Neural networks. Questions from the experts. - page 5
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
Agreed. That's what I was asking, what is the relationship between error and profit, preferably on OOS....))
Too joo you said that the nued result could be due to data normalisation, I replied that there was none.
I agree with Leo that it's not always the error criterion that determines the final profit, but it's the error that matters in the task I have in front of me now. I'll post the forecast made by the grid tonight to get others' opinions on the quality of the forecast and possible improvements)
Хорошо, чуть позже (часа через 2-3), попробую обоснованно показать, каким образом профит (или что то другое, не важно, что мы хотим получить от сети) зависит от фитнес функции.
А гарантию того, что мы получим профит в будующем, конечно, никто дать никогда не сможет. А вот к чему стремится должна сетка, пожалуй, мы должны определять для неё однозначно.
You don't have to waste your time, because the difference between "want" and "get" is not philosophical at all, although it is formulated in philosophical terms of "subjective" and "objective".
The fact that the results on the fit are inversely proportional to the root-mean-square error is something we know without you.
Unequivocally the net must aim for a profit on the OOS. Otherwise there is no point.
То, что результаты на подгонке обратно пропорциональны среднеквадратичной ошибке - это мы и без Вас знаем.
Are you using root mean square error as well? You are the father of emc networking. :)
Reshetov wrote(a) >>
Definitely the net must aim for a profit on the OOS. Otherwise there is no sense.
It's understandable. Another question is how it should strive for it.
Вы тоже что ли используете среднеквадратичную ошибку? Отец эмкуэльных сетей Вы наш. :)
Это и ежу понятно. Другой вопрос, как она должна к этому стремится.
I don't use the root-mean-square error for trading, as it only characterizes the quality of the fit.
Therefore the error in the sample should in no way tend to
As promised, I'm posting a picture and an explanation of it. Network: MLP one hidden layer. 2000 points in training. 1000 on the out of sampler) I received current and pre EMA from the first picture and pre-close from the first and the second one. That's all! Why all and so little? Because increasing number of neurons, layers, inputs etc. doesn't influence result at all. This is what scares me) And what is shown as a prediction, you can get, well, a very simple formula, which is calculated by hand. Why is it so unclear to me. What should I change? Can it be done better?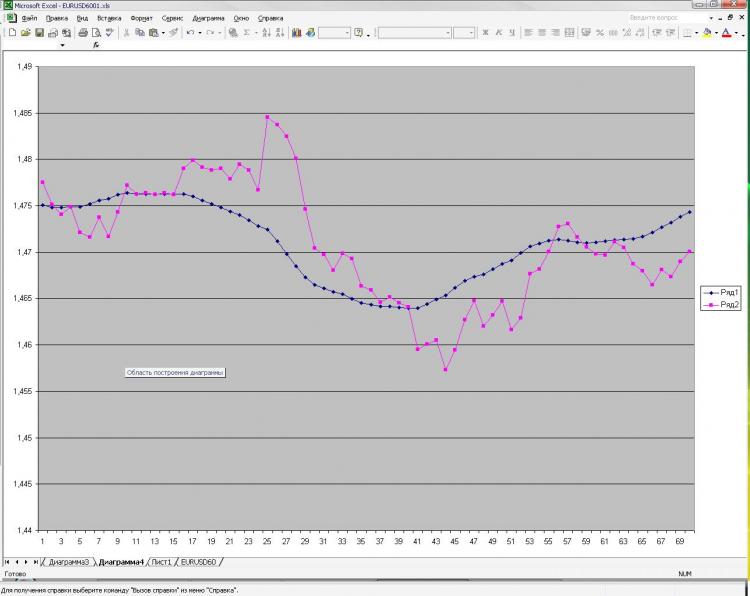
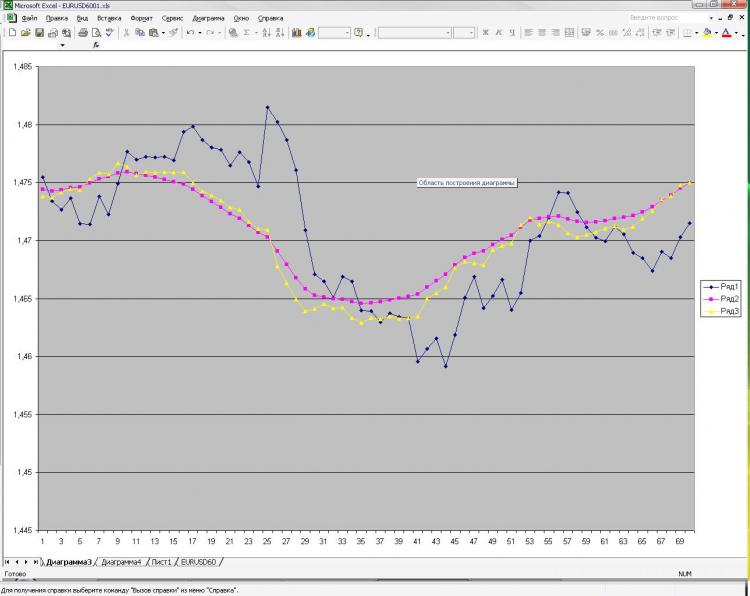
Как и обещал выкладываю картинку и пояснения к ней. Сеть: MLP один скрытый слой. 2000 точек в обучении. 1000 на аут оф сампле) На вход были даны текущее и пред значение ЕМА с первой картинки, а также пред клоуз с первой и второй картинки. Все! Почему все и так мало? Да потому, что увеличение кол-ва нейронов, слоев, входов и т.д. на результат ВООБЩЕ не влияет. Это меня и пугает) Причем, то, что изображено в качестве прогноза, можно получить, ну очень простой формулой, которая ручками считается. Почему так мне непонятно. Что нужно менять? Можно ли сделать лучше?
You have described the problem of approximation. Two "reference" points are not enough to describe the shape. In addition, you supply one more clout point each, which not only does not describe the curvature, but also a straight line. Try at least 3 points from each set of input parameters. I.e. three EMA points and three clause points, so 6 input neurons, with 6 to 12 neurons in the hidden layer. A larger number of neurons in the hidden layer is not reasonable for this problem.
Изначально я давал 40 последних клоузов с первого и второго чарта, а также 40 значений ема с первого чарта - результат тот же, почти один в один! Давал вместо абс значений %-ые приращения - тоже самое! Разница лишь в сотых долях %. Если итоговый "прогноз" и был более плавный, но я разницы на заметил. Можно подать одино из пред значений ЕМА, которую и нужно получить на выходе. В этом случае прогноз 100% т.к. формула ЕМА как Вы помните реккурентная, но в этом случае сети не нужны))))) Вот я и не могу понять, что такое, где я ошибаюсь.
Give me a sample here, I'll try it in Statistica