Сортировка по ObjectName
Если представить себе, что имена хранятся в мапе для ускорения поиска, допустим, а перебор -- это обход дерева, то все сразу становится на места, нет?
Гм, и вопрос на засыпку -- какой сакральный смысл сортировки по времени создания? Это ж не ордера...
Если представить себе, что имена хранятся в мапе для ускорения поиска, допустим, а перебор -- это обход дерева, то все сразу становится на места, нет?
Да. Только мне это представлялось просто массивом с именами. Новый объект - новая ячейка с новым номером.
Гм, и вопрос на засыпку -- какой сакральный смысл сортировки по времени создания? Это ж не ордера...
ок. У меня есть куча индикаторов для выделения экстремумов. По каждому можно построить ЗЗ, канал и пр., и пр. Идея (сделал уже) была в том, чтобы каждый этот индикатор во вр. точке своего экстремума создавал гр. объект. А индикатор или индикаторы, которые строят по этим точкам ЗЗ и пр., просто считывали эти графические объекты. При таком подходе можно отвязаться от источника экстремумов и построителями по ним всякого разного. Через файл - медленно, а вот через ВР объектов - нормально.
Поэтому, в реал-тайме мне нужно было считывать последний, созданный источником объект/экстремум. Я (как оказалось неправильно) предполагал, что это будет объект с именем ObjectName(ObjectsTotal()-1).
Но я решил задачу по др. Просто имя = номеру.
Вот, например: в подокне источник волатильности, на графике инструмента видны созданные им по экстремумам гр.объекты (в натуре они не видны, но это я их сделал видимыми для наглядности), а в окне инструмента ЗЗ, построенный по этим гр.объектам.
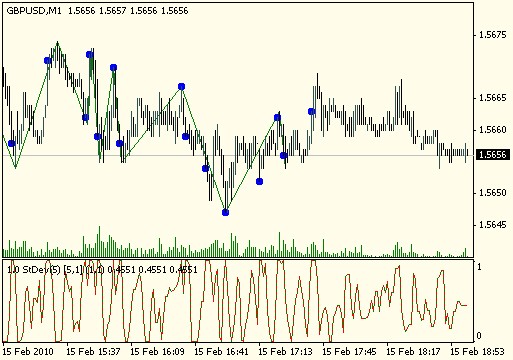
Просто на график, с имеющейся разметкой по экстремума, набрасывается индикатор, которую эту разметку считывает.
для истории... https://www.mql5.com/ru/forum/113718
Ага. Действительно. Плохо искал - каюсь.
ок. Если авторы удалят свои посты - я удалю тему.
Если представить себе, что имена хранятся в мапе для ускорения поиска, допустим, а перебор -- это обход дерева, то все сразу становится на места, нет?
Гм, и вопрос на засыпку -- какой сакральный смысл сортировки по времени создания? Это ж не ордера...
смысл, мне кажется, очевиден: получается, что при создании каждого следующего объекта терминалу приходится искать место в порядке имен, в которое его воткнуть, а потом переприсваивать номера всем объектам, которые идут после него - это ли не лишняя работа??
Дело в том еще, что разметку по экстремумам, я рассматриваю как разбивку ЦР - т.е. как новый ЦР. И мне неудобно в каждый индикатор (МАшки там, стохастики и пр.) по этому новому ценовому ряду внедрять свой источник экстремумов. Тем более, что источники могут быть любыми. Это для каждого источника - своя МАшка, МАКД, RSI и пр. А так - кинул на график, индикатор прочел разбивку и посчитал. Ну, полная аналогия с ВР инструмента - на какой инструмент кидаешь индикатор, по тому он считает.
Поэтому, я по логике ЦР по инерции и думал, что объекты лежат в том порядке, как были созданы.
Не знаю, как вам, но согласен с alsu, - неочевидная полезность лишних затрат. А для меня так вовсе - бесполезность. Кому такой подход с сортировкой может понадобиться?
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Занадобилось тут мне из индикатора получить имя/свойства последнего созданного др. индикатором гр.объекта.
Фигня вопрос, подумал: ObjectName(ObjectsTotal()-1); Других объектов, кроме как от этого индикатора, на чарте нет.
ЩАЗ! Оказывается, последним по номеру будет не тот, который создан последним, а последний в сортировке по имени объекта! Нормально, да? Для меня - нет. Но что имеем...
Для проверки написал простой скрипт, который создает объекты с именами или от 0 до 4, или от 4 до 0, а потом в цикле считывает имена объектов. Так и есть. Порядок создания не важен - важно имя объекта.
По-моему, бредовая логика. Но придется ее учитывать - куда деваться...
===
Если для кого-то это было известным или даже очевидным (!?), то для меня - нет.