Aprendizaje automático en el trading: teoría, práctica, operaciones y más - página 436
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Está funcionando, ¡gracias! Es interesante cómo funciona...
¿Busca la opción más parecida o hace una media entre varias? Aparentemente encuentra 1 mejor. Creo que debería ir a por 10 o incluso 100 variantes y buscar la predicción media (el número exacto debería determinarlo el optimizador).
Sí, aquí muestra 1 mejor, no se molestó con muchas variantes, se puede tratar de rehacer si usted entiende mi escritura )
Nunca he podido aprender a operar con beneficios utilizando sólo los precios. Pero el modelo de patrón sí, así que la elección es obvia :)
Una cosa es encontrar un "patrón" y otra muy distinta es que dé una ventaja estadística. En mi opinión, lo dudo mucho por alguna razón. De hecho la búsqueda de patrones por convolución (producto, diferencia) a lo largo de toda la longitud de una serie histórica con promediación es como hacer una regresión en NS con UNA NEURONA, que es el modelo lineal más simple con signos extremadamente estúpidos, un trozo de precio como es.
Una cosa es encontrar un "patrón" y otra cosa es encontrar una ventaja estadística. En mi opinión, lo dudo mucho. De hecho la búsqueda de patrones por convolución (producto, diferencia) sobre toda la longitud de las series históricas con promediado, es como hacer regresión en NS con UNA NEURONA, que es el modelo lineal más simple, con características extremadamente tontas, un trozo de precio tal cual.
Si se trata de una sola neurona, entonces con un número de entradas igual a la longitud del patrón, (patrón de 30 barras = 30 entradas NSb de 500 barras = 500 entradas NS).
En mi opinión, muchas neuronas de las capas internas del SN son análogas a la memoria, 10 - 50 - 100 neuronas adicionales son correspondientemente 10 - 50 - 100 variantes memorizadas de señales de entrada. Y comparando el patrón con 375000 variantes del historial (M1 durante un año) tenemos una memoria absolutamente precisa y completa, en lugar de 10 -50 - 100 variantes más frecuentes. Luego, a partir de esta memoria, el buscador de patrones identifica N resultados más similares y obtiene la predicción media, mientras que la red neuronal aumenta los pesos de las conexiones entre las neuronas con cada patrón similar.
No está claro por qué hay que aplicar la convolución, supongo que propones convolucionar el patrón buscado con cada variante del historial, como resultado obtenemos la 3ª secuencia temporal - ¿y cómo ayuda a determinar la similitud del patrón y la variante que se comprueba?Si es una neurona, entonces con el número de entradas igual a la longitud de la plantilla, (plantilla de 30 barras = 30 entradas NS de 500 barras = 500 entradas NS).
Otra cosa que no está clara es por qué se debe aplicar la convolución, supongo que propones convolucionar el patrón buscado con cada variante de la historia, como resultado obtenemos la 3ª secuencia temporal - ¿y cómo ayuda a definir la similitud del patrón y la variante probada?
Sí, aquí se muestra 1 mejor, no se molestó con muchas variantes, puede intentar rehacerlo si entiende mi escritura )
al mirar la foto, algo no está bien...
He aquí un ejemplo al azar
Su línea de previsión azul va muy inclinada hacia abajo, con un movimiento débil de una variante similar...
Aquí se acaba de photoshopear esta variante y resultó no tan empinada y más lógica por la idea.
mientras miro la foto, algo no está bien...
He aquí un ejemplo al azar
Su línea azul de previsión desciende de forma muy pronunciada, con un movimiento débil de una variante similar...
Aquí se acaba de photoshopear esta variante y resultó no tan empinada y más lógica por la idea.
Lo he notado :) en ciertas situaciones no cuenta el ángulo correctamente por alguna razón, comenzó cuando lo reescribí de una versión de un solo marco de tiempo a una de varios marcos de tiempo, y todavía no he descubierto dónde está el fallo
Por cierto, es posible que no lo haya contado bien del todo... no se me ocurrió comprobarlo con Photoshop. El ángulo entre los gráficos anteriores y las previsiones debe ser el mismo
Exactamente.
Colapsas el patrón y la fila donde los extremos eran más similares, es simple. Por ejemplo, tienes una fila {0,0,0,1,2,3,1,1,1} y quieres encontrar un patrón {1,2,3} en ella, la convolución te dará {0,0,0,3,8,14,11,8, 6} (contados a ojo) 14 como máximo donde está la "cabeza" de nuestro patrón. Por supuesto, es deseable normalizar los vectores antes de la convolución, ya que de lo contrario habrá extremos en lugares con números grandes.
¿Por qué complicar las cosas así? ¿Por qué debemos buscar un extremo en la convolución si podemos buscar {0,0,0,1,2,3,1,1,1} específicamente en la fila {1,2,3}? Aparte de aumentar la complejidad y el tiempo de cálculo, no veo ninguna ventaja.
¿Por qué complicar las cosas así? ¿Por qué debemos buscar un extremo en la convolución si podemos buscar {0,0,0,1,2,3,1,1,1} específicamente en la serie {1,2,3}? Aparte de la complicación y el mayor tiempo de cálculo, no veo ninguna ventaja.
Hmmm... ¿qué quiere decir con "buscar específicamente"? Por favor, dame un ejemplo de algoritmo más rápido que la convolución.
Se pueden utilizar dos operaciones: longitud de diferencia vectorial y producto escalar, longitud de diferencia, créanme es de 3 a 10 veces más lento, diferencia de componentes, elevar al cuadrado, suma, extracción de raíces, y la convolución es multiplicar y sumar.
Hay que tomar cada trozo de una fila de longitud 3 como un vector y compararlo por "similitud" con nuestro {1,2,3}
Hmmm... ¿qué quiere decir con "buscar específicamente"? Por favor, dame un ejemplo de un algoritmo más rápido que la convolución.
La más fácil es desplazar por pasos el ancho de la ventana del ejemplo buscado a través de la secuencia y encontrar la suma de los valores abs. de los deltas:
0,0,0 y 1,2,3 error = (1-0)+(2-0)+(3-0)=6
0,0,1 y 1,2,3 error = (1-0)+(2-0)+(3-1)=5
0,1,2 y 1,2,3 error = (1-0)+(2-1)+(3-2)=3
1,2,3 y 1,2,3 error = (1-1)+(2-2)+(3-3)=0
2,3,1 y 1,2,3 error = (2-1)+(3-2)+Abs(1-3) =4
Donde el mínimo error es la máxima similitud.
Notado :) en ciertas situaciones, por alguna razón no cuenta el ángulo correctamente, comenzó después de que reescribí de la versión de un solo marco de tiempo a la versión de múltiples marcos de tiempo, y nunca captó donde está el error
Por cierto, es posible que estuviera contando mal del todo... no llegué a comprobarlo con photoshop. Debería obtener el mismo ángulo entre los gráficos anteriores y las previsiones.
Todavía no estoy seguro de que sea correcto considerar los gráficos como similares con una diferencia tan grande en los ángulos de inclinación. Utilizando el mismo ejemplo:
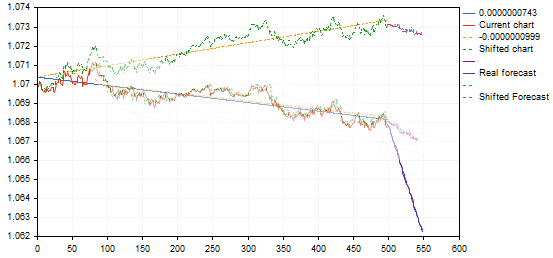
la variante encontrada da un pullback desde el punto superior de la tendencia o el final de la misma, al trasladarla al gráfico del patrón dará una previsión de continuación de la tendencia decreciente y no de reversión - esencialmente una señal inversa. Algo no está bien aquí.... tal vez no necesitemos estas transformaciones afines....? ¿Y la simple correlación (error mínimo) es suficiente?