
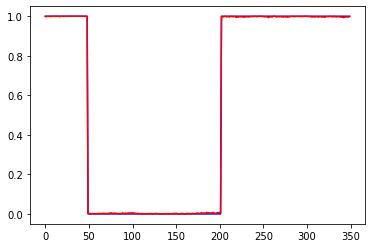
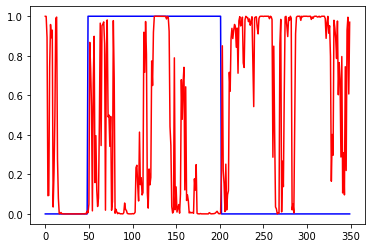
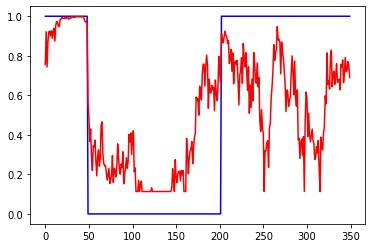
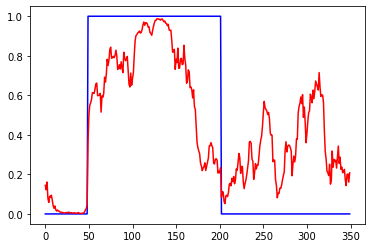
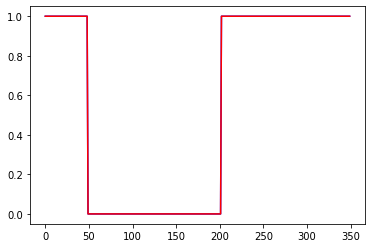
Первый график вход, третий выход. 2 и 4 валидация. 1 график приращения, 3 график сигнал на покупку некоторой "классической" системы. 2 инвертированый 1, а 4 сигнал на покупку для 2
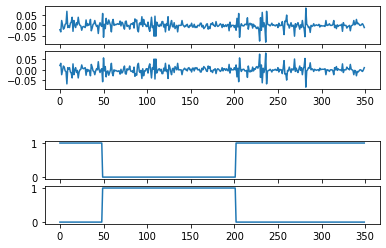
Базовая модель: 100 входов, 20 скрытых нейронов в 1 Dense слое с активацией tanh, 1 выход с активацией sigmoid, 2000 эпох, батч 32. Для сети перевернутый по вертикали вход это совсем другой ряд, но т.к. трейн и валидация проходят на одном участке истории, то возможна подгонка/подглядывание.
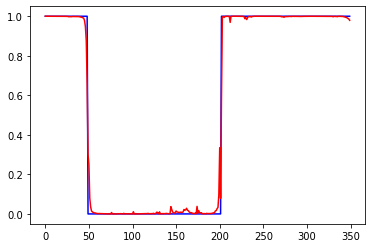
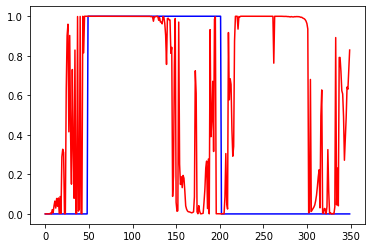
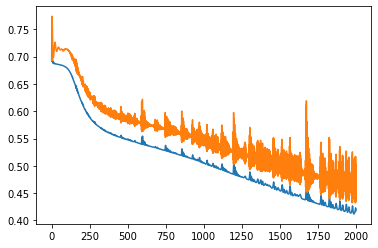
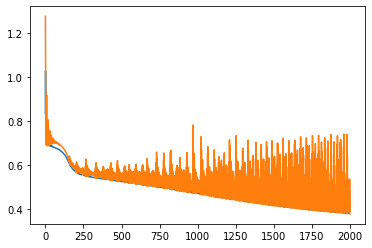
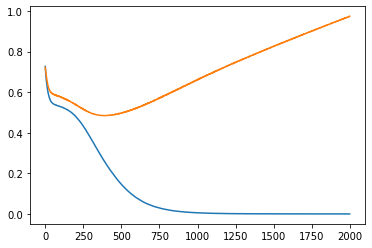
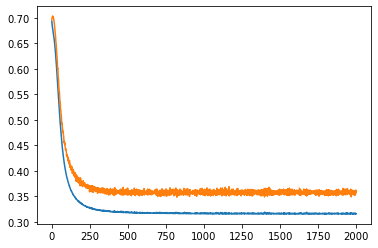
Слева ошибки на трейне и валидации от эпох. В центре выход сети на трейне и эталон. Справа выход сети на валидации и эталон.
Обычная сеть похоже лучше, чем lstm. И tanh лучше чем relu. lstm какие то тугие и капризные. Долго учатся, плохо видят закономерность.
lstm, данные нормированы к диапазону +-1:
tanh, данные нормированы к диапазону +-1:



sigmoid, данные нормированы к диапазону +-1, сильный разброс результатов, от аналогичного tanh до очень плохого:
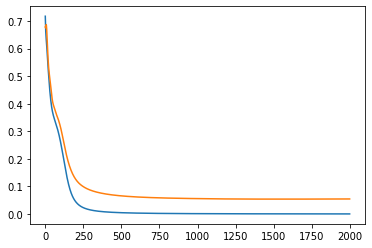
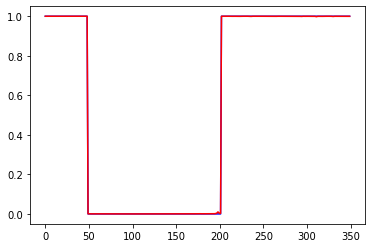
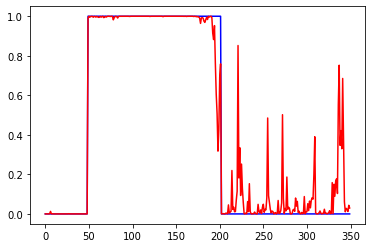
sigmoid, данные нормированы к диапазону 0-1:
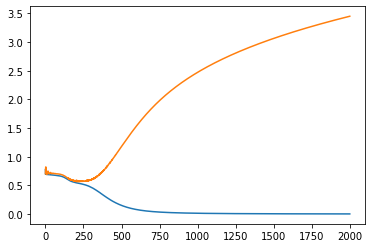
relu, данные нормированы к диапазону +-1:



relu, данные нормированы к диапазону 0-1:
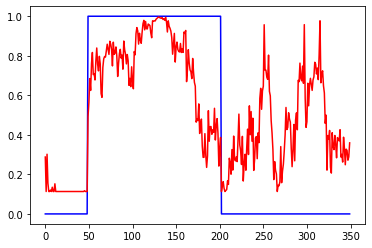
linear (линейная/без ф-ии активации), данные нормированы к диапазону +-1, масштабирование входа, увеличение нейронов не помогает:

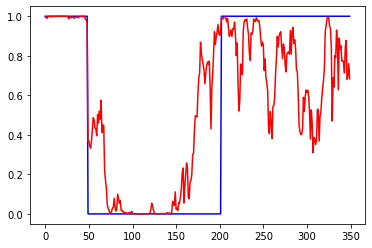
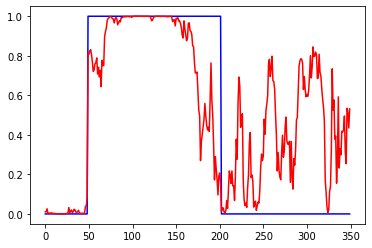
linear (линейная/без ф-ии активации), данные нормированы к диапазону 0-1:

Уменьшил число входов до 50
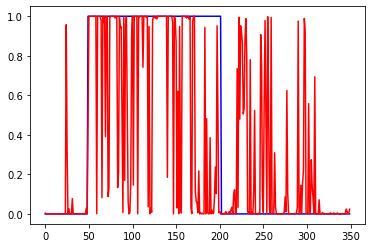
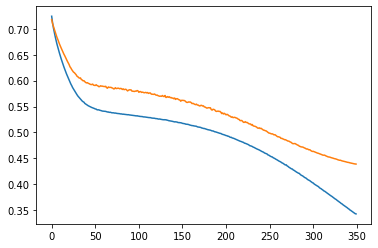
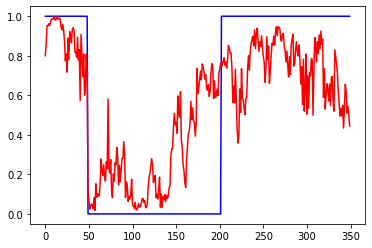
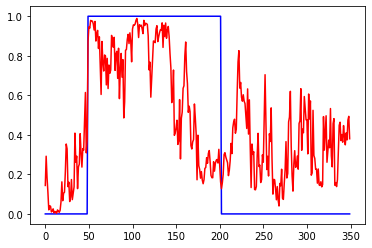
Много эксперементировал с параметрами сети, но в среднем результат был такой. То есть закономерность определяется на промежутке 50-100 последних баров.
Уменьшил число нейронов до 1
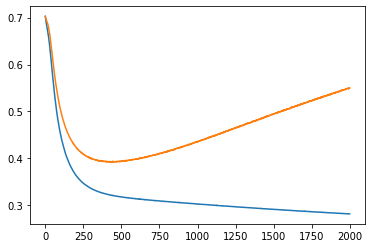
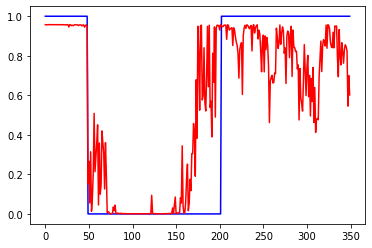
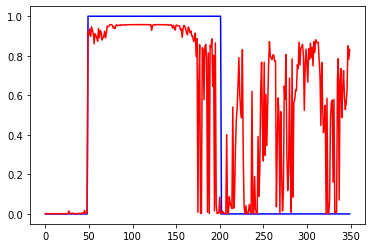
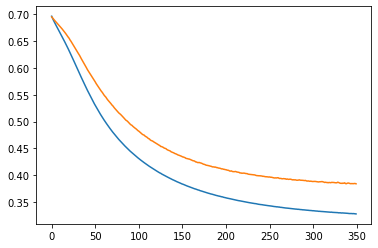
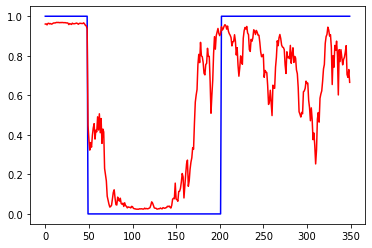
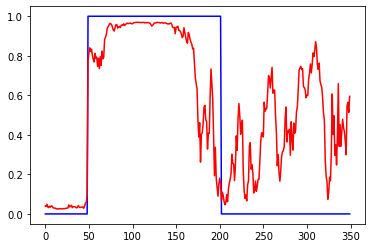
Убрал нормировку к +-1, т.е. данные в диапазоне +-0.05
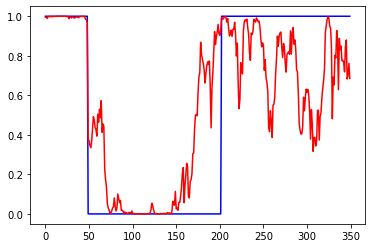
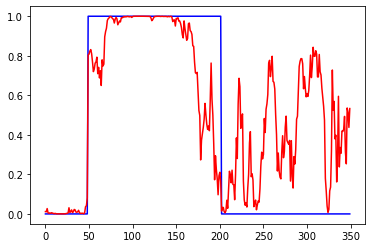
Другой тестовый пример, пересечение ма и цены. На вход подаются приращения нескольких последних баров, на выход направление сделки (1-бай, 0-селл). Параметры базовой сети: 1 Dense слой с tanh. 1 эпоха, батч=32. win - число входов, per - период МА, total - размер обучающей выборки. Сеть обучается за 1 эпоху, что бы при обучении не было повторных примеров. Валидация проходит на инвертированной по вертикали (*-1) обучающей выборке. Тест проходит на отдельной независимой выборке. Все они равны total. При per<=win сеть показывает высокую точность, что и требовалось доказать, сеть способна искать скрытые закономерности.
Для небольших сетей (<1000 нейронов) расчет на cpu быстрее, чем на gpu. При батче=8192 расчеты проходят за одинаковое время. Этот тестовый пример с 1 и 100 скрытыми нейронами считается за одинаковое время. Для cpu двойная и одинарная точность считается за одинаковое время, результаты сопоставимые. Разные типы активации считаются за примерно одинаковое время и дали сопоставимые результаты. Размер win не сильно влияет на время. total=10^6 при батче=1 считается за 18 минут. Зависимость между батчем и временем линейная.
Точность от размера выборки. батч=1 , per=100, win=100. Первый столбец - размер выборки (total), 2 - время мин.сек, 3 - точность на тесте, 4 - точность на трейне, 5 - точность на валидации.
1м 18.49 99. 98.7 99.
100к 1.54 98.5 97.3 98.6
10к 0.11 97.8 88.4 98.1
1к 0.01 71.2 62.1 66.5
Добавление шума к входу. total=10^6, батч=32 , per=10, win=10. Первый столбец - доля шума от входа, 2 - точность на тесте, 3 - точность на трейне, 4 - точность на валидации.
0.001 99.8 98.1 99.8
0.01 99.6 98.2 99.6
0.1 96.8 96.1 96.8
1 74.9 74.2 75.1
Число входов и ошибка. total=10^6, батч=32 , per=100. точность на тесте, точность на трейне, точность на валидации.
win=150: 99.5 98.7 99.5
win=100: 99.6 98.8 99.6
win=90: 98.9 98.2 98.9
win=80: 97.2 96.6 97.2
win=70: 94.8 94.3 94.8
win=60: 92.0 91.6 91.9
win=50: 88.6 88.2 88.6
win=20: 74.7 74.4 74.7
Графики весов. 1 входной нейрон. ма(100) 100 входов слева, ма(50) 100 входов справа
Вырезки:
Активации:
В качестве ф-ии активации можно использовать что угодно, хоть косинус, результат получается на уровне популярных. Рекомендуется использовать relu (со сдвигом bias 0.1 (не рекомендуется использовать вместе с инициализацией случайным блужданием)), т.к. он простой (быстро считается) и лучше идет обучение: Эти блоки легко оптимизировать, потому что они очень похожи на линейные. Разница только в том, что блок линейной ректификации в половине своей области определения выводит 0. Поэтому производная блока линейной ректификации остается большой всюду, где блок активен. Градиенты не только велики, но еще и согласованы. Вторая производная операции ректификации всюду равна нулю, а первая производная равна 1 всюду, где блок активен. Это означает, что направление градиента гораздо полезнее для обучения, чем в случае, когда функция активации подвержена эффектам второго порядка... При инициализации параметров аффинного преобразования рекомендуется присваивать всем элементам b небольшое положительное значение, например 0.1. Тогда блок линейной ректификации в начальный момент с большой вероятностью окажется активен для большинства обучающих примеров, и производная будет отлична от нуля.
В отличие от кусочно-линейных, сигмоидальные блоки близки к асимптоте в большей части своей области определения – приближаются к высокому значению, когда z стремится к бесконечности, и к низкому, когда z стремится к минус бесконечности. Высокой чувствительностью они обладают только в окрестности нуля. Из-за насыщения сигмоидальных блоков градиентное обучение сильно затруднено. Поэтому использование их в качестве скрытых блоков в сетях прямого распространения ныне не рекомендуется... Если использовать сигмоидальную функцию активации необходимо, то лучше взять не логистическую сигмоиду, а гиперболический тангенс. Он ближе к тождественной функции в том смысле, что tanh(0) = 0, тогда как σ(0) = 1/2. Поскольку tanh походит на тождественную функцию в окрестности нуля, обучение глубокой нейронной сети напоминает обучение линейной модели при условии что сигналы активации сети удается удерживать на низком уровне. При этом обучение сети с функцией активации tanh упрощается.
Для lstm нужно использовать сигмоид или арктангенс (рекомендуется устанавливать смещение 1 для вентиля забывания): Сигмоидальные функции активации все же применяются, но не в сетях прямого распространения. К рекуррентным сетям, многим вероятностным моделям и некоторым автокодировщикам предъявляются дополнительные требования, исключающие использование кусочно-линейных функций активации и делающие сигмоидальные блоки более подходящими, несмотря на проблемы насыщения.
Линейная активация и уменьшение параметров: Если каждый слой сети состоит только из линейных преобразований, то сеть в целом будет линейной. Однако некоторые слои могут быть и чисто линейными – это вполне нормально. Рассмотрим слой нейронной сети, имеющий n входов и p выходов. Его можно заменить двумя слоями, в одном из которых используется матрица весов U, а в другом – матрица весов V. Если в первом слое нет функции активации, то мы, по сути дела, разложили на множители матрицу весов исходного слоя, основанного на W. Если U порождает q выходов, то U и V вместе содержат только (n + p)q параметров, тогда как W – np параметров. Для малых q экономия параметров может быть существенной. Платой за это является ограничение – линейное преобразование должно иметь низкий ранг, но таких низкоранговых связей часто достаточно. Таким образом, линейные скрытые блоки предлагают эффективный способ уменьшить число параметров сети.
Релу больше подходит для глубоких сетей: Несмотря на популярность ректификации в ранних моделях, в 1980-е годы ее почти всюду заменили сигмоиды, поскольку они лучше работают в очень малых нейронных сетях.
Но в целом оно лучше: для небольших наборов данных использование ректифицирующих нелинейностей даже важнее, чем обучение весов скрытых слоев. Случайных весов достаточно для распространения полезной информации по сети с линейной ректификацией, что позволяет классифицирующему выходному слою обучаться отображению различных векторов признаков на идентификаторы классов. Если доступно больше данных, то процесс обучения начинает извлекать так много полезных знаний, что превосходит по качеству случайным образом выбранные параметры... обучение гораздо легче проходит в ректифицированных линейных сетях, чем в глубоких сетях, для которых функции активации характеризуются кривизной или двусторонним насыщением...
Регуляризация:
Управление сложностью модели – не просто поиск модели правильного размера с правильным числом параметров. Вместо этого мы могли обнаружить – и в реальных приложениях глубокого обучения так почти всегда и бывает – что наилучшая эмпирическая модель (в смысле минимизации ошибки обобщения) – это большая модель, подходящим образом регуляризированная. В некоторых случаях без регуляризации просто невозможно корректно поставить задачу машинного обучения. В большинстве вариантов регуляризации гарантируется сходимость итерационных методов, применяемых к недоопределенным задачам. В нейронных сетях мы обычно предпочитаем штрафовать по норме только веса аффинного преобразования в каждом слое, оставляя смещения нерегуляризированными.
Один из самых простых и распространенных видов штрафа параметров – по норме L2, – который часто называют снижением весов. Цель такой стратегии регуляризации – выбирать веса, близкие к началу координат.L2-регуляризация заставляет алгоритм обучения «воспринимать» вход X как имеющий более высокую дисперсию и, следовательно, уменьшать веса тех признаков, для которых ковариация с выходными метками мала, по сравнению с добавленной дисперсией.
По сравнению с L2-регуляризацией, L1-регуляризация дает более разреженное решение. В этом контексте под разреженностью понимается тот факт, что у некоторых параметров оптимальное значение равно 0. Свойство разреженности, присущее L1-регуляризации, активно эксплуатировалось как механизм отбора признаков. Благодаря L1-штрафу некоторые веса обращаются в 0, и соответствующие им признаки отбрасываются.
Из-за штрафа процедура невыпуклой оптимизации может застрять в локальном минимуме. Явные ограничения, реализованные с помощью обратного проецирования, в таких случаях могут работать гораздо лучше, потому что не поощряют приближения весов к началу координат. Такие явные ограничения вступают в силу, только когда веса становятся большими и грозят выйти за пределы области ограничений. Наконец, явные ограничения на основе обратного проецирования могут быть полезны, потому что привносят устойчивость в процедуру оптимизации. Если скорость обучения высока, то есть риск попасть в петлю с положительной обратной связью, когда большие веса приводят к большим градиентам, а это, в свою очередь, приводит к большому обновлению весов. Если такие обновления стабильно увеличивают веса, то θ быстро отдаляется от начала координат, пока не наступит численное переполнение. Явные ограничения с обратным проецированием не дают таким петлям вызывать неограниченный рост весов. Рекомендуется использовать ограничения в сочетании с высокой скоростью обучения, чтобы быстрее исследовать пространство параметров без потери устойчивости.
Нейронные сети не очень устойчивы к шуму. Один из путей повышения робастности нейронных сетей – обучать их на данных, к которым добавлен случайный шум. Еще один способ использования шума ради регуляризации моделей – прибавление его к весам.
dropout. В процессе прореживания обучается ансамбль, состоящий из подсетей, получаемых удалением невыходных блоков из базовой сети. Обычно входной блок включается с вероятностью 0.8, а скрытый – с вероятностью 0.5. Прореживание эффективнее других стандартных вычислительно недорогих регуляризаторов: снижения весов, фильтрации с ограничением по норме и разреженной активации. Дальнейшего улучшения можно добиться, комбинируя прореживание с другими видами регуляризации. Как правило, оптимальная ошибка на контрольном наборе при использовании прореживания намного ниже, но расплачиваться за это приходится гораздо большим размером модели и числом итераций алгоритма обучения. Для очень больших наборов данных регуляризация не сильно снижает ошибку обобщения. Если в нашем распоряжении очень мало помеченных обучающих примеров, то прореживание менее эффективно. Своей мощью прореживание в немалой степени обязано тому факту, что к скрытым блокам применяется маскирующий шум.
Основная цель пакетной нормировки – улучшить оптимизацию, но шум может давать регуляризирующий эффект, так что иногда прореживание оказывается излишним.
Оптимизаия:
В большинстве ситуаций нас интересует некоторая мера качества P, которая определена относительно тестового набора и может оказаться вычислительно неприступной. Поэтому мы оптимизируем P косвенно. Мы уменьшаем другую функцию стоимости J(θ) в надежде, что при этом улучшится и P. Это резко отличается от чистой оптимизации, где минимизация J и есть конечная цель. Иногда реально интересующая нас функция потерь и та, что может быть эффективно оптимизирована, – «две большие разницы». Обучение зачастую заканчивается, когда производные суррогатной функции потерь все еще велики, и этим разительно отличается от чистой оптимизации, при которой считается, что алгоритм сошелся, если градиент стал очень малым.
Сравним две гипотетические оценки градиента, одна на основе 100 примеров, другая – 10 000. Для вычисления второй оценки потребуется в 100 раз больше времени, но стандартная ошибка среднего уменьшится только в 10 раз. Большинство алгоритмов оптимизации сходится гораздо быстрее (в терминах общего времени вычислений, а не числа обновлений), если им позволено быстро вычислять приближенные оценки градиента вместо медленного вычисления точного значения.
Алгоритмы оптимизации, в которых используется весь обучающий пакет, называются пакетными, или детерминированными, градиентными методами, поскольку обрабатывают сразу все примеры одним большим пакетом. Большинство алгоритмов, используемых в глубоком обучении, находится где-то посередине – число примеров в них больше одного, но меньше размера обучающего набора. Традиционно они назывались мини-пакетными, или мини-пакетными стохастическими, методами, а сейчас – просто стохастическими.
Чем больше пакет, тем точнее оценка градиента, но зависимость хуже линейной. Если пакет очень мал, то не удается в полной мере задействовать преимущества многоядерной архитектуры. Если все примеры из пакета нужно обрабатывать параллельно (так обычно и бывает), то размер пакета лимитирован объемом памяти. Для некоторых видов оборудования оптимальное время выполнения достигается при определенных размерах массива. Так, для GPU наилучшие результаты получаются, когда размер пакета – степень 2. Типичный пакет имеет размер от 32 до 256, а для особо больших моделей иногда пробуют 16. Небольшие пакеты могут дать эффект регуляризации, быть может, из-за шума, который они вносят в процесс обучения.
Ошибка обобщения часто оказывается наилучшей для пакета размера 1. Но для обучения с таким маленьким размером пакета нужна небольшая скорость обучения для обеспечения устойчивости из-за высокой дисперсии оценки градиента. Общее время работы может оказаться очень большим из-за увеличения числа шагов – как из-за пониженной скорости обучения, так и потому, что для перебора всего обучающего набора требуется больше шагов.
В зависимости от вида алгоритма используется разная информация из мини-пакета, причем разными способами. Одни алгоритмы более чувствительны к ошибке выборки, чем другие, либо потому что в них используется информация, которую трудно оценить точно на небольшой выборке, либо потому что информация используется так, что ошибка выборки усиливается. Методы, которые вычисляют обновления только на основе градиента, обычно сравнительно устойчивы и могут работать с пакетами небольшого размера, порядка 100. Методы второго порядка, в которых используется также матрица Гессе, обычно нуждаются в пакетах гораздо большего размера, порядка 10 000. Такие большие пакеты нужны, чтобы свести к минимуму флуктуации в оценках.
Необходимо, чтобы примеры были независимы. Два последовательных мини-пакета примеров тоже должны быть независимы. Многие наборы данных естественно упорядочены так, что между последовательными примерами имеется высокая корреляция. Тем не менее обычно для получения наилучших результатов стоит сделать несколько проходов по обучающему набору, если только он не слишком велик. Если используется несколько таких периодов, то лишь в первом спуск происходит в направлении несмещенного градиента ошибки обобщения, но, конечно, дополнительные периоды обычно дают достаточный выигрыш в плане уменьшения ошибки обучения, чтобы перевесить вред от увеличения разрыва между ошибкой обучения и ошибкой тестирования. В тех случаях, когда размер набора данных растет быстрее, чем вычислительные ресурсы для его обработки, все чаще в машинном обучении переходят к практике, когда каждый обучающий пример используется ровно один раз, или даже производится неполный проход по обучающему набору. Если обучающий набор очень велик, то переобучение перестает быть проблемой, и на первый план выходят проблемы недообучения и вычислительной эффективности.
Многие специалисты-практики приписывают почти все трудности, связанные с оптимизацией нейронных сетей, локальным минимумам. Чтобы исключить локальные минимумы как возможную причину проблем, имеет смысл построить график зависимости нормы градиента от времени. Если норма градиента не убывает почти до нуля, то проблема не в локальных минимумах и вообще не в критических точках. В пространствах высокой размерности установить с полной определенностью, что корень зла – локальные минимумы, бывает очень трудно. Малые градиенты характерны для многих особенностей строения, помимо локальных минимумов.
Теоретически доказано, что мелкие автокодировщики без нелинейностей имеют глобальные минимумы и седловые точки, но не имеют локальных минимумов со стоимостью выше, чем в глобальном минимуме. Есть эмпирические свидетельства в пользу того, что метод градиентного спуска во многих случаях способен выйти из седловой точки. Могут также существовать широкие плоские области с постоянным значением. В этих областях равны нулю и градиент, и гессиан. Такие вырожденные участки – серьезная проблема для всех алгоритмов численной оптимизации. Целевая функция сильно нелинейной глубокой нейронной сети или рекуррентной сети часто характеризуется резкими нелинейностями в пространстве параметров. В местах таких нелинейностей значения производных очень велики. Когда параметры приближаются к подобному утесу, шаг обновления в методе градиентного спуска может сдвинуть параметры очень далеко, при этом может потеряться все, чего удалось достичь в ходе предшествующей оптимизации. Самых печальных последствий можно избежать с помощью эвристической техники отсечения градиента. Основная идея – вспомнить, что градиент определяет не оптимальный размер шага, а лишь оптимальное направление в бесконечно малой области. В рекуррентных сетях на каждом временном шаге используется одна и та же матрица, но в сетях прямого распространения это не так, поэтому даже в очень глубоких сетях прямого распространения, как правило, удается избежать проблемы исчезающего и взрывного градиента.
Большинство алгоритмов оптимизации исходит из предположения, что имеется доступ к точному градиенту или гессиану. На практике же обычно налицо только зашумленная или даже смещенная оценка этих величин. Длительность обучения определяется в первую очередь длиной траектории, ведущей к решению. Траектория обучения резко удлиняется из-за необходимости обогнуть по широкой дуге скалообразную структуру. В центре многих исследований, посвященных трудностям оптимизации, находится вопрос о том, достигает ли обучение глобального минимума, локального минимума или седловой точки, но на практике нейронные сети не находят никакую критическую точку. Многие из современных направлений исследований нацелены на поиск хороших начальных значений параметров в задачах с трудной глобальной структурой, а не на разработку алгоритмов с нелокальным перемещением.
Инициализация параметров:
Обучение глубоких моделей – задача настолько сложная, что большинство алгоритмов сильно зависит от выбора начальных значений. Современные стратегии инициализации просты и основаны на эвристических соображениях. Большинство стратегий основано на стремлении получить некоторые полезные свойства сети в начальный момент. Однако мы плохо понимаем, какие из этих свойств и при каких условиях сохраняются после начала процесса обучения. Дополнительная трудность состоит в том, что некоторые начальные точки хороши с точки зрения оптимизации, но никуда не годятся с точки зрения обобщаемости. Пожалуй, единственное, что мы знаем наверняка, – это то, что начальные параметры должны «нарушить симметрию» между разными блоками.
В типичном случае мы выбираем в качестве смещений блоков эвристически выбранные константы. Условная дисперсия предсказания, обычно тоже задается эвристическими константами. Подходы к заданию смещений и весов должны быть согласованы. Инициализация всех смещений нулями совместима с большинством схем инициализации весов. Есть несколько ситуаций, в которых разумно присваивать некоторым смещениям ненулевые значения. Обычно безопасно инициализировать дисперсию, или точность, значением 1.
Почти всегда веса модели инициализируются случайными значениями с нормальным или равномерным распределением. Масштаб начального распределения сильно влияет как на результат процедуры оптимизации, так и на способность сети к обобщению. Чем больше начальные веса, тем сильнее эффект нарушения симметрии, что помогает избежать избыточных блоков. Большие начальные веса помогают также предотвратить потерю сигнала во время прямого или обратного распространения через линейные компоненты каждого слоя – чем больше значения в матрице, тем больше результат умножения матриц. Однако если начальные веса слишком велики, то может случиться взрывной рост значений во время прямого или обратного распространения. Балансирование этих разнонаправленных факторов и определяет идеальный масштаб весов.
Взгляды на проблему с точки зрения регуляризации и оптимизации могут дать совершенно разные подходы к инициализации сети. С точки зрения оптимизации, веса должны быть достаточно большими, чтобы способствовать успешному распространению информации. Но соображения регуляризации побуждают делать веса поменьше. Использование таких алгоритмов оптимизации, как стохастический градиентный спуск, который производит инкрементные изменения весов и выказывает тенденцию к остановке в областях, близких к начальным параметрам, выражает априорное знание о том, что конечные параметры должны быть близки к начальным.
Существуют некоторые эвристики для выбора начального масштаба весов. Правильного выбора коэффициента усиления достаточно для обучения глубоких сетей с 1000 уровней. К сожалению, оптимальные критерии для начальных весов зачастую не приводят к оптимальному качеству. Тому может быть три причины. Во-первых, неподходящий критерий – возможно, он не способствует сохранению нормы сигнала во всей сети. Во-вторых, свойства, справедливые в момент инициализации, могут нарушаться после начала обучения. В-третьих, критерий может ускорять оптимизацию, но непреднамеренно увеличивать ошибку обобщения.
Хорошее эвристическое правило выбора начальных масштабов – проанализировать диапазон стандартного отклонения активаций или градиентов на одном мини-пакете данных. Если веса слишком малы, то диапазон активаций будет сужаться по мере прямого распространения по сети. Раз за разом определяя первый слой с неприемлемой малой активацией и увеличивая веса в нем, можно в конце концов получить сеть с разумными начальными активациями снизу доверху.
Стратегии оптимизации:
Пакетная нормировка. Это метод адаптивной перепараметризации, появившийся из-за трудностей обучения очень глубоких моделей. Градиент говорит, как обновлять каждый параметр в предположении, что другие слои не изменяются. На практике мы обновляем все слои одновременно. Очень трудно выбрать правильную скорость обучения, т. к. эффект обновления параметров одного слоя сильно зависит от всех остальных слоев. Перепараметризация значительно снижает остроту проблемы координации обновлений между многими слоями. Пакетную нормировку можно применить к входному и любому скрытому слою сети.
Действие пакетной нормировки направлено на стандартизацию только среднего и дисперсии каждого блока с целью стабилизировать обучение, но она не препятствует изменению связей между блоками и нелинейных статистик одного блока. Поскольку последний слой сети способен обучиться линейному преобразованию, мы на самом деле можем попробовать удалить все линейные связи между блоками в пределах одного слоя. К сожалению, исключение всех линейных взаимодействий обходится гораздо дороже стандартизации среднего и стандартного отклонений каждого отдельного блока, так что пакетная нормировка до сих пор остается наиболее практичным решением.
Нормировка среднего и стандартного отклонений блока может снизить выразительную мощность нейронной сети, содержащей этот блок. Для сохранения выразительной мощности обычно заменяют пакет активаций скрытых блоков H на γH′+ β, а не просто на нормированную матрицу H′. Переменные γ и β – обученные параметры, благодаря которым новая величина может иметь произвольные среднее и стандартное отклонения. На первый взгляд, это кажется бессмысленным – зачем было устанавливать среднее в 0, а потом вводить параметр, который позволяет снова переустановить его в произвольное значение β? Да затем, что новая параметризация может представить то же самое семейство функций от входных данных, что и старая, но при этом обладает другой динамикой обучения. В старой параметризации среднее H определялось сложным взаимодействием между параметрами на уровнях ниже H. В новой же параметризации среднее γH′ + β определяется только величиной β. При новой параметризации модель гораздо легче обучить методом градиентного спуска.
Большинство слоев нейронных сетей имеет вид φ(XW + b), где φ – фиксированная нелинейная функция активации. Естественно спросить, следует ли применять пакетную нормировку ко входу X или к уже преобразованному значению XW + b. Рекомендуется последнее. Точнее говоря, XW + b следует заменить результатом нормировки XW. Член смещения нужно опустить, потому что он становится избыточным ввиду параметра β, применяемого в ходе перепараметризации.
Архитектура. На практике важнее выбирать семейство моделей, легко поддающееся оптимизации, чем мощный алгоритм оптимизации. Прогресс в области нейронных сетей за последние тридцать лет в основном был связан именно с изменением семейства моделей. Стохастический градиентный спуск с учетом импульса, использовавшийся для обучения сетей еще в 1980-х годах, и по сей день применяется в самых передовых приложениях. Говоря конкретно, в современных нейронных сетях предпочтение отдается линейным преобразованиям между слоями и функциями активации, дифференцируемым почти всюду и имеющим значительный наклон на больших участках своей области определения. Такие новации в области проектирования моделей, как LSTM, блоки линейной ректификации и maxout-блоки, все направлены на использование более линейных функций, чем в предыдущих моделях типа глубоких сетей с сигмоидными блоками. У таких моделей есть полезные свойства, упрощающие оптимизацию. Градиент распространяется сквозь много слоев, при условии что у якобиана линейного преобразования имеются разумные сингулярные значения. К тому же линейные функции монотонно возрастают в одном направлении, так что даже если выход модели очень далек от правильного, из вычисления градиента сразу становится ясно, в каком направлении должен сместиться выход, чтобы уменьшить функцию потерь. Иными словами, современные нейронные сети проектируются так, чтобы локальная информация о градиенте достаточно хорошо соответствовала движению в сторону далеко находящегося решения.
Есть и другие стратегии проектирования моделей, способствующие упрощению оптимизации. Например, линейные пути или прямые связи между слоями уменьшают длину кратчайшего пути от параметров нижних слоев к выходу, а потому смягчают проблему исчезающего градиента. К идее прямых связей близка идея о добавлении дополнительных копий выходов, которые были бы соединены с промежуточными слоями сети, как в GoogLeNet и сетях с глубоким проникновением учителя. Эти «вспомогательные головы» обучаются решать ту же задачу, что основной верхний слой сети, чтобы нижние слои получали больший градиент. По завершении обучения вспомогательные головы можно отбросить. Это альтернатива стратегиям предобучения. При таком подходе можно совместно обучать все слои на одной стадии, но изменить архитектуру, так чтобы промежуточные слои (особенно ниже расположенные) могли получать рекомендации о том, что делать, по более короткому пути. Эти рекомендации несут нижним слоям сигнал об ошибке.
Методы продолжения – это семейство стратегий, которые упрощают оптимизацию посредством выбора таких начальных точек, чтобы локальная оптимизация проходила в основном в областях пространства с хорошим поведением. Идея заключается в том, чтобы построить последовательность целевых функций от одних и тех же параметров. Последовательность функций стоимости проектируется так, чтобы решение одной функции было хорошим начальным приближением для другой. Таким образом, мы сначала находим решение легкой задачи, а затем постепенно уточняем его для решения все более трудных задач, пока не найдем решения исходной задачи. Традиционные методы продолжения (которые появились задолго до применения этой идеи к обучению нейронных сетей) обычно основываются на сглаживании целевой функции. Упрощение целевой функции может устранить плоские участки, уменьшить дисперсию оценки градиента, улучшить обусловленность матрицы Гессе или сделать еще что-то, что либо облегчит вычисление локальных обновлений, либо улучшит соответствие между локальными обновлениями направлений и движением в сторону глобального решения.
Подход, называемый обучением по плану, или шейпингом, можно интерпретировать как метод продолжения. В основе обучения по плану лежит идея планирования процесса обучения, когда начинают с простых понятий и постепенно вводят более сложные. Еще один важный вклад в исследования в области обучения по плану связан с обучением рекуррентных нейронных сетей улавливанию долговременных зависимостей. Обнаружено, что гораздо лучшие результаты получаются при использовании стохастического плана, когда обучаемому всегда предъявляется случайная смесь простых и трудных примеров, но средняя доля трудных примеров (тех, в которых имеются долговременные зависимости) постепенно увеличивается. Когда использовался детерминированный план, никакого улучшения по сравнению с эталоном (обычное обучение на полном обучающем наборе) не наблюдалось.
Практика:
Для большинства приложений невозможно достичь полной безошибочности. Причина может заключаться в том, что входные признаки содержат неполную информацию о выходной величине, или в том, что система принципиально стохастическая. Кроме того, нас ограничивает конечный объем обучающих данных.
В качестве алгоритма оптимизации стоит взять СГС с импульсом и затухающей скоростью обучения. Еще одна разумная альтернатива – Adam. Если обучающий набор не насчитывает десятков миллионов примеров, следует с самого начала включить какие-то мягкие формы регуляризации. Ранняя остановка – почти универсальная рекомендация. Прореживание – отличный способ регуляризации, легко реализуемый и совместимый со многими моделями и алгоритмами обучения. Пакетная нормировка также иногда уменьшает ошибку обобщения и позволяет отказаться от прореживания благодаря шуму в оценке статистик, вносимому для нормировки каждой переменной.
Основная цель ручного подбора гиперпараметров – привести эффективную емкость модели в соответствие со сложностью задачи. Эффективная емкость ограничена тремя факторами: репрезентативной емкостью модели, способностью алгоритма обучения минимизировать функцию стоимости и степенью регуляризации модели посредством функции стоимости и процедуры обучения.
Пожалуй, самым важным гиперпараметром является скорость обучения. Если у вас есть время для настройки только одного гиперпараметра, займитесь скоростью обучения. Она управляет эффективной емкостью модели не столь прямо, как остальные гиперпараметры: эффективная емкость максимальна, когда скорость обучения правильно подобрана для задачи оптимизации, а не когда она особенно велика или мала. Для настройки параметров, отличных от скорости обучения, необходимо следить за ошибкой обучения и тестирования, чтобы понять, является ли модель переобученной или недообученной, а затем соответственно подкорректировать емкость.
Нейронные сети обычно работают оптимально, когда ошибка обучения очень мала (а потому емкость велика), а ошибка тестирования в основном обусловлена разрывом между ошибкой обучения и тестирования. Ваша цель – уменьшить этот разрыв, не увеличивая ошибку обучения быстрее, чем сокращается разрыв. Для уменьшения разрыва измените гиперпараметры регуляризации, так чтобы уменьшить эффективную емкость модели, например добавьте прореживание или снижение весов. Обычно наилучшее качество достигается для большой хорошо регуляризированной (например, с помощью прореживания) модели.
"Киты" НС, бигдата и вычислительные мощности:
Основные идеи, лежащие в основе сетей прямого распространения, не сильно изменились с 1980-х годов. По-прежнему используются все тот же алгоритм обратного распространения и те же подходы к градиентному спуску. Повышением качества работы, имевшим место в промежутке между 1986 и 2015 годом, нейронные сети обязаны в основном двум факторам. Во-первых, благодаря более крупным наборам данных статистическое обобщение перестало быть серьезным препятствием на пути развития нейронных сетей. Во-вторых, сами нейронные сети стали гораздо больше благодаря более мощным компьютерам и улучшению программной инфраструктуры. Некоторые алгоритмические изменения также заметно повысили качество сетей. Одним из таких изменений стала замена среднеквадратической ошибки семейством функций потерь на основе перекрестной энтропии... Еще одно важное алгоритмическое изменение, резко улучшившее качество сетей прямого распространения, – замена сигмоидных скрытых блоков кусочно-линейными, например блоками линейной ректификации.
Перспективы:В 2016 году действует грубое эвристическое правило: алгоритм глубокого обучения с учителем достигает приемлемого качества при наличии примерно 5000 помеченных примеров на категорию и оказывается сопоставим или даже превосходит человека, если обучается на наборе данных, содержащем не менее 10 миллионов помеченных примеров. Если говорить об общем числе нейронов, то до недавнего времени нейронные сети были на удивление малы. После добавления скрытых блоков размер искусственных нейронных сетей удваивался в среднем каждые 2,4 года. Чем больше сеть, тем выше ее точность на более сложных задачах. Если темпы масштабирования не ускорятся в результате внедрения новых технологий, то искусственная нейронная сеть сравняется с человеческим мозгом по числу нейронов не раньше 2050-х годов. Биологические нейроны могут представлять более сложные функции, чем современные искусственные, поэтому биологические нейронные сети могут оказаться даже больше, чем показано на диаграмме. В некоторых нейронных сетях число соединений почти такое же, как у кошки, а сети с числом соединений, как у мелких млекопитающих типа мыши, встречаются сплошь и рядом. Даже в мозге человека число соединений на нейрон нельзя назвать заоблачным. Нынешние сети, которые мы считаем очень большими с вычислительной точки зрения, меньше нервной системы сравнительно примитивных позвоночных животных, например лягушек.
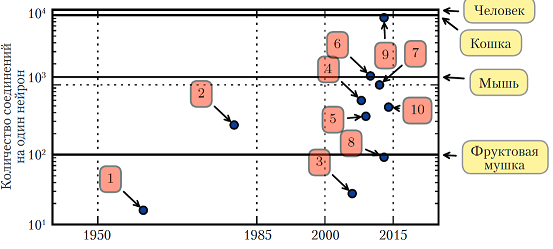
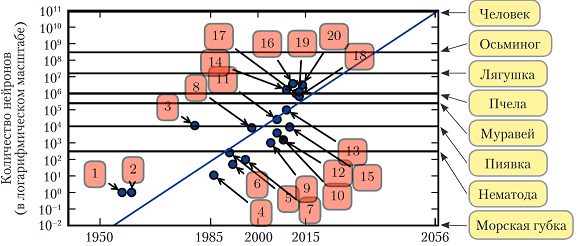
https://deeplearningbook.org/
https://habr.com/ru/post/322438/
https://towardsdatascience.com/predicting-stock-price-with-lstm-13af86a74944
https://github.com/nate-benton90/Tutorials-1/blob/master/Keras-Tutorials/5.%20Stock%20Price%20Prediction%20using%20a%20Recurrent%20Neural%20Network/Stock%20Price%20Prediction.ipynb
https://towardsdatascience.com/random-initialization-for-neural-networks-a-thing-of-the-past-bfcdd806bf9e
https://medium.com/inveterate-learner
https://towardsdatascience.com/n-beats-beating-statistical-models-with-neural-nets-28a4ba4a4de8
https://github.com/fastai/fastbook
https://habr.com/ru/company/ods/blog/336168/
https://github.com/huseinzol05/Stock-Prediction-Models





")
