データサイエンスと機械学習—ニューラルネットワーク(第02回):フィードフォワードNNアーキテクチャの設計

「私は、ニューラルネットワークが簡単だと言っているわけではありません。機能させるには、専門家である必要があります。しかし、その専門知識は、幅広いアプリケーションにわたって役に立ちます。ある意味では、以前は機能の設計に費やされていたすべての労力が、アーキテクチャの設計、損失関数の設計、および最適化スキームの設計に費やされます。手作業は、より高いレベルの抽象化に引き上げられました。」
--Stefano Soatto
はじめに
前回の記事では、ニューラルネットワークの基本について説明し、非常に基本的で静的なMLPを構築しましたが、実際のアプリケーションでは、出力のために単純な2つの入力とネットワーク内の2つの隠れ層ノードを必要としないことを知っています。これが前回作成したものです。
場合によっては、問題に最適なネットワークは、入力層に10個のノード、隠れ層に13個のノード/ニューロン、出力層に4個程度のノードを持つネットワークである可能性があります。言うまでもなく、ネットワーク全体の隠れ層の数を調整する必要があります。
私が言いたいのは、何か動的なものが必要だということです。プログラムを壊すことなくパラメータを変更して最適化できる動的コードです。python-kerasライブラリを使用してニューラルネットワークを構築する場合、複雑なアーキテクチャであっても構成とコンパイルの作業を少なくする必要があります。これは、MQL5で達成できるようにしたいことです。
本連載の必読の1つである線形回帰第03回でおこなったのと同じように、モデルの行列/ベクトル形式を導入して、無制限の入力数を持つ柔軟なモデルを作成できるようにしました。
行列が救いの手をさしのべます。
ハードコーディングされたモデルは、新しいパラメータに合わせて最適化しようとすると失敗し、手順全体に時間がかかって面倒なことは誰もが知っています. (それだけの価値はありません)。

ニューラルネットワークの背後にある操作を詳しく見てみると、各入力に割り当てられた重みが乗算され、出力がバイアスに追加されることがわかります。これは行列演算でうまく処理できます。

基本的に、入力と重み行列の内積を求め、最終的にそれをバイアスに追加します。
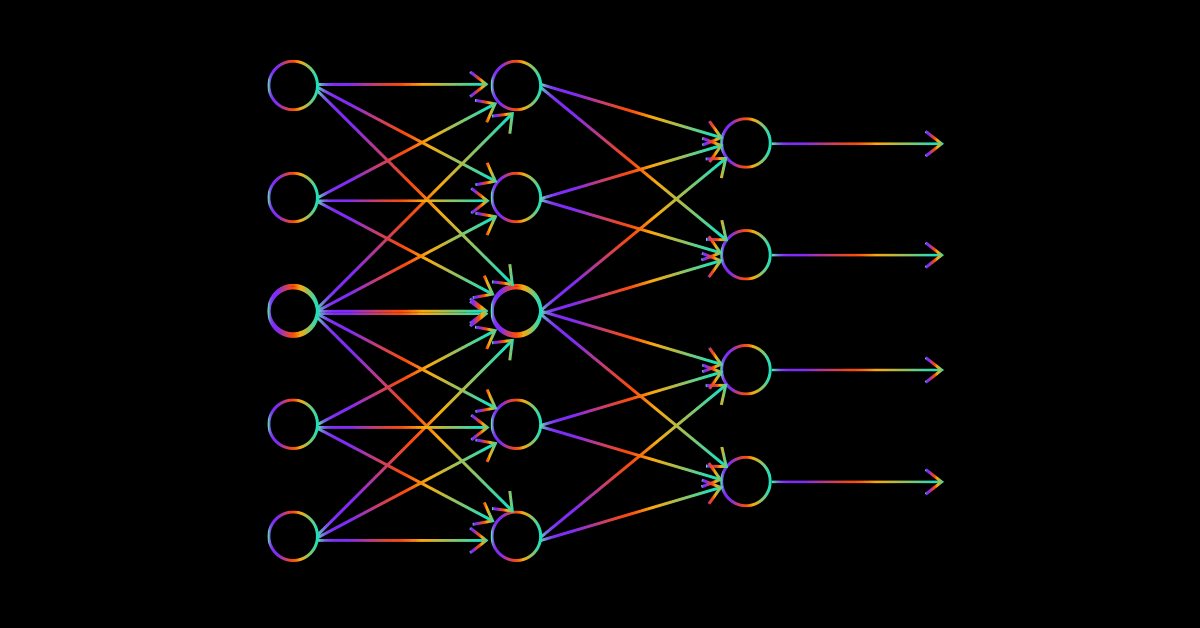
柔軟なニューラルネットワークを構築するために、入力層に2ノード、最初の隠れ層に4ノード、2番目の隠れ層に6ノード、3番目の隠れ層に1ノード、最終的に出力層に1ノードという奇妙なアーキテクチャを試してみます。

これは、行列ロジックがすべてのシナリオでスムーズに動作するかどうかをテストするためのものです。
- 前の(入力)層のノード数が次の層(出力層)より少ない場合
- 前の(入力)層のノード数が次の層より多い場合
- 入力層と次の層(出力)層のノード数が等しい場合
行列演算をコーディングして値を計算する前に、演算全体を可能にする基本的な作業をおこないましょう。
ランダムな重みとバイアス値を生成します。
//Generate random bias for(int i=0; i<m_hiddenLayers; i++) bias[i] = MathRandom(0,1); //generate weights int sum_weights=0, L_inputs=inputs; double L_weights[]; for (int i=0; i<m_hiddenLayers; i++) { sum_weights += L_inputs * m_hiddenLayerNodes[i]; ArrayResize(Weights,sum_weights); L_inputs = m_hiddenLayerNodes[i]; } for (int j=0; j<sum_weights; j++) Weights[j] = MathRandom(0,1);
この操作は前の部分で見ましたが、注目すべきことの1つは、これらの重みとバイアスの値はエポックのサイクルで使用されるために一度生成されることになっているということです。
エポックについて
エポックは、ニューラルネットワーク内のすべてのデータの完全なパスです。フィードフォワードでは、すべての入力の完全なフォワードパスです。バックプロパゲーションでは、フォワードパスとバックワードパス全体です。簡単に言えば、ニューラルネットワークがすべてのデータを確認したときです。
前回の記事で見たMLPとは異なり、今回はkerasを使用している人にはおなじみの、出力層の活性化関数を考慮した実装を使用しています。基本的に、隠れ層に異なる活性化関数を持ち、出力層に出力につながる活性化関数を持つことができます。
CNeuralNets(fx HActivationFx,fx OActivationFx,int &NodesHL[],int outputs=NULL, bool SoftMax=false);
入力HActivationFxは隠れ層の活性化関数、OActivationFxは出力層の活性化関数、NodesHL[]は隠れ層のノード数です。その配列に3つの要素があるとします。これは、3つの隠れ層があり、それらの層のノードの数が配列内に存在する要素によって決定されることを意味します。以下のコードを参照してください。
int hlnodes[3] = {4,6,1}; int outputs = 1; neuralnet = new CNeuralNets(SIGMOID,RELU,hlnodes,outputs);
これは、上で見た画像のアーキテクチャです。outputs引数はオプションです。NULLのままにしておくと、次の構成が出力層に適用されます。
if (m_outputLayers == NULL) { if (A_fx == RELU) m_outputLayers = 1; else m_outputLayers = ArraySize(MLPInputs); }
隠れ層の活性化関数としてRELUを選択した場合、出力層には1つのノードが含まれます。それ以外の場合、最終層の出力の数は最初の層の入力の数と等しくなります。隠れ層でRELU以外の活性化関数を使用している場合は、分類ニューラルネットワークを使用している可能性が高いため、デフォルトの出力層は列の数と等しくなります。これは信頼できませんが、分類の問題を解決しようとしている場合、出力はデータセットからの目標の特徴の数でなければなりません。今後の更新でこれを変更する方法を見つける予定です。現時点では、出力ニューロン数を手動で選択する必要があります。
次に、完全なMLP関数を呼び出して出力を確認してから、操作を可能にするために何がおこなわれたかを説明します。
LI 0 10:10:29.995 NNTestScript (#NQ100,H1) CNeural Nets Initialized activation = SIGMOID UseSoftMax = No IF 0 10:10:29.995 NNTestScript (#NQ100,H1) biases EI 0 10:10:29.995 NNTestScript (#NQ100,H1) 0.6283 0.2029 0.1004 IQ 0 10:10:29.995 NNTestScript (#NQ100,H1) Hidden Layer 1 | Nodes 4 | Bias 0.6283 NS 0 10:10:29.995 NNTestScript (#NQ100,H1) Inputs 2 Weights 8 JD 0 10:10:29.995 NNTestScript (#NQ100,H1) 4.00000 6.00000 FL 0 10:10:29.995 NNTestScript (#NQ100,H1) 0.954 0.026 0.599 0.952 0.864 0.161 0.818 0.765 EJ 0 10:10:29.995 NNTestScript (#NQ100,H1) Arr size A 2 EM 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[0] = 3.81519 X A[0] = 4.000 B[0] = 0.954 NI 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[0] = 9.00110 X A[1] = 6.000 B[4] = 0.864 IE 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[1] = 0.10486 X A[0] = 4.000 B[1] = 0.026 DQ 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[1] = 1.06927 X A[1] = 6.000 B[5] = 0.161 MM 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[2] = 2.39417 X A[0] = 4.000 B[2] = 0.599 JI 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[2] = 7.29974 X A[1] = 6.000 B[6] = 0.818 GE 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[3] = 3.80725 X A[0] = 4.000 B[3] = 0.952 KQ 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[3] = 8.39569 X A[1] = 6.000 B[7] = 0.765 DL 0 10:10:29.995 NNTestScript (#NQ100,H1) before rows 1 cols 4 GI 0 10:10:29.995 NNTestScript (#NQ100,H1) IxWMatrix QM 0 10:10:29.995 NNTestScript (#NQ100,H1) Matrix CH 0 10:10:29.995 NNTestScript (#NQ100,H1) [ HK 0 10:10:29.995 NNTestScript (#NQ100,H1) 9.00110 1.06927 7.29974 8.39569 OO 0 10:10:29.995 NNTestScript (#NQ100,H1) ] CH 0 10:10:29.995 NNTestScript (#NQ100,H1) rows = 1 cols = 4 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< End of the first Hidden Layer >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> NS 0 10:10:29.995 NNTestScript (#NQ100,H1) Hidden Layer 2 | Nodes 6 | Bias 0.2029 HF 0 10:10:29.995 NNTestScript (#NQ100,H1) Inputs 4 Weights 24 LR 0 10:10:29.995 NNTestScript (#NQ100,H1) 0.99993 0.84522 0.99964 0.99988 EL 0 10:10:29.996 NNTestScript (#NQ100,H1) 0.002 0.061 0.056 0.600 0.737 0.454 0.113 0.622 0.387 0.456 0.938 0.587 0.379 0.207 0.356 0.784 0.046 0.597 0.511 0.838 0.848 0.748 0.047 0.282 FF 0 10:10:29.996 NNTestScript (#NQ100,H1) Arr size A 4 EI 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 0.00168 X A[0] = 1.000 B[0] = 0.002 QE 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 0.09745 X A[1] = 0.845 B[6] = 0.113 MR 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 0.47622 X A[2] = 1.000 B[12] = 0.379 NN 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 0.98699 X A[3] = 1.000 B[18] = 0.511 MI 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[1] = 0.06109 X A[0] = 1.000 B[1] = 0.061 ME 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[1] = 0.58690 X A[1] = 0.845 B[7] = 0.622 PR 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[1] = 0.79347 X A[2] = 1.000 B[13] = 0.207 KN 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[1] = 1.63147 X A[3] = 1.000 B[19] = 0.838 GI 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[2] = 0.05603 X A[0] = 1.000 B[2] = 0.056 GE 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[2] = 0.38353 X A[1] = 0.845 B[8] = 0.387 GS 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[2] = 0.73961 X A[2] = 1.000 B[14] = 0.356 CO 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[2] = 1.58725 X A[3] = 1.000 B[20] = 0.848 KH 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[3] = 0.59988 X A[0] = 1.000 B[3] = 0.600 OD 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[3] = 0.98514 X A[1] = 0.845 B[9] = 0.456 LS 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[3] = 1.76888 X A[2] = 1.000 B[15] = 0.784 KO 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[3] = 2.51696 X A[3] = 1.000 B[21] = 0.748 PH 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[4] = 0.73713 X A[0] = 1.000 B[4] = 0.737 FG 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[4] = 1.53007 X A[1] = 0.845 B[10] = 0.938 RS 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[4] = 1.57626 X A[2] = 1.000 B[16] = 0.046 OO 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[4] = 1.62374 X A[3] = 1.000 B[22] = 0.047 EH 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[5] = 0.45380 X A[0] = 1.000 B[5] = 0.454 DG 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[5] = 0.95008 X A[1] = 0.845 B[11] = 0.587 PS 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[5] = 1.54675 X A[2] = 1.000 B[17] = 0.597 EO 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[5] = 1.82885 X A[3] = 1.000 B[23] = 0.282 KH 0 10:10:29.996 NNTestScript (#NQ100,H1) before rows 1 cols 6 RL 0 10:10:29.996 NNTestScript (#NQ100,H1) IxWMatrix HI 0 10:10:29.996 NNTestScript (#NQ100,H1) Matrix NS 0 10:10:29.996 NNTestScript (#NQ100,H1) [ ND 0 10:10:29.996 NNTestScript (#NQ100,H1) 0.98699 1.63147 1.58725 2.51696 1.62374 1.82885 JM 0 10:10:29.996 NNTestScript (#NQ100,H1) ] LG 0 10:10:29.996 NNTestScript (#NQ100,H1) rows = 1 cols = 6 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< End of second Hidden Layer >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> ML 0 10:10:29.996 NNTestScript (#NQ100,H1) Hidden Layer 3 | Nodes 1 | Bias 0.1004 OG 0 10:10:29.996 NNTestScript (#NQ100,H1) Inputs 6 Weights 6 NQ 0 10:10:29.996 NNTestScript (#NQ100,H1) 0.76671 0.86228 0.85694 0.93819 0.86135 0.88409 QM 0 10:10:29.996 NNTestScript (#NQ100,H1) 0.278 0.401 0.574 0.301 0.256 0.870 RD 0 10:10:29.996 NNTestScript (#NQ100,H1) Arr size A 6 NO 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 0.21285 X A[0] = 0.767 B[0] = 0.278 QK 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 0.55894 X A[1] = 0.862 B[1] = 0.401 CG 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 1.05080 X A[2] = 0.857 B[2] = 0.574 DS 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 1.33314 X A[3] = 0.938 B[3] = 0.301 HO 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 1.55394 X A[4] = 0.861 B[4] = 0.256 CJ 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 2.32266 X A[5] = 0.884 B[5] = 0.870 HF 0 10:10:29.996 NNTestScript (#NQ100,H1) before rows 1 cols 1 LR 0 10:10:29.996 NNTestScript (#NQ100,H1) IxWMatrix NS 0 10:10:29.996 NNTestScript (#NQ100,H1) Matrix DF 0 10:10:29.996 NNTestScript (#NQ100,H1) [ NN 0 10:10:29.996 NNTestScript (#NQ100,H1) 2.32266 DJ 0 10:10:29.996 NNTestScript (#NQ100,H1) ] GM 0 10:10:29.996 NNTestScript (#NQ100,H1) rows = 1 cols = 1
ネットワークを視覚化して、最初の層のみで何がおこなわれたかを確認します。残りはまったく同じ手順の繰り返しです。

行列乗算は、期待通りに最初の層の重みを入力に正確に乗算することができましたが、ロジックのコーディングは思ったほど単純ではなく、少し混乱する可能性があります。以下のコードを参照してください。コードの残りの部分は無視して、MatrixMultiply関数だけに注目してください。
void CNeuralNets::FeedForwardMLP( double &MLPInputs[], double &MLPOutput[]) { //--- m_hiddenLayers = m_hiddenLayers+1; ArrayResize(m_hiddenLayerNodes,m_hiddenLayers); m_hiddenLayerNodes[m_hiddenLayers-1] = m_outputLayers; int HLnodes = ArraySize(MLPInputs); int weight_start = 0; double Weights[], bias[]; ArrayResize(bias,m_hiddenLayers); //--- int inputs=ArraySize(MLPInputs); int w_size = 0; //size of weights int cols = inputs, rows=1; double IxWMatrix[]; //dot product matrix //Generate random bias for(int i=0; i<m_hiddenLayers; i++) bias[i] = MathRandom(0,1); //generate weights int sum_weights=0, L_inputs=inputs; double L_weights[]; for (int i=0; i<m_hiddenLayers; i++) { sum_weights += L_inputs * m_hiddenLayerNodes[i]; ArrayResize(Weights,sum_weights); L_inputs = m_hiddenLayerNodes[i]; } for (int j=0; j<sum_weights; j++) Weights[j] = MathRandom(0,1); for (int i=0; i<m_hiddenLayers; i++) { w_size = (inputs*m_hiddenLayerNodes[i]); ArrayResize(L_weights,w_size); ArrayCopy(L_weights,Weights,0,0,w_size); ArrayRemove(Weights,0,w_size); MatrixMultiply(MLPInputs,L_weights,IxWMatrix,cols,cols,rows,cols); ArrayFree(MLPInputs); ArrayResize(MLPInputs,m_hiddenLayerNodes[i]); inputs = ArraySize(MLPInputs); for(int k=0; k<ArraySize(IxWMatrix); k++) MLPInputs[k] = ActivationFx(IxWMatrix[k]+bias[i]); } }
入力層のネットワークの最初の入力は、1xnの行列として提供されます。これは、1行であるが列数が不明(n)であることを意味します。行の「for」ループの前に、このロジックを外部で初期化します。
int cols = inputs, rows=1;
乗算プロセスを完了するために必要な合計重みの数を取得するには、入力層/前の層の数を出力/次の層の数に乗算します。この場合、最初の隠れ層に2つの入力と4つのノードがあるため、最終的に2x4=8、8つの重み値が必要です。次はすべての中で最も重要なトリックです。
MatrixMultiply(MLPInputs,L_weights,IxWMatrix,cols,cols,rows,cols);
これをよく理解するために、行列の乗算が何をするか見てみましょう:
void MatrixMultiply(double &A[],double &B[],double &AxBMatrix[], int colsA,int rowsB,int &new_rows,int &new_cols)
最後の入力new_rows、new_colsは、新しい行列の行と列の新しく更新された値を取得し、値は次の行列の行と列の数として再利用されます。次の層の入力は前の層の出力であることを覚えていらっしゃるでしょうか。
これは行列にとってさらに重要です。
- 最初の層:入力行列=1x2、重み行列=2x4、出力行列=1x4
- 2番目の層:入力行列=1x4、重み行列=4x6、出力行列=1x6
- 3番目の層:入力行列=1x6、重み行列=6x1、出力行列=1x1
行列を乗算する場合、最初の行列の列数は2番目の行列の行数と等しくなければなりません。結果の行列は、最初の行列の行数と2番目の行列の列数の次元を占有します。
以上の操作から
最初の入力は次元がわかっているものですが、重み行列には、入力と隠れ層のノード数を乗算して求められた8つの要素があるため、最終的に次の数に等しい行があると結論付けることができます。前の層の列/入力であり、それだけです。新しい行と新しい列の値を古いものに変更するプロセスにより、このロジックが可能になります(InsideMatrixMultiply関数)。
new_rows = rowsA; new_cols = colsB;
行列の詳細については、行列の標準ライブラリを試してみるか、記事の最後にリンクされているこのライブラリで使用されている別のものを試してみてください。
柔軟なアーキテクチャができたので、ネットワークの訓練と、このフィードフォワードMLPの訓練とテストがどのように見えるかを見てみましょう。
関連するプロセス
- x個のエポックについてネットワークを訓練し、エラーが最も少ないモデルを見つけます。
- モデルのパラメータをバイナリファイルに保存します。これは、エキスパートアドバイザー内の他のプログラムなどで読み取ることができます。
少し待ってください。エラーが最も少ないモデルを見つけると言いましたよね。これは単なるフィードフォワードです。
MQL5.communityの一部の人達は、入力にこれらのパラメータを使用してEAを最適化することを好み、うまくいきますが、ここでは重みとバイアスを一度だけ生成し、残りのエポックでそれらを使用します。逆伝播ですが、ここでの唯一のことは、これらの値が設定されると更新されないことです。それらはまったく更新されません。
1に設定されているデフォルトのエポック数を使用します。
void CNeuralNets::train_feedforwardMLP(double &XMatrix[],int epochs=1)
コードを変更し、そこからスクリプトの入力に重みを付ける方法を見つけることができます。エポックの数を任意の値に設定できますが、この方法に制限されません。ちなみにこれはデモンストレーションです。
見たことのないデータでのモデルのテストまたは使用
訓練したモデルを使用できるようにするには、そのパラメータを他のプログラムと共有できる必要があります。これは、ファイルを使用して可能になることがあります。モデルのパラメータは配列からのdouble値であるため、必要なものはバイナリファイルです。バイナリファイルを読み取ります。重みとバイアスを保存し、それらをそれぞれの配列に保存して、すぐに使用できるようにします。
これがニューラルネットワークの訓練を担当する関数です。
void CNeuralNets::train_feedforwardMLP(double &XMatrix[],int epochs=1) { double MLPInputs[]; ArrayResize(MLPInputs,m_inputs); double MLPOutputs[]; ArrayResize(MLPOutputs,m_outputLayers); double Weights[], bias[]; setmodelParams(Weights,bias); //Generating random weights and bias for (int i=0; i<epochs; i++) { int start = 0; int rows = ArraySize(XMatrix)/m_inputs; { if (m_debug) printf("<<<< %d >>>",j+1); ArrayCopy(MLPInputs,XMatrix,0,start,m_inputs); FeedForwardMLP(MLPInputs,MLPOutputs,Weights,bias); start+=m_inputs; } } WriteBin(Weights,bias); }
setmodelParams()は、重みとバイアスのランダムな値を生成する関数です。モデルを訓練した後、重みとバイアスの値を取得し、それらをバイナリファイルに保存します。
WriteBin(Weights,bias);
MLPですべてがどのように機能するかを示すために、こちらにある実際のサンプルデータセットを使用します。
引数XMatrix[]は、モデルを訓練するすべての入力値の行列です。この場合、CSVファイルを行列にインポートする必要があります。

データセットをインポートする
読者の代わりにやりました。
double XMatrix[]; int rows,cols; CSVToMatrix(XMatrix,rows,cols,"NASDAQ_DATA.csv"); MatrixPrint(XMatrix,cols,3);
上記のコードの出力は次の通りです。
MN 0 12:02:13.339 NNTestScript (#NQ100,H1) Matrix MI 0 12:02:13.340 NNTestScript (#NQ100,H1) [ MJ 0 12:02:13.340 NNTestScript (#NQ100,H1) 4173.800 13067.500 13386.600 34.800 RD 0 12:02:13.340 NNTestScript (#NQ100,H1) 4179.200 13094.800 13396.700 36.600 JQ 0 12:02:13.340 NNTestScript (#NQ100,H1) 4182.700 13108.000 13406.600 37.500 FK 0 12:02:13.340 NNTestScript (#NQ100,H1) 4185.800 13104.300 13416.800 37.100 ..... ..... ..... DK 0 12:02:13.353 NNTestScript (#NQ100,H1) 4332.700 14090.200 14224.600 43.700 GD 0 12:02:13.353 NNTestScript (#NQ100,H1) 4352.500 14162.000 14225.000 47.300 IN 0 12:02:13.353 NNTestScript (#NQ100,H1) 4401.900 14310.300 14226.200 56.100 DK 0 12:02:13.353 NNTestScript (#NQ100,H1) 4405.200 14312.700 14224.500 56.200 EE 0 12:02:13.353 NNTestScript (#NQ100,H1) 4415.800 14370.400 14223.200 60.000 OS 0 12:02:13.353 NNTestScript (#NQ100,H1) ] IE 0 12:02:13.353 NNTestScript (#NQ100,H1) rows = 744 cols = 4
これで、CSVファイル全体がXMatrix[]内に格納されます。
この結果の行列の良い点は、変数colsがCsvファイルから列数を取得するため、ニューラルネットワークの入力について心配する必要がないことです。これらは、ニューラルネットワークの入力になります。最後に、スクリプト全体は次のようになります。
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ #include "NeuralNets.mqh"; CNeuralNets *neuralnet; //+------------------------------------------------------------------+ void OnStart() { int hlnodes[3] = {4,6,1}; int outputs = 1; int inputs_=2; double XMatrix[]; int rows,cols; CSVToMatrix(XMatrix,rows,cols,"NASDAQ_DATA.csv"); MatrixPrint(XMatrix,cols,3); neuralnet = new CNeuralNets(SIGMOID,RELU,cols,hlnodes,outputs); neuralnet.train_feedforwardMLP(XMatrix); delete(neuralnet); }
シンプルだとおもいますが、まだコードを数行修正しなければなりません。train_feedforwardMLP内で、データセット全体の反復を単一のエポック反復に追加しました。これは、エポックの完全な意味を作成するためです。
for (int i=0; i<epochs; i++) { int start = 0; int rows = ArraySize(XMatrix)/m_inputs; for (int j=0; j<rows; j++) //iterate the entire dataset in a single epoch { if (m_debug) printf("<<<< %d >>>",j+1); ArrayCopy(MLPInputs,XMatrix,0,start,m_inputs); FeedForwardMLP(MLPInputs,MLPOutputs,Weights,bias); start+=m_inputs; } }
このプログラムをデバッグモードで実行したときのログを見てみましょう。
bool m_debug = true;
ニューラルネットワークをデバッグしていない限り、デバッグモードはハードドライブのスペースをいっぱいにする可能性があるのでfalseに設定してください。プログラムを1回実行したところ、最大21Mbのスペースを占めるログが生成されました。
2つの反復の概要:
MR 0 12:23:16.485 NNTestScript (#NQ100,H1) <<<< 1 >>> DE 0 12:23:16.485 NNTestScript (#NQ100,H1) Hidden layer nodes plus the output FS 0 12:23:16.485 NNTestScript (#NQ100,H1) 4 6 1 1 KK 0 12:23:16.485 NNTestScript (#NQ100,H1) Hidden Layer 1 | Nodes 4 | Bias 0.3903 IN 0 12:23:16.485 NNTestScript (#NQ100,H1) Inputs 4 Weights 16 MJ 0 12:23:16.485 NNTestScript (#NQ100,H1) 4173.80000 13067.50000 13386.60000 34.80000 DF 0 12:23:16.485 NNTestScript (#NQ100,H1) 0.060 0.549 0.797 0.670 0.420 0.914 0.146 0.968 0.464 0.031 0.855 0.240 0.717 0.288 0.372 0.805 .... PD 0 12:23:16.485 NNTestScript (#NQ100,H1) MLP Final Output LM 0 12:23:16.485 NNTestScript (#NQ100,H1) 1.333 HP 0 12:23:16.485 NNTestScript (#NQ100,H1) <<<< 2 >>> PG 0 12:23:16.485 NNTestScript (#NQ100,H1) Hidden layer nodes plus the output JR 0 12:23:16.485 NNTestScript (#NQ100,H1) 4 6 1 1 OH 0 12:23:16.485 NNTestScript (#NQ100,H1) Hidden Layer 1 | Nodes 4 | Bias 0.3903 EI 0 12:23:16.485 NNTestScript (#NQ100,H1) Inputs 4 Weights 16 FM 0 12:23:16.485 NNTestScript (#NQ100,H1) 4179.20000 13094.80000 13396.70000 36.60000 II 0 12:23:16.486 NNTestScript (#NQ100,H1) 0.060 0.549 0.797 0.670 0.420 0.914 0.146 0.968 0.464 0.031 0.855 0.240 0.717 0.288 0.372 0.805 GJ 0 12:23:16.486 NNTestScript (#NQ100,H1)
すべてがセットアップされ、期待どおりに機能しています。次に、モデルパラメータをバイナリファイルに保存します。
モデルのパラメータをバイナリファイルに保存する
bool CNeuralNets::WriteBin(double &w[], double &b[]) { string file_name_w = NULL, file_name_b= NULL; int handle_w, handle_b; file_name_w = MQLInfoString(MQL_PROGRAM_NAME)+"\\"+"model_w.bin"; file_name_b = MQLInfoString(MQL_PROGRAM_NAME)+"\\"+"model_b.bin"; FileDelete(file_name_w); FileDelete(file_name_b); handle_w = FileOpen(file_name_w,FILE_WRITE|FILE_BIN); if (handle_w == INVALID_HANDLE) { printf("Invalid %s Handle err %d",file_name_w,GetLastError()); } else FileWriteArray(handle_w,w); FileClose(handle_w); handle_b = FileOpen(file_name_b,FILE_WRITE|FILE_BIN); if (handle_b == INVALID_HANDLE) { printf("Invalid %s Handle err %d",file_name_b,GetLastError()); } else FileWriteArray(handle_b,b); FileClose(handle_b); return(true); }
このステップは超重要です。前述のように、同じライブラリを使用する他のプログラムとモデルパラメータを共有するのに役立ちます。バイナリファイルは、スクリプトファイルの名前のサブディレクトリに保存されます。

次は、他のプログラムでモデルパラメータにアクセスする方法の例です。
double weights[], bias[]; int handlew = FileOpen("NNTestScript\\model_w.bin",FILE_READ|FILE_BIN); FileReadArray(handlew,weights); FileClose(handlew); int handleb = FileOpen("NNTestScript\\model_b.bin",FILE_READ|FILE_BIN); FileReadArray(handleb,bias); FileClose(handleb); Print("bias"); ArrayPrint(bias,4); Print("Weights"); ArrayPrint(weights,4);
以下が出力です。
HR 0 14:14:02.380 NNTestScript (#NQ100,H1) bias DG 0 14:14:02.385 NNTestScript (#NQ100,H1) 0.0063 0.2737 0.9216 0.4435 OQ 0 14:14:02.385 NNTestScript (#NQ100,H1) Weights GG 0 14:14:02.385 NNTestScript (#NQ100,H1) [ 0] 0.5338 0.6378 0.6710 0.6256 0.8313 0.8093 0.1779 0.4027 0.5229 0.9181 0.5449 0.4888 0.9003 0.2870 0.7107 0.8477 NJ 0 14:14:02.385 NNTestScript (#NQ100,H1) [16] 0.2328 0.1257 0.4917 0.1930 0.3924 0.2824 0.4536 0.9975 0.9484 0.5822 0.0198 0.7951 0.3904 0.7858 0.7213 0.0529 EN 0 14:14:02.385 NNTestScript (#NQ100,H1) [32] 0.6332 0.6975 0.9969 0.3987 0.4623 0.4558 0.4474 0.4821 0.0742 0.5364 0.9512 0.2517 0.3690 0.4989 0.5482名前と場所がわかれば、どこからでもこのファイルにアクセスできます。
モデルの使用
これは簡単な部分です。フィードフォワードMLP関数が変更され、新しい入力の重みとバイアスが追加されました。これは、最近の価格データなどのモデルを実行するのに役立ちます。
void CNeuralNets::FeedForwardMLP(double &MLPInputs[],double &MLPOutput[],double &Weights[], double &bias[])
重みとバイアスを抽出し、モデルをライブで使用する方法に関する完全なコードです。最初にパラメータを読み取り、次に入力行列ではなく入力値をプラグインします。これは、今回は訓練済みモデルを使用して入力値の結果を予測するためです。MLPOutput[]は、出力配列を提供します。
double weights[], bias[]; int handlew = FileOpen("NNTestScript\\model_w.bin",FILE_READ|FILE_BIN); FileReadArray(handlew,weights); FileClose(handlew); int handleb = FileOpen("NNTestScript\\model_b.bin",FILE_READ|FILE_BIN); FileReadArray(handleb,bias); FileClose(handleb); double Inputs[]; ArrayCopy(Inputs,XMatrix,0,0,cols); //copy the four first columns from this matrix double Output[]; neuralnet = new CNeuralNets(SIGMOID,RELU,cols,hlnodes,outputs); neuralnet.FeedForwardMLP(Inputs,Output,weights,bias); Print("Outputs"); ArrayPrint(Output); delete(neuralnet);
これはうまくいくはずです。
これで、さまざまな種類のアーキテクチャを自由に探索し、さまざまなオプションを探索して、何が最適かをもう一度確認できます。
フィードフォワードニューラルネットワークは、最初に考案された最も単純なタイプの人工ニューラルネットワークです。このネットワークでは、情報は入力ノードから隠れノード(存在する場合)を経由して出力ノードへと一方向(前方向)にのみ移動します。ネットワークにサイクルやループはありません。
今コード化したこのモデルは基本的なものであり、最適化されていない限り、必ずしも望む結果が得られるとは限りません(100%確信しています)。
最後に
MQL5にはデータ サイエンスパッケージがないため、各機械学習手法の秘密裏の理論とすべてを理解することが重要です。 少なくともPythonフレームワークはありますが、MetaTraderで解決する必要がある場合もあります。この種の背後にある理論をしっかりと理解していなければ、機械学習を理解して最大限に活用することは困難です。先に進むにつれて、理論の重要性と、連載の前半で説明した事柄が非常に重要であることが証明されます。
よろしくお願いします。
GitHubリポジトリ:https://github.com/MegaJoctan/NeuralNetworks-MQL5
行列とベクトルのライブラリについてもっと読む
参考文献|書籍
記事の参照
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/11334
 ニューラルネットワークが簡単に(第26部):強化学習
ニューラルネットワークが簡単に(第26部):強化学習
 市場の数学:利益、損失、コスト
市場の数学:利益、損失、コスト
 VIDYAによる取引システムの設計方法を学ぶ
VIDYAによる取引システムの設計方法を学ぶ
 ニューラルネットワークが簡単に(第25部):転移学習の実践
ニューラルネットワークが簡単に(第25部):転移学習の実践
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索