
Funcionalidades do assistente MQL5 que você precisa conhecer (Parte 07): Dendrogramas
Introdução
Este artigo, que faz parte da série sobre o uso do Assistente MQL5, revisa os dendrogramas. Já estudamos várias ideias relacionadas ao Assistente MQL5 que podem ser úteis para traders, como: análise discriminante linear, cadeias de Markov, transformada de Fourier e algumas outras. Este artigo discute maneiras de usar o extenso código ALGLIB, traduzido pela MetaQuotes, junto com o uso do Assistente MQL5 embutido para testar e desenvolver novas ideias efetivamente.
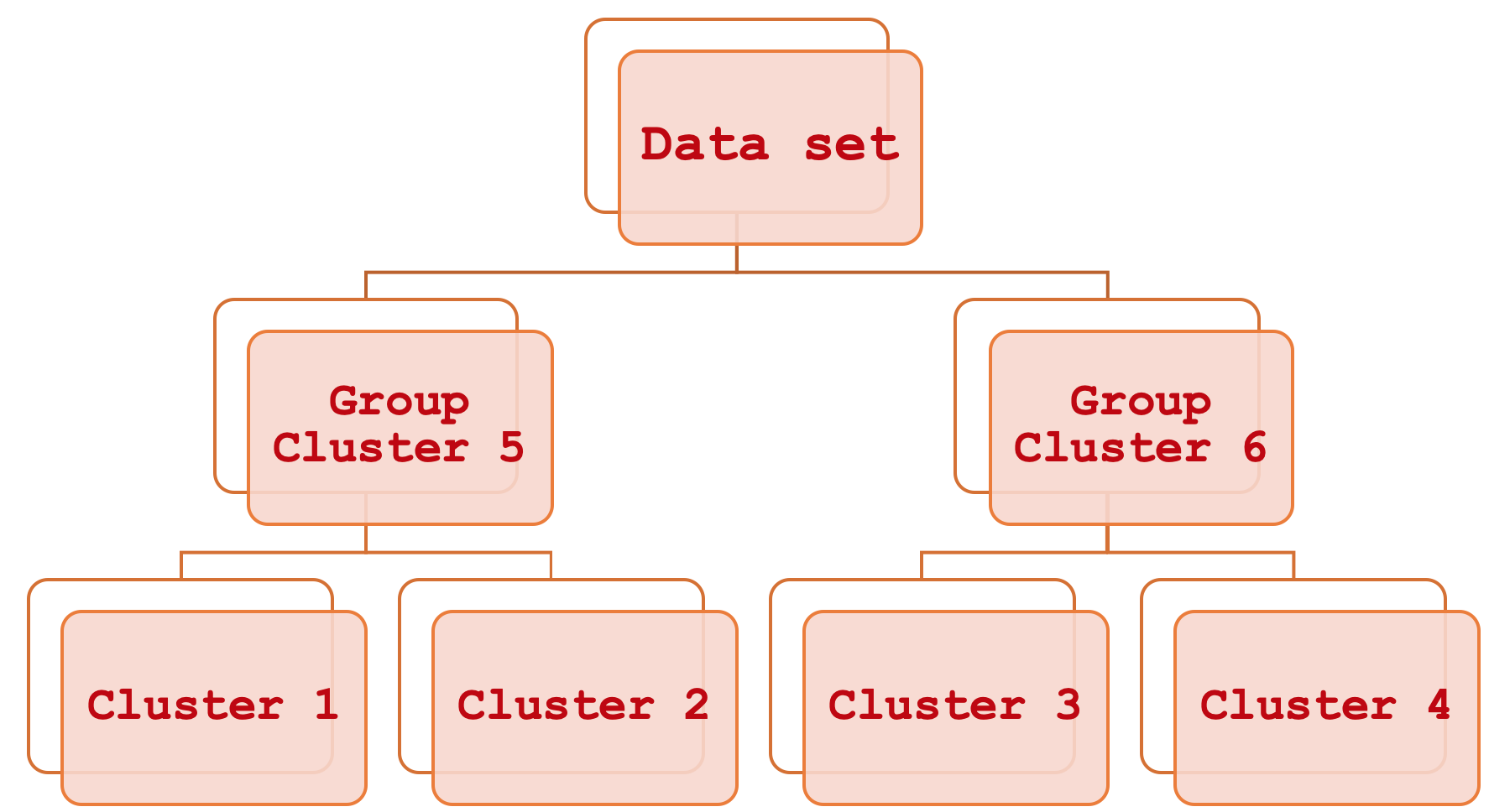
O agrupamento hierárquico aglomerativo parece muito complexo, mas na realidade é bastante simples. Em resumo, é uma maneira de ligar diferentes partes de um conjunto de dados, começando por considerar os principais agrupamentos individuais, e então agrupando-os sistematicamente passo a passo, até que todo o conjunto de dados seja visto como uma única unidade organizada. O resultado desse processo é um diagrama hierárquico, mais comumente chamado de dendrograma.
O foco do artigo será em como esses agrupamentos constituintes podem ser usados para avaliar e, assim, prever a faixa de preços das barras, mas, diferentemente dos artigos anteriores, quando isso era feito para auxiliar na configuração de trailing stops, aqui usaremos o conhecimento adquirido para gerenciamento de capital e determinação do tamanho da posição. Como o artigo é voltado para aqueles que estão apenas começando a se iniciar na plataforma MetaTrader e a linguagem de programação MQL5, usuários experientes podem achar alguns tópicos desinteressantes.
A importância de obter previsões exatas a partir da faixa de preços é em grande parte subjetiva. Seu valor depende em grande medida da estratégia do trader e da abordagem geral para a negociação. Quando a precisão das previsões não é muito importante? Por exemplo, quando em suas configurações de trading você inicialmente usa uma alavancagem mínima ou não a usa de todo, tem um stop-loss definido, e tende a manter posições por longos períodos que podem durar, digamos, meses, e você tem um tamanho fixo de posição de margem (ou mesmo um lote fixo). Nesse caso, a volatilidade do preço da barra pode ser relegada a um segundo plano, enquanto você se concentra na verificação dos sinais de entrada e saída. Se você é um trader intradiário, usa uma grande alavancagem ou não deixa posições de trading abertas durante o fim de semana, ou tem um tempo médio/curto de retenção de posições no mercado, então a faixa de preços das barras é definitivamente algo que você deve considerar. Quanto ao gerenciamento de capital, veremos como aproveitar a faixa por meio de nossa própria instância da classe ExpertMoney. Porém, sua aplicação pode ir além do gerenciamento de capital e até incluir risco, já que entender e prever de forma sensata a faixa de preços da barra pode ajudar a decidir quando aumentar as posições abertas e, inversamente, quando as reduzir.
Volatilidade
As faixas de preços das barras (é assim que definimos volatilidade neste artigo) no contexto da negociação é a diferença entre o máximo e o mínimo preço do símbolo negociado durante um período de tempo estabelecido. Se tomarmos, digamos, um período diário, e durante o dia o preço do símbolo negociado subir para o nível H, mas não acima de H, e cair para o nível L e novamente não abaixo de L, então nossa faixa para os propósitos deste artigo é calculada como:
H – L;
A volatilidade é importante por causa de um fenômeno frequentemente chamado de agrupamento de volatilidade (volatility clustering). Este fenômeno ocorre quando períodos de alta volatilidade geralmente são seguidos por ainda mais volatilidade e, inversamente, períodos de baixa volatilidade também são acompanhados por menor volatilidade. A importância disso é subjetiva, como mencionado anteriormente, porém, para a maioria dos traders (incluindo, na minha opinião, todos os iniciantes) saber como negociar usando alavancagem pode ser uma vantagem a longo prazo, já que alta volatilidade pode levar a um stop out não porque o sinal de entrada estava errado, mas porque havia muita volatilidade. Mesmo tendo um stop-loss decente, há situações em que seu preço pode não estar disponível. Podemos lembrar do episódio com o franco suíço em janeiro de 2015. Nesse caso, sua posição seria fechada pela corretora ao próximo melhor preço disponível, que muitas vezes é pior do que seu stop-loss. Apenas ordens limitadas garantem o preço; ordens stop e stop-loss não oferecem tal garantia.
Assim, as faixas de preços das barras não apenas fornecem uma visão geral do ambiente de mercado, mas também podem ajudar a determinar os níveis de preço de entrada e até de saída. Novamente, dependendo da sua estratégia, se, por exemplo, você mantém uma posição longa em algum símbolo, o grau da faixa prevista da barra de preço (o que você prevê) pode facilmente determinar ou, pelo menos, indicar onde posicionar o nível de entrada e até mesmo o take-profit.
Aqui eu arrisco parecer monótono, mas talvez fosse útil destacar os principais tipos de velas de preço, bem como mostrar seus respectivos intervalos. Os padrões de velas mais conhecidos são retenção bearish, retenção bullish, martelo, lápide, doji de pernas longas e libélula. Claro, na verdade existem mais padrões, mas os mencionados cobrem a maioria das situações que você encontrará no gráfico de preços. Em todos esses casos, como será mostrado abaixo, a faixa da barra de preço simplesmente representa o preço máximo menos o preço mínimo.
Agrupamento hierárquico aglomerativo
O agrupamento hierárquico aglomerativo (Agglomerative Hierarchical Clustering, AHC) é um método para, primeiro, classificar dados dentro de um determinado número de agrupamentos e, em seguida, vincular esses agrupamentos de maneira sistemática e hierárquica por meio do chamado dendrograma. Na verdade, a necessidade de considerar múltiplas variáveis em um único ponto de dados é algo que pode ser desafiador ao realizar comparações. Por exemplo, uma empresa que deseja avaliar seus clientes com base nas informações recebidas deles pode usar esse método, já que a informação inevitavelmente abrangerá diferentes aspectos da vida dos clientes, como compras passadas, idade, gênero, endereço, etc. O AHC quantifica todas essas variáveis para cada cliente e cria agrupamentos a partir dos centroides aparentes de cada ponto de dados. Além disso, esses agrupamentos são reunidos em uma hierarquia com relações sistemáticas. Assim, se a classificação requer, digamos, 5 agrupamentos, então o AHC fornecerá esses 5 agrupamentos em uma forma ordenada, o que significa que você pode inferir quais agrupamentos são mais semelhantes entre si e quais são mais distintos. Essa comparação de agrupamentos, embora secundária, pode ser útil se você precisar cotejar mais de um ponto de dados e saber se eles estão em agrupamentos separados. A classificação dos agrupamentos determinará a distância entre dois pontos usando a quantidade de separação entre seus respectivos agrupamentos.
O AHC é um tipo de aprendizado não supervisionado. Isso significa que el pode ser usado para fazer previsões usando classificadores. No nosso caso, estamos prevendo as faixas das barras de preço. Outro usuário, com os mesmos agrupamentos treinados, pode utilizá-los para prever mudanças nos preços de fechamento ou para outro aspecto relacionado à sua negociação. Isso proporciona maior flexibilidade do que o aprendizado supervisionado, que tem um classificador específico, o que faria com que o modelo fosse usado apenas para prever o aspecto para o qual foi classificado. Isso significa que fazer previsões para outro propósito exigiria o re-treinamento do modelo com um novo conjunto de dados.
Ferramentas e bibliotecas
A plataforma MQL5, por meio de sua IDE, permite o desenvolvimento de robôs investidores, ou EAs, personalizados do zero. Hipoteticamente, poderíamos seguir esse caminho. Mas, essa abordagem exigiria a tomada de várias decisões relativas ao sistema de negociação, que podem variar entre traders que implementam o mesmo conceito. Além disso, esse código pode ser excessivamente personalizado e propenso a erros, sendo muito difícil de modificar para diferentes situações. Por isso, o melhor caminho é integrar nossa ideia com outras classes "padrão" de robôs investidores fornecidos pelo Assistente MQL5. Isso não só reduzirá o nosso trabalho de depuração (mesmo nas classes embutidas do MQL5, às vezes ocorrem erros, mesmo que sejam poucos), mas também, mantendo-o como uma instância de uma das classes padrão, a classe pode ser usada e combinada com uma amplo leque de outras classes no Assistente MQL5 para criar diferentes robôs investidores, garantindo um experimento consistente.
O código da biblioteca MQL5 contém as classes AlgLib, mencionadas em artigos anteriores desta série e que serão novamente utilizadas neste artigo. Em particular, no arquivo DATAANALYSIS.MQH, usaremos a classe CClustering e mais algumas outras classes relacionadas para criar o AHC para nossos dados de séries de preços. Uma vez que estamos interessados principalmente na faixa de preços das barras, nossos dados de treinamento consistirão nessas faixas de períodos anteriores. Ao usar as classes de treinamento de dados do arquivo de análise de dados incluído, esses dados geralmente são colocados em uma matriz XY, onde X representa as variáveis independentes e Y os classificadores ou "rótulos" que o modelo aprende. Ambos são geralmente representados em uma única matriz.
Preparação dos dados para treinamento
No entanto, neste artigo, como estamos aplicando um aprendizado não supervisionado, nossos dados de entrada consistem apenas nas variáveis independentes X, que serão as faixas históricas dos preços das barras. Ao mesmo tempo, gostaríamos de fazer previsões considerando outro fluxo de dados relacionados, a saber, a faixa final dos preços das barras. Isso é equivalente a Y. Para combinar esses dois conjuntos de dados, mantendo a flexibilidade do aprendizado não supervisionado, podemos usar a seguinte estrutura de dados:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class CMoneyAHC : public CExpertMoney { protected: double m_decrease_factor; int m_clusters; // clusters int m_training_points; // training points int m_point_featues; // point featues ... public: CMoneyAHC(void); ~CMoneyAHC(void); virtual bool ValidationSettings(void); //--- virtual double CheckOpenLong(double price,double sl); virtual double CheckOpenShort(double price,double sl); //--- void DecreaseFactor(double decrease_factor) { m_decrease_factor=decrease_factor; } void Clusters(int value) { m_clusters=value; } void TrainingPoints(int value) { m_training_points=value; } void PointFeatures(int value) { m_point_featues=value; } protected: double Optimize(double lots); double GetOutput(); CClusterizerState m_state; CAHCReport m_report; struct Sdata { CMatrixDouble x; CRowDouble y; Sdata(){}; ~Sdata(){}; }; Sdata m_data; CClustering m_clustering; CRowInt m_clustering_index; CRowInt m_clustering_z; };
Assim, as faixas históricas dos preços das barras serão coletadas como um novo lote a cada nova barra. Os robôs investidores criados pelo assistente MQL5 tendem a tomar decisões de negociação a cada nova barra, e para nossos testes isso é suficiente. Na verdade, existem abordagens alternativas, p. ex., coletar um lote grande com vários meses/anos, e então, com base em testes, examinar quão bem os agrupamentos do modelo podem separar as possíveis as barras com baixa volatilidade daquelas com alta volatilidade. Lembre-se também de que estamos usando apenas 3 agrupamentos: um extremo destinado para barras muito voláteis, um para volatilidade muito baixa e outro para volatilidade média. Novamente, pode-se explorar, por exemplo, 5 agrupamentos, mas o princípio para o que queremos seria o mesmo. Vamos ordenar os agrupamentos (de maior para a menor volatilidade) e determinar em qual agrupamento se encontra nosso atual ponto de dados.
Preenchimento com dados
O código para recuperar as últimas faixas de barras a cada nova barra e preencher a estrutura personalizada é o seguinte:
m_data.x.Resize(m_training_points,m_point_featues); m_data.y.Resize(m_training_points-1); m_high.Refresh(-1); m_low.Refresh(-1); for(int i=0;i<m_training_points;i++) { for(int ii=0;ii<m_point_featues;ii++) { m_data.x.Set(i,ii,m_high.GetData(StartIndex()+ii+i)-m_low.GetData(StartIndex()+ii+i)); } }
A quantidade de pontos de treinamento determina quão grande é nosso conjunto de dados de treinamento. Este é um parâmetro de entrada configurável que diz respeito ao ponto de dados. Porém, este ele define a quantidade de "dimensões" que cada ponto de dado possui. Assim, no nosso caso, por padrão, temos 4 dimensões, mas isso simplesmente significa que usamos as últimas 4 faixas dos preços das barras para determinar qualquer ponto de dados. Isso é semelhante a um vetor.
Criação de agrupamentos
Então, uma vez que temos dados na nossa estrutura personalizada, o próximo passo será modelá-los usando o gerador de modelos AHC Alglib. No código, este modelo é chamado de "estado", então nosso modelo é chamado m_state. Este é um processo de duas etapas. Primeiro, precisamos gerar pontos de modelo baseados nos dados de treinamento fornecidos e, em seguida, executar o gerador AHC. A configuração dos pontos pode ser vista como a inicialização do modelo e a garantia de uma definição clara de todos os parâmetros chave. No nosso código, a chamada ocorre da seguinte maneira:
m_clustering.ClusterizerSetPoints(m_state, m_data.x, m_training_points, m_point_featues, 20);
O segundo passo importante é executar o modelo para determinar os agrupamentos de cada um dos pontos de dados fornecidos no conjunto de treinamento. Isso é feito chamando a função ClusterizerRunAHC, conforme indicado abaixo:
m_clustering.ClusterizerRunAHC(m_state, m_report);
Do ponto de vista da Alglib, esta é a base para a criação dos agrupamentos que precisamos. Esta função realiza um breve pré-processamento e, em seguida, chama a função protegida (privada) ClusterizerRunAHCInternal, que realiza todo o trabalho pesado. Tudo o que é necessário pode ser encontrado no arquivo include\math\AlgLib\dataanalysis.mqh, a partir da linha 22463. A geração do dendrograma no array de saída cidx merece atenção especial. Este array combina habilmente uma grande quantidade de informações sobre os agrupamentos em um único array. Um pouco antes disso, será necessário criar uma matriz de distâncias para todos os pontos de dados de treinamento por meio de seus centroides. Este array mapeia os valores da matriz de distância para os índices do agrupamento, com os primeiros valores até o número total de pontos de treinamento representando o agrupamento de cada ponto, e os índices subsequentes representando a fusão desses agrupamentos para formar um dendrograma.
Não menos notável é o tipo de distância utilizado na criação da matriz de distâncias. Há nove opções disponíveis, incluindo: distância de Chebyshev, distância euclidiana, correlação de postos de Spearman. Cada uma dessas alternativas recebe um índice, que configuramos quando chamamos a função mencionada acima com os valores definidos. Como a escolha do tipo de distância deve ser muito sensível à natureza e ao tipo dos agrupamentos criados, ela deve ser considerada cuidadosamente. O uso da distância euclidiana (cujo índice é 2) oferece uma implementação mais flexível ao configurar o AHC, pois, ao contrário de outros tipos de distância, aqui pode ser utilizado o método de Ward.
Obtenção de agrupamentos
A extração de agrupamentos é tão simples quanto a sua criação. Simplesmente chamamos uma função, ClusterizerGetKClusters, e ela extrai dois arrays do relatório de saída da função de geração de agrupamento que chamamos anteriormente (iniciamos o AHC). Os arrays são um array de índices de agrupamentos e arrays de z-agrupamentos, e eles definem não apenas como os agrupamentos são determinados, mas também como um dendrograma pode ser formado a partir deles. A chamada desta função é feita simplesmente, conforme indicado abaixo:
m_clustering.ClusterizerGetKClusters(m_report, m_clusters, m_clustering_index, m_clustering_z);
A estrutura dos agrupamentos obtidos é muito simples, pois, no nosso caso, classificamos nosso conjunto de dados de treinamento com base em apenas 3 agrupamentos. Isso significa que temos no máximo três níveis de fusão dentro do dendrograma. Se usássemos mais agrupamentos, nosso dendrograma certamente seria mais complexo e potencialmente teria níveis de fusão de n-1, onde n é o número de agrupamentos usados pelo modelo.
Anotação dos pontos de dados
Agora veremos a rotulação dos pontos de dados de treinamento para auxiliar na previsão. Não estamos interessados na simples classificação de conjuntos de dados. Em vez disso, queremos usá-los, e, para isso, nossos "rótulos" serão a faixa de preços final após cada ponto de dados de treinamento. Extraímos um novo conjunto de dados para cada nova barra, que incluirá o ponto de dados atual, cuja volatilidade final é desconhecida. É por isso que, ao rotular, pulamos o ponto de dados com índice 0, como mostrado no nosso código abaixo:
for(int i=0;i<m_training_points;i++) { if(i>0)//assign classifier only for data points for which eventual bar range is known { m_data.y.Set(i-1,m_high.GetData(StartIndex()+i-1)-m_low.GetData(StartIndex()+i-1)); } }
É claro que também podem ser usadas outras variantes de rotulação. Por exemplo, em vez de nos concentrarmos na faixa de preços só da próxima barra, poderíamos considerar a faixa, digamos, das próximas 5 ou 10 barras, usando a faixa total dessas barras como o valor de y. Essa abordagem pode levar a valores mais "precisos" e menos errôneos, e o mesmo prognóstico pode ser usado se nossos rótulos forem destinados à direção do preço (mudanças no preço de fechamento), resultando em uma tentativa de prever não apenas uma, mas muito mais barras. De qualquer forma, como pulamos o primeiro índice, já que não tínhamos seu valor final, nós também pularíamos n barras (onde n é o número de barras próximas que queremos projetar). Essa abordagem de longo prazo levaria a um atraso significativo devido ao aumento de n. Por outro lado, grandes atrasos permitem comparar com segurança com o valor previsto, já que o atraso é de apenas uma barra do valor-alvo y.
Previsão de volatilidade
Após completar a "rotulação" do conjunto de dados treinado, podemos determinar a qual agrupamento nosso atual ponto de dados pertence entre os agrupamentos definidos no modelo. Isso é feito simplesmente iterando pelos arrays de saída do relatório de modelagem e comparando o índice do agrupamento do ponto de dados atual com os índices de outros pontos de dados de treinamento. Se eles coincidirem, então pertencem ao mesmo agrupamento. A seguir, temos um código relativamente simples:
if(m_report.m_terminationtype==1) { int _clusters_by_index[]; if(m_clustering_index.ToArray(_clusters_by_index)) { int _output_count=0; for(int i=1;i<m_training_points;i++) { //get mean target bar range of matching cluster if(_clusters_by_index[0]==_clusters_by_index[i]) { _output+=(m_data.y[i-1]); _output_count++; } } // if(_output_count>0){ _output/=_output_count; } } }
Uma vez encontrado um correspondente, prosseguimos simultaneamente para calcular o valor médio de Y de todos os pontos de dados de treinamento nesse agrupamento. Obter o valor médio pode ser considerado um método bastante rudimentar, mas é utilizável. Outros métodos incluem a busca pela mediana ou a moda. Independentemente da opção escolhida, o mesmo princípio de obter o valor Y do nosso ponto de dados atual apenas a partir de outros pontos de dados no seu agrupamento é aplicado.
Uso de dendrogramas
O código-fonte fornecido demonstra como os agrupamentos individuais criados podem ser usados para classificação e elaboração de previsões. Qual é, então, o papel do dendrograma? Por que é importante quantificar a diferença entre cada agrupamento e os demais? Para responder a esta questão, poderíamos considerar a possibilidade de comparar dois pontos de dados de treinamento, em vez de classificar apenas um, como fizemos. Em termos de volatilidade neste cenário, poderíamos obter dados do histórico em um ponto de inflexão chave (como um fractal chave durante flutuações, se você estiver prevendo a direção dos preços, mas lembre que neste artigo estamos considerando a volatilidade). Como teremos agrupamentos de ambos os pontos, a distância entre eles nos dirá quão próximo nosso atual ponto de dados está do último ponto de inflexão.
Exemplos
Foram realizados vários testes com a ajuda de um robô Investidor, compilado pelo Assistente com uma instância da classe de gerenciamento de capital. A classe de sinais foi baseada no oscilador Awesome. O robô Investidor foi executado no EURUSD H4 de 01.10.2022 a 01.10.2023. O relatório é apresentado abaixo:

Como controle, também realizamos testes com as mesmas condições acima, exceto que usamos a opção de margem fixa fornecida pela biblioteca como gerenciamento de capital, o que nos deu o seguinte relatório:

As implicações de nosso breve teste, baseadas nesses dois relatórios, são que existe o potencial de ajustar nosso volume de acordo com a volatilidade predominante do símbolo. Abaixo estão as configurações usadas pelo nosso robô Investidor e elemento de controle.

E

Como você pode ver, foram usadas configurações semelhantes, exceto para nosso robô Investidor, onde tivemos que alterá-las para gerenciamento de capital.
Considerações finais
Exploramos como o agrupamento hierárquico aglomerativo e dendrogramas podem ajudar a identificar/avaliar diferentes conjuntos de dados e como esse agrupamento pode ser usado na elaboração de previsões. Como sempre, os conceitos gerais e o código-fonte são destinados a testar ideias, especialmente em condições em que são combinados com diferentes abordagens. É por isso que usamos o mesmo formato de código que para as classes do Assistente MQL5.
Notas sobre os complementos
O código anexado é para ser compilado usando o Assistente MQL5 - a compilação inclui o arquivo de classe de sinal e o arquivo de classe de trailing. Neste artigo, o arquivo de sinal foi o oscilador Awesome (SignalAO.mqh). Aqui você pode encontrar mais informações sobre o uso do Assistente.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/13630
 Adicionando um LLM personalizado a um robô investidor (Parte 2): Exemplo de implementação de ambiente
Adicionando um LLM personalizado a um robô investidor (Parte 2): Exemplo de implementação de ambiente
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso