
Neuronale Netze leicht gemacht (Teil 43): Beherrschen von Fähigkeiten ohne Belohnungsfunktion

Einführung
Verstärkungslernen ist ein leistungsfähiger Ansatz des maschinellen Lernens, der es einem Agenten ermöglicht, selbständig zu lernen, indem er mit der Umgebung interagiert und Feedback in Form einer Belohnungsfunktion erhält. Eine der größten Herausforderungen beim Reinforcement Learning ist jedoch die Notwendigkeit, eine Belohnungsfunktion zu definieren, die das gewünschte Verhalten des Agenten formalisiert.
Die Bestimmung der Belohnungsfunktion kann eine komplexe Angelegenheit sein, insbesondere bei Aufgaben, die mehrere Ziele erfordern oder bei denen es mehrdeutige Situationen gibt. Außerdem haben manche Aufgaben keine explizite Belohnungsfunktion, was die Anwendung traditioneller Methoden des Verstärkungslernens erschwert.
In diesem Artikel stellen wir das Konzept „Diversity is All You Need“ (Vielfalt ist alles, was man braucht) vor, das es Ihnen ermöglicht, einem Modell eine Fähigkeit ohne eine explizite Belohnungsfunktion beizubringen. Die Vielfalt der Aktionen, die Erkundung der Umgebung und die Maximierung der Variabilität der Interaktionen mit der Umgebung sind Schlüsselfaktoren für das Training eines Agenten, um sich effektiv zu verhalten.
Dieser Ansatz bietet eine neue Perspektive auf das Lernen ohne Belohnungsfunktion und kann bei der Lösung komplexer Probleme nützlich sein, bei denen die Identifizierung einer expliziten Belohnungsfunktion schwierig oder unmöglich ist.
1. Das Konzept „Diversity is All You Need“
Im wirklichen Leben sind bestimmte Kenntnisse und Fähigkeiten erforderlich, damit ein Darsteller bestimmte Aufgaben erfüllen kann. In ähnlicher Weise bemühen wir uns beim Training eines Modells um die Entwicklung der Fähigkeiten, die zur Lösung des gegebenen Problems erforderlich sind.
Beim Verstärkungslernen ist die Belohnungsfunktion das wichtigste Instrument zur Stimulierung eines Modells. Es ermöglicht dem Agenten zu verstehen, wie erfolgreich seine Aktionen waren. Belohnungen sind jedoch oft selten, und es sind zusätzliche Ansätze erforderlich, um optimale Lösungen zu finden. Wir haben uns bereits mit einigen Methoden befasst, die ein Modell ermutigen, seine Umgebung zu erkunden, aber sie sind nicht immer effektiv.
Traditionell ausgebildete Modelle haben eine enge Spezialisierung und sind nur in der Lage, bestimmte Probleme zu lösen. Bei kleinen Änderungen in der Problemstellung ist ein komplettes Neutraining des Modells erforderlich, auch wenn die vorhandenen Fähigkeiten nützlich sein können. Das Gleiche passiert, wenn sich das Umfeld ändert.
Eine mögliche Antwort auf dieses Problem ist die Verwendung hierarchischer Modelle, die aus mehreren Blöcken bestehen. In solchen Modellen erstellen wir separate Modelle für verschiedene Fähigkeiten und einen Planer, der den Einsatz dieser Fähigkeiten verwaltet. Die Ausbildung von Planern ermöglicht es uns, neue Probleme mit Hilfe von zuvor erlernten Fähigkeiten zu lösen. Dies wirft jedoch die Frage nach der Angemessenheit und Qualität der bereits erlernten Fähigkeiten auf, da zur Lösung neuer Probleme zusätzliche Fähigkeiten erforderlich sein können.
Das Konzept „Diversity is All You Need“ schlägt vor, hierarchische Modelle mit getrennten Fähigkeiten und einem Planer zu verwenden. Der Schwerpunkt liegt auf einer maximalen Vielfalt von Aktionen und der Erkundung der Umgebung, sodass der Agent effektiv lernen und sich anpassen kann. Durch die Vermittlung unterschiedlicher und ausgeprägter Fähigkeiten wird das Modell flexibler und anpassungsfähiger und ist in der Lage, verschiedene Strategien in unterschiedlichen Situationen anzuwenden. Dieser Ansatz ist nützlich, wenn es schwierig ist, explizite Belohnungen zu ermitteln, da das Modell selbstständig neue Lösungen erkunden und finden kann.
Der Kerngedanke dieses Konzepts besteht darin, die Vielfalt als Mittel zum Lernen zu nutzen. Die Vielfalt der Aktionen und des Verhaltens eines Modells ermöglicht es ihm, den Zustandsraum zu erkunden und neue Möglichkeiten zu entdecken. Die Vielfalt beschränkt sich nicht auf willkürliche oder unwirksame Aktionen, sondern zielt darauf ab, verschiedene nützliche Strategien zu entdecken, die in unterschiedlichen Situationen angewendet werden können.
Das Konzept „Diversity is All You Need“ impliziert, dass Vielfalt eine Schlüsselkomponente für eine erfolgreiche Ausbildung ist, ohne eine offensichtliche Belohnungsfunktion. Ein Modell, das mit einer Vielzahl von Fähigkeiten trainiert wurde, wird flexibler und anpassungsfähiger und ist in der Lage, je nach Kontext und Aufgabenanforderungen unterschiedliche Strategien anzuwenden.
Dieser Ansatz kann bei der Lösung komplexer Probleme eingesetzt werden, bei denen die Bestimmung einer expliziten Belohnungsfunktion schwierig oder unzugänglich ist. Es ermöglicht dem Modell, die Umgebung selbstständig zu erkunden und dabei verschiedene Fähigkeiten und Strategien zu erlernen, die zur Entdeckung neuer Wege und Lösungen führen können.
Eine weitere Voraussetzung, die dem Konzept „Diversity is All You Need“ zugrunde liegt, ist die Annahme, dass der aktuelle Zustand des Modells nicht nur von der gewählten Aktion abhängt, sondern auch von den eingesetzten Fähigkeiten. Das heißt, anstatt einfach eine Aktion mit einem Zustand zu verknüpfen, lernt das Modell, bestimmte Zustände mit bestimmten Fähigkeiten zu verknüpfen.
Der Konzeptalgorithmus besteht aus zwei Stufen. Erstens erfolgt das ungesteuerte Erlernen einer Vielzahl von Fähigkeiten ohne Verbindung zu einer bestimmten Aufgabe, was eine gründliche Erkundung der Umgebung ermöglicht und das Verhaltenstoolkit des Agenten erweitert. Es folgt eine Phase des überwachten Verstärkungslernens, die darauf abzielt, eine maximale Effizienz des Modells bei der Lösung des vorgegebenen Ziels zu erreichen.
In der ersten Phase trainieren wir das Kompetenzmodell. Der Input des Modells besteht aus dem aktuellen Zustand der Umgebung und der ausgewählten Fähigkeit, die angewendet werden soll. Das Modell generiert die entsprechende Aktion, die dann ausgeführt wird. Das Ergebnis dieser Aktion ist ein Übergang zu einem neuen Zustand der Umgebung. In diesem Stadium sind wir nur an diesem neuen Zustand interessiert, und es wird keine externe Belohnung verwendet.
Stattdessen verwenden wir ein Diskriminatormodell, das auf der Grundlage des neuen Zustands versucht zu bestimmen, welche Fähigkeit im vorherigen Schritt verwendet wurde. Die Kreuzentropie zwischen den Ergebnissen des Diskriminators und dem One-Hot-Vektor, der der angewandten Fähigkeit entspricht, dient als Belohnung für unser Fähigkeitsmodell.
Das Kompetenzmodell wird mit Methoden des Reinforcement Learning wie Actor-Critic trainiert. Das Diskriminatormodell hingegen wird mit klassischen überwachten Lernmethoden trainiert.
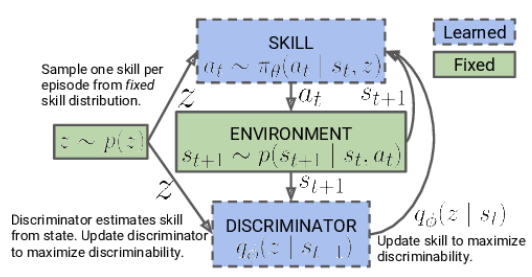
Zu Beginn des Kompetenzmodelltrainings arbeiten wir mit einer festen Basis von Kompetenzen, die nicht vom aktuellen Zustand abhängt. Dies ist darauf zurückzuführen, dass wir noch keine Informationen über die Fähigkeiten und ihren Nutzen in den verschiedenen Staaten haben. Unsere Aufgabe ist es, diese Fähigkeiten zu erlernen. Bei der Entwicklung der Modellarchitektur legen wir die Anzahl der zu trainierenden Fähigkeiten fest.
Während des Trainingsprozesses für das Fähigkeitsmodell erforscht und vervollständigt der Agent aktiv jede Fähigkeit auf der Grundlage der von der Umgebung erhaltenen Informationen. Wir füttern das Modell mit zufälligen IDs, sodass es jede Fähigkeit unabhängig von den anderen erlernen und auffüllen kann.
Das Modell verwendet die erlernten Fertigkeits-IDs und den aktuellen Zustand der Umgebung, um die geeignete Aktion zu bestimmen. Es lernt, bestimmte Fähigkeiten mit bestimmten Zuständen zu verknüpfen und Aktionen für jede Fähigkeit auszuwählen.
Es ist wichtig zu wissen, dass das Modell zu Beginn des Trainings keine Vorkenntnisse über die Fähigkeiten oder ihre Nützlichkeit unter bestimmten Bedingungen hat. Sie untersucht und bestimmt unabhängig die Zusammenhänge zwischen Fähigkeiten und Zuständen im Ausbildungsprozess. In diesem Fall wird eine Belohnungsfunktion verwendet, die eine maximale Vielfalt des Agentenverhaltens in Abhängigkeit von der eingesetzten Fähigkeit fördert.
Sobald die Trainingsphase für das Kompetenzmodell abgeschlossen ist, gehen wir zur nächsten Phase über, dem überwachten Verstärkungslernen. In diesem Schritt trainieren wir ein Scheduler-Modell mit dem Ziel, ein bestimmtes Ziel zu maximieren oder die maximale Belohnung innerhalb einer bestimmten Aufgabe zu erhalten. Dabei können wir ein Modell mit festen Fähigkeiten verwenden, was den Trainingsprozess des Scheduler-Modells beschleunigen kann.
Ein zweistufiger Ansatz für das Training eines Fähigkeitsmodells, der mit der unbeaufsichtigten Vervollständigung von Fähigkeiten beginnt und mit dem überwachten Verstärkungslernen endet, ermöglicht es dem Modell, unabhängig voneinander Fähigkeiten für eine Vielzahl von Aufgaben zu erlernen und zu nutzen.
Beachten Sie, dass wir in unserem Ansatz den hierarchischen Entscheidungsprozess gegenüber dem zuvor diskutierten hierarchischen Modell modifiziert haben. Früher haben wir mehrere Agenten eingesetzt, jeder mit seinen eigenen Fähigkeiten. Die Agenten schlugen Handlungsoptionen vor, und der Planer bewertete diese Optionen und traf dann die endgültige Entscheidung.
Wir haben diese Reihenfolge im aktuellen Konzept geändert. Nun analysiert der Planer zunächst die aktuelle Situation und entscheidet sich für die Auswahl der geeigneten Fähigkeit. Der Agent entscheidet dann auf der Grundlage der ausgewählten Fähigkeit über die geeignete Aktion.
Wir haben also den hierarchischen Prozess umgedreht: Jetzt entscheidet der Planer über die zu verwendende Fähigkeit, und dann führt der Agent die der gewählten Fähigkeit entsprechende Aktion aus. Dieser Wandel ermöglicht es uns, unsere Fähigkeiten je nach aktueller Situation effizient zu verwalten und einzusetzen.
2. Implementierung mittels MQL5
Lassen Sie uns nun zur praktischen Umsetzung unserer Arbeit übergehen. Wie im vorigen Artikel beginnen wir mit der Erstellung einer Datenbank von Beispielen, die wir zum Trainieren des Modells verwenden werden. Die Datenerfassung erfolgt durch den EA „DIAYN\Research.mq5“, der eine modifizierte Version des EA aus dem vorherigen Artikel ist. Der derzeitige Algorithmus weist jedoch einige Unterschiede auf.
Die erste Änderung, die wir vorgenommen haben, bezieht sich auf die Architektur der Modelle. Wir haben Änderungen an der Architektur vorgenommen, um neuen Anforderungen und Ideen gerecht zu werden, die sich aus dem Konzept „Diversity is All You Need“ ergeben.
Wir verwenden drei Modelle für den Lernprozess:
- Das Agentenmodell (Fähigkeiten). Es ist für die Vermittlung und Umsetzung verschiedener Fähigkeiten entsprechend dem aktuellen Stand der Umwelt verantwortlich.
- Ein Planer, der auf der Grundlage einer Situationsbeurteilung Entscheidungen trifft und die geeigneten Fähigkeiten zur Erfüllung der Aufgabe auswählt. Der Planer arbeitet mit dem Kompetenzmodell zusammen und leitet die Entscheidungsfindung auf höherer Ebene.
- Ein Diskriminator, der nur während des Trainings des Fähigkeitsmodells verwendet wird und nicht in Echtzeit zum Einsatz kommt. Sie dient der Rückmeldung und der Berechnung von Belohnungen während des Trainings.
Es ist wichtig zu wissen, dass das Qualifikationsmodell und der Planer die wichtigsten Modelle sind, die in der industriellen Praxis und bei der Problemlösung verwendet werden. Der Diskriminator dient nur zur Verbesserung des Trainings des Fähigkeitsmodells und wird nicht für den eigentlichen Betrieb des Systems verwendet.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *scheduler, CArrayObj *discriminator) { //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- if(!discriminator) { scheduler = new CArrayObj(); if(!scheduler) return false; }
Nach dem Algorithmus „Diversity is All You Need“ erhält das Agentenmodell (Skill- oder Fähigkeitenmodell) einen Eingangsdatenpuffer, der Beschreibungen des aktuellen Zustands und die Kennung des verwendeten Skills enthält. Im Rahmen unserer Arbeit übermitteln wir die folgenden Informationen:
- Historische Daten zu Kursbewegungen und Indikatoren: Diese Daten geben Aufschluss über vergangene Kursbewegungen auf dem Markt und die Werte verschiedener Indikatoren. Sie liefern einen wichtigen Kontext für die Entscheidungsfindung des Agentenmodells.
- Informationen über den aktuellen Kontostand und offene Positionen: Diese Daten enthalten Informationen über den aktuellen Kontostand, offene Positionen, die Positionsgröße und andere Finanzparameter. Sie helfen dem Agentenmodell, die aktuelle Situation und die Zwänge bei seinen Entscheidungen zu berücksichtigen.
- One-Hot Fähigkeits-ID Vektor: Dieser Vektor ist eine binäre Darstellung der ID der verwendeten Fertigkeit. Sie gibt eine bestimmte Fähigkeit an, die das Agentenmodell in einem bestimmten Zustand anwenden sollte.
Um solche Eingaben zu verarbeiten, ist eine ausreichend große Quelldatenschicht erforderlich, damit das Agentenmodell alle notwendigen Informationen über Marktbedingungen, Finanzdaten und die gewählte Fähigkeit erhält, um optimale Entscheidungen zu treffen.
//--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * BarDescr + AccountDescr + NSkills); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Nachdem wir die Eingabedaten erhalten haben, erstellen wir eine Daten-Normalisierungsschicht, die eine wichtige Rolle bei der Verarbeitung der Eingabedaten spielt, bevor sie an das Agentenmodell weitergegeben werden. Die Daten-Normalisierungsebene ermöglicht es Ihnen, unterschiedliche Ausgangsmerkmale auf den gleichen Maßstab zu bringen. Dadurch wird die Stabilität und Konsistenz der Daten gewährleistet. Dies ist wichtig, damit das Agentenmodell effektiv arbeiten und qualitativ hochwertige Ergebnisse liefern kann.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die aufbereiteten Rohdaten können mit einem Block von Faltungsschichten verarbeitet werden.
Faltungsschichten sind eine Schlüsselkomponente in der Architektur von Deep-Learning-Modellen, insbesondere bei Bild- und Sequenzverarbeitungsaufgaben. Sie ermöglichen es, räumliche und lokale Abhängigkeiten aus den Quelldaten zu extrahieren.
Im Falle des Algorithmus „Diversity is All You Need“ können Faltungsschichten auf historische Kursbewegungsdaten und Indikatoren angewendet werden, um wichtige Muster und Trends zu extrahieren. Dies hilft dem Agenten, die Beziehungen zwischen verschiedenen Zeitschritten zu erfassen und Entscheidungen auf der Grundlage der erkannten Muster zu treffen.
Jede Faltungsschicht besteht aus 4 Filtern, die die Eingabedaten in einem bestimmten Fenster abtasten. Das Ergebnis der Anwendung von Faltungsoperationen ist eine Reihe von Merkmalskarten, die wichtige Merkmale der Daten hervorheben. Solche Transformationen ermöglichen es dem Agentenmodell, wichtige Merkmale der Daten im Zusammenhang mit einer Verstärkungslernaufgabe zu erkennen und zu berücksichtigen.
Faltungsschichten geben dem Agentenmodell die Fähigkeit, sinnvolle Aspekte der Daten zu „sehen“ und sich darauf zu konzentrieren, was ein wichtiger Schritt bei der Entscheidungsfindung und der Durchführung von Maßnahmen nach dem Prinzip „Diversity is All You Need“ ist.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Nachdem die Daten den Block der Faltungsschichten durchlaufen haben, werden sie im Entscheidungsblock verarbeitet, der aus drei vollständig verbundenen Schichten besteht. Durch die Weiterleitung von Daten durch vollständig vernetzte Schichten ist das Agentenmodell in der Lage, komplexe Abhängigkeiten zu lernen und Beziehungen zwischen verschiedenen Aspekten der Daten zu entdecken.
Die Ausgabe des Entscheidungsblocks erfolgt mittels FQF (Fully Parameterized Quantile Function). Dieses Modell wird zur Schätzung der Quantile der Verteilung der zukünftigen Belohnungen oder Zielvariablen verwendet. Das Agentenmodell kann nicht nur Durchschnittswerte schätzen, sondern auch verschiedene Quantile vorhersagen, was für die Modellierung von Unsicherheit und Entscheidungsfindung unter stochastischen Bedingungen nützlich ist.
Die Verwendung eines vollständig parametrisierten FQF-Modells als Ausgabe des Entscheidungsblocks ermöglicht dem Agentenmodell flexiblere und genauere Vorhersagen, die zur optimalen Auswahl von Aktionen im Rahmen des Konzepts „Diversity is All You Need“ verwendet werden können.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Das Scheduler-Modell führt eine Klassifizierung des aktuellen Zustands der Umgebung durch, um die zu verwendende Fähigkeit zu bestimmen. Im Gegensatz zum Agentenmodell hat der Scheduler eine vereinfachte Architektur ohne die Verwendung von Faltungsschichten zur Datenvorverarbeitung, was Ressourcen spart.
Die Eingabedaten für den Planer sind ähnlich wie die des Agenten, mit Ausnahme des Vektors zur Identifizierung der Fähigkeiten. Der Planer erhält eine Beschreibung des aktuellen Zustands des Umfelds, einschließlich historischer Preisbewegungsdaten, Indikatoren sowie Informationen über den aktuellen Kontostand und offene Positionen.
Die Klassifizierung des Zustands der Umgebung und die Bestimmung der verwendeten Fähigkeiten erfolgt, indem die Daten durch vollständig verbundene Schichten und den FQF-Block geleitet werden. Die Ergebnisse werden mit der Funktion SoftMax normalisiert. Dies führt zu einem Vektor von Wahrscheinlichkeiten, der die Wahrscheinlichkeit widerspiegelt, dass ein Zustand zu jeder möglichen Fähigkeit gehört.
Das Scheduler-Modell ermöglicht es also, auf der Grundlage des aktuellen Zustands der Umgebung zu bestimmen, welche Fähigkeit eingesetzt werden soll. Dies hilft dem Agentenmodell, eine angemessene Entscheidung zu treffen und die optimale Aktion im Sinne des Konzepts „Diversity is All You Need“ auszuwählen.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NSkills; descr.window_out = 32; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Um die Fähigkeiten zu diversifizieren, verwenden wir ein drittes Modell - Discriminator. Seine Aufgabe ist es, die unerwartetsten Aktionen zu belohnen, was zur Vielfalt des Verhaltens des Agenten beiträgt. Da die Genauigkeit dieses Modells nicht sehr hoch ist, beschließen wir, seine Architektur weiter zu vereinfachen und den FQF-Block zu eliminieren.
In der Discriminator-Architektur verwenden wir nur die Normalisierungsschicht und vollständig verbundene Schichten. Auf diese Weise können die Rechenressourcen reduziert werden, ohne dass die Klassifizierungsfähigkeit des Modells beeinträchtigt wird. Am Ausgang des Modells verwenden wir die SoftMax-Funktion, um die Wahrscheinlichkeiten von Aktionen zu erhalten, die zu verschiedenen Fähigkeiten gehören.
//--- Discriminator discriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills; descr.optimization = ADAM; descr.activation = None; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- return true; }
Nachdem wir die Architektur der Modelle beschrieben haben, können wir mit der Organisation der Datenerfassung für das Training fortfahren. In der ersten Phase der Datenerhebung werden wir nur das Agentenmodell verwenden, da wir keine primären Informationen über die Umwelt haben. Stattdessen können wir einen zufällig generierten Vektor zur Identifizierung von Fähigkeiten verwenden, der vergleichbare Ergebnisse mit einem ungeübten Modell liefert. Dies wird es uns auch ermöglichen, den Verbrauch von Computerressourcen erheblich zu reduzieren.
Die Methode OnTick organisiert den direkten Prozess der Datenerfassung. Zu Beginn der Methode wird geprüft, ob das Ereignis der Eröffnung eines neuen Balkens eingetreten ist, und wenn ja, werden die historischen Daten geladen.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Ähnlich wie im vorigen Artikel laden wir Informationen über den aktuellen Zustand in zwei Arrays: das Array mit den historischen Daten und das Array mit den Informationen über den Kontostand der sState-Struktur.
MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- sState.state[b * 12] = (float)Rates[b].close - open; sState.state[b * 12 + 1] = (float)Rates[b].high - open; sState.state[b * 12 + 2] = (float)Rates[b].low - open; sState.state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; sState.state[b * 12 + 4] = (float)sTime.hour; sState.state[b * 12 + 5] = (float)sTime.day_of_week; sState.state[b * 12 + 6] = (float)sTime.mon; sState.state[b * 12 + 7] = rsi; sState.state[b * 12 + 8] = cci; sState.state[b * 12 + 9] = atr; sState.state[b * 12 + 10] = macd; sState.state[b * 12 + 11] = sign; }
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); sState.account[2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); sState.account[3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); sState.account[4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } sState.account[5] = (float)buy_value; sState.account[6] = (float)sell_value; sState.account[7] = (float)buy_profit; sState.account[8] = (float)sell_profit;
Wir speichern die resultierende Struktur in einer Beispieldatenbank, um anschließend Modelle zu trainieren. Um Quelldaten an das Agentenmodell zu übertragen, müssen wir einen Datenpuffer erstellen. In diesem Fall beginnen wir damit, historische Daten in diesen Puffer zu laden.
State1.AssignArray(sState.state);
Um einen stabileren und gleichermaßen effektiven Betrieb des Modells mit unterschiedlichen Kontogrößen zu gewährleisten, wurde beschlossen, die Informationen über den Kontostand in relative Einheiten umzuwandeln. Zu diesem Zweck werden wir einige Änderungen an den Kontostatusanzeigen vornehmen.
Anstelle des absoluten Saldowertes wird der Saldoveränderungsfaktor verwendet. Auf diese Weise können relative Veränderungen des Gleichgewichts im Laufe der Zeit berücksichtigt werden.
Wir werden auch den Eigenkapitalindikator durch das Verhältnis von Eigenkapital zu Bilanzsumme ersetzen. Dies wird dazu beitragen, den relativen Anteil des Eigenkapitals am Saldo zu berücksichtigen und den Indikator zwischen verschiedenen Konten besser vergleichbar zu machen.
Darüber hinaus werden wir eine Eigenkapitalveränderungsquote hinzufügen, die es uns ermöglicht, Veränderungen des relativen Eigenkapitals im Laufe der Zeit zu berücksichtigen.
Schließlich werden wir das Verhältnis von kumuliertem Gewinn/Verlust zum Kontostand einführen, um die relative Größe der kumulierten Handelsergebnisse im Verhältnis zum Kontostand zu berücksichtigen.
Durch diese Änderungen wird ein vielseitigeres Modell geschaffen, das unterschiedliche Kontogrößen effektiv handhaben und deren relative Gesundheit berücksichtigen kann.
State1.Add((sState.account[0] - prev_balance) / prev_balance); State1.Add(sState.account[1] / prev_balance); State1.Add((sState.account[1] - prev_equity) / prev_equity); State1.Add(sState.account[3] / 100.0f); State1.Add(sState.account[4] / prev_balance); State1.Add(sState.account[5]); State1.Add(sState.account[6]); State1.Add(sState.account[7] / prev_balance); State1.Add(sState.account[8] / prev_balance);
Um die Vorbereitung der Daten für das Modell abzuschließen, erstellen wir einen zufälligen One-Hot-Vektor, der als Skill-Identifikator dienen wird. Ein One-Hot-Vektor ist ein binärer Vektor, bei dem nur ein Element 1 ist und die übrigen Elemente 0 sind. Auf diese Weise kann das Modell verschiedene Fähigkeiten auf der Grundlage des Wertes des Elements, das einer bestimmten Fähigkeit entspricht, unterscheiden und identifizieren.
Durch die Generierung eines zufälligen One-Hot-Vektors wird sichergestellt, dass die Skill-IDs in jedem Datenbeispiel unterschiedlich und eindeutig sind. Dies steht im Einklang mit unserem Konzept „Diversity is All You Need“.
vector<float> one_hot = vector<float>::Zeros(NSkills); int skill=(int)MathRound(MathRand()/32767.0*(NSkills-1)); one_hot[skill] = 1; State1.AddArray(one_hot);
In diesem Stadium übertragen wir die vorbereiteten Ausgangsdaten in das Akteursmodell und führen einen Vorwärtsdurchlauf durch das Modell durch. Der Vorwärtsdurchlauf ist der Prozess, bei dem Eingabedaten durch die Schichten eines Modells geleitet werden und entsprechende Ausgabewerte erzeugen.
Nach der Durchführung des Vorwärtsdurchlaufs erhalten wir Modellausgaben, die die Wahrscheinlichkeiten für jede Aktion darstellen, wie sie durch das Akteursmodell bestimmt wurden. Um eine Aktion auszuwählen, wählen wir eine der möglichen Aktionen auf der Grundlage der ermittelten Wahrscheinlichkeiten aus (Zufallsauswahl unter Berücksichtigung der Wahrscheinlichkeiten).
Das Action-Sampling ermöglicht es dem Akteur, die Umgebung so weit wie möglich zu erkunden, basierend auf den einzelnen Fähigkeiten. Dies erhöht die Vielfalt der Aktionen, die das Modell ausführen kann, und trägt dazu bei, dass nicht zu oft dieselben Aktionen gewählt werden. Dieser Ansatz verleiht dem Modell eine größere Flexibilität und die Fähigkeit, sich an unterschiedliche Situationen in der Umwelt anzupassen.
if(!Actor.feedForward(GetPointer(State1), 1, false)) return; int act = Actor.getSample();
Der weitere Code der Methode wurde ohne Änderungen aus der früheren EA-Version übernommen. Der vollständige Code des EA, einschließlich aller Methoden, ist in der angehängten Datei zu finden.
Das Sammeln einer Beispieldatenbank wurde bereits in den vorangegangenen Artikeln ausführlich beschrieben, sodass wir uns nicht wiederholen und gleich zur Entwicklung des EA „DIAYN\Study.mq5“ für das Training von Modellen übergehen werden. Wir haben größtenteils den vorherigen Code verwendet, aber erhebliche Änderungen an der Trainingsmethode mit dem Namen Train vorgenommen.
Wir sind von dem ursprünglichen Algorithmus, den die Autoren der Methode vorgeschlagen haben, leicht abgewichen. In unserem EA trainieren wir ein Kompetenzmodell und einen Scheduler parallel. Natürlich wird der Diskriminator nach dem Konzept „Diversity is All You Need“ mitgeschult.
Daher streben wir eine Vielfalt der Fähigkeiten und Verhaltensweisen der Modelle an, um nachhaltigere und effektivere Ergebnisse zu erzielen.
Wie zuvor findet das Modelltraining innerhalb einer Schleife statt. Die Anzahl der Iterationen dieses Zyklus wird in den externen Parametern des EA festgelegt.
Bei jeder Iteration der Trainingsschleife wählen wir zufällig einen Durchgang und einen Zustand aus der Beispieldatenbank aus. Nachdem wir einen Zustand ausgewählt haben, laden wir historische Daten über Kursbewegungen und Indikatoren in einen Datenpuffer, ähnlich wie es im Datenerfassungs-EA geschieht.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); State1.AssignArray(Buffer[tr].States[i].state);
Wir fügen auch Daten zum Kontostatus und zu offenen Positionen in denselben Datenpuffer ein. Wie bereits erwähnt, wandeln wir diese Daten in relative Einheiten um, um die Modelle für unterschiedliche Kontogrößen robuster zu machen. Dadurch können wir die Darstellung des Kontostatus und der offenen Positionen im Modell vereinheitlichen und ihre Vergleichbarkeit für das Training sicherstellen.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State1.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State1.Add(Buffer[tr].States[i].account[1] / PrevBalance); State1.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State1.Add(Buffer[tr].States[i].account[3] / 100.0f); State1.Add(Buffer[tr].States[i].account[4] / PrevBalance); State1.Add(Buffer[tr].States[i].account[5]); State1.Add(Buffer[tr].States[i].account[6]); State1.Add(Buffer[tr].States[i].account[7] / PrevBalance); State1.Add(Buffer[tr].States[i].account[8] / PrevBalance);
Die vorbereiteten Daten reichen für das Planermodell aus, und wir können einen Vorwärtsdurchlauf durch das Modell durchführen, um die zu verwendende Fähigkeit zu bestimmen.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Scheduler.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Nach der Durchführung eines Vorwärtsdurchlaufs durch das Planermodell und dem Erhalt eines Vektors von Wahrscheinlichkeiten, bilden wir einen One-Hot-Skill-Identifikationsvektor. Hier gibt es zwei Optionen für die Auswahl der Fertigkeiten: die gierige Auswahl, bei der die Fertigkeit mit der höchsten Wahrscheinlichkeit ausgewählt wird, und die Stichprobenauswahl, bei der die Fertigkeit nach dem Zufallsprinzip auf der Grundlage von Wahrscheinlichkeiten ausgewählt wird.
Während der Trainingsphase wird empfohlen, Stichproben zu verwenden, um die Erkundung der Umgebung zu maximieren. Auf diese Weise kann das Modell verschiedene Fähigkeiten untersuchen und verborgene Fähigkeiten und optimale Strategien entdecken. Während des Trainings trägt das Sampling dazu bei, eine vorzeitige Konvergenz zu einer bestimmten Fähigkeit zu vermeiden, und ermöglicht vielfältigere Erkundungsaktivitäten, was ein flexibleres und anpassungsfähigeres Trainingsmodell fördert.
int skill = Scheduler.getSample(); SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; State1.AddArray(SchedulerResult);
Der sich daraus ergebende Vektor zur Identifizierung von Fähigkeiten wird dem Quelldatenpuffer hinzugefügt, der an den Eingang des Agentenmodells weitergegeben wird. Danach wird ein Vorwärtsdurchlauf durch das Agentenmodell durchgeführt, um die Aktion zu erzeugen. Die aus dem Modell gewonnene Wahrscheinlichkeitsverteilung wird für die Stichprobe der Aktion verwendet.
Durch die Auswahl einer Aktion aus einer Wahrscheinlichkeitsverteilung kann das Agentenmodell eine Vielzahl von Entscheidungen auf der Grundlage der Wahrscheinlichkeiten der einzelnen Aktionen treffen. Dies fördert die Erkundung verschiedener Strategien und Verhaltensoptionen und hilft dem Modell auch, sich nicht vorschnell auf eine bestimmte Handlung festzulegen.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Actor.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } int action = Actor.getSample();
Nach einem Vorwärtsdurchlauf des Agentenmodells wird ein Datenpuffer für einen Vorwärtsdurchlauf des Diskriminatormodells gebildet, in dem der nächste Zustand des Systems beschrieben wird. Ähnlich wie beim vorigen Schritt beginnen wir mit dem Laden historischer Daten in einen Puffer. In diesem Fall kopieren wir einfach die historischen Daten aus der Beispieldatenbank in den Datenpuffer, da diese Indikatoren nicht vom Modell und den verwendeten Fähigkeiten abhängen.
State1.AssignArray(Buffer[tr].States[i + 1].state);
Wir haben einige Schwierigkeiten, den Kontostand zu beschreiben. Wir können nicht einfach Daten aus der Beispieldatenbank übernehmen, da sie nur selten mit der ausgewählten Aktion übereinstimmen werden. Ebenso können wir nicht einfach eine Aktion aus der Beispieldatenbank ersetzen, da der Diskriminator den als Eingabe erhaltenen Zustand analysiert und ihn mit der verwendeten Fähigkeit vergleicht. Genau hier entsteht die Lücke.
Es ist jedoch wichtig zu beachten, dass die Ausgabe des Diskriminators nur als Belohnungsfunktion verwendet wird. Bei der Beschreibung des neuen Kontostandes ist keine hohe Genauigkeit erforderlich. Stattdessen brauchen wir eine Vergleichbarkeit der Daten über verschiedene Aktivitäten hinweg. Daher können wir die Werte des Kontostands auf der Grundlage des vorherigen Zustands annähernd schätzen, wobei die Größe der letzten Kerze und die gewählte Aktion berücksichtigt werden. Wir haben bereits alle notwendigen Daten für die Berechnung.
In der ersten Phase kopieren wir die Kontodaten aus dem vorherigen Zustand und berechnen den Gewinn für eine Long-Position, wenn sich der Kurs um den Wert der letzten Kerze bewegt. Dabei wird das spezifische Volumen der Position und ihre Richtung nicht berücksichtigt. Wir werden diese Parameter später betrachten.
vector<float> account; account.Assign(Buffer[tr].States[i].account); int bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT);
Anschließend werden die Kontoinformationen entsprechend der gewählten Aktion angepasst. Der einfachste Fall ist die Schließung von Positionen. Wir addieren einfach den kumulierten Gewinn oder Verlust zum aktuellen Kontostand. Der sich daraus ergebende Wert wird dann auf die Elemente Eigenkapital und freier Spielraum übertragen, und die übrigen Kennzeichen werden auf Null zurückgesetzt.
Wenn wir eine Handelsoperation durchführen, müssen wir die entsprechende Position erhöhen. In Anbetracht der Tatsache, dass alle Geschäfte mit einem Mindestlot getätigt werden, erhöhen wir die Größe der entsprechenden Position um das Mindestlot.
Um den kumulierten Gewinn oder Verlust für jede Richtung zu berechnen, multiplizieren wir den zuvor berechneten Gewinn für ein Lot mit der Größe der entsprechenden Position. Da der Gewinn für die Kaufposition zuvor berechnet wurde, addieren wir diesen Wert zum vorherigen kumulierten Gewinn für die Kaufpositionen und subtrahieren ihn von den Verkaufspositionen. Der Gesamtgewinn des Kontos ergibt sich aus der Addition der Gewinne in den verschiedenen Richtungen.
Das Eigenkapital errechnet sich aus der Summe des Saldos und des kumulierten Gewinns.
Die Margenindikatoren bleiben unverändert, da die Änderung der Mindestmenge unbedeutend sein wird.
Im Falle des Haltens einer Position ist die Vorgehensweise ähnlich, mit der Ausnahme, dass das Positionsvolumen verändert wird.
switch(action) { case 0: account[5] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; case 1: account[6] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; case 2: account[0] += account[4]; account[1] = account[0]; account[2] = account[0]; for(bar = 3; bar < AccountDescr; bar++) account[bar] = 0; break; case 3: account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; }
Nachdem wir die Daten über den Saldostatus und die offenen Positionen angepasst haben, fügen wir sie dem Datenpuffer hinzu. In diesem Fall konvertieren wir wie zuvor ihre Werte in relative Einheiten und führen einen direkten Durchlauf durch das Diskriminatormodell durch.
PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; State1.Add((account[0] - PrevBalance) / PrevBalance); State1.Add(account[1] / PrevBalance); State1.Add((account[1] - PrevEquity) / PrevEquity); State1.Add(account[3] / 100.0f); State1.Add(account[4] / PrevBalance); State1.Add(account[5]); State1.Add(account[6]); State1.Add(account[7] / PrevBalance); State1.Add(account[8] / PrevBalance); //--- if(!Discriminator.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Nach einem Vorwärtsdurchlauf des Diskriminators vergleichen wir dessen Ergebnisse mit einem One-Hot-Vektor, der die Identifikation der im Vorwärtsdurchlauf des Agenten verwendeten Fähigkeit enthält.
Discriminator.getResults(DiscriminatorResult);
Actor.getResults(ActorResult);
ActorResult[action] = DiscriminatorResult.Loss(SchedulerResult, LOSS_CCE);
Der durch den Vergleich der beiden Vektoren erhaltene Wert der Kreuzentropie wird als Belohnung für die gewählte Aktion verwendet. Diese Belohnung ermöglicht es uns, das Agentenmodell zurückzurechnen und seine Gewichte zu aktualisieren, um die zukünftige Handlungsauswahl zu verbessern.
Result.AssignArray(ActorResult); State1.AddArray(SchedulerResult); if(!Actor.backProp(Result, DiscountFactor, GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Der One-Hot-Identitätsvektor, der die verwendete Fähigkeit darstellt, ist der Zielwert beim Training des Diskriminatormodells. Wir verwenden diesen Vektor als Ziel, um den Diskriminator so zu trainieren, dass er die Systemzustände entsprechend der ausgewählten Fähigkeit korrekt klassifiziert.
Result.AssignArray(SchedulerResult); if(!Discriminator.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Wir verwenden Kontostandsänderungen nur als Belohnung für den Disponenten. Wir berechnen diese Menge genau und vermitteln sie als relative Werte. Im Gegensatz zum Agenten, der nur für die gewählte Aktion eine Belohnung erhält, verteilen wir die Belohnung des Planers auf alle Fähigkeiten, basierend auf den Wahrscheinlichkeiten der Wahl jeder Fähigkeit. Die Belohnung des Planers wird also auf die Fähigkeiten entsprechend ihrer Auswahlwahrscheinlichkeit aufgeteilt.
Result.AssignArray(SchedulerResult * ((account[0] - PrevBalance) / PrevBalance)); if(!Scheduler.backProp(Result, DiscountFactor, GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Nach Abschluss jeder Iteration des Lernzyklus erzeugen wir eine Informationsnachricht mit Daten über den Lernprozess. Diese Meldung wird in einem Diagramm angezeigt, um den Prozess zu visualisieren. Wir gehen dann zur nächsten Iteration über und setzen den Trainingsprozess fort.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Discriminator", iter * 100.0 / (double)(Iterations), Discriminator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nach Abschluss des Trainingsprozesses führen wir eine Bereinigung des Diagramms durch, wobei frühere Informationsdaten entfernt werden. Dann wird die Abschaltung des EA eingeleitet.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Discriminator", Discriminator.getRecentAverageError()); ExpertRemove(); //--- }
Der Anhang enthält den vollständigen Code aller im EA verwendeten Methoden und Funktionen. Hier finden Sie ausführliche Informationen.
3. Test
Das Modell wurde auf historischen Daten des EURUSD-Instruments mit dem Zeitrahmen H1 während der ersten vier Monate des Jahres 2023 trainiert. Während des Trainingsprozesses wurde ein nicht-indikativer Fehler in der Funktionsweise des Agentenmodells entdeckt, der mit der Belohnungspolitik zusammenhängt, die zu einem unbegrenzten Wachstum der Belohnungen führen kann. Der Trainingsprozess wird jedoch nach wie vor von der Leistung der Planer- und Diskriminatormodelle gesteuert.
Das zweite Merkmal des Prozesses ist das Fehlen einer direkten Beziehung zwischen der Wahl des Planers und der durchgeführten Aktion. Die Wahl des Planers hat mehr Einfluss auf die Wahl der Strategie als auf die konkrete Maßnahme. Das bedeutet, dass der Planer den allgemeinen Entscheidungsansatz festlegt, während die spezifische Aktion vom Agentenmodell auf der Grundlage des aktuellen Zustands und der ausgewählten Fähigkeit ausgewählt wird.
Um die Leistung des trainierten Modells zu testen, haben wir Daten aus den ersten beiden Wochen des Monats Mai 2023 verwendet, die nicht in der Trainingsmenge enthalten waren, aber dem Trainingszeitraum sehr nahe kommen. Dieser Ansatz ermöglicht es uns, die Leistung des Modells auf neuen Daten zu bewerten, während die Daten vergleichbar bleiben, da es keine zeitliche Lücke zwischen den Trainings- und den Testsätzen gibt.
Für die Tests haben wir den modifizierten EA „DIAYN\Test.mq5“ verwendet. Die vorgenommenen Änderungen betrafen nur die Datenaufbereitungsalgorithmen in Übereinstimmung mit der Modellarchitektur und dem Prozess der Aufbereitung der Quelldaten. Die Reihenfolge des Aufrufs direkter Übergänge von Modellen wurde ebenfalls geändert. Das Verfahren ist ähnlich aufgebaut wie die zuvor beschriebenen Berater für das Sammeln einer Datenbank von Beispielen und Trainingsmodellen. Der detaillierte EA-Code ist im Anhang zu finden.


Bei der Prüfung des trainierten Modells wurde ein kleiner Gewinn erzielt, mit einem Gewinnfaktor von 1,61 und einem Erholungsfaktor von 3,21. Innerhalb der 240 Balken des Testzeitraums tätigte das Modell 119 Handelsgeschäfte, von denen fast 55 % mit Gewinn abgeschlossen wurden.
Eine wichtige Rolle bei der Erzielung dieser Ergebnisse spielte der Planer, der den Einsatz aller Fähigkeiten gleichmäßig verteilte. Es ist wichtig zu erwähnen, dass die gierige Strategie zur Auswahl von Aktionen und Fähigkeiten verwendet wurde. Das Modell wählte auf der Grundlage des aktuellen Zustands die rentabelste Aktion aus.

Schlussfolgerung
In diesem Artikel wurde ein Ansatz für das Training eines Handelsmodells vorgestellt, der auf der DIAYN-Methode (Diversity is All You Need) basiert, die es ermöglicht, das Modell in einer Vielzahl von Fähigkeiten zu trainieren, ohne an eine bestimmte Aufgabe gebunden zu sein.
Das Modell wurde anhand historischer Daten für das Instrument EURUSD trainiert, wobei der H1-Zeitrahmen in den ersten 4 Monaten des Jahres 2023 verwendet wurde.
Während des Trainings stellte sich heraus, dass es keinen direkten Zusammenhang zwischen der Wahl des Planers und der durchgeführten Aktion gab. Der Trainingsprozess blieb jedoch kontrolliert und zeigte eine gewisse Fähigkeit des Modells, gewinnbringend zu handeln.
Nach Abschluss des Trainings wurde das Modell an neuen Daten getestet, die nicht in der Trainingsmenge enthalten waren. Die Testergebnisse zeigten einen geringen Gewinn, einen Gewinnfaktor von 1,61 und einen Rückgewinnungsfaktor von 3,21. Um jedoch stabilere und bessere Ergebnisse zu erzielen, ist eine weitere Optimierung und Verbesserung der Modellstrategie erforderlich.
Ein wichtiger Aspekt des Modells war der Planer, der den Einsatz aller Fähigkeiten gleichmäßig verteilte. Dies verdeutlicht, wie wichtig es ist, wirksame Entscheidungsstrategien zu entwickeln, um erfolgreiche Handelsergebnisse zu erzielen.
Generell bietet der vorgestellte Ansatz zum Training eines Handelsmodells auf Basis der DIAYN-Methode interessante Perspektiven für die Entwicklung des automatisierten Handels. Weitere Forschungen und Verbesserungen dieses Ansatzes könnten zu effizienteren und profitableren Handelsmodellen führen.
Liste der Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study.mql5 | Expert Advisor | Modelltraining EA |
| 3 | Test.mq5 | Expert Advisor | Modellversuche EA |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | FQF.mqh | Klassenbibliothek | Klassenbibliothek zur Organisation der Arbeit eines vollständig parametrisierten Modells |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/12698
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.