
Teoria das Categorias em MQL5 (Parte 14): funtores com ordem linear
Introdução
A teoria das categorias, conforme introduzida por Samuel Eilenberg e Saunders Mac Lane na década de 1950, pode ser vista como um meio de estudar sistemas com ênfase na transformação em cada fase, em vez das fases em si. Ela tem sido usada em uma ampla gama de aplicações, desde programação funcional com linguagens como Haskell; até linguística, estudando a estrutura e composicionalidade de línguas naturais; até topologia algébrica, proporcionando uma abordagem unificada para entender diferentes construções topológicas e invariantes, para citar apenas algumas.
Nesta série, a teoria das categorias tem se concentrado até agora em informações e estruturas em níveis de subcategorias, principalmente conjuntos (objetos) em nosso caso. Já analisamos suas relações e propriedades, tudo dentro de uma categoria.
O propósito deste artigo e de alguns outros que seguirão é ampliar o foco de uma categoria e começar a examinar as relações que diferentes categorias podem ter entre si. Formalmente, essas são referidas como funtores. Portanto, vamos analisar várias categorias e suas possíveis relações. Dentro do conjunto de dados de um trader, existem várias categorias que valem a pena estudar. No entanto, para enfatizar as qualidades transcendentais da teoria das categorias, vamos sair da caixa e, neste artigo, examinar a relação entre os dados das marés oceânicas coletados na costa da Califórnia e a volatilidade do Índice NASDAQ. Há algo nas marés oceânicas que prenuncia a volatilidade deste índice? Esperamos poder responder a essa pergunta, em algum grau, até o final do artigo.
Este artigo e alguns outros que seguirão não introduzirão novos conceitos em si, mas revisarão o que já foi abordado e buscarão aplicá-lo de maneira diferente, o que pode significar em uma escala mais ampla.
Marés oceânicas e índice NASDAQ
Os dados das marés oceânicas são publicados e disponibilizados ao público pela Administração Nacional Oceânica e Atmosférica (NOAA) por meio de seu site, que pode ser visto aqui. Os dados registram a altura da maré oceânica em relação a um ponto de referência, quatro vezes ao dia. O horário e a altitude da maré em cada momento são os únicos dados registrados para cada dia ao longo do ano. Aqui está uma prévia:

Todos os oceanos são divididos em 4 regiões, com valores de maré coletados de várias estações de medição em cada região. Para a Costa Oeste da América do Norte, por exemplo, que se estende do Chile, na América do Sul, até o Alasca, existem 33 estações. Para nossa análise, escolheremos os dados coletados na estação de Monterey, na Califórnia, no ano de 2020.
O NASDAQ é uma bolsa de valores bem estabelecida, mas aqui o estamos analisando principalmente como um índice, composto por várias empresas de tecnologia, como MSFT, AAPL, GOOG e AMZN, todas sediadas na Califórnia. Este índice pode ser negociado pela maioria das corretoras, portanto, seu feed de preços informará nossa categoria, à medida que verificamos se o valor de mercado dessas empresas, que revolucionaram setores e exemplificam o espírito inovador da Califórnia, está de alguma forma relacionado aos dados das marés oceânicas coletados em sua costa.
Mapeamento de dados usando os funtores da teoria das categorias
Ainda não falamos explicitamente sobre funtores na série até agora, no entanto, nos artigos em que examinamos monoides, grupos de monoides, gráficos e ordens, estava implícito que estávamos lidando com funtores, porque cada um desses conceitos poderia ser considerado uma categoria e suas relações muitas vezes formavam a base dos artigos em que estavam. Assim, o morfismos entre monoides eram, por exemplo, funtores de facto.
Formalmente, um funtor é uma correspondência entre categorias que preserva sua estrutura e relações, conforme definido pelos objetos e seus morfismos em cada uma. Se C e D são categorias, então o funtor F de C para D
Consiste em duas coisas, ou seja, para cada objeto c em C, há um objeto associado F(c) em D e para cada dois objetos em b, c em C com um morfismo f
![]()
existe um morfismo associado F(f)
em D.Funções também têm os axiomas adicionais de preservar a composição, o que significa que, se tivermos morfismos
![]()
e
em C, então F preserva a composição em C, de tal forma que
e morfismos de identidade em C são preservados para cada objeto associado em D, de tal forma que, se
então
A importância de relacionar diferentes categorias reside na descoberta. Para cada sistema classificado como uma categoria, muitas vezes não há uma maneira de não apenas traduzir uma categoria em outra, mas também de estabelecer a 'posição relativa' e talvez a importância de cada categoria dentro de um contexto mais amplo. É por isso que os funtores, que por exemplo, poderiam associar uma categoria de valores negociáveis com seu próprio portfólio de morfismos ponderados para outra categoria de estratégias de negociação. O benefício de tal funtor para traders pode estar relacionado à perspectiva, mas se o funtor mapear com um atraso de tempo, poderemos estabelecer quais estratégias usar com base em nossos valores mobiliários em carteira ou quais valores mobiliários manter a seguir com base em nossa estratégia atual, por exemplo.
Uma ordem linear ou ordem total, para recapitular, além de atender aos axiomas de transitividade e reflexividade, também atende aos requisitos de anti-simetria e comparabilidade. Isso geralmente significa que todos os dados em uma ordem linear devem ser numéricos, ou, se forem textuais, devem ser discretos, de modo que a operação binária '<=' possa ser aplicada sem ambiguidade ou gerar um resultado indefinido. Os dados das marés oceânicas, conforme representados no site da NOAA, são multidimensionais se considerarmos um dia como um único ponto de dados. Eles têm 4 entradas de data e hora para cada altura, 4 valores em ponto flutuante das alturas e a entrada de data e hora para o dia. Se considerarmos nossa ordem linear para comparar o valor da data e hora do dia para cada ponto de dados, então os dados oceânicos se tornam uma série temporal simples com 2 conjuntos de dados em cada ponto, a data como data e hora e a altura da maré como dados em ponto flutuante.
Representar essa ordem linear como uma categoria significaria que a operação binária entre dois pontos de dados consecutivos se tornaria um morfismo e cada ponto de dados se tornaria um objeto, que contém 4 conjuntos de dados: as 4 datas e horas em que as alturas foram registradas e os 4 valores de altura, se agruparmos esses dados em dias, já que esses valores de maré eram capturados diariamente. No entanto, precisamos normalizar um pouco mais esses dados, já que nem todos os dias têm 4 pontos de dados. Alguns têm apenas 3. Como nossa categoria terá relações isomórficas simples, é importante que sejamos consistentes com o número de elementos em cada domínio (dia).
A categoria de volatilidade do NASDAQ seguiria um padrão semelhante ao das marés oceânicas, pois vinculamos os pontos de dados de preço com base na sequência no tempo, como morfismos.
Análise comparativa e ideias
Se mapearmos nossa categoria de maré com a categoria do Índice NASDAQ, teríamos que fazer isso com um atraso no tempo para obter algum benefício de previsão. Mas primeiro, precisaríamos construir uma instância da categoria de classe de marés oceânicas, e isso pode ser representado como mostrado abaixo:
protected:
...
CCategory _category_ocean,_category_nasdaq;
CDomain<string> _domain_ocean,_domain_nasdaq;
CHomomorphism<string,string> _hmorph_ocean,_hmorph_nasdaq; Como estamos interessados em usar esse functor para previsões, nossa categoria será dinâmica, ou seja, ela será redefinida a cada nova barra, mas o functor dela para a categoria NASDAQ será constante. Desse modo, como nosso atraso é de um dia, os três morfismos mencionados anteriormente que vinculam as altitudes oceânicas registradas podem ser definidos a partir da leitura dos dados das marés oceânicas no arquivo CSV da seguinte forma:
void CTrailingCT::SetOcean(int Index)
{
...
if(_handle!=INVALID_HANDLE)
{
...
while(!FileIsLineEnding(_handle))
{
...
if(_date>_data_time)
{
_category_ocean.SetDomain(_category_ocean.Domains(),_domain_ocean);
break;
}
else if(__DATETIME.day_of_week!=6 && __DATETIME.day_of_week!=0 && datetime(int(_data_time)-int(_date))<=PeriodSeconds(PERIOD_D1))//_date<=_data_time && datetime(int(_data_time)-(1*PeriodSeconds(PERIOD_D1)))<=_date)
{
_element_value.Let();_element_value.Cardinality(1);_element_value.Set(0,DoubleToString(_value));
_domain_ocean.Cardinality(_elements);_domain_ocean.Set(_elements-1,_element_value);
_elements++;
}
}
FileClose(_handle);
}
else
{
printf(__FUNCSIG__+" failed to load file. Err: "+IntegerToString(GetLastError()));
}
} Da mesma forma, construiremos nosso conjunto de volatilidade da NASDAQ com a lista abaixo:
void CTrailingCT::SetNasdaq(int Index)
{
m_high.Refresh(-1);
m_low.Refresh(-1);
_value=0.0;
_value=(m_high.GetData(Index+StartIndex()+m_high.MaxIndex(Index,_category_ocean.Homomorphisms()))-m_low.GetData(Index+StartIndex()+m_low.MinIndex(Index,_category_ocean.Homomorphisms())))/m_symbol.Point();
_element_value.Let();_element_value.Cardinality(1);_element_value.Set(0,DoubleToString(_value));
_domain_nasdaq.Cardinality(1);_domain_nasdaq.Set(0,_element_value);
_category_nasdaq.SetDomain(_category_nasdaq.Domains(),_domain_nasdaq);
} Seus morfismos também são montados de uma maneira não muito diferente. Agora, o funtor, como já mencionado na definição, mapeia não apenas os objetos entre as duas categorias, mas também mapeia os morfismos. Isso meio que implica que um verifica o outro. Se começarmos com o mapeamento de objetos, parte do nosso funtor para os dados das marés oceânicas para a NASDAQ, ele é inicializado da seguinte forma:
double CTrailingCT::GetOutput()
{
...
...
_domain.Init(3+1,3);
for(int r=0;r<4;r++)
{
CDomain<string> _d;_d.Let();
_category_ocean.GetDomain(_category_ocean.Domains()-r-1,_d);
for(int c=0;c<_d.Cardinality();c++)
{
CElement<string> _e; _d.Get(c,_e);
string _s; _e.Get(0,_s);
_domain[r][c]=StringToDouble(_s);
}
}
_codomain.Init(3);
for(int r=0;r<3;r++)
{
CDomain<string> _d;
_category_nasdaq.GetDomain(_category_nasdaq.Domains()-r-1,_d);
CElement<string> _e; _d.Get(0,_e);
string _s; _e.Get(0,_s);
_codomain[r]=StringToDouble(_s);
}
_inputs.Init(3);_inputs.Fill(m_consant_morph);
M(_domain,_codomain,_inputs,_output,1);
return(_output);
} Da mesma forma, a construção do funtor dos morfismos terá a seguinte forma:
double CTrailingCT::GetOutput()
{
...
...
_domain.Init(3+1,3);
for(int r=0;r<4;r++)
{
...
if(_category_ocean.Domains()-r-1-1>=0){ _category_ocean.GetDomain(_category_ocean.Domains()-r-1-1,_d_old); }
for(int c=0;c<_d_new.Cardinality();c++)
{
...
CElement<string> _e_old; _d_old.Get(c,_e_old);
string _s_old; _e_old.Get(0,_s_old);
_domain[r][c]=StringToDouble(_s_new)-StringToDouble(_s_old);
}
}
_codomain.Init(3);
for(int r=0;r<3;r++)
{
...
if(_category_nasdaq.Domains()-r-1-1>=0){ _category_nasdaq.GetDomain(_category_nasdaq.Domains()-r-1-1,_d_old); }
...
CElement<string> _e_old; _d_old.Get(0,_e_old);
string _s_old; _e_old.Get(0,_s_old);
_codomain[r]=StringToDouble(_s_new)-StringToDouble(_s_old);
}
_inputs.Init(3);_inputs.Fill(m_consant_morph);
M(_domain,_codomain,_inputs,_output,1);
return(_output);
} A maior parte do trabalho aqui está em tornar os dados das marés oceânicas acessíveis ao MQL5. Para isso, os dados são acessados a partir de um arquivo CSV na pasta de dados comum em um formato tabular semelhante ao nosso elemento na categoria de marés oceânicas. O formato dos dados inclui um campo de data e hora para sincronização com o horário do servidor de negociação ao selecionar os valores corretos. O IDE do MQL5 tem outras alternativas para acessar esses dados secundários e uma delas é por meio de um banco de dados, pois é possível projetar uma conexão nativa a partir do IDE. Portanto, se você tiver um banco de dados na máquina local ou uma conexão em nuvem, isso pode ser explorado. Para nossos propósitos, no entanto, como gostaria que os leitores pudessem replicar facilmente os resultados dos testes postados aqui, um arquivo CSV na pasta comum está sendo usada.
Nosso funtor mapeia duas coisas entre as categorias, o que significa que, para evitar duplicidade, simplesmente teremos uma conexão verificando ou confirmando a outra. Como no início não sabemos qual dessas configurações seria ideal para nosso sistema de negociação, testaremos ambas.
Por isso, na primeira configuração, teremos o funtor entre os objetos confirmando ou verificando os morfismos entre os objetos no codomínio (conjunto NASDAQ). Isso pode ser representado diagramaticamente como abaixo:
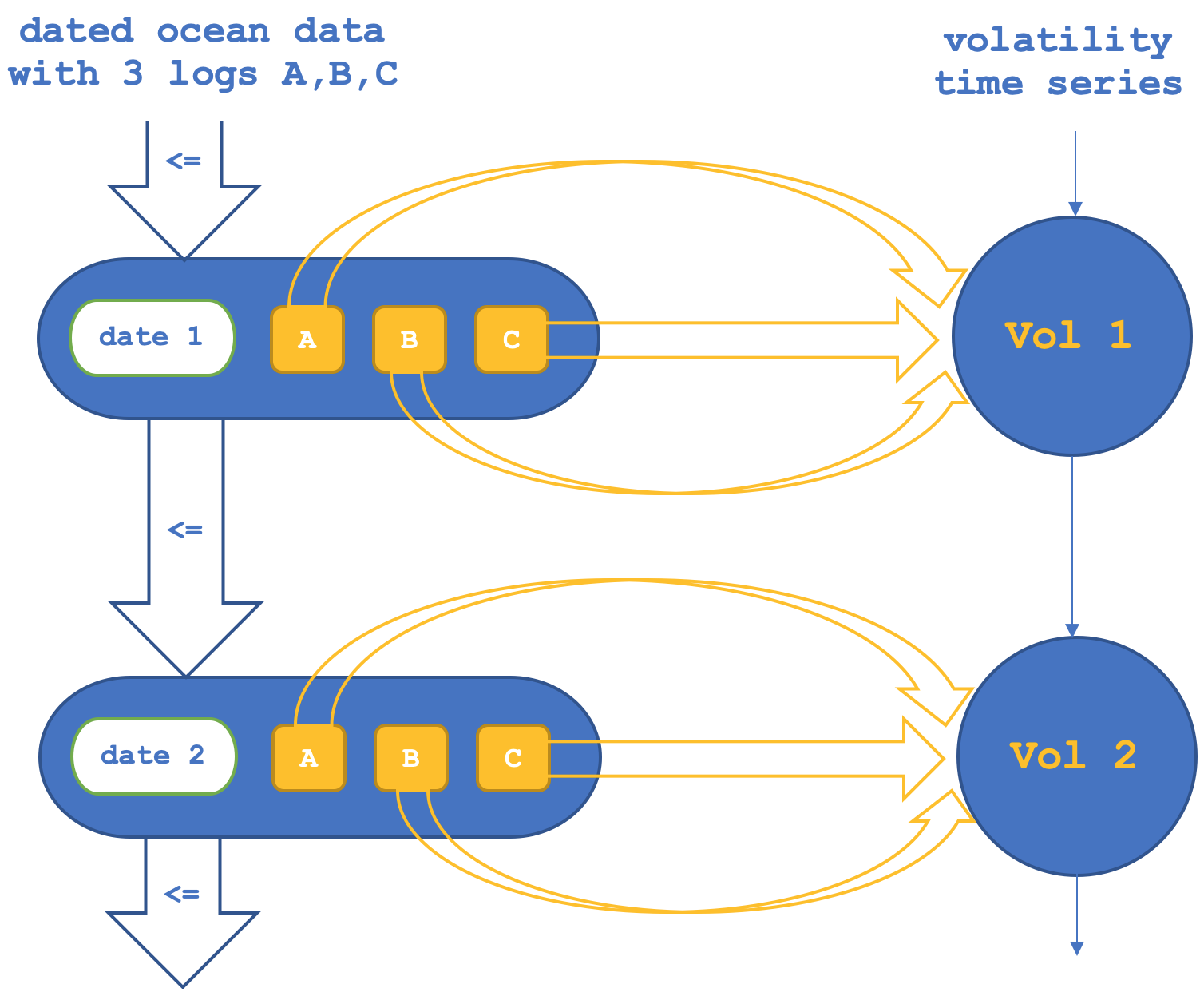
Se executarmos testes para tentar prever a volatilidade da NASDAQ com base apenas nos funtores de objetos, obtemos relatórios como o abaixo (o código para isso está anexado como 'TraillingCT_14_1a'):

Se, como mencionado, também tentarmos o oposto, onde nos concentramos nos funtores entre os morfismos e depois confirmamos os objetos, isso pode ser representado da seguinte forma:
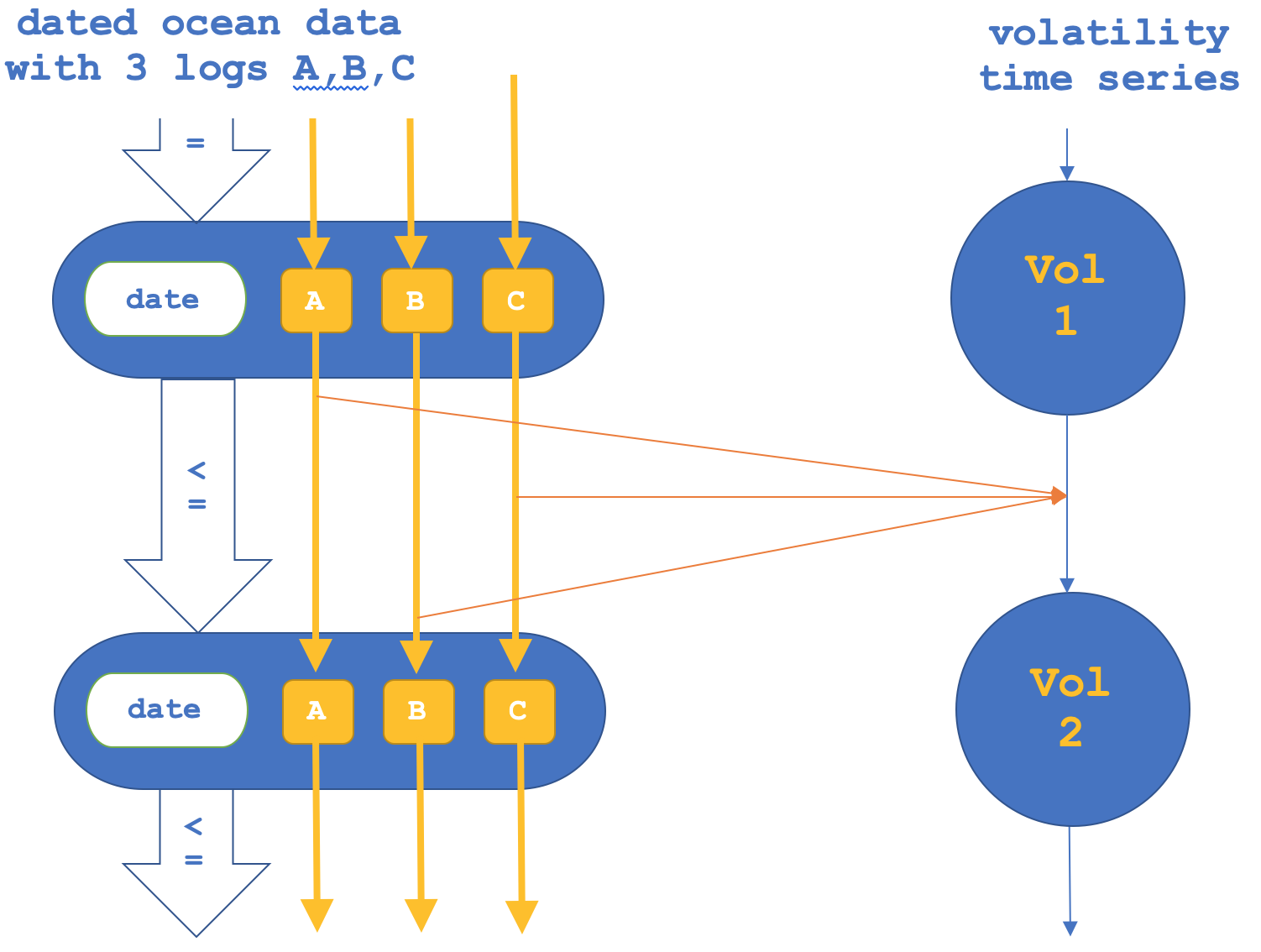
O relatório do testador apenas para funtores de morfismo é indicado abaixo:

Das nossas duas opções de teste acima, mapear objetos versus mapear morfismos produziu resultados diferentes, mesmo durante a janela de teste muito curta, de 1º de janeiro de 2020 a 15 de março do mesmo ano, em um intervalo diário. Qual das duas opções poderia ser mais útil para os traders na realização de previsões de qualquer tipo, não apenas em relação à volatilidade, exigiria testes ao longo de períodos mais longos no aspecto específico do sistema de negociação em teste, seja o sinal de entrada, gestão de dinheiro ou trailing stop, como é o caso aqui.
O período escolhido para este teste, embora muito curto, foi realmente significativo para o NASDAQ, pois foi quando o índice atingiu suas máximas históricas e, em meio ao início da pandemia de covid, declinou bastante precipitadamente. Por isso, embora este teste sugira uma possível correlação com os dados das marés oceânicas, certamente não está implicando nenhuma causalidade.
Como tem sido o caso desta série, o sinal de entrada usado é muito básico, neste caso foi o oscilador incrível embutido nas configurações padrão do respectivo arquivo de sinal. O dimensionamento da posição também foi fixo, como de costume. Testamos o NASDAQ no intervalo diário porque nossos dados de categoria de domínio foram coletados diariamente, em três intervalos. Assim, ao formatar isso como uma ordem linear equivalente de categoria, cada dia constituiu um domínio (objeto) que continha 3 elementos, que eram os três pontos de dados de cada dia, como mencionado anteriormente.
O que deve ser o grande aprendizado aqui é que conjuntos de dados díspares e aparentemente não relacionados podem ser examinados e testados em busca de relações defasadas úteis que podem ajudar a orientar as decisões de negociação. Em nossos testes acima, o defasamento foi de um único dia, mas o seu poderia ser mais longo. Conjuntos de dados alternativos aos que usamos aqui, como as marés oceânicas, poderiam ter sido escolhidos, e a lista é muito longa. Mas talvez seja útil compartilhar alguns exemplos de conjuntos de dados que podem substituir os dados das marés oceânicas usados acima e que também forneceriam mais insights sobre como nossos mercados e sistemas exógenos estão interconectados.
Conjuntos de dados alternativos poderiam incluir preços de commodities; notícias de tecnologia, onde o número de artigos sobre novas tendências tecnológicas, por exemplo, como IA, em comparação com artigos de notícias alternativas, como entretenimento, poderia ser rastreado com um atraso para possíveis relações; dados de sentimento em redes sociais sobre o tom das postagens de mídia social, quantificados por métodos baseados em léxicos, também podem ser examinados em relação à volatilidade do NASDAQ (ou de qualquer título negociado), especialmente se estiver relacionado a ações de tecnologia. Esses exemplos novamente estão inclinados para o lado esotérico para ajudar a construir uma vantagem, mas conjuntos de dados mais próximos de casa, como preços de outros títulos ou valores de indicadores, também podem ser considerados.
Considerações finais
Nós examinamos como os dados em uma categoria de formato de ordem linear podem ser relacionados usando um funtor com os preços de ativos financeiros. Neste caso, nossos dados de domínio consistiam em um conjunto de dados improváveis sobre as alturas das marés oceânicas coletadas ao longo da costa da Califórnia. Tentamos relacioná-los com a volatilidade do NASDAQ com um atraso diário por meio de um funtor. Essa relação pode assumir duas formas: de objetos para objetos ou de morfismos para morfismos. Como resultado de nossos testes, que incluíram o uso dos mesmos sinais de entrada e métodos de dimensionamento de posição, ambas as formas produziram resultados significativamente diferentes, dado o curto período de teste.
Funtores na teoria das categorias podem desempenhar um papel importante na associação de diferentes tipos de dados. Para este artigo, usamos um conjunto de dados bastante complexo para fins de classificação e associação, mas o leitor pode encontrar opções mais adequadas. Embora essas opções não necessariamente proporcionem uma vantagem, elas podem ser úteis para fins de teste.
As futuras possibilidades de associação de ordem linear com conjuntos de dados, do ponto de vista do trader, podem seguir várias direções. Isso pode incluir previsões meteorológicas, integração de dados e gráficos em áreas como inteligência artificial, aprendizado de máquina e transferência de aprendizado, nas quais as ordens lineares, que são funtores relacionados a dados financeiros, podem ser mais desenvolvidas. Por exemplo, os pesos dos funtores obtidos entre duas categorias podem ser testados ou até mesmo aplicados em diferentes áreas, potencialmente aprimorando modelos de aprendizado de máquina e sua eficácia.
Existem muitas outras oportunidades, incluindo análise estatística e agregação de dados, inferências aleatórias e estudos de correlação, financiamento quantitativo com financiamento algorítmico, tomada de decisões baseadas em dados e muito mais. A escolha da aplicação dependerá da perspectiva ou abordagem do trader.
Os leitores são incentivados a explorar esta área de acordo com sua especialização e abordagem de mercado. O campo tem um grande potencial, incluindo análises interdisciplinares de dados.
Coloque os arquivos TrailingCT_14_1a.mqh e TrailingCT_14_1b.mqh na pasta MQL5\include\Expert\Trailing\ e o arquivo ct_14_1s.mqh pode ser colocado na pasta Include.
As recomendações fornecidas aqui sobre como criar um EA com a ajuda do Assistente podem ser úteis para você. Conforme mencionado no artigo, usei o Awesome Oscillator como sinal de entrada e margem fixa para o gerenciamento de capital. Ambos os componentes fazem parte da biblioteca MQL5. Como sempre, o objetivo do artigo não é apresentar a você uma solução definitiva, mas sim oferecer uma ideia que você possa adaptar à sua própria estratégia. Os arquivos anexos foram compilados usando o Assistente. Você pode compilá-los ou criar seus próprios.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/13018
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso