Ускоряемся - использование пакета IPP для увеличения скорости работы советника
Мне интересны быстрые стандартные математические функции в виде кода С++. В опциях С++ компилятора есть поддержка расширенного набора инструкций, неужель эти библиотеки сильно быстрее?
В опциях какого компилятора? Вообще все эти SSE1-2 просто выполняют за одну команду операцию над векторами данных, никакой быстрой сложной математики там нет, сложение-умножение и другие простейшие операции. В последних наборах вроде включили примитивы для шифрования и что-то еще, но тут я не в курсе.
У Интела есть простенькая библиотека www.intel.com/design/pentiumiii/devtools/AMaths.zip, разработанная еще под первый SSE, там даже тест готовый есть, можно запустить и посммотреть число тактов на функцию.
Так что ИМХО после использования SSE* дальнейший выигрыш можно получить за счет распараллеливания на многоядернике. Насколько я знаю, MKL заточен на параллельную обработку и на многих задачах типа матриц рвет такие технологии распараллеливания, как OMP и TBB.
Вообще, если нужно распараллеливать свой код на С++, рекомендуют использовать TBB, для обычного Си лучше OMP
В опциях какого компилятора?
В MVS:

Спасибо за библиотечку - очень интересно.
Недавно смотрел вебинар по Parallel Studio, там была табличка, насколько Intel C++ быстрее ближайших конкурентов. Названий конкурентов не приводилось, но ясно, что это MVS & GCC. Цифры были от 40% на целочисленных до 15% на double.
Интеловский компилер умеет использовать все расширенные вплоть до SSE4, остальные пока нет. А насчет MKL вот фраза из доки:
The Intel® Math Kernel Library (Intel® MKL) contains functions that are more highly optimized for Intel microprocessors than for other microprocessors. While the functions in Intel® MKL offer optimizations for both Intel and Intel-compatible microprocessors, depending on your code and other factors, you will likely get extra performance on Intel microprocessors.
While the paragraph above describes the basic optimization approach for Intel® MKL as a whole, the library may or may not be optimized to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include Intel® Streaming SIMD Extensions 2 (Intel® SSE2), Intel® Streaming SIMD Extensions 3 (Intel® SSE3), and Supplemental Streaming SIMD Extensions 3 (Intel® SSSE3) instruction sets and other optimizations.
Вероятно, на математику крайне сильно влияет размер кэша процессора.
А для того же Intel Fortran библиотеки в т.ч. используют CUDA.
Если так важны вычисления- не лучше ли пересесть на Fortran?
Ради 15%? Это даже не смешно. Рассматриваю новое железо, только если прирост на нужном мне приложении будет не менее 40-50%. А вообще больше полагаюсь на программную оптимизацию кода.
Вероятно, на математику крайне сильно влияет размер кэша процессора.
Нет, не крайне. На компиляцию - да, серьезно. На архивацию/деархивацию тоже. Но порядок роста невелик: увеличение кэша с 3 до 6 МВ ускоряет выполнение даже на этих приложениях не более чем на 10-20%.
Ну вот, я не поленился и провел небольшой тест, вычисление числа Пи. Приаттачу файл проекта для VS2010 и 5 скомпилированных екзешников, находятся в папке Release. У меня довольно старый Core2 Duo, 2-x ядерный, 3.11 Ghz, SSE4 не поддерживает. Думаю, на более новых процах результат будет еще круче. Кстати, обратите внимание, в последнем тесте включенная OMP явно мешает интелловской встроенной параллелизации. IPP компилировал, как статическую библиотеку, надеюсь, будет работать без установки Parallel Studio.
Вот код:
#include "stdafx.h" #include <stdio.h> #include <time.h> long long num_steps = 1000000000; double step; int _tmain(int argc, _TCHAR* argv[]) { clock_t start, stop; double x, pi, sum=0.0; int i; step = 1./(double)num_steps; start = clock(); //#pragma omp parallel for private(x) reduction(+:sum) // для включения OMP раскомментируйте эту строчку for (i=0; i<num_steps; i++) { x = (i + .5)*step; sum = sum + 4.0/(1.+ x*x); } pi = sum*step; stop = clock(); printf("The value of PI is %15.12f\n",pi); printf("The time to calculate PI was %f seconds\n", (double)(stop - start)/1000.0 ); return 0; }
Результаты:
| Компилятор, опции компилятора | секунд |
|---|---|
| 1. MS C++, включена оптимизация по скорости, SSE2, модель вычислений с плав.точной: быстрый | 10.5 |
| 2. MS C++, включена оптимизация по скорости, SSE2, модель вычислений с плав.точной: быстрый, использ. OMP | 5.35 |
| 3. Intel C++ Compiler XE 12.1, SSE3, параллелизация откл, OMP откл. | 5.32 |
| 4. Intel C++ Compiler XE 12.1, SSE3, параллелизация вкл, используется IPP | 2.71 |
| 5. Intel C++ Compiler XE 12.1, SSE3, параллелизация вкл, используется IPP, использ. OMP | 2.85 |
А нет ли у Вас VCOMP100.DLL и libiomp5md.dll? Обе библиотеки нашел и запустил всё.
Процессор - Sandy Bridge G840 2.8 GHz. Ну, собственно, вот что вышло (2, 4 и 5 не выполнились из-за отсутствия этих библиотек):
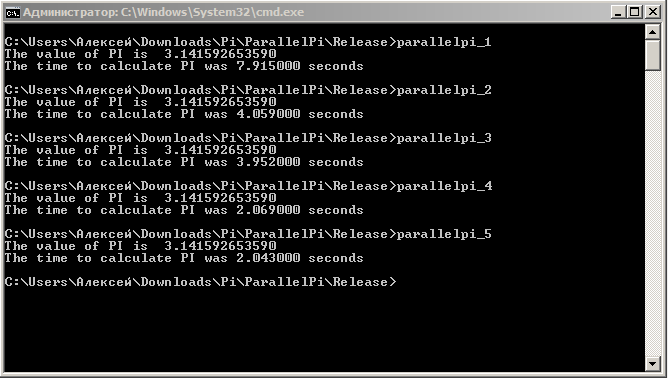
Да, ускорение есть, и очень существенное. Кстати, интересно посмотреть, сколько времени это будет вычисляться на MQL4:

Видимо, SSE3 тут и не пахнет. Конечно, медленнее примерно в 3.5 раза.
Да, камушки у нас по 2 ядра/2 потока, так что видно, насколько SB опережает старую архитектуру даже на более низкой частоте. А вот тест с MQL откровенно удивил, я ожидал худшего.
Хотя, есть такое чувство, что за последний год они компилятор переработали, возможно, применили наработки по компилятору MQL5.
И в догонку, решил проверить свой любимый C#, результаты практически совпадают с MVC: 10.66c при однопоточном, 5.47 сек при параллелизации, которая появилась в .NET 4. То есть .NET в настоящее время не хуже С++ от того же MS.
Ну а для фильтров и прочей DSP я использую IPP, тем более, там есть готовые обертки и под дотнет и под С++.
Вот так параллелиться цикл на C# 4.0, надо просто указать, чтобы массив разбивал на части. Хотя выглядит жутковато )))
static double ParallelPartitionerPi() { double sum = 0.0; double step = 1.0 / (double)num_steps; object monitor = new object(); Parallel.ForEach(Partitioner.Create(0, num_steps), () => 0.0, (range, state, local) => { for (int i = range.Item1; i < range.Item2; i++) { double x = (i + 0.5) * step; local += 4.0 / (1.0 + x * x); } return local; }, local => { lock (monitor) sum += local; }); return step * sum; }
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Всем привет!
Есть предложение сделать обзор по двум замечательным продуктам, которые могут значительно ускорить работу вашего советника и предоставить готовые реализации некоторых алгоритмов.
В последнее время занялся применением Intel Parallel Studio XE 2011 . В принципе, юзал и раньше, еще лет 12-13 назад, тогда она называлась Intel Signal Processing Library. За эти годы из набора оптимизированных DLL вырос огромный продукт, тем не менее, по прежнему можно использовать в старом стиле - просто как подключаемые DLL. Есть там две крутые библиотеки, вот их краткое описание:
А зачем вообще ускорять работу советника? Я вижу два ответа (в рамках этого форума, разумеется).
Кто еще предложит варианты? И это кому-нибудь здесь интересно?