쉬워요. 저는 수십 개의 데이터 세트를 생성 해제할 수 있습니다. 저는 지금 TP=50, SL=500을 조사하고 있습니다. 선생님의 마크업에는 평균 10%의 오류가 있습니다. 20%라면 자두 모델이 됩니다. 따라서 요점은 분류 오류가 아니라 모든 이익과 손실을 합산한 결과에 있습니다.
보시다시피 최상위 모델의 오차는 9.1%이고, 8.3%의 오차로 무언가를 얻을 수 있습니다. 차트는 일주일에 한 번씩 재교육을 통해 5 년 동안 총 264 번의 재교육을 통해 얻은 OOS 만 보여줍니다. 모델이 분류 오류 9.1 %로 0에서 작동하고 50/500 = 0.1, 즉 10 %가되어야한다는 것이 흥미 롭습니다. 1%가 스프레드를 먹은 것으로 나타났습니다(바당 최소값, 실제는 더 클 것입니다).
그러나 가장 중요한 것은 사용 가능한 기능의 예측력이 변하지 않거나 미래에 약하게 변한다는 이론적 증거가 있어야 한다는 것입니다. 전체 스팀롤러에서 이것이 가장 중요한 것입니다.
불행히도 아무도 이것을 찾지 못했습니다. 그렇지 않으면 그는 여기에 있지 않고 열대 섬에있을 것입니다))))
예. 하나의 트리 또는 회귀라도 패턴이 존재하고 변하지 않으면 패턴을 찾을 수 있습니다.
1. 분류 오류가 20% 미만인 교사-특성 쌍을 가진 사람이 있나요?
쉬워요. 저는 수십 개의 데이터 세트를 생성 해제할 수 있습니다. 저는 지금 TP=50, SL=500을 조사하고 있습니다. 선생님의 마크업에는 평균 10%의 오류가 있습니다. 20%라면 자두 모델이 됩니다.
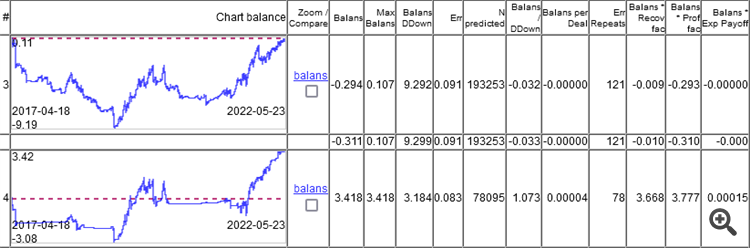
따라서 요점은 분류 오류가 아니라 모든 이익과 손실을 합산한 결과에 있습니다.
보시다시피 최상위 모델의 오차는 9.1%이고, 8.3%의 오차로 무언가를 얻을 수 있습니다.
차트는 일주일에 한 번씩 재교육을 통해 5 년 동안 총 264 번의 재교육을 통해 얻은 OOS 만 보여줍니다.
모델이 분류 오류 9.1 %로 0에서 작동하고 50/500 = 0.1, 즉 10 %가되어야한다는 것이 흥미 롭습니다. 1%가 스프레드를 먹은 것으로 나타났습니다(바당 최소값, 실제는 더 클 것입니다).
먼저 모델 내부가 쓰레기로 가득 차 있다는 사실을 깨달아야 합니다...
훈련된 나무 모델을 내부의 규칙과 그 규칙에 대한 통계로 분해하면 다음과 같습니다.
처럼 :
로 분해하고 샘플에서 규칙 오류의 발생 빈도에 대한 오류의 의존성을 분석합니다.
우리는 다음을 얻습니다.
그런 다음 이 영역에 관심이 있습니다.
규칙이 매우 잘 작동하지만 너무 드물기 때문에 10-30 개의 관찰이 통계가 아니기 때문에 통계의 진위를 의심하는 것이 합리적입니다.
먼저 모델 내부가 쓰레기로 가득 차 있다는 사실을 깨달아야 합니다...
학습된 나무 모델을 내부의 규칙과 그 규칙에 대한 통계로 분해하면 다음과 같습니다.
처럼:
를 생성하고 샘플에서 규칙 오류의 발생 빈도에 대한 규칙 오류의 의존성을 분석합니다.
우리는 얻습니다
최근 게시물의 어둠 속 한줄기 햇살
기사가 있다면 그것에 대한 기사가 있을 것입니다.
관련 기사가 있다면 있을 겁니다.
지난번 글에서도 같은 내용이었습니다. 하지만 당신의 방식이 더 빠르다면 그건 장점입니다.
더 빠르다니 무슨 뜻인가요?
더 빠르다니 무슨 뜻인가요?
속도 측면에서.
5k 샘플에서 약 5-15초
5k 샘플에서 약 5-15초가 소요됩니다.
처음부터 TC를 얻기까지의 전체 과정을 의미합니다.
두 개의 모델을 여러 번 재훈련하기 때문에 매우 빠르지는 않지만 괜찮습니다.
그리고 마지막에는 정확히 무엇을 걸러냈는지 모르겠어요.
처음부터 TC를 받기까지의 모든 과정을 말입니다.
두 모델을 여러 번 재교육하고 있기 때문에 빠르지는 않지만 괜찮습니다.
마지막에는 정확히 무엇을 걸러냈는지 모르겠어요.
5천 훈련.
유효한 60k.
모델 훈련 - 1-3초
규칙 추출 - 5-10초
각 규칙(20~30만 개의 규칙)의 유효성 확인 60만 1~2분
물론 모든 것은 근사치이며 기능 및 데이터의 수에 따라 다릅니다.