MQL5 开发的自动交易示例的文章


您应该知道的 MQL5 向导技术(第 06 部分):傅里叶(Fourier)变换
约瑟夫·傅里叶(Joseph Fourier)引入的傅里叶变换是将复杂的数据波分解构为简单分量波的一种方法。 此功能对交易者来说可能更机敏,本文将对此进行关注。


在莫斯科交易所(MOEX)里使用破位挂单的自动兑换网格交易
本文探讨在莫斯科交易所(MOEX)里基于破位挂单的网格交易方法如何在 MQL5 智能系统中实现。 在市场上进行交易时,最简单的策略之一是设计“捕捉”市场价格的订单网格。

神经网络变得轻松(第三十七部分):分散关注度
在上一篇文章中,我们讨论了在其架构中使用关注度机制的关系模型。 这些模型的具体特征之一是计算资源的密集功用。 在本文中,我们将研究于自我关注度模块内减少计算操作数量的机制之一。 这将提高模型的常规性能。

MQL5 中的范畴论 (第 7 部分):多域、相对域和索引域
范畴论是数学的一个多样化和不断扩展的分支,直到最近才在 MQL5 社区中得到一些报道。 这些系列文章旨在探索和验证一些概念和公理,其总体目标是建立一个开放的函数库,提供洞察力,同时也希望进一步在交易者的策略开发中运用这个非凡的领域。


神经网络实验(第 5 部分):常规化传输到神经网络的输入参数
神经网络是交易者工具包中的终极工具。 我们来检查一下这个假设是否成立。 在交易中运用神经网络,MetaTrader 5 是最接近自给自足的媒介。 为此提供了一个简单的解释。
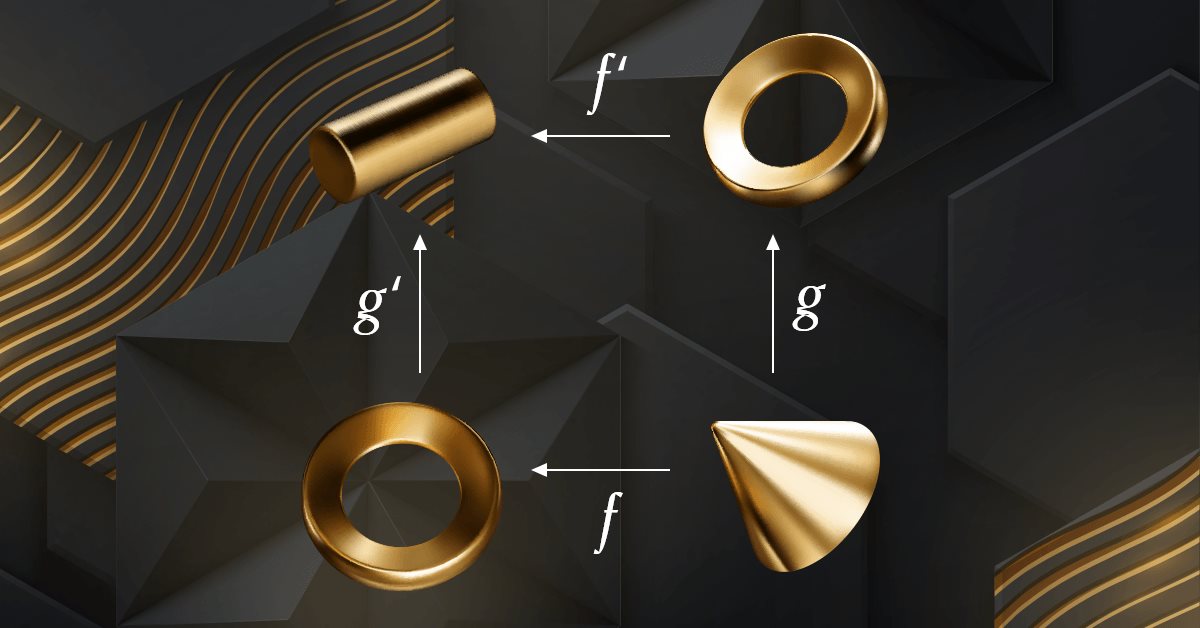
MQL5 中的范畴论 (第 6 部分):单态回拉和满态外推
范畴论是数学的一个多样化和不断扩展的分支,直到最近才在 MQL5 社区中得到一些报道。 这些系列文章旨在探索和验证一些概念和公理,其总体目标是建立一个开放的函数库,提供洞察力,同时也希望进一步在交易者的策略开发中运用这个非凡的领域。

MetaTrader 中的多机器人:从单图表中启动多个机器人
在本文中,我将研究一个简单的模板,用来创建通用的 MetaTrader 机器人,该机器人可以在多个图表上使用,同时仅附加到一个图表,无需在每个单独的图表上为每个机器人实例进行配置。

神经网络实验(第 4 部分):模板
在本文中,我将利用实验和非标准方法开发一个可盈利的交易系统,并验证神经网络是否对交易者有任何帮助。 若在交易中运用神经网络的话, MetaTrader 5 完全可作为一款自给自足的工具。 简单的解释。

神经网络变得轻松(第三十六部分):关系强化学习
在上一篇文章中讨论的强化学习模型中,我们用到了卷积网络的各种变体,这些变体能够识别原始数据中的各种对象。 卷积网络的主要优点是能够识别对象,无关它们的位置。 与此同时,当物体存在各种变形和噪声时,卷积网络并不能始终表现良好。 这些是关系模型可以解决的问题。

构建自动运行的 EA(第 14 部分):自动化(VI)
在本文中,我们将把本系列中的所有知识付诸实践。 我们最终将建立一个 100% 自动化和功能性的系统。 但在此之前,我们仍然需要学习最后一个细节。
多层感知器和反向传播算法(第 3 部分):与策略测试器集成 - 概述(I)
多层感知器是简单感知器的演变,可以解决非线性可分离问题。 结合反向传播算法,可以有效地训练该神经网络。 在多层感知器和反向传播系列的第 3 部分当中,我们将见识到如何将此技术集成到策略测试器之中。 这种集成将允许使用复杂的数据分析,旨在制定更好的决策,从而优化您的交易策略。 在本文中,我们将讨论这种技术的优点和问题。


构建自动运行的 EA(第 12 部分):自动化(IV)
如果您认为自动化系统很简单,那么您可能并未完全理解创建它们需要什么。 在本文中,我们将谈谈杀死大量智能系统的问题。 不分青红皂白地触发订单是解决这个问题的可能方法。

构建自动运行的 EA(第 11 部分):自动化(III)
如果没有健全的安全性,自动化系统就不会成功。 但是,如果不对某些事情有很好的理解,就无法确保安全性。 在本文中,我们将探讨为什么在自动化系统中实现最大安全性是一项挑战。

神经网络实验(第 3 部分):实际应用
在本系列文章中,我会采用实验和非标准方法来开发一个可盈利的交易系统,并检查神经网络是否对交易者有任何帮助。 若在交易中运用神经网络,MetaTrader 5 则可作为近乎自给自足的工具。

构建自动运行的 EA(第 09 部分):自动化(II)
如果您无法控制其调度表,则自动化就意味着毫无意义。 没有工人能够一天 24 小时高效工作。 然而,许多人认为自动化系统理所当然地每天 24 小时运行。 但为 EA 设置工作时间范围总是有好处的。 在本文中,我们将研究如何正确设置这样的时间范围。

构建自动运行的 EA(第 09 部分):自动化(I)
尽管创建自动 EA 并非一项非常困难的任务,但在缺乏必要知识的情况下可能会犯许多错误。 在本文中,我们将研究如何构建初级自动化,其中包括创建一个触发器来激活盈亏平衡和尾随停止价位。

神经网络变得轻松(第三十五部分):内在好奇心模块
我们继续研究强化学习算法。 到目前为止,我们所研究的所有算法都需要创建一个奖励政策,从而令代理者能够每次从一个系统状态过渡到另一个系统状态的转换中估算其每个动作。 然而,这种方式人为因素相当大。 在实践中,动作和奖励之间存在一些时间滞后。 在本文中,我们将领略一种模型训练算法,该算法可以操控从动作到奖励的各种时间延迟。

构建自动运行的 EA(第 08 部分):OnTradeTransaction
在本文中,我们将目睹如何利用事件处理系统快速有效地处理与订单系统相关的问题。 配合这个系统,EA 就能更快地工作,如此它就不必持续不断地搜索所需的数据。
神经网络变得轻松(第三十四部分):全部参数化的分位数函数
我们继续研究分布式 Q-学习算法。 在之前的文章中,我们研究了分布式和分位数 Q-学习算法。 在第一种算法当中,我们训练了给定数值范围的概率。 在第二种算法中,我们用给定的概率训练了范围。 在这两个发行版中,我们采用了一个先验分布知识,并训练了另一个。 在本文中,我们将研究一种算法,其允许模型针对两种分布进行训练。

构建自动运行的 EA(第 07 部分):账户类型(II)
今天,我们将看到如何创建一个在自动模式下简单安全地工作的智能系统。 交易者应当始终明白自动 EA 正在做什么,以便若它“偏离轨道”,交易者可以尽早将其从图表中删除,并控制事态。


构建自动运行的 EA(第 06 部分):账户类型(I)
今天,我们将看到如何创建一个在自动模式下简单安全地工作的智能系统。 当前状态下,我们的 EA 已能在任何状况下工作,但尚未准备好自动化。 我们仍然需要在几点上努力。

构建自动运行的 EA(第 05 部分):手工触发器(II)
今天,我们将看到如何创建一个在自动模式下简单安全地工作的智能系统。 在上一篇文章的末尾,我建议允许手工操作 EA 是合适的,至少在一段时间内。


构建自动运行的 EA(第 03 部分):新函数
今天,我们将看到如何创建一个在自动模式下简单安全地工作的智能系统。 在上一篇文章中,我们已启动开发一个在自动化 EA 中使用的订单系统。 然而,我们只创建了一个必要的函数。

构建自动运行的 EA(第 02 部分):开始编码
今天,我们将看到如何创建一个在自动模式下简单安全地工作的智能系统。 在上一篇文章中,我们讨论了任何人在继续创建自动交易的智能系统之前需要了解的第一步。 我们首先研究了概念和结构。


神经网络变得轻松(第三十二部分):分布式 Q-学习
我们在本系列的早期文章中领略了 Q-学习方法。 此方法均化每次操作的奖励。 2017 年出现了两篇论文,在研究奖励分配函数时展现出了极大的成功。 我们来研究运用这种技术解决我们问题的可能性。

帧分析器(Frames Analyzer)工具带来的时间片交易魔法
什么是帧分析器(Frames Analyzer)? 这是适用于任意智能系统的一个插件模块,在策略测试器中、以及测试器之外进行参数优化期间,该工具在参数优化完成后立即读取测试创建的 MQD 文件、或数据库,并分析优化帧数据。 您能够与拥有帧分析器工具的其他用户共享这些优化结果,从而共同讨论结果。



神经网络变得轻松(第二十九部分):优势扮演者-评价者算法
在本系列的前几篇文章中,我们见识到两种增强的学习算法。 它们中的每一个都有自己的优点和缺点。 正如在这种情况下经常发生的那样,接下来的思路是将这两种方法合并到一个算法,使用两者间的最佳者。 这将弥补它们每种的短处。 本文将讨论其中一种方法。

神经网络变得轻松(第二十八部分):政策梯度算法
我们继续研究强化学习方法。 在上一篇文章中,我们领略了深度 Q-学习方法。 按这种方法,已训练模型依据在特定情况下采取的行动来预测即将到来的奖励。 然后,根据政策和预期奖励执行动作。 但并不总是能够近似 Q-函数。 有时它的近似不会产生预期的结果。 在这种情况下,近似方法不应用于功用函数,而是应用于动作的直接政策(策略)。 其中一种方法是政策梯度。