
Возможности Мастера MQL5, которые вам нужно знать (Часть 10): Нетрадиционная RBM
Введение

Ограниченные машины Больцмана (Restrictive Boltzmann Machines, RBMs) — это форма нейронной сети, которая довольно проста по своей структуре, но, тем не менее, довольно популярна за свои возможности выявления скрытых свойств и функций в наборах данных. Нейронная сеть изучает веса в меньшем измерении из входных данных большего размера. Эти веса часто называют распределениями вероятностей. Как всегда, больше информации можно найти здесь, но структуру сети можно проиллюстрировать изображением ниже:
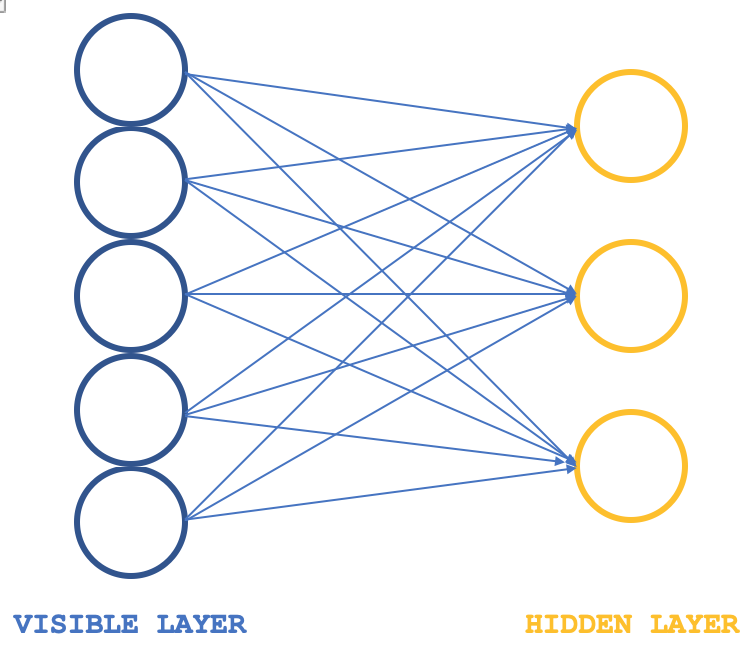
Обычно RBM состоят из двух слоев (я говорю "обычно", потому что есть некоторые сети, которые объединяют их в преобразователи) - видимого слоя и скрытого, причем видимый слой больше (имеет больше нейронов), чем скрытый. Каждый нейрон в видимом слое соединяется с каждым нейроном в скрытом слое во время так называемой положительной фазы. Во время этой фазы, как это характерно для большинства нейронных сетей, входные значения в видимом слое умножаются на значения веса при соединении нейронов, и сумма этих произведений добавляется к смещению для определения значений соответствующих скрытых нейронов. Далее следует отрицательная фаза. Через различные нейронные связи она восстанавливает входные данные в исходное состояние, начиная с вычисленных значений в скрытом слое.
Таким образом, на ранних циклах, как и следовало ожидать, восстановленные входные данные обязательно будут не соответствовать исходным входным данным, поскольку часто RBM инициализируется со случайными весами. Это означает, что веса необходимо скорректировать, чтобы приблизить восстановленные выходные данные к входным. Это дополнительная фаза, которая будет следовать за каждым циклом. Конечным результатом и целью этой положительной фазы цикла, за которой следует отрицательная фаза и корректировка весов, является получение весов соединяющих нейронов, которые при применении к входным данным могут дать нам "интуитивные" значения нейронов в скрытом слое. Эти значения нейронов в скрытом слое представляют собой то, что называется распределением вероятностей входных данных по скрытым нейронам.
Положительную и отрицательную фазы цикла RBM часто вместе называют семплированием по Гиббсу. Чтобы добиться точного соответствия распределения вероятностей данных, связующие веса корректируются с помощью так называемой контрастной дивергенции (Contrastive Divergence). Итак, если бы у нас был простой класс, иллюстрирующий это в MQL5, наш интерфейс мог бы выглядеть следующим образом:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Crbm { protected: ... public: bool init; matrix weights_v_to_h; matrix weights_h_to_v; vector bias_v_to_h; vector bias_h_to_v; matrix old_visible; matrix old_hidden; matrix new_hidden; matrix new_visible; matrix output; void GibbsSample(matrix &Input); void ContrastiveDivergence(); Crbm(int Visible, int Hidden, int Sample, double LearningRate, ENUM_LOSS_FUNCTION Loss); ~Crbm(); };
Примечательными переменными здесь являются матрицы, которые регистрируют веса при распространении от видимого слоя к скрытому, а также при распространении в обратном направлении. Они названы weights_v_to_h и weights_h_to_v соответственно. Кроме того, должны быть включены векторы, регистрирующие систематические ошибки, и, что наиболее важно, 4 набора нейронов, которые используются в семплировании по Гиббсу для хранения значений нейронов в каждой выборке - 2 для видимого слоя и 2 для скрытого. Семплирование по Гиббсу как для положительной, так и для отрицательной фазы может быть определено следующим образом:
//+------------------------------------------------------------------+ //| Feed through network using Gibbs Sampling | //+------------------------------------------------------------------+ void Crbm::GibbsSample(matrix &Input) { old_visible.Fill(0.0); old_visible.Copy(Input); //old_hidden = old_visible * weights_v_to_h; //new_hidden = Sigmoid(old_hidden) + bias_v_to_h; for (int GibbsStep = 0; GibbsStep < sample; GibbsStep++) { // Positive phase... Upward pass with biases for (int j = 0; j < hidden; j++) { old_hidden[GibbsStep][j] = 0.0; for (int i = 0; i < visible; i++) { old_hidden[GibbsStep][j] += (old_visible[GibbsStep][i] * weights_v_to_h[i][j]); } new_hidden[GibbsStep][j] = 1.0 / (1.0 + exp(-(old_hidden[GibbsStep][j] + bias_v_to_h[j]))); } } //new_visible = new_hidden * weights_h_to_v; //output = Sigmoid(new_visible) + bias_v_to_h; for (int GibbsStep = 0; GibbsStep < sample; GibbsStep++) { // Negative phase... Downward pass with biases for (int i = 0; i < visible; i++) { new_visible[GibbsStep][i] = 0.0; for (int j = 0; j < hidden; j++) { new_visible[GibbsStep][i] += (new_hidden[GibbsStep][j] * weights_h_to_v[j][i]); } output[GibbsStep][i] = 1.0 / (1.0 + exp(-(new_visible[GibbsStep][i] + bias_h_to_v[i]))); } } }
Аналогично обновление весов и смещений нейронов можно реализовать с помощью приведенной ниже функции:
//+------------------------------------------------------------------+ //| Update weights using Contrastive Divergence | //+------------------------------------------------------------------+ void Crbm::ContrastiveDivergence() { // Update weights based on the difference between positive and negative phase matrix _weights_v_to_h_update; _weights_v_to_h_update.Init(visible, hidden); _weights_v_to_h_update.Fill(0.0); matrix _weights_h_to_v_update; _weights_h_to_v_update.Init(hidden, visible); _weights_h_to_v_update.Fill(0.0); for (int i = 0; i < visible; i++) { for (int j = 0; j < hidden; j++) { _weights_v_to_h_update[i][j] = learning_rate * ( (old_visible[0][i] * weights_v_to_h[i][j]) - old_hidden[0][j] ); _weights_h_to_v_update[j][i] = learning_rate * ( (new_hidden[0][j] * weights_h_to_v[j][i]) - new_visible[0][i] ); } } // Apply weight updates for (int i = 0; i < visible; i++) { for (int j = 0; j < hidden; j++) { weights_v_to_h[i][j] += _weights_v_to_h_update[i][j]; weights_h_to_v[j][i] += _weights_h_to_v_update[j][i]; } } // Bias updates vector _bias_v_to_h_update; _bias_v_to_h_update.Init(hidden); vector _bias_h_to_v_update; _bias_h_to_v_update.Init(visible); // Compute bias updates for (int j = 0; j < hidden; j++) { _bias_v_to_h_update[j] = learning_rate * ((old_hidden[0][j] + bias_v_to_h[j]) - new_hidden[0][j]); } for (int i = 0; i < visible; i++) { _bias_h_to_v_update[i] = learning_rate * ((new_visible[0][i] + bias_h_to_v[i]) - output[0][i]); } // Apply bias updates for (int i = 0; i < visible; ++i) { bias_h_to_v[i] += _bias_h_to_v_update[i]; } for (int j = 0; j < hidden; ++j) { bias_v_to_h[j] += _bias_v_to_h_update[j]; } }
Несмотря на то, что в старой структуре RBM на иллюстрации схематически показаны только 2 слоя, код содержит значения нейронов для 5 слоев, поскольку значения нейронов отрицательной и положительной фазы регистрируются после каждого произведения, а также после каждой активации. Таким образом, старый видимый слой регистрирует необработанные значения входных данных, старый скрытый слой регистрирует первое произведение входных данных и весов, а новый скрытый слой затем регистрирует активируемые сигмоидой значения этого продукта. Новый видимый слой регистрирует второе произведение нового скрытого слоя и отрицательных весов фазы, и, наконец, "выходной" слой регистрирует активацию произведения.
Этот традиционный подход к RBM представлен здесь только в исследовательских целях в том виде, в котором он скомпилирован, но не проверен, поскольку в этой статье основное внимание уделяется альтернативному подходу к проектированию и обучению RBM. Однако в целях анализа ключевым результатом функции семплирования по Гиббсу будут значения нейронов в первом и втором "скрытых слоях". Двойные значения этих двух наборов нейронов будут фиксировать свойства входных данных после того, как сеть будет достаточно обучена.
Так какой же нетрадиционный RBM способен сохранять основные принципы, но в другой структуре? Трехслойный перцептрон, входной и выходной слои которого имеют одинаковые размеры, а единственный скрытый размер меньше, чем эти два внешних слоя. Как можно гарантировать, что обучение по-прежнему будет проходить без учителя, учитывая что перцептроны обычно обучаются с учителем? Дело в том, что каждая строка входных данных также служит целевым выходом, что, по сути, является тем, что выполняет семплирование по Гиббсу в каждом цикле, так что наша цель получения весов для всех подключений к скрытому слою может быть достигнута, как обычно, посредством обратного распространения ошибки. Таким образом, структура нашего RBM будет напоминать изображение ниже:
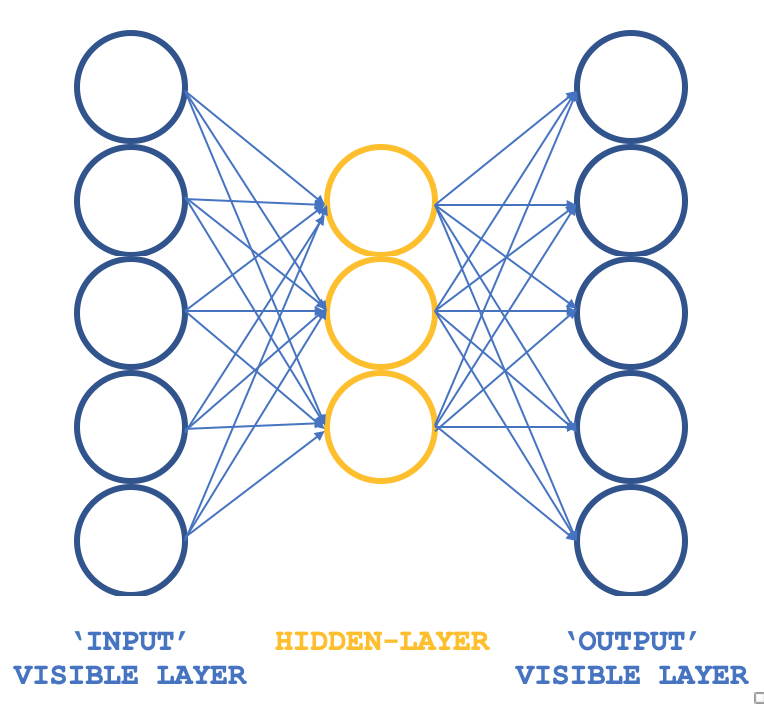
Такой подход при использовании с классами ALGLIB обеспечивает компактный и эффективный подход к тестированию RBM вместо написания всего кода с нуля. Как только появятся работоспособные идеи, можно будет рассмотреть возможность настройки и, возможно, написания кода с нуля.
Напомним, что целью обучения будет получение весов сети, которые могут точно отображать особенности входных данных в скрытом слое. Они будут извлечены и использованы на следующем этапе модели, и для наших целей их можно рассматривать как нормализованный формат входных данных.
Происхождение RBM
В статье на сайте deeplearning.net, которая, к несчастью, больше недоступна, RBM часто определяют как энергетические модели (energy-based models) из-за их способности связывать скалярную энергию с каждой конфигурацией интересующего набора данных. Обучение осуществляется путем изменения этой энергетической функции так, чтобы ее форма имела желаемые свойства. "Энергетическая функция" является разговорным названием функции, участвующей в преобразовании набора входных данных в другой (транзитный) формат и, наконец, обратно к входным данным, так что "энергия" представляет собой разницу между набором входных данных и выходными данными. Таким образом, весь смысл обучения RBM заключается в том, чтобы иметь желаемые конфигурации "низкой энергии", в которых разница между первоначальными входными данными и конечными выходными данными сведена к минимуму. Вероятностные модели, основанные на энергии, будут определять распределение вероятностей, полученное с помощью этой энергетической функции, как вектор скрытых нейронов в виде дроби суммы значений скрытых нейронов для всех выбранных входных данных.
Обычно энергетические модели обучаются путем выполнения (стохастического) градиентного спуска на эмпирическом отрицательном логарифмическом правдоподобии данных обучения. В целом, машины Больцмана не имеют скрытых слоев и все нейроны связаны между собой.
Поэтому первым шагом в упрощении вычислений является оценка математического ожидания с использованием фиксированного числа выборок модели. Образцы, используемые для оценки положительного фазового градиента, называются веса, а произведение этих матричных весов и вектора набора входных данных должно обеспечивать вектор значений нейронов (т.е. при использовании Монте-Карло). У нас почти появился практичный стохастический алгоритм для обучения RBM. Единственный недостающий ингредиент — это то, что позволило бы извлечь эти веса. Хотя статистическая литература изобилует методами выборки, методы Монте-Карло с цепью Маркова особенно хорошо подходят для таких моделей, как машины Больцмана (BM).
Машины Больцмана представляют собой особую форму лог-линейного марковского случайного поля (log-linear Markov Random Field, MRF), для которого функция энергии линейна по своим свободным параметрам. Чтобы сделать их достаточно мощными для представления сложных распределений (то есть перехода от ограниченной параметрической настройки к непараметрической), мы считаем, что некоторые переменные никогда не наблюдаются (они называются скрытыми, как указано выше). Имея больше скрытых переменных (также называемых скрытыми единицами), мы можем увеличить возможности моделирования машины Больцмана. Получающиеся в результате ограниченные машины Больцмана дополнительно ограничивают BM теми, у которых нет видимых-видимых и скрытых-скрытых связей, как показано на вводном изображении выше.
Таким образом, на практике очевидно, что не все аспекты набора данных легко "видимы", или нам приходится вводить некоторые ненаблюдаемые переменные, чтобы увеличить выразительную силу модели. Это можно рассматривать как предположение о том, что некоторые аспекты набора входных данных неизвестны и поэтому требуют изучения. Таким образом, это предположение подразумевает градиент к этим неизвестным. Градиент — это изменение или разница между известными данными и неизвестными, то есть "скрытыми" данными.
Градиент будет содержать две фазы - положительную и отрицательную. Термины "положительный" и "отрицательный" отражают их влияние на плотность вероятности или отображаемые неизвестные, определяемые моделью. Положительная фаза, известная как первая фаза, увеличивает вероятность обучающих данных (за счет уменьшения соответствующей свободной энергии), а вторая фаза уменьшает вероятность возврата выборок, сгенерированных моделью, к набору выборочных данных.
Итак, подведем итог: когда размер известных и скрытых наборов данных не определен, как в неограниченных машинах Больцмана, обычно трудно определить этот градиент аналитически, поскольку он требует большого количества вычислений. Вот почему RBM, заранее определяя количество известных и неизвестных, могут реально определить распределение вероятностей.
Сетевая архитектура и обучение
Наша трехслойная структура, показанная выше, будет реализована с использованием входного и выходного слоев размером 5 и скрытого слоя размером 3. Входными данными для 5 значений нейронов будут текущие значения индикатора. Читатель может заменить их, поскольку все источники приложены, но в этой статье мы используем значения индикаторов для скользящей средней, MACD, стохастического осциллятора, процентного диапазона Уильямса и индекса относительной бодрости (Relative Vigor Index). Нормализованный вывод, как упоминалось выше, фиксирует значения нейронов из значений первого и второго скрытого слоя, что означает, что размер этого выходного вектора вдвое превышает размер нашего скрытого слоя.
Все весовые продукты и активации обрабатываются классами ALGLIB, и они настраиваются для каждого нейрона. Соответствующий код был опубликован в прошлой статье. В этой статье мы используем значения по умолчанию, которые, безусловно, потребуют корректировки, если мы сделаем еще один шаг вперед, но сейчас они могут служить для иллюстрации получения распределения вероятностей данных.
Таким образом, соединения в этой сети напоминают бабочку, а не стрелку, как показано на схеме выше.
Обратное распространение ошибки в обычной нейронной сети корректирует веса соединений путем градиентного спуска с помощью правила многомерной цепочки (multivariate chain rule). Это не похоже на контрастное расхождение, и оно не только потребует более интенсивных вычислений, но и может привести к совершенно другим весам (распределениям вероятностей) по сравнению с тем, что вы должны получить в обычном RBM. Мы используем его для тестовых запусков в этой статье, и, поскольку полный исходный код является общим, изменения на этом этапе могут быть настроены.
Как упоминалось выше, обратное распространение ошибки обычно контролируется, потому что вам нужны целевые значения для получения градиентов, и в нашем случае, поскольку входные данные служат целью, наш модифицированный RBM по-прежнему квалифицируется как не имеющий учителя.
При обучении наша сеть будет корректировать веса таким образом, чтобы выходные данные были как можно ближе к входным. При этом любой новый набор данных, поступающий в сеть, будет предоставлять ключевую информацию нейронам скрытого слоя. Эта информация, поступающая от нейронов, имеет формат массива, как и следовало ожидать. Однако размер этого массива вдвое превышает количество нейронов в скрытом слое. В формате, который мы адаптируем для тестирования, нейронов в скрытом слое три, поэтому это означает, что наш выходной массив, который фиксирует свойства пяти искомых нами индикаторов, имеет размер 6.
Эти значения скрытых нейронов можно рассматривать как формат нормализации пяти значений индикатора. В этом случае у нас нет уменьшения размерности, поскольку вектор свойств имеет размер 6, и все же мы использовали 5 значений входного индикатора, однако, если бы мы использовали больше индикаторов, скажем, 8, и сохранили бы количество нейронов на скрытом слое на уровне 3, у нас было бы сокращение.
Так как же нам использовать эти значения? Если мы придерживаемся точки зрения, что они представляют собой просто нормализацию значений индикаторов, они могут служить вектором классификации, который может быть полезен при сравнении, если мы теперь будем использовать их в другой модели, где мы добавим учителя в форме возможного изменения цены после каждого набора значений индикатора. Итак, все, что мы делаем, это сравниваем вектор текущих значений, возможное изменение цены которого неизвестно, с другими векторами, изменения которых известны, и средневзвешенное значение, где косинусное сходство между этими векторами может действовать как вес, обеспечивает средний прогноз следующего изменения.
Разработка сети на MQL5
Интерфейс для реализации нашего странного RBM может выглядеть так, как показано ниже:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Crbm { protected: int visible; int hidden; int sample; double loss; string file; public: bool init; ... CArrayDouble losses; void Train(matrix &W); void Process(matrix &W, matrix &XY, bool Compare = false); bool ReadWeights(); bool WriteWeights(); bool Writer(); Crbm(int Visible, int Hidden, int Sample, double Loss, string File); ~Crbm(); };
В интерфейсе мы объявляем и используем базовые минимальные классы, которые нам потребуются для запуска перцептрона, как мы делали в предыдущих статьях. Единственным заметным дополнением является двойной массив losses, который помогает нам отслеживать разницу между входным и выходным слоями, а также по ходу дела указывать, какие сети получают свои экспортируемые параметры, записываемые в файл, поскольку, как уже подчеркивалось в прошлом, перцептроны должны быть протестирован с возможностью экспорта настраиваемых параметров, чтобы при развертывании или перемещении советника в производственную среду полученные веса можно было легко использовать, а не каждый раз заново обучать на основе начальных случайных весов.
Таким образом, массив losses просто записывает косинусное сходство между наборами входных и выходных данных для каждой строки данных на каждом ценовом баре. В конце тестового прогона веса сетей или экспортируемые параметры записываются в файл, если число совпадений косинусов ниже входного порога (значение по умолчанию для этого составляет 0,9, но его можно настроить) меньше, чем было записано последний раз, когда файл был зарегистрирован. Этот пороговый параметр помечен как loss.
Синтаксис, используемый для умножения весов и входных значений, вероятно, более сложен, чем следовало бы, учитывая, что matrix и vector теперь являются встроенными типами данных в MQL5. Простое их умножение при мониторинге ассоциации и соответствующих размеров строк и столбцов может привести к тому же результату с меньшим объемом памяти и, следовательно, меньшими вычислительными ресурсами.
Сетевая функция использует классы ALGLIB для инициализации, обучения и обработки наборов данных. Дополнительные настройки с использованием собственного жестко закодированного перцептрона могут привести к повышению эффективности при тестировании и развертывании, поскольку код ALGLIB довольно сложен и "запутан", поскольку, будучи библиотекой, он имеет тенденцию обслуживать более широкий спектр сценариев. Однако даже при готовой реализации можно выполнить некоторые базовые настройки, такие как активация и смещения, и их влияние на производительность сети может быть очень значительным. Это может оказаться полезным на начальном этапе тестирования, который мы здесь и изучаем.
Итак, с помощью этой тестовой установки мы обучаем нашу нетрадиционную RBM на каждом новом баре или всякий раз, когда мы получаем новую ценовую точку, подразумевая, что веса, от которых мы зависим при классификации каждой точки входных данных, уточняются и корректируются с каждым проходом. Можно также изучить альтернативные подходы к корректировке весов, такие как корректировка весов один раз в квартал или два раза в год при условии, что перед использованием сети было проведено обучение в течение приличного количества лет. В статье они не рассматриваются, но упоминаются как возможные пути, которыми читатель может воспользоваться. Функции обучения и процесса определены, как указано ниже:
//+------------------------------------------------------------------+ //| Train Data Matrix | //+------------------------------------------------------------------+ void Crbm::Train(matrix &W) { for(int s = 0; s < sample; s++) { for(int i = 0; i < visible; i++) { xy.Set(s, i, W[s][i]); xy.Set(s, i + visible, W[s][i]); } } train.MLPTrainLM(model, xy, sample, 0.001, 2, info, report); }
Код довольно прост, поскольку его созданием занимаются классы ALGLIB. Функция process кодируется следующим образом:
//+------------------------------------------------------------------+ //| Process New Vector | //+------------------------------------------------------------------+ void Crbm::Process(matrix &W, matrix &XY, bool Compare = false) { for(int w = 0; w < int(W.Rows()); w++) { CRowDouble _x = CRowDouble(W.Row(w)), _y; base.MLPProcess(model, _x, _y); for(int i = 6; i < visible + 7; i++) { XY[w][i - 6] = model.m_neurons[i]; } //Comparison vector _input = _x.ToVector(); vector _output = _y.ToVector(); if(Compare) { for(int i = 0; i < int(_input.Size()); i++) { printf(__FUNCSIG__ + " at: " + IntegerToString(i) + " we've input: " + DoubleToString(_input[i]) + " & y: " + DoubleToString(_y[i]) ); } //Loss printf(__FUNCSIG__ + " loss is: " + DoubleToString(_output.Loss(_input, LOSS_COSINE)) ); } losses.Add(_output.Loss(_input, LOSS_COSINE)); } }
Эта функция в некотором смысле представляет собой "секретный ингредиент" алгоритма, поскольку она показывает, как мы извлекаем значения скрытых нейронов из перцептрона для каждого значения входных данных. Мы извлекаем эти веса на каждом баре в виде выборки. Поэтому мы выводим их в матричном формате, где строка входных данных дает нам вектор весов.
Веса, извлекаемые для каждой точки входных данных, служат нормализованными формами пяти значений индикаторов, а упомянутое выше сравнение взвешенных векторов можно реализовать следующим образом:
//+------------------------------------------------------------------+ //| RBM Output. | //+------------------------------------------------------------------+ double CSignalRBM::GetOutput(void) { m_close.Refresh(-1); MA.Refresh(-1); MACD.Refresh(-1); STOCH.Refresh(-1); WPR.Refresh(-1); RVI.Refresh(-1); double _output = 0.0; int _i=StartIndex(); matrix _w; _w.Init(m_sample,__VISIBLE); matrix _xy; _xy.Init(m_sample,7); if(RBM.init) { for(int s=0;s<m_sample;s++) { for(int i=0;i<5;i++) { if(i==0){ _w[s][i] = MA.GetData(0,_i+s); } else if(i==1){ _w[s][i] = MACD.GetData(0,_i+s); } else if(i==2){ _w[s][i] = WPR.GetData(0,_i+s); } else if(i==3){ _w[s][i] = STOCH.GetData(0,_i+s); } else if(i==4){ _w[s][i] = RVI.GetData(0,_i+s); } } if(s>0){ _xy[s][2*__HIDDEN] = m_close.GetData(_i+s)-m_close.GetData(_i+s+1); } } RBM.Train(_w); RBM.Process(_w,_xy); double _w=0.0,_w_sum=0.0; vector _x0=_xy.Row(0); _x0.Resize(6); for(int s=1;s<m_sample;s++) { vector _x=_xy.Row(s); _x.Resize(6); double _weight=fabs(1.0+_x.Loss(_x0,LOSS_COSINE)); _w+=(_weight*_xy[s][6]); _w_sum+=_weight; } if(_w_sum>0.0){ _w/=_w_sum; } _output=_w; } return(_output); }
С помощью последнего цикла for мы получаем средний вероятный прогноз, основанный на весовом коэффициенте косинусного сходства с другими точками данных, которые имеют известный Y (возможное изменение цены).
Мы оптимизировали этот настроенный экземпляр класса сигналов советника для GBPUSD H4 с 2023.07.01 по 2023.10.01 с помощью пошагового теста с 2023.10.01 по 2023.12.25 и получили следующие отчеты.


Результаты потенциально неплохие. Обычное тестирование в идеале должно проводиться с реальными тиками брокера, с которым вы собираетесь торговать. И в идеале это должно произойти после того, как будут внесены соответствующие изменения и настройки не только в источники входных данных, но, возможно, в конструкцию и эффективность перцептрона. Последний бит важен, потому что надежные результаты тестирования должны быть получены за длительные периоды исторических данных, поэтому с исходным кодом ALGLIB "из коробки" эта задача может оказаться сложной.
Заключение
Мы рассмотрели традиционное определение сети RBM и то, как ее можно реализовать на MQL5. Что еще более важно, мы изучили нетрадиционный вариант этой сети, который структурирован и обучен во многом как простой многослойный перцептрон, и рассмотрели, можно ли использовать "распределение вероятностей", которое мы называли выходными весами, при построении другого пользовательского экземпляра класса сигнала советника. Результаты обратного и прямого тестирования показывают, что существует потенциал использования системы при условии более тщательного тестирования и, возможно, точной настройки выбора входных данных.
Примечания
Прикрепленный код можно использовать после сборки с помощью Мастера MQL5. Я уже описывал, как это можно сделать, в предыдущих статьях серии. Эта статья также может служить руководством для тех, кто не знаком с Мастером.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/13988
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования