Problems with UTF-8 character encoding during compilation
Characters in code-page 1250 or 1256 are encoded differently in UTF-8.
For example the character "é" is encoded as 0xE9 is code-page 1250, but it is encoded as 0xC3 0xA9 in UTF-8.
So, you are either working in UTF-8 (unicode) or you are working in CodePage 1250. You cannot work in both.
Make sure you are not mixing different encodings in your source file.
Language files are separate includes.
- prepared a file coded in CP 1250
- open it in ME while MT4 is set to 1256
- result: garbage displayed in ME
- compilation on CP 1256
- executing the compiled program on MT4 set to CP 1250
- result: OK
Seems like I'm stuck between rock and a hard place, both of them suck but each in a different way.
- switch between CPs every time I want to compile a different lang version
- edit language files in a different text editor and save each in corresponding CP
Second option suck a bit less, since I'm also using VS Code.
Is there a 3rd way that let me edit and compile all lang files without switching CP or editor?
Language files are separate includes.
- prepared a file coded in CP 1250
- open it in ME while MT4 is set to 1256
- result: garbage displayed in ME
- compilation on CP 1256
- executing the compiled program on MT4 set to CP 1250
- result: OK
Seems like I'm stuck between rock and a hard place, both of them suck but each in a different way.
- switch between CPs every time I want to compile a different lang version
- edit language files in a different text editor and save each in corresponding CP
Second option suck a bit less, since I'm also using VS Code.
Is there a 3rd way that let me edit and compile all lang files without switching CP or editor?
I think that maybe you are causing your own dilema by not properly understanding things. I myself use both MetaEditor and VSCode, and I'm Portuguese, so I frequently use characters from the Portuguese character-set as well as many other characters such as copyright sign and others. I have absolutely no difficulty or issues in working with UTF-8 all the time.
The correct procedure is as follows:
- Open the original file in VSCode and make sure that it knows that is encoded as CP 1250.
In the bottom right corner of the VSCode window, there is the encoding.
Click on it and choose "Reopen with encoding" and then choose desired codepage encoding. - Save it to a new file so as not to change the original.
In the bottom right corner of the VSCode window, there is the encoding.
Click on it and choose "Save as encoding" and then choose UTF-8 (without BOM, for example). - From their onwards, only work with the UTF-8 file on both VSCode and MetaEditor.
I think that maybe you are causing your own dilema by not properly understanding things. I myself use both MetaEditor and VSCode, and I'm Portuguese, so I frequently use characters from the Portuguese character-set as well as many other characters such as copyright sign and others. I have absolutely no difficulty or issues in working with UTF-8 all the time.
The correct procedure is as follows:
- Open the original file in VSCode and make sure that it knows that is encoded as CP 1250.
In the bottom right corner of the VSCode window, there is the encoding.
Click on it and choose "Reopen with encoding" and then choose desired codepage encoding. - Save it to a new file so as not to change the original.
In the bottom right corner of the VSCode window, there is the encoding.
Click on it and choose "Save as encoding" and then choose UTF-8 (without BOM, for example). - From their onwards, only work with the UTF-8 file on both VSCode and MetaEditor.
I think I understood and this is exactly what I have done. But to make SURE SURE I did it for like 4th time
- MT4 CP is set to 1256 (Arabic)
- prepared a file with Polish characters coded in 1250
- VS Code opens and saves this file properly as 1250 - although on open it recognizes it incorrectly as ISO 8859-2, but reopen as 1250 is ok, to make sure I checked the file in HEX and confirmed coded as 1250
- Made a copy of this file, opened in VSC as 1250, saved as UTF-8
- In ME file displays fine
- Compiled is garbage on MT4 set to 1250
- Tested with UTF-16 - same result, displays fine in ME, compiled is garbage
- File with CP 1250 displays as garbage in ME but compiled is ok on MT4 set to 1250
I think I understood and this is exactly what I have done. But to make SURE SURE I did it for like 4th time
- MT4 CP is set to 1256 (Arabic)
- prepared a file with Polish characters coded in 1250
- VS Code opens and saves this file properly as 1250 - although on open it recognizes it incorrectly as ISO 8859-2, but reopen as 1250 is ok, to make sure I checked the file in HEX and confirmed coded as 1250
- Made a copy of this file, opened in VSC as 1250, saved as UTF-8
- In ME file displays fine
- Compiled is garbage on MT4 set to 1250
- Tested with UTF-16 - same result, displays fine in ME, compiled is garbage
- File with CP 1250 displays as garbage in ME but compiled is ok on MT4 set to 1250
What operating system and version are you using?
What build of MT4 are you using?
I'm using Windows 10 and I have no such problem on MT4 (build 1380) nor MT5 (build 3802).
The only time the code-page is relevant is if I am using the command line interface or a very old application.
If you can supply an example source file (in codepage 1250 or 1256) for us to test, I will be glad to test it on my end and see If I can reproduce your issue.
EDIT: Also, if possible, can you show some screenshots of the issue on your end?
Win11, latest build, Polish language in Windows. Example files attached.
--EDIT--
I forgot to mention - the same utf-8 source file compiled when Win for non-unicode is set to PL - result good.
| CP for MT4 is set in regional settings for non unicode applications (tried BETA UTF-8 setting and with it MT4 interface is garbage when lang set to Arabic) the only way it's displayed correctly is this setting (particular Arab country doesn't matter) | 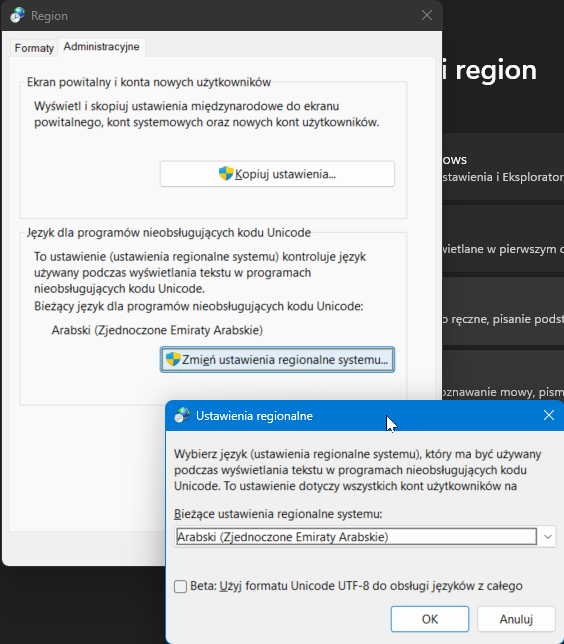 |
| UTF-8 coded file with PL characters coded as 1250 generated from VS Code in ME looks ok but does not compile right | 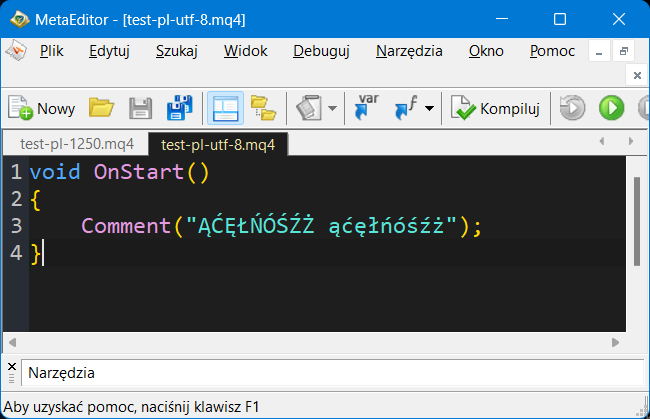 |
| 1250 file with PL characters coded as 1250 generated from VS Code in ME looks garbage but compiles right | 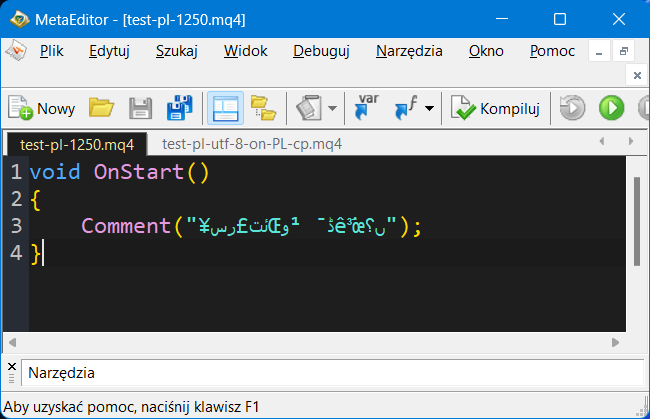 |
Try setting the CodePage to 1256 and not 1250, and work with the 1256 source files instead of 1250 or UTF-8.
By the way, the file "pl-source-cp1250.mq4" is actually Windows 1256 and not 1250.
And when you save it to UTF-8 in VSCode, select UTF-8 with BOM. The (with BOM) is important in this case so that it does not get mistaken for some other codepage format.
void OnStart() { Comment("¥ئت£رسŒڈ¯ ¹وê³ٌَœں؟"); Print("¥ئت£رسŒڈ¯ ¹وê³ٌَœں؟"); }
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
I am developing software in multiple languages using code pages 1250 and 1256. Expecting to code in even more CPs in the future. In the source code in ME, all the national characters display correctly. The sources are saved in utf8.
The problem occurs during compilation. Only characters from the Windows CP that is set for MT4 a the given moment are compiled correctly. For other CPs, the compiled version displays rubbish instead of out-of-range characters, even though MT4 is set to the code page of the language version of the program.
Example
Maybe someone has encountered a similar problem and knows a solution? Because having to restart Windows every time to compile a different language version is unacceptable. Running separate VMs set to different CPs ditto.