
Основы статистики

Введение
Что такое статистика? Вот определение, которое дает Википедия: "Статистика - отрасль знаний, в которой излагаются общие вопросы сбора, измерения и анализа массовых статистических (количественных или качественных) данных." (Статистика). Из этого определения вытекают три основные задачи статистики: сбор данных, измерение данных и анализ данных. Для трейдера полезной является задача анализа данных, так как информация предоставляется брокером или же через торговый терминал, и уже заранее измерена.
Современные трейдеры (в большинстве своем) используют технический анализ для принятия решений о покупке или продаже. Они сталкиваются со статистикой, практически на каждом шагу, когда используют тот или иной индикатор, или же пытаются спрогнозировать уровень цен в ближайший период времени. Да что там говорить, сам график колебания цен является некой статистикой какой-либо акции или валюты во времени. Поэтому очень важно понимать базовые принципы статистики, на которых основаны и построены множество механизмов, облегчающих задачу трейдера о принятии решения.
Теория вероятности и статистика
Любая статистика - это результат изменения состояний объекта, ее порождающего. Рассмотрим валютный курс EURUSD по часовым таймфреймам:

В данном случае, объектом является отношение двух валют, а статистикой - их курс в каждый момент времени. Каким же образом соотношение двух валют влияют на свой курс? Почему в данный промежуток времени мы имеем именно такой график курса, а не другой. Почему в данный момент времени курс валют идет вниз, а не вверх? Ответом на эти вопросы является слово "вероятность". Каждый объект, в зависимости от вероятности, может принимать одно или другое значение.
Проведем простой эксперимент: возьмем монету, и будем подбрасывать ее определенное количество раз, каждый раз фиксируя результат выпадения. Предположим, что монета идеальна. Тогда для нее можно составить следующую таблицу:
| Исход | Вероятность |
|---|---|
| Орел | 0.5 |
| Решка | 0.5 |
Исходя из таблицы можно сделать вывод, что монета с одинаковой вероятностью может упасть вверх либо "орлом", либо "решкой". Другие исходы здесь невозможны (заранее исключили вариант ребро), так как сумма вероятностей всех возможных событий должна равняться единице.
Подбросим монету 10 раз. Рассмотрим результаты выпадений:
| Исход | Количество |
|---|---|
| Орел | 8 |
| Решка | 2 |
Почему так получилось, ведь вероятность выпадения у сторон одинаковая? Вероятность выпасть вверх у сторон монеты действительно одинаковая, но это не означает, что после определенного количества испытаний монета должна упасть ровно половину раз на одну сторону, и половину на другую. Вероятность лишь показывает, что в данном одном испытании (подбрасывании) монета упадет вверх либо "орлом", либо "решкой", и шансы этих двух событий одинаковы.
Теперь подбросим монету 100 раз. Получим новую таблицу исходов:
| Исход | Количество |
|---|---|
| Орел | 53 |
| Решка | 47 |
Как видно, количество исходов так же не равны. Однако, 53 и 47 - это тот результат, который подтверждает изначальные предположения о вероятности. Почти половину раз монета упала "орлом", и половину "решкой".
Теперь проделаем обратную работу. Пусть есть монета, у которой неизвестны вероятности выпадений сторон. Нужно определить, является ли она идеальной, т.е. имеет одинаковые вероятности для выпадения сторон.
Возьмем данные из первого опыта. Поделим количество исходов для сторон на полное количество исходов. Получим вероятности:
| Исход | Вероятность |
|---|---|
| Орел | 0.8 |
| Решка | 0.2 |
Как видно, из первого опыта очень тяжело сделать вывод, что монета идеальна. Проделаем то же для второго опыта:
| Исход | Количество |
|---|---|
| Орел | 0.53 |
| Решка | 0.47 |
А для этих результатов, с высокой степенью точности, можно говорить, что монета действительно идеальна.
На этом простом примере, можно сделать важный вывод: с ростом количества испытаний, статистика более точно отражает свойства объекта ее порождающего.
Таким образом, статистика и вероятность сильно переплетаются. Статистика является результатом испытаний над объектом, и напрямую зависит от вероятности состояний этого объекта. В свою очередь, с помощью статистики можно оценить вероятности состояний объекта. Именно здесь возникает главная задача трейдера: зная данные о торгах за определенный промежуток времени (статистику), спрогнозировать поведение цен(курса) на следующий период времени (получить вероятность), и на основании этого принять решение о покупке или продаже.
Поэтому, вернувшись к введению, важно так же знать и понимать взаимосвязь между статистикой и вероятностью, а также иметь знания по оценке рисков и рисковых ситуаций, но это уже не относится к теме данной статьи.
Базовые статистические параметры
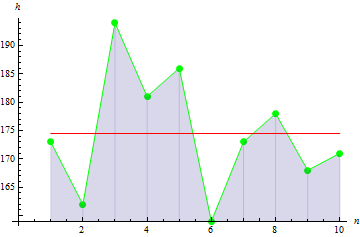
Рассмотрим теперь базовые статистические параметры. Предположим, что имеются данные о росте в сантиметрах 10 человек в некоторой группе:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Рост | 173 | 162 | 194 | 181 | 186 | 159 | 173 | 178 | 168 | 171 |
Данные в таблице называются выборкой, а их количество - объемом выборки. Рассмотрим некоторые параметры этой выборки. Все параметры будут являться выборочными, так как они получаются из данных выборки, а не из данных о случайной величине.
1. Выборочное математическое ожидание
Выборочное математическое ожидание показывает среднее значение выборки. В данном случае - это средний рост члена группы.
Для вычисления математического ожидания, нужно:
- Просуммировать все значения выборки.
- Полученное поделить на ее объем.
Формула:
![]()
Где:
- M - выборочное математическое ожидание,
- a[i] - элемент выборки,
- n - объем выборки.
Рассчитав значение выборочного мат. ожидания, получаем 174.5 см.
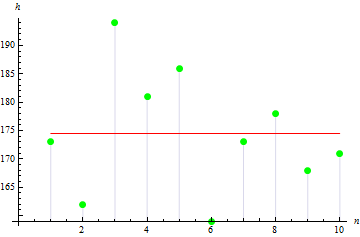
2. Выборочная дисперсия
Выборочная дисперсия показывает насколько значения выборки отдалены от ее математического ожидания. Чем значение больше, тем данные более разбросаны.
Для вычисления дисперсии, нужно:
- Вычислить математическое ожидание выборки.
- От каждого элемента выборки вычесть мат. ожидание и возвести разность в квадрат.
- Просуммировать все полученные выше значения.
- Поделить сумму на объем выборки минус 1.
Формула:
![]()
Где:
- D - выборочная дисперсия,
- M - выборочное математическое ожидание,
- a[i] - элемент выборки,
- n - объем выборки.
Для данной выборки значение дисперсии равно: 113.611.
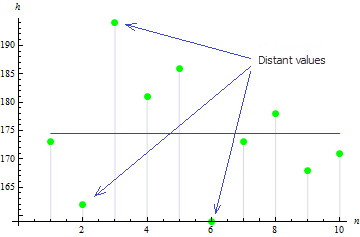
Как видно на рисунке, 3 значения далеко отстоят от мат. ожидания, что и приводит к большому значению дисперсии.
3. Выборочная асимметрия
Выборочная асимметрия показывает, насколько значения выборки асимметричны относительно ее мат. ожидания. Чем ближе значение к нулю, тем значения выборки симметричней.
Для вычисления асимметрии, нужно:
- Вычислить математическое ожидание выборки.
- Вычислить дисперсию выборки.
- Просуммировать кубы разности каждого элемента и мат. ожидания.
- Полученное поделить на значение дисперсии в степени 2/3.
- Полученное домножить на коэффициент, равный объему выборки, деленному на произведение объема выборки минус 1 и объема выборки минус 2.
Формула:
![]()
Где:
- A - выборочная асимметрия,
- D - выборочная дисперсия,
- M - выборочное математическое ожидание,
- a[i] - элемент выборки,
- n - объем выборки.
Для данной выборки получаем достаточно малое значение асимметрии: 0.372981. Это вызвано тем, что далекие значения, компенсируют друг друга.
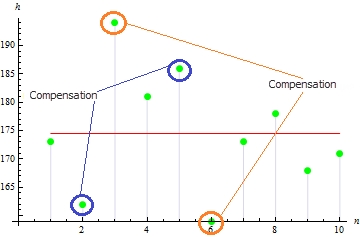
Для асимметричной выборки значение будет больше. Например для следующих данных значение будет равняться: 1.384651.
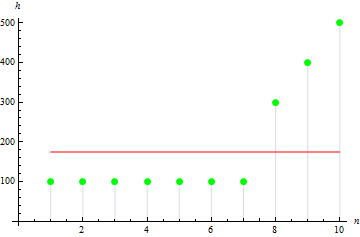
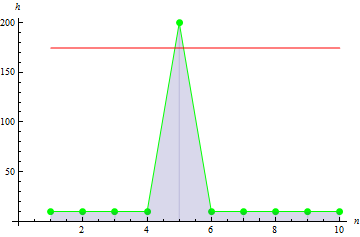
4. Выборочный эксцесс
Выборочный эксцесс показывает меру остроты пика выборки.
Для вычисление эксцесса, нужно:
- Вычислить математическое ожидание выборки.
- Вычислить дисперсию выборки.
- Просуммировать четвертые степени разности каждого элемента и мат. ожидания.
- Поделить полученное на квадрат дисперсии.
- Полученное домножить на коэффициент, равный произведению объема выборки на объем выборки плюс 1, деленного на произведение объема выборки минус 1, объема выборки минус 2 и объема выборки минус 3.
- Вычесть из полученного произведение 3-ех и объема выборки минус 1 в квадрате, деленного на произведение объема выборки минус 1 и объема выборки минус 2.
Формула:
![]()
Где:
- E - выборочный эксцесс,
- D - выборочная дисперсия,
- M - выборочное математическое ожидание,
- a[i] - элемент выборки,
- n - объем выборки.
Для данных о росте получаем значение: -0.1442285.
Для данных с острым пиком получаем большее значение: 10.
5. Выборочная ковариация
Выборочная ковариация - это величина, показывающая степень линейной зависимости между двумя выборками данных. Между линейно независимыми данными ковариация будет равняться 0.
Для демонстрации этого параметра, дополнительно введем данные о весе каждого из 10 человек:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Вес | 65 | 70 | 83 | 60 | 105 | 58 | 69 | 90 | 78 | 65 |
Для вычисления ковариации двух выборок, нужно:
- Вычислить математическое ожидание первой выборки.
- Вычислить математическое ожидание второй выборки.
- Просуммировать все произведения двух разностей: первая - элемент первой выборки минус мат. ожидание первой выборки; вторая - элемент второй выборки (соответствующий элементу первой выборки) минус мат. ожидание второй выборки.
- Полученное поделить на объем выборки минус 1.
Формула:
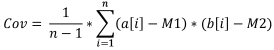
Где:
- Cov - выборочная ковариация,
- a[i] - элемент первой выборки,
- b[i] - элемент первой выборки,
- M1 - выборочное математическое ожидание первой выборки,
- M2 - выборочное математическое ожидание второй выборки,
- n - объем выборки.
Рассчитаем значение ковариации для двух выборок: 91.2778. Зависимость есть, покажем это на совмещенном графике:
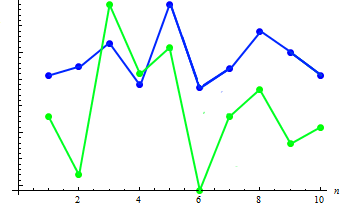
Как видно (как правило) увеличению роста соответствует уменьшение веса и наоборот.
6. Выборочная корреляция
Выборочная коррелляция так же показывает степень линейной зависимости между двумя выборками, но ее значение всегда колеблется от -1 до 1.
Для вычисления корреляции двух выборок, нужно:
- Вычислить дисперсию первой выборки.
- Вычислить дисперсию второй выборки.
- Вычислить ковариацию этих выборок.
- Ковариацию поделить на корень из произведения дисперсий.
Формула:
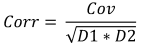
Где:
- Corr - выборочная корреляция,
- Cov - выборочная ковариация,
- D1 - выборочная дисперсия первой выборки,
- D2 - выборочная дисперсия второй выборки,
Для данных о росте и весе, значение корреляции будет равняться 0.579098.
Как используется статистика для торговли
Самым простым примером использования статистических параметров в торговле является индикатор MovingAverage или скользящее среднее. При его расчете используются данные за определенный период, и считается среднее арифметическое значение цены:
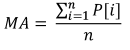
Где:
- MA - значение индикатора,
- P[i] - цена,
- n - период измерения MA
Как видно, индикатор является полным аналогом выборочного математического ожидания. Несмотря на свою простоту, это индикатор используется в подсчете EMA - экспонециального скользящего среднего, который в свою очередь является базовым элементом для построения индикатора MACD - классического инструмента для измерения силы и направления тренда.

Статистика в MQL5
Рассмотрим реализацию базовых статистических параметров, изложенных выше, в MQL5. Эти статистические методы, описанные выше (и не только), реализованы в пакете Статистические функции statistics.mqh. Рассмотрим их код.
1. Выборочное математическое ожидание
Функция пакета, вычисляющая выборочное мат. ожидание, называется Average:

На вход функции подается выборка с данными. На выходе имеем мат. ожидание.
2. Выборочная дисперсия
Функция пакета, вычисляющая выборочную дисперсию, называется Variance:

На вход функции подается выборка с данными и ее мат. ожидание. На выходе имеем дисперсию.
3. Выборочная асимметрия
Функция пакета, вычисляющая выборочную асимметрию, называется Asymmetry:

На вход функции подается выборка с данными, ее мат. ожидание и дисперсия. На выходе имеем асимметрию.
4. Выборочный эксцесс
Функция пакета, вычисляющая выборочный эксцесс, называется Excess (Excess2):

На вход функции подается выборка с данными, ее мат. ожидание и дисперсия. На выходе имеем эксцесс.
5. Выборочная ковариация
Функция пакета, вычисляющая выборочную ковариацию, называется Cov:

На вход функции подаются две выборки с данными и их мат. ожидания. На выходе имеем ковариацию.
6. Выборочная корреляция
Функция пакета, вычисляющая выборочную корреляцию, называется Corr:

На вход функции подается ковариация двух выборок, дисперсия первой выборки и дисперсия второй выборки. На выходе имеем корреляцию.
Теперь зададим выборку с данными о росте и весе и проанализируем ее в пакете.#include <Statistics.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- зададим две выборки значений. double arrX[10]={173,162,194,181,186,159,173,178,168,171}; double arrY[10]={65,70,83,60,105,58,69,90,78,65}; //--- вычислим математическое ожидание double mx=Average(arrX); double my=Average(arrY); //--- для вычисления дисперсии используем значение мат. ожидания double dx=Variance(arrX,mx); double dy=Variance(arrY,my); //--- значения асимметрии и эксцесс double as=Asymmetry(arrX,mx,dx); double exc=Excess(arrX,mx,dx); //--- значения ковариации и корреляции double cov=Cov(arrX,arrY,mx,my); double corr=Corr(cov,dx,dy); //--- вывод результатов в log файл PrintFormat("mx=%.6e",mx); PrintFormat("dx=%.6e",dx); PrintFormat("as=%.6e",as); PrintFormat("exc=%.6e",exc); PrintFormat("cov=%.6e",cov); PrintFormat("corr=%.6e",corr); }
После выполнения скрипта терминал выдаст следующие результаты:
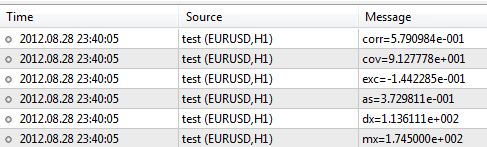
Пакет содержит также множество других функций, описание которых находится в CodeBase - https://www.mql5.com/ru/code/866.
Заключение
Небольшие выводы были уже сделаны в конце пункта "Теория вероятности и статистика". Вдобавок к этому хотелось бы сказать, что изучать статистику, как и любую другую науку, нужно с самых азов. Даже благодаря ее базовым элементам можно упрощать понимание многих сложных вещей, механизмов, закономерностей, что в конечном итоге является крайне необходимым в работе трейдера.
 Ордерные стратегии. Универсальный автомат
Ордерные стратегии. Универсальный автомат
 Статистический Carry Trading
Статистический Carry Trading
 Как купить торгового робота в MetaTrader Market и установить его?
Как купить торгового робота в MetaTrader Market и установить его?
 MetaQuotes ID в мобильном терминале MetaTrader
MetaQuotes ID в мобильном терминале MetaTrader
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Алгоритмов определения мод должно быть полно, поэтому универсальный свой велосипед здесь ни к месту.
Тут скорее надо смотреть на примерах, что хочется получить и что не хотелось бы получать.
А мне статья понравилась.
Очень легко воспринимается и содержит достаточно информации.
А на большее, судя по названию, и не претендует.
Не вижу какой-либо пользы от этой статьи. Ряд банальностей из ТВ. И если бы эта статья не была напечатана на специализированном, наполовину трейдерском сайте, то можно было и промолчать. Но учитывая сайт, хочу заметить следующее.
Существует наука по измерению, анализу и прогнозу экономических данных. Называется эконометрика. Она близкая, кровная родственница статистики, но имеются существенные различия.
1. Для трейдеров анализ сам по себе не имеет ценности, если из анализа не вытекает прогноз. В статье прогноз вообще не упомянут.
2. Эконометрика изначально исходит из нестационарности экономических рядов. И если бы хотя бы помнить об этом, так сказать держать в уме, то рассказ об основных статистиках был бы не таким радужным: для нестационарных рядов основные понятия мо, дисперсия и др. можно применять с кучей оговорок. Во всяком случае следует всегда сомневаться. К примеру, для нестационарных рядов среднее не обязательно будет сходиться к мо. О корреляции вообще молчу.
3. Эконометрика исходит из очень коротких выборок - нескольких десятков наблюдений. Не интересна средняя за много лет, так как такая средняя предполагает и нахождение в позе несколько лет. В условиях кризисов становятся важными оценки результатов расчета. Именно оценки радикально отличают ТВ от статистики и особенно от эконометрики.
Школярская статья. Уровень спец школы, даже не младших курсов института.
"На этом простом примере, можно сделать важный вывод: с ростом количества испытаний, статистика более точно отражает свойства объекта ее порождающего."
Для стационарного процесса (Сферический Конь в Вакуме) - Да.
Для Временных рядов реальных данных данное утверждение больше похоже на бред.
Если бы форекс был Стационарным временным рядом - для его оценки не нужен был бы MQL5 - хватило бы простых деревянных щет из бакалеи.
Если в мотенке сверлят дырки в хаотичном порядке и в хаотичные временные промежутки.
то статистика за весь период - будет больше похоже на отчет РосСтата - или бред сумасшедшего
"Именно здесь возникает главная задача трейдера: зная данные о торгах за определенный промежуток времени (статистику),спрогнозировать поведение цен(курса) на следующий период времени (получить вероятность), и на основании этого принять решение о покупке или продаже."
еще одно утверждение по смыслу не далеко ушло от бреда. Для того чтобы что то прогнозировать. нужно с начало доказать самому себе что ряд не случаен и подается прогнозу. Можно иметь доход и на случайных рядах. их нельзя прогнозировать но можно вытащить из них. ассиметрию вероятности и положительное/отрицательное мат ожидание.