Econometria: bibliografia
I seguenti riferimenti sono disponibili sul tema "Fondamenti dell'analisi di regressione".
Davidson,Russell e James G. MacKinnon (1993). Estimation and Inference inEconometrics, Oxford: Oxford University Press.
Greene, William H. (2008). Econometric Analysis, 6th Edition, Upper Saddle River, NJ: Prentice-Hall.
Johnston, Jack e John Enrico DiNardo (1997). Metodi econometrici, 4a edizione, New York: McGraw-Hill.
Pindyck, Robert S. e Daniel L. Rubinfeld (1998). Modelli econometrici e previsioni economiche, 4a edizione, New York: McGraw-Hill.
Wooldridge, Jeffrey M. (2000). Econometria introduttiva: un approccio moderno. Cincinnati, OH: South-Western College Publishing.
Vi faccio un esempio di regressione, che non è altro che una funzione (variabile dipendente) che dipende dai suoi argomenti (variabili indipendenti, regressori). Ci sono diversi passi da seguire quando si calcola una regressione:
1. Bisogna scrivere un'equazione.
Prendo la MA caldamente favorita, ma ponderata, quindi indulgente per me, calcolandola utilizzando le 5 barre precedenti (valori di ritardo). Scrivo la formula nella forma:
EURUSD = C(1)*EURUSD(-1) + C(2)*EURUSD(-2) + C(3)*EURUSD(-3) + C(4)*EURUSD(-4) + C(5)*EURUSD(-5)
2. stima
È necessario stimare il coefficiente c(i) di questa equazione in modo che la curva del nostro MA corrisponda il più possibile alla serie iniziale EURUSD_H1-year. Otteniamo il risultato della valutazione dei coefficienti sconosciuti.
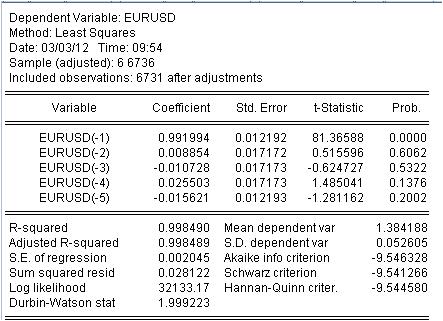
Abbiamo ottenuto i valori del nostro MA ponderato. Abbiamo l'equazione:
EURUSD = 0,991993934254*EURUSD(-1) + 0,00885362355538*EURUSD(-2) - 0,0107282369642*EURUSD(-3) + 0,0255027160774*EURUSD(-4) - 0,0156205779585*EURUSD(-5)
3. Risultati.
Quali risultati vediamo?
3.1 Prima di tutto l'equazione di Mach stessa. Voglio prestare attenzione a una piccola sfumatura. Quando calcoliamo una maschera semplice calcolando la media, non la registriamo a metà dell'intervallo ma alla sua fine per qualche motivo. La regressione viene utilizzata per calcolare l'ultimo valore in base ai precedenti.
3.2 Si scopre che i rapporti non sono costanti, ma variabili casuali con una loro deviazione.
3.3. L'ultima colonna dice che c'è una probabilità non nulla che i coefficienti dati siano proprio zero.
4. Lavorare con l'equazione
Diamo un'occhiata alla nostra miscela ponderata.

La mashka ha coperto il cofanetto così strettamente che non può essere visto, ma ci sono ancora discrepanze tra il cofanetto e la mashka. Ecco le statistiche di queste discrepanze

Vediamo un'enorme dispersione da -137 punti a 215 punti. Anche se la deviazione standard = 20 punti.
Conclusione.
Abbiamo ricevuto una qualità insolitamente alta della maschera con le caratteristiche statistiche note utilizzando la regressione.
L'ultimo. Yusuf! Non andare sotto il tram, non far ridere il pubblico su un altro filo.
Pronto a discutere la letteratura e l'applicazione del tema della regressione.
3. Risultati.
Quali risultati vediamo?
3.1 Prima di tutto, l'equazione di Mach stessa. Voglio sottolineare una sottigliezza qui. Quando calcoliamo una maschera semplice ottenendo la media, per qualche motivo non mettiamo questa media nel mezzo dell'intervallo, ma alla sua fine. La regressione viene utilizzata per calcolare l'ultimo valore in base ai precedenti.
3.2 Si scopre che i rapporti non sono costanti, ma variabili casuali!
3.3 L'ultima colonna dice che c'è una probabilità non nulla che i coefficienti dati siano zero.
1. scusate il sale in più nella ferita - la serie originale è comunque non stazionaria.
2) Questa probabilità è quasi sempre non zero.
3. avete controllato la multicollinearità? IMHO se si elimina la multicollinearità rimane solo una variabile. Avete determinato i fattori significativi?
4. Quante osservazioni avete per 5 variabili?
Come fai ad essere così alfabetizzato?
1. scusate il sale in più nella ferita - la serie originale è comunque non stazionaria.
Naturalmente, non siamo interessati agli altri.
2. Questa probabilità è quasi sempre non zero.
Non è vero. Se non è zero, è un errore di forma funzionale.
3. avete controllato la multicollinearità? IMHO se si elimina la multicollinearità rimane solo una variabile. Avete identificato i fattori significativi?
Cosa sono i "fattori significativi" non lo capisco, ma per favore guardate i coefficienti di correlazione.
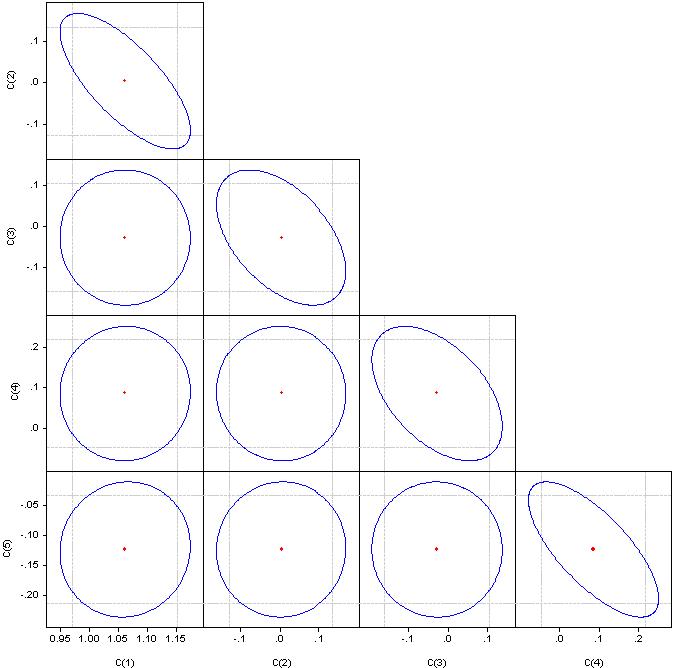
Se è un cerchio, la correlazione è zero. Se uniti in una linea retta, la correlazione tra la coppia di coefficienti corrispondente è del 100%.
4. Quante osservazioni avete per 5 variabili?
6736 osservazioni
Il primo passo in qualsiasi modello di regressione è la selezione dei fattori. Se non si applica la regressione stepwise (con inclusioni o eccezioni), allora bisogna selezionarli manualmente.
Multicollinearità - stretta dipendenza tra le variabili dei fattori incluse nel modello. Non la correlazione dei coefficienti, ma la correlazione dei fattori.
La presenza di multicollinearità porta a:
- distorsione del valore di i parametri del modello, che tendono a sovrastimare;
- condizionamento debole del sistema di equazioni normali;
- complicazione di il processo di determinazione di le caratteristiche delfattore più significativo .
Un indicatore di multicollinearità è che i coefficienti di correlazione a coppie superano il valore di 0,8. Qui i fattori hanno chiaramente una forte correlazione. Per eliminarlo dobbiamo eliminare i fattori ridondanti. O manualmente o tramite regressione graduale.
Guarda nel pacchetto - regressione a gradini o regressione ridge.
E 6736/4 sono troppe osservazioni. Abbiamo bisogno di google - non ricordo come determinare il numero ottimale di osservazioni in base al numero di fattori.
Sia così gentile da partecipare ai miei thread di econometria.
Continuiamo con la selezione della letteratura.
Il prossimo argomento sono i ritardi di Almon.
Come notato sopra, ci sono difficoltà con i coefficienti di regressione calcolati usando il metodo dei minimi quadrati. È emersa l'idea di imporre ulteriori vincoli ai coefficienti di regressione in cui la variabile dipendente è determinata da diversi ritardi della variabile indipendente come nell'equazione di cui sopra.
L'idea è quella di imporre dei vincoli sui coefficienti ai valori di ritardo tali che obbediscano a qualche distribuzione polinomiale. EViews chiama questo approccio "polinomi a ritardo distribuito (PDL)". La scelta del particolare grado del polinomio è determinata sperimentalmente.
Questo approccio è descritto qui.
Ecco un esempio pratico.
Costruiamo un analogo di una scala con un periodo di 5, ma i coefficienti della barra dovrebbero essere su un polinomio di 3° ordine.
In EViews è scritto come segue per EURUSD
EURUSD PDL(EURUSD(-1), 5,3)
In una forma più familiare:
EURUSD = + C(5)*EURUSD(-1) + C(6)*EURUSD(-2) + C(7)*EURUSD(-3) + C(8)*EURUSD(-4) + C(9)*EURUSD(-5) + C(10)*EURUSD(-6)
Stimiamo i coefficienti tramite OLS e otteniamo il risultato della stima dei coefficienti:
EURUSD = + 0,934972661616*EURUSD(-1) + 0,139869148138*EURUSD(-2) - 0,093599954464*EURUSD(-3) - 0,0264992987207*EURUSD(-4) + 0,0801064628352*EURUSD(-5) - 0,0348473223286*EURUSD(-6)
La statistica sulla stima dell'equazione è la seguente:
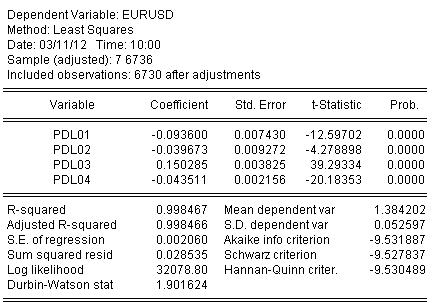
Dalle statistiche possiamo vedere un ottimo livello di mappatura del quoziente iniziale dal nostro sventolare da Almon R-square = 0,998467
Graficamente sembra:

La regressione (la sventagliata di Almon) ha coperto completamente il quoziente originale.
E un ultimo cucchiaio di miele.
Vediamo qual è il residuo, cioè la differenza tra il nostro mash di Almon e il cotier originale. La stazionarietà/non stazionarietà di questo residuo è molto importante.

Il test della radice unitaria afferma che il residuo è stazionario.
I mash-up che usiamo non hanno questo livello di adattamento al quoziente originale e la proprietà di stazionarietà dell'errore di adattamento.
Vorrei spostare i link da un thread vicino.
Questi collegamenti riguardano l'area più problematica: la prognosi.
Il primo è un allegato. c'è una lista di riferimenti.
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Se cercate su Google la parola "econometria", otterrete una lista enorme di letteratura, che è difficile da capire anche per un esperto. Un libro dice una cosa, un altro - un'altra, il terzo - solo una compilazione dei primi due con alcune imprecisioni. Ma l'approccio "dai libri" combina non chiarezza di applicazione di questi libri nella pratica. Non mi interessa che gli intellettuali scendano in sciocchezze da nerd.
Analogamente ad altre liste di libri in questo forum, per esempio, sulla statistica, propongo di compilare collettivamente una lista di libri di testo, monografie, dissertazioni, articoli, risorse Internet e pacchetti software che, secondo l'opinione dei partecipanti, sarebbero rilevanti per la misurazione dei dati economici - per l'econometria. Tuttavia, non dimentichiamo che la statistica matematica è la sorella maggiore dell'econometria. Suggerisco di non includere nulla relativo all'analisi tecnica in questa lista.
Per escludere lo scivolamento nella botanica, propongo un approccio specifico alla lista dei libri. Postiamo i link (i libri stessi) solo se conosco il software che implementa gli algoritmi di questi libri. Ho ristretto il campo a EViews. Questo programma non ha nessun vantaggio sugli altri, ha vantaggi e svantaggi, ma lo prendo come un rubricatore per l'econometria. Ho allegato l'indice del secondo volume del manuale d'uso, per delineare subito la più ampia gamma possibile di problemi. A causa dell'approccio proposto, diverse aree utilizzate in econometria, ma non incluse in EVIEWS, ad esempio NS, wavelets, ecc. Naturalmente sono benvenuti anche i riferimenti a tali programmi e libri.
Se non possiamo solo fornire un link alla fonte dell'algoritmo, ma anche fare calcoli specifici, questo thread non avrà alcun valore.
Suggerisco di usare i numeri dei capitoli dell'allegato per raggruppare i libri.
Quindi, per favore, sostenete.