
ニューラルネットワークが簡単に(第44回):ダイナミクスを意識したスキルの習得

はじめに
複雑な確率的環境における予測問題を解く場合、訓練セット以外で許容できる結果を示すモデルを訓練することは非常に困難であり、しばしば不可能です。同時に、問題をより小さなサブタスクに分割することで、モデル全体のパフォーマンスが大幅に向上します。これまでの記事によって、すでに階層モデルの構築について知っています。そのアーキテクチャは、問題解決をいくつかのサブタスクに分割することを可能にします。それぞれのサブタスクは、より単純な別のモデルによって解決されます。ここで、特定の状態におけるモデルの挙動によって容易に識別できるスキルの正しい訓練という問題が生じます。
前回の記事では、分離可能なスキルを訓練できるDIAYNメソッドを紹介しました。これにより、現在の状態に応じてエージェントの動作を変更できるモデルを構築することが可能になります。覚えていらっしゃるかもしれませんが、DIAYNアルゴリズムは予測不可能な行動に対して報酬を与えます。これにより、できるだけ多くの異なる行動で技術を教えることができます。しかし、逆の見方もあります。そのようなスキルを予測するのは難しくなります。これはエージェントの計画と管理を複雑にします。
このパラダイムでは、行動が容易に予測できるスキルを習得することに疑問が生じます。同時に、行動の多様性を犠牲にする覚悟もありません。同様の問題は、2020年に発表されたDADS (Dynamics-Aware Discovery of Skills)メソッドの著者らによって解決されています。DIAYNとは異なり、DADSメソッドは、行動に多様性があるだけでなく、予測可能なスキルを教えようとしています。
1.DADSアーキテクチャの概要と基本ステップ
複数の個別の振る舞いとそれに対応する環境の変化を研究することで、モデル予測制御を行動空間ではなく行動空間でのプランニングに用いることができます。この点で、主な問題は、ランダムで予測不可能であることを考慮した上で、どのようにしてそのような振る舞いを得ることができるかということです。DADS (Dynamics-Aware Discovery of Skills)法は、モデルベース制御を容易にするという明確な目標を持った、低レベルのスキルを学習するための教師なし強化学習システムを提案します。
DADSを使用して学習したスキルは、予測可能性のために直接最適化され、予測モデルを学習するためのより良い洞察を提供します。スキルの主な特徴は、自律的な探求を通じて完全に習得されることです。つまり、スキルツールキットとその予測モデルは、タスクと報酬関数が設計される前に学習されます。このように、十分な数があれば、環境を十分に研究し、その中で行動するスキルを身につけることができます。
DIAYN法と同様に、DADSアルゴリズムは2つのモデルを使用します。スキルモデル(エージェント)と識別器(スキルダイナミクスモデル)です。
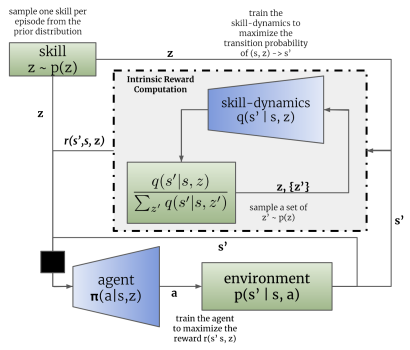
モデルは順次反復的に学習されます。まず、識別器は現在の状態と使用されているスキルに基づいて将来の状態を予測するように訓練されます。そのために、現在の状態とワンホットスキル識別ベクトルがエージェントモデルの入力に供給されます。エージェントは、環境で起こされる行動を生成します。行動の結果、エージェントは環境の新しい状態に移動します。
次に、識別器は同じ初期データに基づいて、環境の新しい状態を予測しようとします。この場合、識別器の働きは、先に述べたオートエンコーダの働きに似ています。しかしこの場合、デコーダは潜在状態から元のデータを復元するのではなく、次の状態を予測します。オートエンコーダを訓練したように、識別器も勾配降下法で訓練します。
ご覧の通り、DIAYNとDADSのアルゴリズムの最初の違いはここにあります。DIAYNでは、新しい状態に基づいて、この状態に至ったスキルを決定しました。DADS識別器は逆の機能を果たします。初期データと既知の技術に基づいて、その後の環境の状態を予測します。
ここで注意しなければならないのは、このプロセスは反復的であるということです。したがって、すぐに最尤推定を達成しようとはしません。同時に、エージェントを訓練するためには、少なくとも最初の近似値が必要になります。
最初の識別器訓練反復の後、エージェント(スキルモデル)の訓練に移ります。すぐに、識別器とエージェントの訓練に異なるパッケージのソースデータが使われるとしましょう。ただし、これは訓練サンプルを別に作成する必要があるということではありません。私たちは経験値再生バッファを共有しています。各反復においてのみ、このバッファからランダムに2つの訓練データを生成します。
DIAYN法と同様に、スキルモデルは、識別器によって生成された報酬に基づいて強化学習法を用いて学習されます。いつものように、違いは細部にあります。DADSは、報酬を生み出すために別の数式を使います。数学的な計算やアプローチの正当性については、ここでは触れません。元の記事でご覧ください。最終的な報酬の方程式だけを考えます。
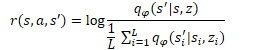
この式において、q(s'|s,z)は、個別の初期状態sおよびスキルzに対する識別器の出力です。Lはスキルの数を決めます。したがって、報酬方程式の分子には、分析されたスキルの予測状態が示されています。分母には、すべての可能なスキルについての平均予測状態が含まれます。
このような報酬関数を使うことで、上記の問題を解決することができます。分子には現在のスキルに対する予測状態を使うので、予測状態の達成につながるエージェントの行動に報酬を与えます。これにより、スキル動作の予測可能性が実現します。
同時に、分母にすべての可能なスキルの平均状態を使うことで、統計的平均とできるだけ異なるスキルの振る舞いに、より多くの報酬を与えることができます。
このように、DADS方式は予測可能性とスキルの多様性のバランスを実現しています。これにより、環境を探索する能力を維持しながら、構造化された予測可能な行動をするスキルを教えることができます。
識別器からのフィードバックとスキルモデルの訓練がエージェントの行動を変化させることに留意してください。その結果、経験再現バッファに蓄積された例とは異なる振る舞いをすることになります。そのため、最適な結果を得るために、識別器とエージェントを逐次的に訓練する反復プロセスを使用します。その過程で、モデルの訓練は何度か繰り返されます。さらに、この方法の著者らは、現在のエージェント 方策を使用して行動を実行する確率と、経験値再生バッファ内でこの行動を起こす確率の比によって決定される重要度係数を使用することを提案しています。これにより、エージェントの確立された行動により多くの注意を払うことができます。同時に、ランダムな行動の影響は平準化されます。
DADS方式はもともと、技能訓練や環境モデルの作成のために提案されたものであることに留意すべきです。このように、予測可能なスキルと、十分な確率で環境の新しい状態を予測できるダイナミクスモデルを訓練することで、数歩先の計画を立てることができます。同時に、計画を立てるプロセスでは、具体的な行動から、より一般的なスキルの概念に基づいた活動へと移行することができます。具体的な行動は、予定されたスキルに従ってエージェントが決定します。
しかし、この段階では長期的な計画には進まず、前回の記事と同じように、個々のステップのスキルを決定するスケジューラの訓練に落ち着きました。
2.MQL5を使用した実装
アルゴリズムの実用的な実装に移りましょう。直接アルゴリズムの実装に移る前に、モデルのアーキテクチャを決めます。
DIAYNと同様に、実装では3つのモデルを使用します。エージェント(スキルモデル)、識別器(ダイナミックモデル)、スケジューラです。
このアルゴリズムは、エージェントが現在の状態と選択されたスキルに基づいて起こす行動を決定します。したがって、ソースデータ層のサイズは、現在の状態を記述するベクトルと、選択されたスキルを識別するワンホットベクトルを設定するのに十分でなければなりません。
エージェントの出力では、可能な行動の空間の確率分布のベクトルを受け取ります。ご覧のように、エージェントの初期データ、機能、結果は、DIAYNメソッドのエージェントの対応する特性と完全に類似しています。この実装では、エージェントのアーキテクチャは変更しません。これによって、2つの技能訓練法の効果を実際に比較することができます。しかし、これは別のモデルアーキテクチャが使えないことを意味するものではありません。
エージェントアーキテクチャでは、ソースデータを比較可能な形式にするためにバッチ正規化層を使用していたことを思い出してください。
//--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * BarDescr + AccountDescr + NSkills); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
正規化されたデータは、2つの畳み込み層とサブサンプリング層からなるブロックによって処理され、ソースデータの個々のパターンと傾向を識別することが可能になります。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
畳み込み層の後に処理されたデータは、完全連結層と完全にパラメータ化された量子化FQFモデルを含む決定ブロックに渡されます。
決定ブロックの出力としてFQFを使用することで、行動を起こした後の報酬について、その平均値だけでなく、環境の確率性を考慮した確率分布も考慮した、より正確な予測を得ることができます。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
前述したように、今回は数歩先の予測を立てるための環境モデルは作っていません。前回同様、各ステップで使用するスキルを定義します。そのため、スケジューラを訓練するためのアーキテクチャやアプローチも変更しませんでした。ここでは、バッチ正規化層を使用して、生データを比較可能な形式にします。意思決定ブロックは、完全連結層とFQFモデルで構成されます。その結果は、SoftMax層を使って確率分布の領域に移されます。
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NSkills; descr.window_out = 32; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
ただし、識別器モデルのアーキテクチャに変更を加えました。DADSアルゴリズムが識別器としてDynamicモデルを使用していることを思い出してください。検討中のアルゴリズムによれば、現在の状態と選択されたスキルに基づいて、環境の新しい状態を予測する必要があります。また、DADS法のダイナミクスモデルは、数ステップ先の計画を立てる際に将来の状態を予測するために使われます。しかし、前述の通り、長期的な計画は立てありません。つまり、将来の環境状態のすべての指標を予測することから、わずかに外れる可能性があるということです。ご存知のように、環境状態は2つの大きなブロックで構成されています。
- 価格の動きと分析された指標の履歴データ
- 現在の口座のステータスの状況を示す指標
個人トレーダーが金融市場の状態に与える影響は、無視できるほど些細なものです。したがって、エージェントの行動は、履歴データに影響を与えません。つまり、エージェントを訓練する際に、内部報酬の形成から除外することができます。遠大な計画を立てることはないので、これらの指標を予測することは意味がありません。したがって、内部報酬を形成するためには、口座の将来の状態を示す指標を予測すれば十分なのです。
もう一点、注意すべきことがあります。エージェントの内部報酬を形成する方程式を見てみましょう。分析したスキルの予測状態に加え、可能性のあるすべてのスキルの平均予測状態も使用します。つまり、ある報酬を決定するためには、すべてのスキルについて将来の状態を予測しなければなりません。モデルの訓練プロセスをスピードアップするため、マルチヘッドモデルの出力を作成することにしました。このモデルは、1つの初期データに基づいて、可能性のあるすべてのスキルの予測状態を返します。
したがって、Discriminatorモデルのソースデータ層は、Schedulerモデルの同様の層と同等であり、選択されたスキルを考慮することなく、システムの状態の説明を記録するのに十分でなければなりません。
//--- Discriminator discriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; }
受信した初期データはバッチ正規化層で一次処理され、完全連結パーセプトロンで構成される意思決定ブロックに転送されます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!discriminator.Add(descr)) { delete descr; return false; }
モデルの出力にも完全連結層が使われています。そのサイズは、教えられるスキルの数と、システムの1つの状態を記述する要素の数の積に等しくなります。この場合、口座状況説明の要素数を示します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills*AccountDescr; descr.optimization = ADAM; descr.activation = None; if(!discriminator.Add(descr)) { delete descr; return false; }
前回の記事では、口座の状態を説明するために指標の相対値を使用することを決めたが、それにもかかわらず、これらの値は正規化されていないようであることは注目に値します。それらを予測する際に、1つも活性化関数を使うことはできません。したがって、識別器モデルの出力は、活性化関数のないニューラル層を使用します。
すべての使用モデルのアーキテクチャを記述するための完全なコードは、ライブラリファイル Trajectory.mqhにあるCreateDescriptions関数にまとめられています。この機能をEAファイルからライブラリファイルに転送することで、訓練のすべての段階で1つのモデルアーキテクチャを使用することができるので、EA間でモデルアーキテクチャの記述を手動でコピーする必要がなくなります。
モデルを訓練し、得られた結果をテストする間、DIAYN法によるモデルの訓練と同様に3つのEAを使用します。訓練モデル用の主要データ収集EA 「Research.mq5」は、ほとんど変更することなく完全に移行されました。この変更が影響したのは、モデルを記録するためのファイル名と、前述したアーキテクチャーソリューションにのみです。EAの全コードは添付ファイルにあります。
DADSアルゴリズムの実装のための主な変更は、モデル訓練EA「Study.mq5」に加えられました。まず第一に、これはモデルアーキテクチャが事前に宣言された定数に適合しているかを監視するもので、OnInitメソッドで実行されます。ここでは、変更されたモデルアーキテクチャに合わせてコントロールを調整しました。
Discriminator.getResults(DiscriminatorResult); if(DiscriminatorResult.Size() != NSkills * AccountDescr) { PrintFormat("The scope of the discriminator does not match the skills count (%d <> %d)", NSkills * AccountDescr, Result.Total()); return INIT_FAILED; } Scheduler.getResults(SchedulerResult); Scheduler.SetUpdateTarget(MathMax(Iterations / 100, 500000 / SchedulerBatch)); if(SchedulerResult.Size() != NSkills) { PrintFormat("The scope of the scheduler does not match the skills count (%d <> %d)", NSkills, Result.Total()); return INIT_FAILED; } Actor.getResults(ActorResult); Actor.SetUpdateTarget(MathMax(Iterations / 100, 500000 / AgentBatch * NSkills)); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
Trainモデルの訓練方法に大きな変更が加えられました。まず、2つの新しい補助メソッドを見てみましょう。最初のメソッドはGetNewStateです。この方法の本体では、口座の以前の状態、計画された行動、および既知の「将来の」値動きに基づいて、計算されたバランス指標の状態を形成します。
このメソッドは、予測ではなく、計算されたバランス状態を定義することに留意してください。この言葉遊びには多くの意味が隠されています。バランスパラメータの予測値は、Dynamicsモデル(Discriminator)によって得られます。現在のメソッドでは、経験値再生バッファからのその後の価格変動の知識に基づいて、計算された残高の状態を定義します。このような計算が必要なのは、クリップボードから得たエージェントの行動と、使用されたスキルや更新された行動戦略を考慮してエージェントが生成した行動との間に食い違いが生じる可能性が高いからです。経験値再生バッファのデータにより、ストラテジーテスターで行動を繰り返すことなく、どのエージェント行動に対しても正確に口座ステータスとポジションを計算することができます。これにより、訓練セットを大幅に拡大し、モデル訓練の質を向上させることができます。同様の機能は前回の記事ですでに実装されています。別メソッドを用意するのは、モデルの訓練の過程でこの機能を何度も呼び出すためです。
このメソッドは、パラメータで、意思決定段階での口座説明パラメータの動的配列、行動ID、およびロングポジションの1ロットあたりのその後の値動きからの利益/損失の値を受け取ります。操作の結果として、指定された行動を考慮して、アカウントのその後の状態を記述する値のベクトルを返します。
メソッド本体では、結果を記録するためのベクトルを作成し、口座の初期状態という形で初期値をそこに移します。
vector<float> GetNewState(float &prev_account[], int action, double prof_1l) { vector<float> result; //--- result.Assign(prev_account);
次に、実行される行動に応じて分岐がおこなわれます。ポジションを建てる、または追加するという取引操作がおこなわれた場合、対応する方向のポジションの新しい値を計算します。次に、ポジションのサイズとその後の値動きを考慮して、各方向の累積損益の変化を計算します。口座の累積損益の値は、上記で計算された2つの指標の合計に等しくなります。その結果と残高指標を足すことで、口座資本が得られます。
switch(action) { case 0: result[5] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break; case 1: result[6] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break;
すべての未決済ポジションが決済された場合は、単純に現在の残高に累積利益の値を加算します。その結果得られた値を資本と余剰証拠金にコピーします。残りのパラメータをゼロにリセットします。
case 2: result[0] += result[4]; result[1] = result[0]; result[2] = result[0]; for(int i = 3; i < AccountDescr; i++) result[i] = 0; break;
待機中(エージェントの行動なし)のパラメータの再計算は、ポジションの数量の変化を除いて、ポジションを開く取引操作に似ています。つまり、過去に建てたポジションの累積損益と資本のみを再計算します。
case 3: result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break; } //--- return result return result; }
すべてのパラメータを再計算した後、結果の値のベクトルを呼び出し元のプログラムに返します。
2つ目のメソッドは、識別器の予測値、選択されたスキル、および前回の口座状態に基づいて、エージェントへの内部報酬額を計算するために使用されます。
エージェントは特定の行動に対して報酬を受け取ることに注意してください。しかし、メソッドのパラメータにはエージェントが選択した行動を示しません。実際、ここでエージェントの予想と受け取った報酬の間にあるギャップがあることに気づきます。結局のところ、エージェントが選択した行動が、識別器によって予測された状態につながらない可能性があります。もちろん、エージェントと識別器を訓練する過程で、そのようなずれが生じる確率は減少しますが、可能性は残るでしょう。同時に、報酬が予測された状態につながる行動に対応することも重要です。そうでなければ、スキルの予測された動作は得られません。そのため、2つの状態(現在の状態と、選択されたスキルの予測状態)から、報われる行動を決定します。
GetAgentReward関数は、選択されたスキル、識別器のフォワードパスの結果のベクトル、および以前のバランス状態を記述する配列をパラメータとして受け取ります。関数操作の結果、エージェント報酬のベクトルを得る予定です。
メソッド本体で準備作業をしなければなりません。識別器のフォワードパス結果ベクトルには、すべての可能なスキルに対する予測状態が含まれます。報酬を決定するためには、個々のスキルを分離し、個々のパラメータに照らし合わせて平均値を計算しなければなりません。行列オペレーションは、この作業を助けてくれます。まず、判別結果のベクトルを行列に再フォーマットします。
1行の新しい行列を作成し、列の数は識別器の結果ベクトルの要素数に等しくなります。ベクトルから行列に値をコピーしてみましょう。次に、行列を長方形に再フォーマットします。行の数はスキルの数に対応し、列の数は1つの状態を表すベクトルのサイズに等しくなります。この場合、ResizeメソッドではなくReshapeメソッドを使用することが非常に重要です。Resizeは既存の値を新しい形式の行列に再配布するためです。Reshapeは、既存の要素を再分配することなく、行と列の数を変更するだけです。この場合、単純に最初のスキル以外のすべてのデータを失うことになります。追加された行はランダムな値で満たされます。
vector<float> GetAgentReward(int skill, vector<float> &discriminator, float &prev_account[]) { //--- prepare matrix<float> discriminator_matrix; discriminator_matrix.Init(1, discriminator.Size()); discriminator_matrix.Row(discriminator,0); discriminator_matrix.Reshape(NSkills, AccountDescr); vector<float> forecast = discriminator_matrix.Row(skill);
あとは、対応する行の値を抽出するだけで、関心のあるスキルの予測状態ベクトルを取り出すことができます。
次に、エージェントが報酬を受け取る行動を決定する必要があります。取引操作の主なパラメータはポジションの変化です。ここに多くの慣例があることは認めます。しかし、それらを使うことで、合理的な確率で予測状態に近づけることができるオペレーションを特定することができます。これが、モデルを管理しやすく、予測しやすいものにしています。
まず、各方向の位置の変化を決定します。ポジションのサイズが両方向で減少している場合、ポジションを決済する行動が最も可能性が高いと考えられます。そうでない場合は、ポジションの変化が大きい方を優先します。この方向で新たな取引が開始されたか、あるいは追加されたと考えます。
変化が同じなら、ただ待つだけです。浮動小数点値を使った確率論によれば、この結果は最も可能性が低くなります。このように、積極的な行動を起こすようモデルを刺激したいのです。
//--- check action int action = 3; float buy = forecast[5] - prev_account[5]; float sell = forecast[6] - prev_account[6]; if(buy < 0 && sell < 0) action = 2; else if(buy > sell) action = 0; else if(buy < sell) action = 1;
報酬行動を定義し、計算のためのデータを準備したので、報酬ベクトルの記入に直接進むことができます。
まず、行動空間の次元に沿ってゼロ値のベクトルを形成します。次に、関心のあるスキルの予測値のベクトルを、全スキルの平均予測値のベクトルで割ります。得られたベクトルから平均値を取ます。これらの操作をおこなった結果、負の値が得られる可能性を想定しています。したがって、その絶対値の対数をとります。これは、主要なタスクとまったく矛盾しません。なぜなら、平均値のベクトルから可能な限り離れた、最も非標準的な行動に対する報酬を最大化したいからです。別の解決策として、ゼロによる除算をなくすためにも、分析されたスキルのベクトルと平均値のベクトルとの間のユークリッド距離を使うことを提案できます。実際にアプローチの質をテストしてみましょう。
//--- calculate reward vector<float> result = vector<float>::Zeros(NActions); float mean = (forecast / discriminator_matrix.Mean(0)).Mean(); result[action] = MathLog(MathAbs(mean)); //--- return result return result; }
結果の報酬値を、先に定義した行動に対応するベクトル要素に設定します。関数操作の最後に、結果の報酬ベクトルを呼び出し元のプログラムに返します。
準備作業が完了したら、Trainモデルの訓練に移ります。ここではまず、いくつかのローカル変数を宣言し、以前に読み込まれた訓練セットの軌道の数を決定します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); vector<float> account, reward; int bar, action; int skill, shift;
次に、モデル訓練プロセスのサイクルシステムをアレンジします。最初に断っておきますが、DADSのアルゴリズムによれば、モデルの訓練は順次反復的におこなわれます。まず識別器を訓練します(フェーズ0)。次にエージェントを訓練します(フェーズ1)。そして最後がスケジューラ(フェーズ2)です。このプロセスを何度か繰り返します。反復回数はEAの外部パラメータで設定します。さらに、EAの外部パラメータに、各フェーズの訓練パッケージのサイズを示します。
ここで、関数本体で入れ子ループのシステムを宣言します。外部ループは、訓練プロセスの反復回数を決定します。ネストされたループが訓練段階を決定します。
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { for(int phase = 0; phase < 3; phase++) {
ネストされたループは、一連の操作に置き換えることができます。しかし、このアプローチによって、モデルを直接渡す前に再生バッファから初期状態を読み込むといった、一般的な操作のコピーを排除することが可能になりました。
各訓練フェーズの操作は、訓練パッケージのサイズ内で繰り返され、各フェーズごとにEAの外部パラメータで指定されます。そのため、まず対応する訓練パッケージのサイズを決定します。次に、必要な繰り返し回数のネストされたループをもうひとつ作ります。
int batch = 0; switch(phase) { case 0: batch = DiscriminatorBatch; break; case 1: batch = AgentBatch; break; case 2: batch = SchedulerBatch; break; default: PrintFormat("Incorrect phase %d"); batch = 0; break; } for(int batch_iter = 0; batch_iter < batch; batch_iter++) {
次に、モデルを直接訓練するプロセスが始まります。まず、初期データを準備する必要があります。経験値再生バッファからランダムに選択します。ここでは、パスとそのパスから状態をランダムに選択します。
int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
次に、システムの現在の状態を表すデータをデータバッファに読み込みます。
State.AssignArray(Buffer[tr].States[i].state);
次に、口座データを相対単位に変換し、バッファを追加します。
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i].account[1] / PrevBalance); State.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i].account[2] / PrevBalance); State.Add(Buffer[tr].States[i].account[4] / PrevBalance); State.Add(Buffer[tr].States[i].account[5]); State.Add(Buffer[tr].States[i].account[6]); State.Add(Buffer[tr].States[i].account[7] / PrevBalance); State.Add(Buffer[tr].States[i].account[8] / PrevBalance);
この段階で、モデルのダイレクトパスをおこなうことができます。ただし、現在の訓練フェーズによって業務の流れを分岐させる前に、各業務フェーズで必要となるデータも準備して、口座の将来の推定状態を算出します。
bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
すべての一般的な作業が終了した後、現在の訓練の段階によって作業の流れを分けることに進みます。
上述したように、学習プロセスは識別器モデルの訓練から始まります。まず、事前に用意したソースデータを基にモデルのダイレクトパスを実行し、操作の正しさを確認します。
switch(phase) { case 0: if(!Discriminator.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
識別器の出力には、研究対象であるすべてのスキルの予測状態のベクトルを受け取ります。したがって、目標値を準備するために、すべてのスキルの目標状態も生成しなければなりません。そのために、学習する技能の数に応じてサイクルをアレンジします。次に、サイクルの本体にある個々のスキルに対して、エージェントのダイレクトパスを実行します。
for(skill = 0; skill < NSkills; skill++) { SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; StateSkill.AssignArray(GetPointer(State)); StateSkill.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
フォワードパスの結果に基づいて、エージェントの行動をサンプリングします。特に行動サンプリングに焦点を当てたいと思います。これはエージェントの行動を可能な限り多様化させ、環境の総合的な研究に貢献することになるからです。
システムの初期状態、サンプリングされた行動、再生バッファから知られるその後の値動きの経験に基づき、口座の次の状態を計算し、ターゲット識別器の値の適切なブロックを埋めます。そして次のスキルの処理に移ります。
action = Actor.getSample(); account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); shift = skill * AccountDescr; DiscriminatorResult[shift] = (account[0] - PrevBalance) / PrevBalance; DiscriminatorResult[shift + 1] = account[1] / PrevBalance; DiscriminatorResult[shift + 2] = (account[1] - PrevEquity) / PrevEquity; DiscriminatorResult[shift + 3] = account[2] / PrevBalance; DiscriminatorResult[shift + 4] = account[4] / PrevBalance; DiscriminatorResult[shift + 5] = account[5]; DiscriminatorResult[shift + 6] = account[6]; DiscriminatorResult[shift + 7] = account[7] / PrevBalance; DiscriminatorResult[shift + 8] = account[8] / PrevBalance; }
ターゲットデータを準備した後、識別器のバックワードパスを実行します。
if(!Result) { Result = new CBufferFloat(); if(!Result) { PrintFormat("Error of create buffer %d", GetLastError()); ExpertRemove(); break; } } Result.AssignArray(DiscriminatorResult); if(!Discriminator.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } break;
次のブロックでは、訓練プロセスの次の段階であるエージェント訓練の反復について見ていきます。訓練の段階によって流れを分ける前に、初期データを用意したことを思い出してください。つまり、すでにソースデータのバッファが生成されているということです。したがって、識別器のフォワードパスを実行し、内部報酬を形成するために必要な演算結果を抽出します。
case 1: if(!Discriminator.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Discriminator.getResults(DiscriminatorResult);
次に、訓練の前の段階と同様に、現在の状態に対するすべてのスキルを順次列挙する循環的なプロセスを編成します。
for(skill = 0; skill < NSkills; skill++) { SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; StateSkill.AssignArray(GetPointer(State)); StateSkill.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
ループ本体では、エージェントの順方向通過、報酬ベクトルの形成、モデルの逆方向通過の操作を整理します。
reward = GetAgentReward(skill, DiscriminatorResult, Buffer[tr].States[i].account); Result.AssignArray(reward); StateSkill.AssignArray(Buffer[tr].States[i + 1].state); account = GetNewState(Buffer[tr].States[i].account, Actor.getAction(), prof_1l); shift = skill * AccountDescr; StateSkill.Add((account[0] - PrevBalance) / PrevBalance); StateSkill.Add(account[1] / PrevBalance); StateSkill.Add((account[1] - PrevEquity) / PrevEquity); StateSkill.Add(account[2] / PrevBalance); StateSkill.Add(account[4] / PrevBalance); StateSkill.Add(account[5]); StateSkill.Add(account[6]); StateSkill.Add(account[7] / PrevBalance); StateSkill.Add(account[8] / PrevBalance); if(!Actor.backProp(Result, DiscountFactor, GetPointer(StateSkill), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } } break;
おわかりのように、スキルの完全な列挙は、ランダムなステートを使用するという、以前使われていた一般的なパラダイムと若干矛盾しています。軌道と初期状態を決定するという点では、サンプリングに忠実であり続けます。個々の状態のスキルを完全に列挙することで、モデルの注意をスキル識別指標に集中させたいと思います。結局のところ、スキルの変化こそが、モデルが行動戦略を変更するシグナルとなるべきなのです。
DADSアルゴリズムの実装の次の段階は、スケジューラの訓練です。このプロセスは、DIAYNメソッドの実装における同様の機能をほぼ完全に繰り返します。まず、スケジューラのダイレクトパスを実行し、スキルの確率的分布を得ます。ただし、前回の実装とは異なり、サンプリングも貪欲なスキル選択もおこないません。現実の状況において、ある戦略か別の戦略かを分ける明確な境界線がないことは理解しています。この境界線は非常に曖昧です。すべての部門は、さまざまな許容範囲と妥協で満たされています。このような条件下では、意思決定のために完全な確率分布をエージェントに転送する決定が生じます。
case 2: if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Scheduler.getResults(SchedulerResult);
エージェントの訓練中に、明確に定義されたスキルIDが伝えられたことに注目してください。さらなる意思決定のために、完全な確率分布をエージェントに転送する実験がさらに面白くなります。結局のところ、このような初期データは訓練セットの域を出ないため、モデルの挙動が予測不可能になります。
State.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } action = Actor.getAction();
フォワードパスの結果に基づいて、貪欲にエージェントの行動を選択します。結局のところ、ここでの目標はプランナーを訓練し、スキルレベルで意思決定方針を管理できるようにすることなのです。これは、意味のある一貫した戦略によって行動が決定される予測可能なスキルを使っている場合にのみ可能です。
次に、口座記述指標の推定されたその後の状態を決定し、それに基づいて、モデル報酬ベクトルを形成します。ご記憶かもしれませんが、私たちは口座残高の相対的変化をモデルの外部報酬として使っています。
account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); SchedulerResult = SchedulerResult * (account[0] / PrevBalance - 1.0); Result.AssignArray(SchedulerResult); State.AssignArray(Buffer[tr].States[i + 1].state); State.Add((account[0] - PrevBalance) / PrevBalance); State.Add(account[1] / PrevBalance); State.Add((account[1] - PrevEquity) / PrevEquity); State.Add(account[2] / PrevBalance); State.Add(account[4] / PrevBalance); State.Add(account[5]); State.Add(account[6]); State.Add(account[7] / PrevBalance); State.Add(account[8] / PrevBalance); if(!Scheduler.backProp(Result, DiscountFactor, GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } break;
モデル報酬ベクトルとそれに続くシステム状態を準備した後、スケジューラモデルをバックワードパスします。
default: PrintFormat("Wrong phase %d", phase); break; } } } if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Discriminator", iter * 100.0 / (double)(Iterations), Discriminator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
モデル学習サイクルシステムの本体での操作の最後には、モデル学習の進捗状況を知らせるメッセージを表示します。
残りのEAメソッドと関数、および学習済みモデルをテストするためのEAは、変更されることなく移管されました。この記事で使用されているすべてのプログラムの完全なコードは、添付ファイルのMQL5ExpertsDADSディレクトリにあります。
3.検証
モデルはEURUSD H1の2023年の最初の4ヶ月間の履歴データで訓練されました。指標はデフォルトのパラメータで使用しました。ご覧の通り、テストパラメータは前回の記事から変更されていません。これにより、2つのスキル訓練メソッドの結果を比較することができます。
学習済みモデルのパフォーマンスを確認するため、ストラテジーテスターで2023年5月の期間についてテストがおこなわれました。言い換えれば、訓練されたモデルのテストは、訓練サンプルの25%の時間間隔で訓練サンプルの外で実施されました。
このモデルでは、プロフィットファクター1.75、リカバリーファクター0.85という利益を生み出す能力を実証しました。利益を上げた取引の割合は52.64%でした。同時に、利益が出た取引の平均収入は、負けた取引の平均収入(2.99対-1.90)を57.37%上回っています。



また、スキルの使い方がほぼ一様であることにも注目したいと思います。すべてのスキルがテストに参加しました。
訓練されたモデルをテストする間、エージェントは貪欲に選択された1つのスキルだけでなく、スケジューラによって生成された完全な確率分布を与えられました。さらに、各エージェントの行動は、予測される報酬の最大値によって貪欲戦略を用いて選択されました。このアプローチにより、スケジューラはモデルの動作を最大限に制御することができ、サンプリング中に起こりうるエージェントの動作の確率性を排除することができます。覚えているかもしれませんが、これがスケジューラモデルの訓練方法です。
注目すべきは、貪欲なスキル選択による実験でも同様の結果が得られたことです。貪欲にスキルを選択することで、プロフィットファクターを1.80まで高めることができました。黒字取引のシェアは0.91%増の53.55%でした。また、平均利益率は3.08まで上昇しました。

結論
本稿では、教師なしスキル訓練のもう1つの方法であるDADS (Dynamics-Aware Discovery of Skills)を紹介しました。この方法を使うことで、環境を効果的に探索できるさまざまなスキルを訓練することができます。同時に、提案された方法で訓練されたスキルは、かなり予測可能な動作をします。これにより、スケジューラの訓練が容易になり、一般的に訓練されたモデルの安定性が増します。
また、MQL5を用いて検討したアルゴリズムを実装し、構築したモデルをテストしました。このテストでは、訓練セット以上の利益を生み出すモデルの能力を実証する、心強い結果が得られました。
ただし、この記事で紹介使用されているすべてのプログラムは、あくまでもアプローチの動作を示すためのものであり、実際の取引に使用できるものではありません。
参考文献リスト
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mql5 | EA | モデル訓練EA |
| 3 | Test.mq5 | EA | モデルテストEA |
| 4 | Trajectory.mqh | クラスライブラリ | システム状態記述構造 |
| 5 | FQF.mqh | クラスライブラリ | 完全にパラメータ化されたモデルの作業を整理するためのクラスライブラリ |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/12750
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索