Artículos con ejemplos de programación de robots comerciales en el lenguaje MQL5
En el ámbito del trading automático los Asesores Expertos es la cima de la programación y objetivo deseable de cada desarrollador. Usted puede escribir su propio Asesor Experto utilizando los artículos de esta sección. Paso a paso los principiantes podrán pasar todas las fases de creación, depuración y simulación de los sistemas automáticos de trading.
Los artículos no sólo enseñarán a programar en el lenguaje MQL5, sino mostrarán cómo implementar cualquier idea y técnica comercial. Usted conocerá cómo programar el Trailing Stop, cómo realizar la gestión del capital, cómo obtener el valor del indicador y muchas cosas más.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Paradigmas de programación (Parte 1): Enfoque procedimental para el desarrollo de un asesor basado en la dinámica de precios
Conozca los paradigmas de programación y su aplicación en el código MQL5. En este artículo, analizaremos las características de la programación procedimental y ofreceremos ejemplos prácticos. Asimismo, aprenderemos a desarrollar un asesor basado en la acción del precio (Action Price) utilizando el indicador EMA y datos de velas. Además, el artículo introduce el paradigma de la programación funcional.
Creamos un asesor multidivisa sencillo utilizando MQL5 (Parte 5): Bandas de Bollinger en el Canal de Keltner - Señales de Indicador
En este artículo, entenderemos por asesor multidivisa un asesor o robot comercial que puede comerciar (abrir/cerrar órdenes, gestionar órdenes, por ejemplo, trailing-stop y trailing-profit, etc.) con más de un par de símbolos de un gráfico. En este artículo, usaremos las señales de dos indicadores, las Bandas de Bollinger® y el Canal de Keltner.

Análisis cuantitativo en MQL5: implementamos un algoritmo prometedor
Hoy veremos qué es el análisis cuantitativo, cómo lo utilizan los grandes jugadores y crearemos uno de los algoritmos de análisis cuantitativo en MQL5.

Redes neuronales: así de sencillo (Parte 67): Utilizamos la experiencia adquirida para afrontar nuevos retos
En este artículo, seguiremos hablando de los métodos de recopilación de datos en una muestra de entrenamiento. Obviamente, en el proceso de entrenamiento será necesaria una interacción constante con el entorno, aunque con frecuencia se dan situaciones diferentes.

Redes neuronales: así de sencillo (Parte 66): Problemática de la exploración en el entrenamiento offline
El entrenamiento offline del modelo se realiza sobre los datos de una muestra de entrenamiento previamente preparada. Esto nos ofrecerá una serie de ventajas, pero la información sobre el entorno estará muy comprimida con respecto al tamaño de la muestra de entrenamiento, lo que, a su vez, limitará el alcance del estudio. En este artículo, querríamos familiarizarnos con un método que permite llenar la muestra de entrenamiento con los datos más diversos posibles.

Aprendiendo MQL5 de principiante a profesional (Parte I): Comenzamos a programar
Este artículo supone la introducción a toda una serie de artículos sobre programación. Partimos del supuesto de que el lector no se ha enfrentado nunca a la programación. Así que empezaremos por lo básico. Nivel de conocimientos de programación: principiante absoluto.
Preparación de indicadores de símbolo/periodo múltiple
En este artículo analizaremos los principios de la creación de los indicadores de símbolo/periodo múltiple y la obtención de datos de ellos en asesores e indicadores. Asimismo, veremos los principales matices de uso de los indicadores múltiples en asesores e indicadores, y su representación a través de los búferes del indicador personalizado.
Indicadores alternativos de riesgo y rentabilidad en MQL5
En este artículo, presentaremos una aplicación de varias medidas de rentabilidad y riesgo consideradas alternativas al ratio de Sharpe e investigaremos diferentes curvas de capital hipotéticas para analizar sus características.

Plantillas listas para conectar indicadores en asesores (Parte 3): Indicadores de tendencia
En este artículo de referencia, echaremos un vistazo a los indicadores estándar de la categoría de Indicadores de tendencia. Asimismo, crearemos plantillas listas para usar estos indicadores en asesores expertos: declaración y configuración de parámetros, inicialización y desinicialización de indicadores, y también obtención de datos y señales de los búferes de indicador en asesores.
Estimamos la rentabilidad futura usando intervalos de confianza
En este artículo, nos adentraremos en la aplicación de técnicas de bootstrapping como forma de evaluar la rentabilidad futura de una estrategia automatizada.

Plantillas listas para conectar indicadores en asesores (Parte 2): Indicadores de volumen y Bill Williams
En este artículo, veremos los indicadores estándar de la categoría de Volúmenes y los Indicadores de Bill Williams. Asimismo, crearemos plantillas listas para su uso en asesores: declaración y configuración de parámetros, inicialización y desinicialización de indicadores, y también obtención de datos y señales de los búferes de indicador en asesores.

Redes neuronales: así de sencillo (Parte 65): Aprendizaje supervisado ponderado por distancia (DWSL)
En este artículo, le presentaremos un interesante algoritmo que se basa en la intersección de los métodos de aprendizaje supervisado y por refuerzo.
Creamos un asesor multidivisa sencillo utilizando MQL5 (Parte 4): Media móvil triangular - Señales del indicador
Por asesor multidivisa en este artículo entendemos un asesor, o un robot comercial que puede operar (abrir/cerrar órdenes, gestionar órdenes como Trailing Stop Loss y Trailing Profit) con más de un par de símbolos desde un gráfico. Esta vez usaremos un solo indicador, a saber, la media móvil triangular en uno o varios marcos temporales.

Redes neuronales: así de sencillo (Parte 64): Método de clonación conductual ponderada conservadora (CWBC)
Como resultado de las pruebas realizadas en artículos anteriores, hemos concluido que la optimalidad de la estrategia entrenada depende en gran medida de la muestra de entrenamiento utilizada. En este artículo, nos familiarizaremos con un método bastante sencillo y eficaz para seleccionar trayectorias para el entrenamiento de modelos.

Redes neuronales: así de sencillo (Parte 63): Entrenamiento previo del Transformador de decisiones no supervisado (PDT)
Continuamos nuestra análisis de la familia de métodos del Transformador de decisiones. En artículos anteriores ya hemos observado que entrenar el transformador subyacente en la arquitectura de estos métodos supone todo un reto y requiere una gran cantidad de datos de entrenamiento marcados. En este artículo, analizaremos un algoritmo para utilizar trayectorias no marcadas para el entrenamiento previo de modelos.

Creamos un asesor multidivisa sencillo utilizando MQL5 (Parte 3): Prefijos/sufijos de símbolos y sesión comercial
Últimamente, he recibido comentarios de varios compañeros tráders sobre cómo usar el asesor multidivisa que estamos analizando con brókeres que utilizan prefijos y/o sufijos con nombres de símbolos, así como sobre la forma de implementar zonas horarias comerciales o sesiones comerciales en el asesor.

Redes neuronales: así de sencillo (Parte 62): Uso del transformador de decisiones en modelos jerárquicos
En artículos recientes, hemos visto varios usos del método Decision Transformer, que permite analizar no solo el estado actual, sino también la trayectoria de los estados anteriores y las acciones realizadas en ellos. En este artículo, veremos una variante del uso de este método en modelos jerárquicos.

Redes neuronales: así de sencillo (Parte 61): El problema del optimismo en el aprendizaje por refuerzo offline
Durante el aprendizaje offline, optimizamos la política del Agente usando los datos de la muestra de entrenamiento. La estrategia resultante proporciona al Agente confianza en sus acciones. No obstante, dicho optimismo no siempre está justificado y puede acarrear mayores riesgos durante el funcionamiento del modelo. Hoy veremos un método para reducir estos riesgos.
Experimentos con redes neuronales (Parte 7): Transmitimos indicadores
Ejemplos de transmisión de indicadores a un perceptrón. En el artículo ofreceremos conceptos generales y presentaremos un asesor listo para usar muy simple, así como los resultados de su optimización y sus pruebas forward.

Redes neuronales: así de sencillo (Parte 60): Online Decision Transformer (ODT)
En los 2 últimos artículos nos hemos centrado en el método Decision Transformer, que modela las secuencias de acciones en el contexto de un modelo autorregresivo de recompensas deseadas. En el artículo de hoy, analizaremos otro algoritmo para optimizar este método.

Redes neuronales: así de sencillo (Parte 59): Dicotomía de control (DoC)
En el artículo anterior nos familiarizamos con el transformador de decisión. Sin embargo, el complejo entorno estocástico del mercado de divisas no nos permitió aprovechar plenamente el potencial del método presentado. Hoy veremos un algoritmo que tiene como objetivo mejorar el rendimiento de los algoritmos en entornos estocásticos.
Creamos un asesor multidivisa sencillo utilizando MQL5 (Parte 2): Señales del indicador - Parabolic SAR de marco temporal múltiple
En este artículo, entenderemos por asesor multidivisa un asesor o robot comercial que puede comerciar (abrir/cerrar órdenes, gestionar órdenes, por ejemplo, trailing-stop y trailing-profit, etc.) con más de un par de símbolos de un gráfico. Esta vez usaremos solo un indicador, a saber, Parabolic SAR o iSAR en varios marcos temporales, comenzando desde PERIOD_M15 y terminando con PERIOD_D1.

Redes neuronales: así de sencillo (Parte 58): Transformador de decisión (Decision Transformer-DT)
Continuamos nuestro análisis de los métodos de aprendizaje por refuerzo. Y en el presente artículo, presentaremos un algoritmo ligeramente distinto que considera la política del Agente en un paradigma de construcción de secuencias de acciones.

Integración de modelos ML con el simulador de estrategias (Conclusión): Implementación de un modelo de regresión para la predicción de precios
Este artículo describe la implementación de un modelo de regresión de árboles de decisión para predecir precios de activos financieros. Se realizaron etapas de preparación de datos, entrenamiento y evaluación del modelo, con ajustes y optimizaciones. Sin embargo, es importante destacar que el modelo es solo un estudio y no debe ser usado en operaciones reales.

Redes neuronales: así de sencillo (Parte 57): Stochastic Marginal Actor-Critic (SMAC)
Hoy le proponemos introducir un algoritmo bastante nuevo, el Stochastic Marginal Actor-Critic (SMAC), que permite la construcción de políticas de variable latente dentro de un marco de maximización de la entropía.

Colocando órdenes en MQL5
Al crear cualquier sistema comercial, existe una tarea que debemos resolver de forma efectiva. Esta tarea consiste en que el sistema comercial coloque órdenes o las procese de forma automática. El artículo analizará la creación de un sistema comercial desde el punto de vista de la colocación efectiva de órdenes.
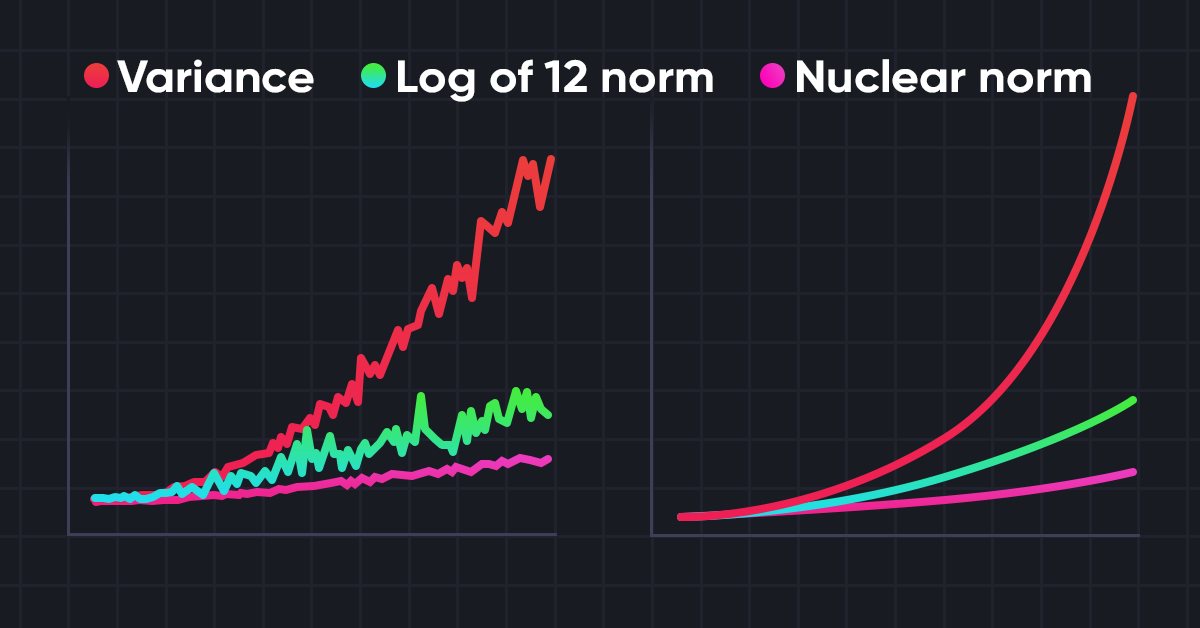
Redes neuronales: así de sencillo (Parte 56): Utilizamos la norma nuclear para incentivar la exploración
La exploración del entorno en tareas de aprendizaje por refuerzo es un problema relevante. Con anterioridad, ya hemos analizado algunos de estos enfoques. Hoy le propongo introducir otro método basado en la maximización de la norma nuclear, que permite a los agentes identificar estados del entorno con un alto grado de novedad y diversidad.
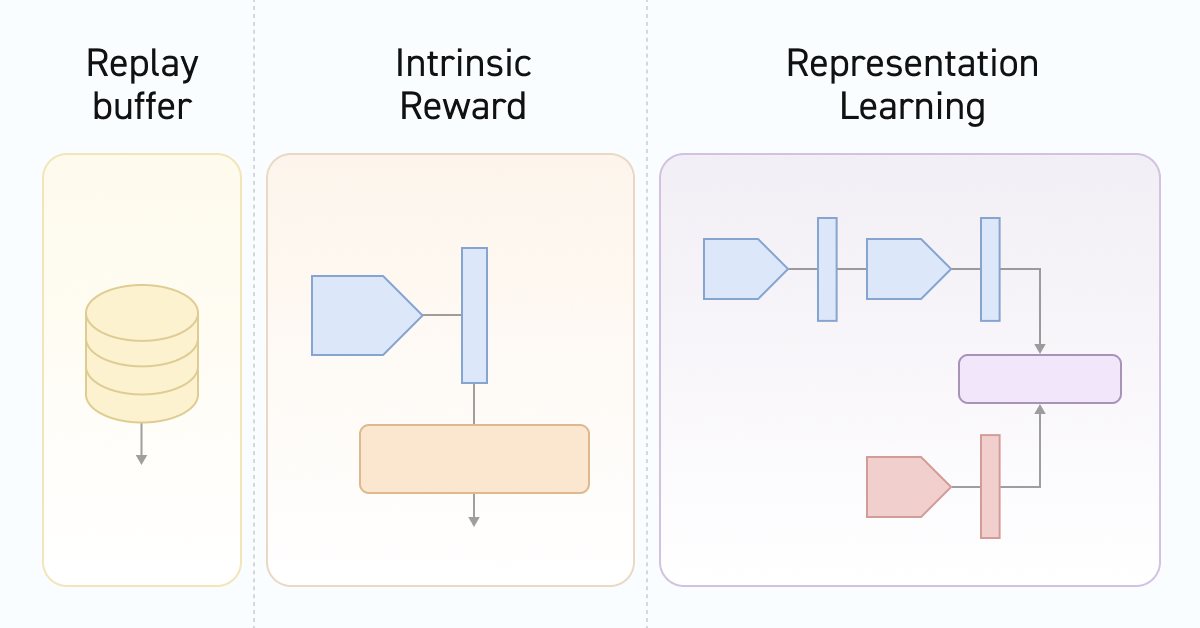
Redes neuronales: así de sencillo (Parte 55): Control interno contrastado (CIC)
El aprendizaje contrastivo (Contrastive learning) supone un método de aprendizaje de representación no supervisado. Su objetivo consiste en entrenar un modelo para que destaque las similitudes y diferencias entre los conjuntos de datos. En este artículo, hablaremos del uso de enfoques de aprendizaje contrastivo para investigar las distintas habilidades del Actor.
Aproximación por fuerza bruta a la búsqueda de patrones (Parte VI): Optimización cíclica
En este artículo mostraremos la primera parte de las mejoras que nos permitieron no solo cerrar toda la cadena de automatización para comerciar en MetaTrader 4 y 5, sino también hacer algo mucho más interesante. A partir de ahora, esta solución nos permitirá automatizar completamente tanto el proceso de creación de asesores como el proceso de optimización, así como minimizar el gasto de recursos a la hora de encontrar configuraciones comerciales efectivas.

Redes neuronales: así de sencillo (Parte 54): Usamos un codificador aleatorio para una exploración eficiente (RE3)
Siempre que analizamos métodos de aprendizaje por refuerzo, nos enfrentamos al problema de explorar eficientemente el entorno. Con frecuencia, la resolución de este problema hace que el algoritmo se complique, llevándonos al entrenamiento de modelos adicionales. En este artículo veremos un enfoque alternativo para resolver el presente problema.

Biblioteca de análisis numérico ALGLIB en MQL5
En este artículo, echaremos un vistazo rápido a la biblioteca de análisis numérico ALGLIB 3.19, sus aplicaciones y sus nuevos algoritmos, que pueden mejorar la eficiencia del análisis de datos financieros.

Creamos un asesor multidivisa sencillo utilizando MQL5 (Parte 1): Señales basadas en ADX combinadas con Parabolic SAR
En este artículo, entenderemos por asesor multidivisa un asesor o robot comercial que puede comerciar (abrir/cerrar órdenes, gestionar órdenes, etc.) con más de un par de símbolos de un gráfico.

Redes neuronales: así de sencillo (Parte 53): Descomposición de la recompensa
Ya hemos hablado más de una vez de la importancia de seleccionar correctamente la función de recompensa que utilizamos para estimular el comportamiento deseado del Agente añadiendo recompensas o penalizaciones por acciones individuales. Pero la cuestión que sigue abierta es el descifrado de nuestras señales por parte del Agente. En este artículo hablaremos sobre la descomposición de la recompensa en lo que respecta a la transmisión de señales individuales al Agente entrenado.

Redes neuronales: así de sencillo (Parte 52): Exploración con optimismo y corrección de la distribución
A medida que el modelo se entrena con el búfer de reproducción de experiencias, la política actual del Actor se aleja cada vez más de los ejemplos almacenados, lo cual reduce la eficacia del entrenamiento del modelo en general. En este artículo, analizaremos un algoritmo para mejorar la eficiencia del uso de las muestras en los algoritmos de aprendizaje por refuerzo.

Redes neuronales: así de sencillo (Parte 51): Actor-crítico conductual (BAC)
Los dos últimos artículos han considerado el algoritmo SAC (Soft Actor-Critic), que incorpora la regularización de la entropía en la función de la recompensa. Este enfoque equilibra la exploración del entorno y la explotación del modelo, pero solo es aplicable a modelos estocásticos. El presente material analizará un enfoque alternativo aplicable tanto a modelos estocásticos como deterministas.

Redes neuronales: así de sencillo (Parte 50): Soft Actor-Critic (optimización de modelos)
En el artículo anterior, implementamos el algoritmo Soft Actor-Critic (SAC), pero no pudimos entrenar un modelo rentable. En esta ocasión, optimizaremos el modelo creado previamente para obtener los resultados deseados en su rendimiento.

Recordando una antigua estrategia de tendencia: dos osciladores estocásticos, MA y Fibonacci
Estrategias comerciales antiguas. Este artículo presenta una estrategia de seguimiento de tendencias. La estrategia es puramente técnica y usa varios indicadores y herramientas para ofrecer señales y niveles objetivo. Los componentes de la estrategia incluyen: Un oscilador estocástico de 14 periodos, un oscilador estocástico de 5 periodos, una media móvil de 200 periodos y una proyección de Fibonacci (para fijar los niveles objetivo).

Redes neuronales: así de sencillo (Parte 49): Soft Actor-Critic
Continuamos nuestro análisis de los algoritmos de aprendizaje por refuerzo en problemas de espacio continuo de acciones. En este artículo, le propongo introducir el algoritmo Soft Astog-Critic (SAC). La principal ventaja del SAC es su capacidad para encontrar políticas óptimas que no solo maximicen la recompensa esperada, sino que también tengan la máxima entropía (diversidad) de acciones.
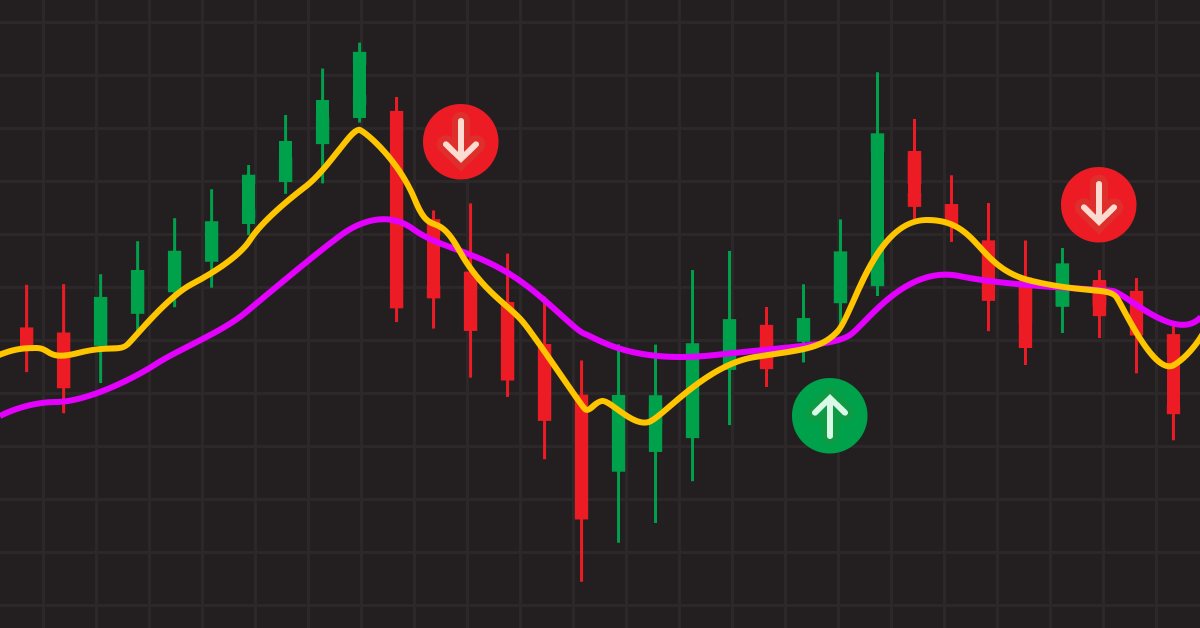
¿Puede Heiken Ashi dar buenas señales en combinación con las medias móviles?
Las combinaciones de estrategias pueden mejorar el rendimiento de las transacciones. Podemos combinar indicadores y patrones para obtener confirmaciones adicionales. Las medias móviles nos ayudan a confirmar tendencias y seguirlas. Se trata del indicador técnico más famoso, lo cual se explica por su sencillez y su probada eficacia de análisis.

Redes neuronales: así de sencillo (Parte 48): Métodos para reducir la sobreestimación de los valores de la función Q
En el artículo anterior, presentamos el método DDPG, que nos permite entrenar modelos en un espacio de acción continuo. Sin embargo, al igual que otros métodos de aprendizaje Q, el DDPG tiende a sobreestimar los valores de la función Q. Con frecuencia, este problema provoca que entrenemos los agentes con una estrategia subóptima. En el presente artículo, analizaremos algunos enfoques para superar el problema mencionado.