Discussion of article "Neural networks made easy (Part 27): Deep Q-Learning (DQN)"
Для тестирования была создана сверточная модель следующей архитектуры:
- Source data layer, 240 elements (20 candles, 12 neurons per description of one candle).
- Convergent layer, source data window 24 (2 candles), step 12 (1 candle), output 6 filters.
- Convergent layer, source data window 2, step 1, 2 filters.
- Collapse layer, source data window 3, step 1, 2 filters.
- Convergent layer, source data window 3, step 1, 2 filters.
- Fully connected neural layer with 1000 elements.
- Fully connected neural layer of 1000 elements.
- Fully connected layer of 3 elements (result layer for 3 actions).
Has anyone figured out how to do this?
I have Transfer Lerning, it works, compiled, but how to create such a model on it?
Has anyone figured out how to do it?
I have Transfer Lerning, it works, compiled, but how to create such a model on it?
1. Start TransferLearning.
2. Do NOT open any model.
3. Just drop in a new model, like adding new neural layers.
4. Click save model and specify the name of the file you will load from the programme.
1. Launch TransferLearning.
2. Do NOT open any model.
3.Just drop in a new model, like adding new neural layers.
4. Click save model and specify the name of the file you will load from the programme.
What kind of layers and what to select? You have several types and several parameters there
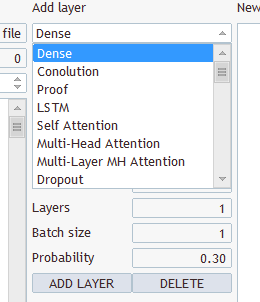
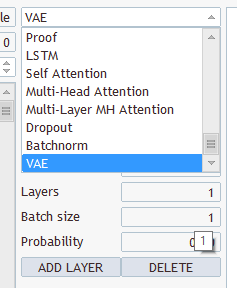
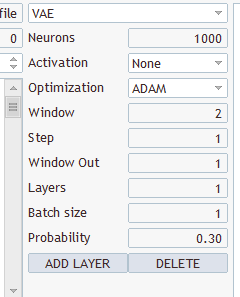
Choose any, save under "EURUSD_PERIOD_H1_Q-learning.nnw", run Q-learning.mq5, it writes in the log.
2022.10.14 15:09:51.743 Experts initialising of Q-learning (EURUSD,H1) failed with code 32767 (incorrect parameters)
And in the Experts tab:
2022.10.14 15:09:51.626 Q-learning (EURUSD,H1) OpenCL: GPU device 'NVIDIA GeForce RTX 3080' selected
2022.10.14 15:09:51.638 Q-learning (EURUSD,H1) EURUSD_PERIOD_H1_Q-learning.nnw
Hello Mr Gizlyk, First of all, I would like to thank you for your well-founded series. However, as a latecomer I have to struggle with some problems in understanding your current article. After I was able to reconstruct the VAE.mqh file and the CBufferDouble class from your previous articles, i can compile your sample application from this article. To test I tried to create a network with your program NetCreater. I gave it up after many tries. The saved networks were not accepted by your application from this article. Couldn't you also offer the network you created for download? Thanks again for your work!
Hello Mr Gizlyk, First of all, I would like to thank you for your well-founded series. However, as a latecomer I have to struggle with some problems in understanding your current article. After I was able to reconstruct the VAE.mqh file and the CBufferDouble class from your previous articles, i can compile your sample application from this article. To test I tried to create a network with your program NetCreater. I gave it up after many tries. The saved networks were not accepted by your application from this article. Couldn't you also offer the network you created for download? Thanks again for your work!
Good afternoon!
After training is not saved, trained model:,
2024.06.01 01:12:26.731 Q-learning (XAUUSD_t,H1) XAUUSD_t_PERIOD_H1_Q-learning.nnw
2024.06.01 01:12:26.833 Q-learning (XAUUSD_t,H1) Iteration 980, loss 0.75659
2024.06.01 01 01:12:26.833 Q-learning (XAUUSD_t,H1) ExpertRemove() function called
Trying to run the tester error:
2024.06.01 01 01:16:31.860 Core 1 2024.01.01 01 00:00:00 XAUUSD_t_PERIOD_H1_Q-learning-test.nnw
2024.06.01 01 01:16:31.860 Core 1 testerstopped because OnInit returns non-zero code 1
2024.06.01.01 01:16:31.861 Core 1 disconnected
2024.06.01.01 01:16:31.861 Core 1 connection closed
Help please who has encountered such how did you solve the problem?
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
New article Neural networks made easy (Part 27): Deep Q-Learning (DQN) has been published:
We continue to study reinforcement learning. In this article, we will get acquainted with the Deep Q-Learning method. The use of this method has enabled the DeepMind team to create a model that can outperform a human when playing Atari computer games. I think it will be useful to evaluate the possibilities of the technology for solving trading problems.
You have probably already guessed that deep Q-learning involves using a neural network to approximate a Q-function. What is the advantage of such an approach? Remember the implementation of the cross-entropy tabular method in the last article. I emphasized that the implementation of a tabular method assumes a finite number of possible states and actions. So, we have limited the number of possible states by clustering the initial data. But is it so good? Will clustering always produce better results? The use of a neural network does not limit the number of possible states. I think this is a great advantage when solving trading related problems.
The very first obvious approach is to replace the table from the previous article with a neural network. But, unfortunately, it's not that easy. In practice, the approach turned out to be not as good as it seemed. To implement the approach, we need to add a few heuristics.
First, let's look at the agent training goal. In general, its goal is to maximize the total rewards. Look at the figure below. The agent has to move from the cell start to the cell Finish. The agent will receive the reward once, when it gets to the Finish cell. In all other states, the reward is zero.
The figure shows two paths. For us it is obvious that the orange path is shorter and more preferable. But in terms of reward maximization, they are equivalent.
Author: Dmitriy Gizlyk