного массива такого же размера займет около 8 миллисекунд на моем ноутбуке.
Если копировать не поэлементно, а через ArrayCopy, то займет около 1 миллисекунды, т.е. почти на порядок быстрее.
2019.06.26 16:24:27.815 TestSpeedRand (EURUSD,M1) Заполнение массива из 1076124 элементов = 4258 микросекунд
2. Да, существует, как минимум, три варианта:
- Если канвас один, то каждый раз перед выводом нового текста очищать и перерисовывать весь канвас. Это самый простой, ленивый, и расточительный вариант в плане ресурса процессора, но я им активно пользуюсь, когда нужно что-то сделать по-быстрому и лень возится с экономией нескольких миллисекунд. Тем более этот вариант самый бережливый в плане ресурсов памяти.
- Если канвас один, то можно , как ты говоришь, предварительно сохранять ту уже сформированную область, на которую накладывается текст (или полностью весь холст). И каждый раз перед перерисовкой текста выводить сохраненный участок. Этот вариант более гуманный для ресурсов процессора, но требует больше кода и памяти под дополнительный массив. Также нужно отслеживать положение и размер текстового поля.
- Ну и, наконец, вариант с отдельным прозрачным канвасом под текст. Пожалуй это самый разумный вариант, только если не будет проблемы "квадратиков".
Спасибо
Возможно нужно будет вставить для наглядности текущую реальную МА в том месте где находится указатель мыши. Сделаю как появиться чуток времени.
Сделал. Для старта/завершения этого режима нужно нажать клавишу "Z"
Привет, Петр!
Простое заполнение массива 1920x1080 ( 2 073 600 элементов) методом поэлементного копирования из другого
сформированного массива такого же размера займет около 8 миллисекунд на моем ноутбуке.
Если копировать не поэлементно, а через ArrayCopy, то займет около 1 миллисекунды, т.е. почти на порядок быстрее.
2. Да, существует, как минимум, три варианта:
- Если канвас один, то каждый раз перед выводом нового текста очищать и перерисовывать весь канвас. Это самый простой, ленивый, и расточительный вариант в плане ресурса процессора, но я им активно пользуюсь, когда нужно что-то сделать по-быстрому и лень возится с экономией нескольких миллисекунд. Тем более этот вариант самый бережливый в плане ресурсов памяти.
- Если канвас один, то можно , как ты говоришь, предварительно сохранять ту уже сформированную область, на которую накладывается текст (или полностью весь холст). И каждый раз перед перерисовкой текста выводить сохраненный участок. Этот вариант более гуманный для ресурсов процессора, но требует больше кода и памяти под дополнительный массив. Также нужно отслеживать положение и размер текстового поля.
- Ну и, наконец, вариант с отдельным прозрачным канвасом под текст. Пожалуй это самый разумный вариант, только если не будет проблемы "квадратиков".
Сделал. Для старта/завершения этого режима нужно нажать клавишу "Z"
Восхитительно...
теперь более понятно стало,
с другой стороны эту информацию можно получить и из веера мувингов...
а вот было бы интересно сделать градиентные границы пучка каналов СКО (Боллинджера) с учетом весов...
а на самом деле я даже заглядывал бы в сторону сглаженных регрессионных каналов, взвешенных по качеству модели,
в роли качества модели для начала можно было бы использовать RMSE (средний квадрат ошибки)...
смысл такой шизофазии - получить оценки вероятностных границ потенциально более "сильных" (ровных) моделей...
Восхитительно...
теперь более понятно стало,
с другой стороны эту информацию можно получить и из веера мувингов...
а вот было бы интересно сделать градиентные границы пучка каналов СКО (Боллинджера) с учетом весов...
а на самом деле я даже заглядывал бы в сторону сглаженных регрессионных каналов, взвешенных по качеству модели,
в роли качества модели для начала можно было бы использовать RMSE (средний квадрат ошибки)...
смысл такой шизофазии - получить оценки вероятностных границ потенциально более "сильных" (ровных) моделей...
Да, Боллинджер это неинтересно. Это весьма примитивно, т.к. каналы Боллинджер это МНК от полинома нулевой степени (банальное среднее
арифметическое - обычная простая МА)
А вот по поводу регрессионных каналов полиномов - эта мысль меня тоже посещала. Думаю полином 2 степени (парабола) с каналом МНК будет
самым оптимальным вариантом. Хотя можно и поэкспериментировать и с полиномами более высокой степени, но вряд ли это даст бенефиты.

ЗЫ Только не ясно, как смешивать разные параметры. В отличии от обычной МА, где мы считываем один параметр - наклон самой МА, то в полиномиальных регрессионных каналах гораздо больше важных параметров: наклон не только самой скользящей (оси канала - трассирующего следа самого полинома), но и текущая ширина канала, наклон верней границы канала, наклон нижней границы канала( они будут разные), наклон самого полинома. Одним измерением трудно будет обойтись, чтобы это все наглядно визуализировать. Но визуализация нужна только человеку. Роботу визуализация не нужна - ему нужны только данные.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
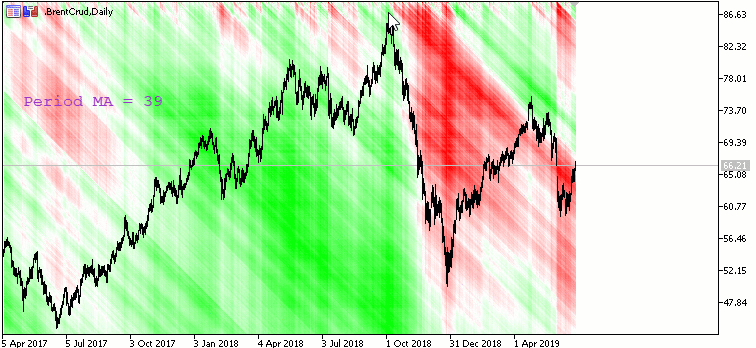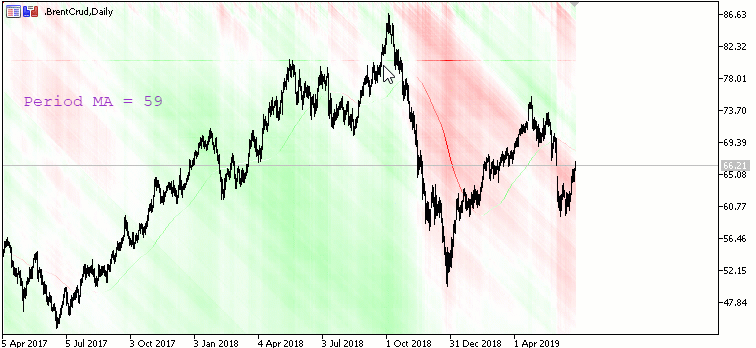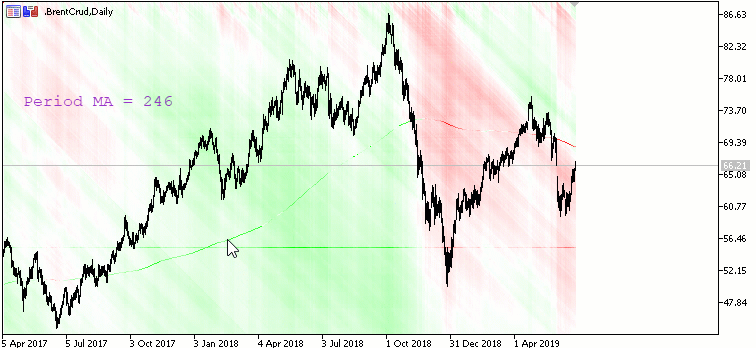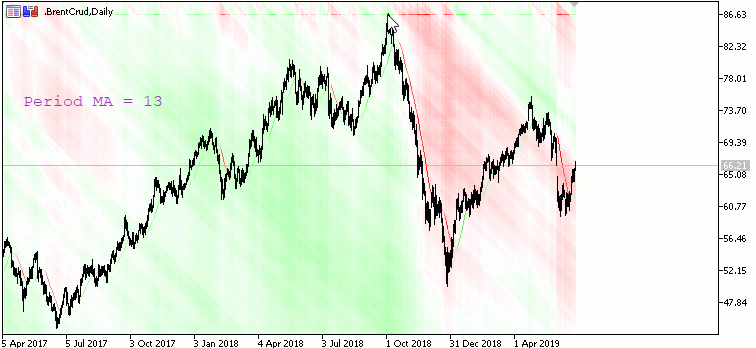
Moving Avarage Map:
Карта наклона Moving Avarage с периодами от 1 (начинается сверху) до X (заканчивается снизу) с шагом 1. X - высота окна в пикселях. Красный цвет - наклон вниз, зеленый - вверх.
Автор: Nikolai Semko