Aprendizaje automático en el trading: teoría, práctica, operaciones y más - página 169
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
si se toman los tapones, nada...
Pero también hay vidrio, T&S, OI...etc...
no te pagarán.
Ya veo, gracias.
Si haces varias operaciones en un minuto, no sobrevivirás en forex... e incluso si por algún milagro tienes una oportunidad entre 1.000.000, no hay garantía de que te paguen.
Pues bien, las condiciones comerciales vuelven a ser las mismas.
Si no eres capaz de usarlo, R-ka tampoco te ayudará. Una cosa es ser consultor de NS y otra cosa es ser usuario. Son cosas muy diferentes...
No creo que nadie lo haga, se llama hacer el absurdo y su objetivo era que el moderador entendiera lo absurdo de sus declaraciones, Reshetov no tiene nada que ver...
Has decidido calcular la media en excel y escribes algo en el foro de mql, eres un parásito porque puedes hacerlo en mt5, mql no ha ayudado a la comunidad de mql, ¿entendido?
Eres un parásito Michael, porque usas JProjection, así es... :)
R no tiene nada que ver, ¿qué más da en qué se escriba? es una cuestión de comodidad, no más.... ¡¡¡¡Aquí, Reshetov escribió su JProjected en Java, prohibirlo, no es mql, no es útil, este como-se-llame - parásito !!!!
es una palabra.
Reshetov realiza sus programas bajo la premisa de que los resultados se utilizarán en la MT. Ha escrito muchos asesores, se le han ocurrido miles de ideas y todo funciona para MT, así que ha hecho mucho como divulgador, mucho.
Puedes escribir todo lo que quieras en el vencejo de Dios, pero necesitas que la comunidad pueda utilizarlo en la MT, de lo contrario no sirves para la comunidad. Una comunidad que se ha cuidado y alimentado, que se ha ampliado invirtiendo enormes cantidades de dinero.
Si tienes una idea factible, no es difícil trasladarla a la ACM. Y el hecho de que escriba aquí y no en los foros de R es comprensible: R no tiene fondo, no es fácil encontrar una comunidad altamente especializada. Y para la comunidad de MT es un activo incuestionable.
Validación cruzada en muestras adicionales en un marco temporal diferente.
Supongamos que tengo un año de datos de entrenamiento. Quiero entrenar 12 modelos: uno con datos de enero y otro con datos de febrero
Esto es un ajuste.
Tomemos como ejemplo datos sencillos y claros y modelémoslos... La formación. Puntos azules - tendencia. Puntos rojos-validación.
n1;n2;objetivo
1;0;1
1;1;2
1;0;1
1;1;2
1;0;1
1;0;1
1;1;2
1;0;1
1;0;1
1;0;1
Arriba a la izquierda 50% de tendencia, 50% de validez. Arriba a la derecha, con mezcla.
Para OOS(fondo) aumentamos la muestra añadiendo estúpidamente la muestra anterior. Ya que en realidad no conocemos el futuro,
introduzcamos un punto con el valor 1,5. Mientras la prueba (OOS) se corresponda con el punto de entrenamiento, todo está bien.
A 1,5, el modelo tropieza... Omitiendo las pequeñas ventajas de utilizar la validación y la primitividad
En la vida real tenemos más o menos la misma imagen...
Esta es la opinión oficial del propietario del recurso.
Desde aquí
Por favor, deja las acusaciones.
Cada lengua tiene su lugar. R es excelente para la investigación interactiva. Es el segundo día que lo exploro (antes leí el libro) y realmente parece un depurador potente con visualización de las entrañas.
Trabajar con R ha revelado inmediatamente nuestros puntos débiles:
Ya en 2001 lanzamos la primera plataforma de trading algorítmico en MQL. Cada vez aumentamos sus posibilidades, pero el conjunto de herramientas matemáticas no era tan bueno. Desarrollamos el análisis, el acceso a los datos, el probador, los cálculos distribuidos, y luego llegamos al punto de vender los productos.
Y entonces quedó claro que la mayoría de las soluciones estaban atascadas en un círculo vicioso de análisis, indicadores y ajustes. Tenemos que dejar que los desarrolladores lleguen al siguiente nivel de capacidad matemática.
Por eso, hace algún tiempo hemos empezado a ampliar las bibliotecas matemáticas en MQL5 y también hemos lanzado en beta Alglib, Fuzzy y Stat. Le permitirán transferir fácilmente algunos modelos de otros sistemas a MQL5 y elevar la clase de soluciones analíticas creadas parala plataforma Metatrader 5.
En los próximos 2 meses verás los avances que haremos en el desarrollo del entorno matemático.
Agradecemos y damos la bienvenida a los debates y artículos sobre paquetes matemáticos complejos. Escribe y envía solicitudes de artículos a Rashid Umarov. Nuestra tarea es animar y educar a los operadores en técnicas más sofisticadas, no encerrarnos en nuestro propio mundo MQL5.
Por supuesto, defendemos y seguiremos defendiendo nuestra lengua y plataforma de los ataques, pero también trabajamos para desarrollarlas. Así que todo irá bien.
PS.
Énfasis mío
En el mundo real tenemos una imagen como esta...
No entiendo del todo su conclusión.
El modelo sólo funcionará mientras funcione con datos conocidos? Es decir, al pronosticar sobre nuevos datos, empezará a tropezar de todos modos, independientemente del tipo de desglose (con/sin mezcla).
La única manera de ahorrar dinero es no comerciar.
Lo hago no sólo para seleccionar los parámetros del modelo, sino también para seleccionar los indicadores y sus parámetros. Descargo 10000 indicadores con diferentes parámetros y lags de mt5, luego uso la genética para buscar tanto los indicadores utilizados en esta lista como los parámetros del modelo (árboles en el bosque, capas en la neurona, etc.). Se puede decir que esta es mi forma de encontrar dependencias constantes.
Si tomo un conjunto de indicadores estándar con parámetros estándar en MT5, entonces no tendré ningún modelo validado de forma cruzada con ellos, ya sea neuronka o trees. Encontrar un conjunto de indicadores en los que los modelos den resultados positivos en dicha validación cruzada es un logro con mucho trabajo y tiempo. Un resultado positivo es un criterio cierto de que existen correlaciones constantes entre todos los predictores en el espacio y el tiempo. Sea cual sea el intervalo que se tome para el entrenamiento, el modelo encontrará las mismas dependencias y se basará en ellas.
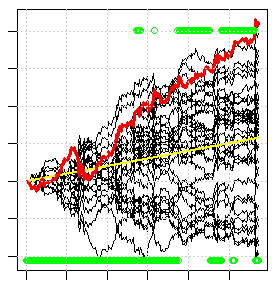
La siguiente imagen es un ejemplo de esta validación cruzada. Cada línea negra es el resultado (crecimiento del saldo) del comercio de cada modelo individual del conjunto. La línea roja es el resultado de la negociación de la mayoría de los modelos del conjunto. Alrededor de 1/3 de los modelos que hay no consiguen ningún beneficio, a pesar de que la genética tardó más de un día en probar todas las variantes, es decir, este es uno de los mejores resultados que se pueden encontrar, aunque el resultado no es ni siquiera muy bueno. Si marcas cualquier indicador estándar de forma gratuita, todo este abanico negro bajará y la línea roja bajará fuera de la pantalla.
Buscando soluciones... en estas realidades.
------------------------------------------------------------------------
La reducción en el lado izquierdo de la pantalla no es mala, el modelo no describe esta zona...