
자동 거래 시스템(Automata-Based Programming)을 위한 새로운 접근 방식
ἓν οἶδα ὅτι οὐδὲν οἶδα ( ο φιλόσοφος Σωκράτης )
나는 아무것도 모른다는 걸 알아요 (철학자 소크라테스)
개요
우선, 이 주제는 MetaQuotes Language 4/5(MQL4/5)를 사용하는 EA를 개발하는 트레이더에게 완전히 새로운 주제입니다. 저는 MetaQuotes 사이트에서 관련 검색을 시도했을 때 직접 확인할 수 있었습니다. 이 주제에 대해서는 아무것도 없어요.
모든 거래자는 프로그램 및 매우 복잡한 프로그램 논리와 관련된 모든 문제를 해결하기 위한 진지한 접근 방식을 필요로 하는 자체 Expert Advisor를 만듭니다. 결국, 프로그램은 어떤 표준에서든 시계처럼 스스로 실행되어 불가항력적인 상황을 초래하게 됩니다.
하지만 어떻게 모든 것을 포용할 수 있을까요? 이는 매우 어려운 문제이며, 따라서 자동 제어 시스템은 유일하게 적절한 자동 데이터 기반 프로그래밍 기술을 사용하여 가장 잘 달성할 수 있는 모든 제어 시스템을 적절하게 프로그래밍해야 합니다. 최근 몇 년 동안 소프트웨어 품질에 대한 높은 요구사항을 설정하는 임베디드 및 실시간 시스템용 프로그래밍 기술 개발에 관심이 집중되고 있습니다.
1991년, 러시아 작가 A.A. Shalyto(강사, 교수, 엔지니어링 DSc, SPbSU ITMO의 "프로그래밍 기술" 부서장)는 그가 "자동 데이터 기반 프로그래밍"이라고 부르는 프로그래밍 기술을 개발했습니다. 저는 독자들이 그것이 얼마나 간단한 자동 데이터 기반 프로그래밍이나 스위치 기술이 될 수 있는지 보는 것을 흥미로워할 것이라고 생각합니다. MTS의 개발을 MetaQuotes Language로 편리하게 할 수 있어 더할 나위 없이 편리합니다. 복잡한 의사 결정 시스템과 잘 어우러집니다.
1. 문제 인식
모든 문제 발생자와 소프트웨어 개발자의 오랜 꿈은 문제에 대한 계획된 솔루션(알고리즘)과 이 알고리즘의 구현이 완전히 일치하는 것입니다. 하지만 문제 발생자와 개발자들에게는 그렇게 되지 않는 것 같습니다. 알고리즘은 구현에 있어 개발자에게 중요한 것을 생략하는 경향이 있지만 프로그램 텍스트 자체는 알고리즘과 거의 유사하지 않습니다.
따라서 두 가지 알고리즘이 있습니다. 하나는 특정 결과를 얻기 위해 사용되는 방법 대신 일반적으로 특정 설계 결과를 나타내는 (설계 솔루션을 기록하고 문서화하기 위한) 알고리즘이고, 두 번째 알고리즘은 개발자의 마음에 있습니다(단, 텍스트로 저장됨).
프로그램 텍스트의 최종 버전은 종종 문서를 수정하려는 시도가 뒤따르지만, 다시 많은 사항이 고려되지는 않습니다. 이 경우 프로그램 로직이 알고리즘의 로직과 아마도 다를 수 있으므로 대응성이 없음을 나타냅니다. 제가 일부러 '아마도'라고 말하는 이유는 아무도 누군가의 프로그램 문자를 확인하지 않기 때문입니다.
프로그램이 크면 텍스트만으로는 알고리즘과 일치하는지 확인할 수 없습니다. 구현의 정확성은 '테스트'라는 절차를 사용하여 확인할 수 있습니다. 기본적으로 개발자가 알고리즘을 파악(서류상으로 배치)하여 마음속으로 다른 알고리즘으로 변환한 후 프로그램으로 출력하는 방법을 확인합니다. 결국, 개발자는 구현이 전혀 무관해지기 전에 만들어진 논리와 모든 것에 대한 귀중한 정보를 가진 유일한 보유자입니다.
개발자는 병에 걸릴 수도 없습니다 (또는... 사임하겠죠). 핵심은 개발자의 지능과 프로그래밍 언어에 대한 지식에 따라 기본적인 프로그램 로직이 달라질 수 있다는 것입니다. 어쨌든 개발자는 적합하다고 생각되는 중간 변수를 많이 도입하고 사용합니다. 그리고 프로그램이 크고 논리적으로 복잡하다면, 보다 자격을 갖춘 전문가가 결함(여기서는 OS 결함이나 잘못된 언어 기능의 사용을 의미하는 것이 아니라 논리적인 측면에서 부적절하게 구현된 것)을 찾는 것이 필요하고, 프로그램 텍스트 자체를 통해 해결해야 합니다.
개발자의 대다수는 프로그래밍(또는 종이에 스케치)하기 전에 알고리즘을 작성하는 데 관심이 없으며, 이는 개발 과정에서 여전히 자신만의 무언가를 생각해야 하기 때문일 수 있습니다. 실제로 프로그래밍을 즉시 진행하고 문서화에서 다소 유사하거나 매우 일반적인 알고리즘을 배치하는 것이 더 나은데 왜 사각형, 다이아몬드 및 화살표를 그리는 데 시간을 낭비해야 하나요?
E모든 사람이 익숙해져 있습니다. 개발자는 이 방법이 더 쉽기 때문에 그렇게 하는 반면, 문제 발생자는 항상 필요한 수준의 프로그래밍 기술을 가지고 있는 것은 아니며, 프로그래밍 기술을 보유하고 있더라도 개발자가 어떤 기술을 개발할지 시기적절하게 변경할 수 없습니다. 편리한 프로그래밍 환경은 또한 지정된 개발 순서의 유효성에 기여합니다. 변수의 디버깅 및 모니터링 값을 위한 고급 도구를 통해 로직의 오류를 감지할 수 있습니다.
시간이 많이 걸리고 프로젝트 마감일이 다가옴에 따라 개발자는 주어진 논리적 문제에 대한 '냅킨' 솔루션을 구상하고 있습니다. 테스트 도중 간과된 오류는 말할 것도 없고 거의 동일한 시나리오(혼돈)를 따르고 있습니다. 이것이 현재 상황입니다. 해결책이 있나요 아니면 적어도 개선될 수 있나요? 표준 방식으로 배치된 알고리즘에서 프로그램 코드로 전환하는 과정에서 중요한 무언가가 손실되는 느낌입니다.
2. 프로그램의 논리적 부분
"자동 데이터 기반 프로그래밍"의 저자는 프로그램의 이상적인 논리적 부분에 대한 다음과 같은 개념을 제안했습니다. 프로그램의 전체 논리는 스위치를 기반으로 합니다. 간단히 말해 다음과 같이 모든 제어 알고리즘(자동화)을 구현할 수 있습니다(이 시점에서는 주석의 의미에 대해 크게 생각하지 말고 구조를 살펴보기만 하면 됩니다).
switch(int STATUS ) // Мulti-valued global state variable of the automaton. { case 0: // start // Checking arc and loop conditions (in order of priority), // transition (change of the value of the variable STATUS) // and execution of arc and loop actions (output function execution); // logging transitions and actions if the condition is met. 0 // Calling nested automata. // Execution of output functions in the state. break ; case 1: // Checking arc and loop conditions (in order of priority), // transition (change of the value of the variable STATUS) // and execution of arc and loop actions (output function execution); // logging transitions and actions if the condition is met. // Calling nested automata. // Execution of output functions in the state. break ; ********* ********* ********* case N-1: // Checking arc and loop conditions (in order of priority), // transition (change of the value of the variable STATUS) // and execution of arc and loop actions (output function execution); // logging transitions and actions if the condition is met. // Calling nested automata. // Execution of output functions in the state. break ; case N: // Checking arc and loop conditions (in order of priority), // transition (change of the value of the variable STATUS) // and execution of arc and loop actions (output function execution); // logging transitions and actions if the condition is met. // Calling nested automata. // Execution of output functions in the state. break ; }
3. 저자(A.A. Shalyto)의 설명에 따른 자동 데이터 기반 프로그래밍입니다. 저자: Shalyto
개발 기법과 상관없이, 모든 프로그램은 특정 시간에 모든 데이터 값에 따라 상태를 결정합니다. 대규모 응용프로그램 프로그램에는 수백, 수천 개의 변수와 여러 개의 제어 흐름이 있을 수 있습니다. 이러한 변수의 전체 집합은 특정 시간에 응용 프로그램 상태를 나타냅니다.
프로그램 상태는 모든 전환 조건에 포함되는 모든 제어 변수의 값 집합으로 보다 간단하게 처리할 수 있습니다. 제어 변수 중 하나의 값이 변경되면 프로그램 상태가 변경됨을 의미하며 프로그램 작동 중에 발생할 수 있는 최대 제어 변수 값의 조합 수에 따라 프로그램 상태 수가 결정됩니다. 프로그램에 이항 제어 변수(플래그)만 사용된다고 가정합니다. 이 경우 n개의 이진 제어 변수를 포함하는 프로그램의 상태 수는 n ~ 2n 범위 내에 있습니다.
개발자가 모든 제어 변수 값 조합(이 경우, 2n 조합)에 대한 반응을 제공했을 수 있습니다. 그러나 일부 제어 변수 값 조합(최대 2n-n) 이 지정되지 않았을 가능성이 높습니다. 그런 다음 예상치 못한 입력 동작 조합이 발생하면 프로그램이 지정되지 않은 상태로 전환될 수 있습니다.
이는 다음과 같은 경우에 거래자에 대한 EA의 무반응과 동일한 영향을 미칩니다:
- 갭,
- 보증금 손실,
- 후속 마진 콜과 함께 부정적인 균형 상황에 빠지는 것,
- 좋은 이익을 얻지 못하고 적자(혹은, 제로 이하)로 돌아가는 것,
- 긴 길이와 짧은 길이의 부정확한 열림과 닫힘,
- 기타 다른 명백한 불리한 상황들.
이러한 상태를 "시각화되지 않음"이라고 합니다. 복잡성으로 인해 프로그램의 모든 가능한 상태를 열거하는 것은 어렵고, 신뢰할 수 없습니다... 구조의 복잡성은 보안 트랩 도어를 구성하는 시각화되지 않은 상태의 원인입니다. 지정되지 않은 상태의 프로그램 동작은 메모리 보호 장애에서 프로그램을 새로운 기능으로 확장하고 다양한 성격의 부작용을 만드는 데 이르기까지 다양할 수 있습니다.
많은 PC 사용자와 모든 소프트웨어 개발자는 사용 중이거나 개발 중인 프로그램이 지정되지 않은 상태에 빠지는 상황을 자주 접하게 됩니다.
프로그램에서 지정되지 않은 상태가 발생할 가능성을 없애려면 설계 단계에서 필요한 모든 상태를 명시적으로 지정해야 하며 이러한 상태를 구별하는 데는 다중 값 제어 변수 하나만 사용해야 합니다. 그런 다음 주 간에 발생할 수 있는 모든 전환을 식별하고 프로그램을 개발하여 '오류화'되지 않도록 해야 합니다.
프로그램 동작의 개발에 있어 엄격함을 달성하기 위해서는 세 가지 구성요소가 필요합니다.
- 프로그램 상태와 프로그램 간의 가능한 전환을 명확하게 식별할 수 있는 수학적 모델입니다.
- 해당 모델에 대한 그래픽 표기법;
- 이 표기법으로 표현된 알고리즘의 구현을 위한 보편적인 방법입니다.
"상태"의 개념에 기초한 유한 자동화가 수학적 모델로 사용될 것을 제안합니다. 자동 데이터 기반 프로그래밍은 설계, 구현, 디버깅 및 문서화와 같은 소프트웨어 개발 단계를 지원합니다.
최근 몇 년 동안 프로그래밍에서 흔히 사용되는 용어인 'event'(이벤트)가 있지만, 제안된 접근법은 'state'(상태)의 개념에 기초하고 있습니다. 입력 변수 또는 이벤트일 수 있는 용어 'input action'(입력 액션)과 결합하면, 'automaton without output'(출력 없는 자동장치) 이라는 용어를 도입할 수 있습니다. 후자에는'output action'(출력작용) 이라는 용어가 뒤따르고 (결정론적 유한) automaton(자동화)의 개념이 추가로 도입되었습니다. 따라서 이러한 개념에 기초한 프로그래밍 영역을 자동 데이터 기반 프로그래밍이라고 하며 각 개발 프로세스를 자동 데이터 기반 프로그램 설계라고 합니다.
지정된 접근 방식은 적용 시 자동 데이터가 전환 그래프로 표현된다는 점에서 특이합니다. 해당 노드를 구별하기 위해 'state assignment'(상태 할당) 이라는 용어가 도입되었습니다. '다중값 상태 할당'을 선택할 때 선택한 변수가 취할 수 있는 값의 수와 일치하는 상태는 하나의 변수만 사용하여 구별할 수 있습니다. 이러한 사실은 프로그래밍에 '프로그램 관찰성'이라는 용어를 도입할 수 있게 했습니다.
제안된 접근법에 따른 프로그래밍은 문제와 구성 요소를 더 잘 이해하고 지정하는 데 도움이 되는 '변수'(플래그)가 아닌 '상태'를 통해 수행됩니다. 이 경우 디버깅은 자동 데이터 측면에서 로그인을 통해 수행됩니다.
위의 접근방식은 형식적이고 동형적인 방법을 사용하여 전환 그래프에서 프로그램 코드로 이동할 것을 제안하므로, 고급 프로그래밍 언어를 사용할 때 스위치 구조를 적용하는 것이 더 합리적인 것으로 보입니다. 그래서 'SWITCH-Technology'라는 용어를 자동화 기반 프로그래밍 패러다임을 지칭할 때 사용하기로 했습니다.
4. 명시적 상태 기반 프로그래밍
오토마타(자동화-automata) 기반 접근 방식의 적용은 '대응형'이라고도 불리는 이벤트 기반 시스템으로 더욱 확대되었습니다. 반응형 시스템은 환경에 의해 설정된 속도로 메시지를 사용하여 환경과 상호 작용합니다(EA는 동일한 클래스에 포함될 수 있음).
오토마타를 이용한 이벤트 기반 시스템의 개발은, 그 이름인 명시적 상태 기반 프로그래밍이 유래한 절차적 접근법을 채택함으로써 가능했습니다. 출력 동작은 이 방법에서 전환 그래프의 호, 루프 또는 노드에 할당됩니다(혼합 오토마타 - Moore 및 Maly automata - 사용). 이를 통해 관련 입력 작업에 대한 반응으로 일련의 작업을 간결하게 표시할 수 있습니다.
주어진 시스템 클래스를 프로그래밍하기 위해 제안된 접근 방식은 이벤트 핸들러에서 제거되고 핸들러에서 호출되는 상호 연결된 자동 데이터 시스템의 생성으로 인해 로직의 중앙 집중화가 향상되었습니다. 이러한 시스템에서 자동 데이터 간의 상호 작용은 내포, 호출 및 상태 번호 교환을 통해 달성할 수 있습니다.
상호 연결된 자동 데이터의 시스템은 시스템 독립적인 프로그램 부분을 구성하는 반면, 시스템 종속 부분은 입력 및 출력 동작 기능, 핸들러 등에 의해 형성됩니다.
주어진 접근 방식의 또 다른 주요 특징은 자동 데이터를 적용할 때 다음과 같은 3가지 방식으로 사용한다는 것입니다:
- 사양에 따라서;
- 구현 방식 (프로그램 코드에 남아 있음);
- 자동 데이터에 대한 로깅 (위에서 지정한 대로).
후자를 통해 자동 데이터 시스템 작동의 정확도를 제어할 수 있습니다. 로깅은 개발된 프로그램을 기반으로 자동으로 수행되며 복잡한 프로그램 로직의 대규모 문제에 사용될 수 있습니다. 이 경우 모든 로그를 관련 스크립트로 간주할 수 있습니다.
로그를 통해 작동 중인 프로그램을 모니터링하고 오토마타가 '그림'이 아니라 실제 활성 엔터티라는 사실을 확인할 수 있습니다. 자동 데이터 기반 접근 방식은 제어 시스템을 만들 때뿐만 아니라 제어 객체를 모델링할 때도 사용할 수 있도록 제안됩니다.
5. 자동 데이터 기반 프로그래밍의 기본 개념
자동 데이터 기반 프로그래밍의 기본 개념은 STATE(상태)입니다. 특정 시간 t0의 시스템 상태의 주요 속성은 현재 상태가 특정 시간 t0에 생성된 모든 입력 작업에 대한 반응을 결정하는 데 필요한 시스템의 과거에 대한 모든 정보를 포함한다는 의미에서 미래(t > t0)와 과거(t < t0)를 '분리'하는 것입니다.
용어 STATE를 사용하는 경우, 상태 기록 데이터에 대한 지식이 필요하지 않습니다. 상태는 현재 엔터티(독립체)의 반응에 영향을 미치는 과거의 모든 투입 행동을 암묵적으로 결합하는 특수한 특성으로 간주할 수 있습니다. 이제 반응은 입력 동작과 현재 상태에 따라서만 달라집니다.
또한 자동 데이터 기반 프로그래밍의 핵심 개념 중 하나는 '입력 동작' 입니다. 입력 동작은 가장 일반적으로 벡터입니다. 이것의 구성요소는 의미와 생성 메커니즘에 따라 이벤트와 입력 변수로 나뉩니다.
유한 상태 집합과 유한 입력 동작 집합의 조합은 출력이 없는 (유한) 자동을 형성합니다. 이러한 자동화는 입력 동작에 대해 특정 방식으로 현재 상태를 변경함으로써 반응합니다. 상태를 변경할 수 있는 규칙을 자동 전환 함수라고 합니다.
오토마톤(자동화) 기반 프로그래밍에서 (유한) 자동이라고 하는 것은 기본적으로 '출력없는 자동화'와 '입력 동작'의 조합입니다. 이러한 자동화는 입력 동작의 상태 변경뿐만 아니라 출력 시 특정 값을 생성함으로써 반응합니다. 출력 작업을 생성하는 규칙을 자동화 출력 함수라고 합니다.
복잡한 동작을 하는 시스템을 설계할 때는 특정 작업 집합과 외부(마켓) 환경에서 발생할 수 있는 이벤트 집합을 사용하여 기존 제어 개체를 출발점으로 삼아야 합니다.
실제로 설계는 일반적으로 제어 객체 및 이벤트를 전제로 합니다.
-
문제의 초기 데이터는 단순히 시스템의 대상 동작을 구두로 설명하는 데 그치지 않고 외부 환경에서 시스템으로 들어오는 이벤트 집합과 모든 제어 객체의 수많은 요청 및 명령의 정확한 사양입니다.
-
제어 상태 집합이 작성됩니다.
-
제어 객체의 모든 요청에는 자동의 해당 입력 변수가 할당되고 모든 명령에는 해당 출력 변수가 할당됩니다. 필요한 시스템 동작을 보장하는 자동화는 제어 상태, 이벤트, 입력 및 출력 변수를 기반으로 구축됩니다.
6. 프로그램 특징 및 장점
자동화 기반 프로그램의 첫 번째 특징은 외부 루프의 존재가 필수적이라는 것입니다. 기본적으로 새로운 것은 없어 보입니다. 여기서 가장 중요한 것은 이 루프가 전체 프로그램의 유일한 논리적 부분이라는 것입니다. (i.e. 새로 들어오는 틱.)
두 번째 기능은 첫 번째 기능부터 이어집니다. 모든 자동에는 모든 논리적 연산으로 구성된 스위치 구조(사실상, 가상적인 구조)가 포함되어 있습니다. 자동화가 호출되면 컨트롤이 '케이스' 레이블 중 하나로 전송되고 관련 작업에 따라 다음 시작 시까지 자동(하위 프로그램) 작동이 완료됩니다. 이러한 작업은 전환 조건을 확인하는 작업으로 구성되며 특정 조건이 충족되면 관련 출력 기능이 호출되고 자동 상태가 변경됩니다.
위에서 언급한 모든 것의 주요 결과는 자동화의 구현이 단순할 뿐만 아니라 가장 중요한 것은 프로그램이 다중값 상태 변수에 의해 제공되는 많은 중간 논리 변수(플래그) 없이 수행할 수 있다는 것입니다.
글로벌 변수(플래그)와 로컬 변수(플래그)를 너무 많이 생각하지 않고 사용하는 것에 익숙해져 마지막 문장은 신뢰하기 어렵습니다. 그들이 없이 어떻게 할까요? 이러한 플래그는 프로그램에게 조건이 충족되었음을 알리는 플래그입니다. 개발자가 필요하다고 판단하지만 프로그램의 다른 곳에서 FALSE로 재설정하려고 할 때(일반적으로 플래그가 항상 TRUE가 되어 원하는 효과를 얻기 시작한 후에만) 플래그가 설정됩니다. (TRUE로 설정됨)
친숙합니다, 그렇죠? 이제 예제를 살펴본 후 다음을 참조하십시오. 추가 변수는 여기에 사용되지 않습니다. 변경은 상태 번호의 값과 논리적 조건이 충족되는 경우에만 적용됩니다. 플래그를 대신할 만한 가치가 있지 않나요?
알고리즘은 프로그램의 논리적 부분을 만드는 데 중요한 역할을 합니다. 여기서 기억해야 할 핵심 구절은 '논리 파트'입니다. 이 경우 상태(state)는 모든 것을 뒷받침합니다. 또 다른 추가되어야 할 단어는 '기다림'입니다. 그리고 제 생각에 우리는 '대기 상태'에 대한 꽤 적절한 정의를 얻었습니다. 상태가 되면 입력 작업(속성, 값 또는 이벤트)이 나타날 때까지 기다립니다. 기다리는 시간은 짧을 수도 있고 길 수도 있습니다. 다시 말해, 불안정하고 안정적인 상태가 있을 수 있습니다.
상태의 첫 번째 속성 은 제한된 입력 작업 집합이 그 상태에서 대기된다는 사실입니다. 모든 알고리즘(및 분명히 모든 프로그램)에는 입력 및 출력 정보가 있습니다. 출력 동작은 변수(예: 객체 속성 작업)와 함수(예: 애플리케이션 시작 함수 호출, 보고서 함수 등)의 두 가지 유형으로 나눌 수 있습니다.
상태의 두 번째 속성은 출력 변수의 정확한 값 집합을 제공하는 것입니다. 이는 매우 간단하지만 매우 중요한 상황을 나타냅니다. 알고리즘(프로그램)이 매 시점에서 특정 상태에 있으므로 모든 출력 변수 값은 언제든지 확인할 수 있습니다.
상태 수는 출력 변수 값의 수와 마찬가지로 제한됩니다. 전환 로깅 기능은 자동 함수와 상태 간 전환 시퀀스에 원활하게 통합되어 있으며, 결과적으로 출력 작업 전달도 항상 결정될 수 있습니다.
기능의 전체 목록은 섹션 2. 제안된 기술의 기능, 전체 장점 목록은 섹션 3. 제안된 기술의 장점에서 확인할 수 있습니다. 이 기사에서는 주제에 대한 방대한 정보를 다룰 수 없습니다! Anatoly Shalyto가 작성한 모든 연구 문헌을 철저히 검토한 후, 모든 이론적 질문은 개인적으로 shalyto@mail.ifmo.ru으로 합니다.
그리고 우리의 목표와 문제점을 염두에 두고 그의 과학적 아이디어를 사용하는 사람으로서, 저는 자동화 기반 프로그래밍 기술을 구현한 세 가지 예를 아래에 더 설명하겠습니다.
7. 자동 데이터 기반 프로그래밍의 예
7.1. 이해를 위한 예시
상태는 시스템이 존재하는 모드일 뿐입니다. 예를 들어, 물은 고체, 액체 또는 기체의 3가지 상태로 존재합니다. 온도 변수(고정 압력)의 영향을 받으면 한 상태에서 다른 상태로 전환됩니다.
시간 기반 온도(t) 관리도가 있다고 가정합니다(이 경우 - 가격 값):

int STATUS=0; // a global integer is by all means always a variable !!! STATUS is a multi-valued flag //----------------------------------------------------------------------------------------------// int start() // outer loop is a must { switch(STATUS) { case 0: //--- start state of the program if(T>0 && T<100) STATUS=1; if(T>=100) STATUS=2; if(T<=0) STATUS=3; break; case 1: //--- liquid // set of calculations or actions in this situation (repeating the 1st status -- a loop in automata-based programming) // // and calls of other nested automata A4, A5; if(T>=100 ) { STATUS=2; /* set of actions when transitioning, calls of other nested automata A2, A3;*/} if(T<0) { STATUS=3; /* set of actions when transitioning, calls of other nested automata A2, A3;*/} // logging transitions and actions when the condition is met. break; case 2: //--- gas // set of calculations or actions in this situation (repeating the 2nd status -- a loop in automata-based programming) // // and calls of other nested automata A4, A5; if(T>0 && T<100) { STATUS=1; /* set of actions when transitioning, calls of other nested automata A2, A3;*/} if(T<=0) { STATUS=3; /* set of actions when transitioning, calls of other nested automata A2, A3;*/} // logging transitions and actions when the condition is met. break; case 3: //--- solid // set of calculations or actions in this situation (repeating the 3rd status -- a loop in automata-based programming) // // and calls of other nested automata A4, A5; if(T>0 && T<100) {STATUS=1; /* set of actions when transitioning, calls of other nested automata A2, A3;*/} if(T>=100) {STATUS=2; /* set of actions when transitioning, calls of other nested automata A2, A3;*/} // logging transitions and actions when the condition is met. break; } return(0); }
압력 매개 변수 P와 새 상태를 추가하고 차트에 설명된 복잡한 종속성을 도입하여 프로그램을 보다 정교하게 만들 수 있습니다.

이 자동 시스템은 32 = 9 전환 조건을 갖추고 있어 어떤 것도 빠뜨리거나 간과할 수 없습니다. 이 스타일은 또한 지침서와 법률을 작성할 때 매우 편리할 수 있습니다! 여기에는 허점이나 법 위반이 허용되지 않습니다 - 일련의 사건들을 모두 다루고 모든 사례를 설명해야 합니다.
자동 데이터 기반 프로그래밍은 우리에게 모든 것을 고려해야 합니다. 그렇지 않으면 일련의 일련의 사건들이 고려되지 않을지라도, 이것이 법률, 지침 및 제어 시스템의 일관성 및 무결성을 확인할 때 주요한 도구인 이유입니다. 수학 법칙도 있습니다:
전환 다이어그램: N= 3 상태, 전환 및 루프 수는 N2 = 9 (화살표 수와 같음)입니다.
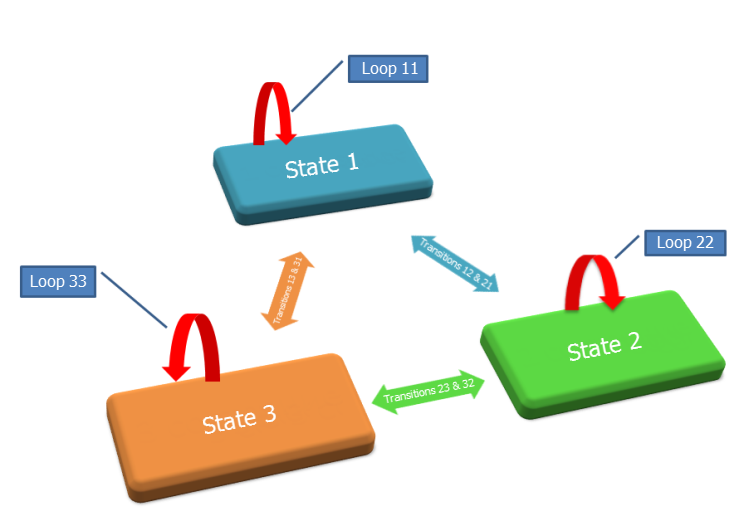
예제에서 변수 수가 다르면 다음과 같습니다:
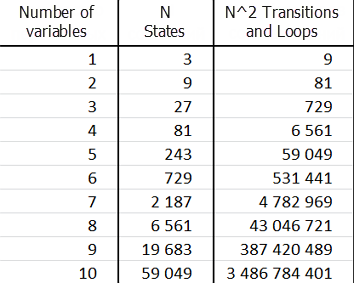
이것은 표의 계산된 모든 값이 기하급수적으로 지수 상승한다는 것을 보여줍니다. 즉, 설계는 주요 시스템 변수를 선택할 때 철저함을 요구하는 복잡한 프로세스입니다.
매개 변수가 두 개뿐이라고 해도 모든 것을 설명하는 것은 매우 어렵습니다! 하지만 실제로는 모든 것이 훨씬 더 쉽습니다! 논리 및 의미에 따라 50-95% 전환은 물리적으로 존재할 수 없으며 상태 수도 60-95% 줄어듭니다. 이러한 논리 및 의미 분석은 모든 전환과 상태를 설명하는 어려움을 크게 줄여줍니다.
좀 더 복잡한 경우에는 EA의 알려진 모든 입력 및 출력 데이터에 대한 최대 상태 수를 계산해야 합니다. 이 문제에 대한 해결책은 조합론 및 조합, 순열, 배열, 숫자 조합 공식을 적용하여 찾을 수 있습니다.
7.2. 이력이 있는 릴레이
EA에서는 릴레이, 트리거, 레지스터, 카운터, 디코더, 비교기 및 기타 비선형 디지털 및 아날로그 제어 시스템 요소의 프로그래밍이 매우 편리할 수 있습니다.

- xmax = 100 - 최대 픽업 값;
- xmin = -100 - 최소 픽업 값;
- x = x(t) - 입력 시 신호;
- Y = Y(t) - 출력 시 신호.
int status=0; // at the beginning of the program we globally assign //------------------------------------------------------------------// switch(status) { case 0: // start Y=x; if(x>xmax) {status=1;} if(x<xmin) {status=2;} break; case 1: //++++++++++++++++++++ if(x>xmax) Y=x; if(x<xmax) Y=xmin; if(x<=xmin) {status=2; Y=xmin;} break; case 2: //-------------------- if(x<xmin) Y=x; if(x>xmin) Y=xmax; if(x>=xmax) {status=1; Y=xmax;} break; }
릴레이 특성:
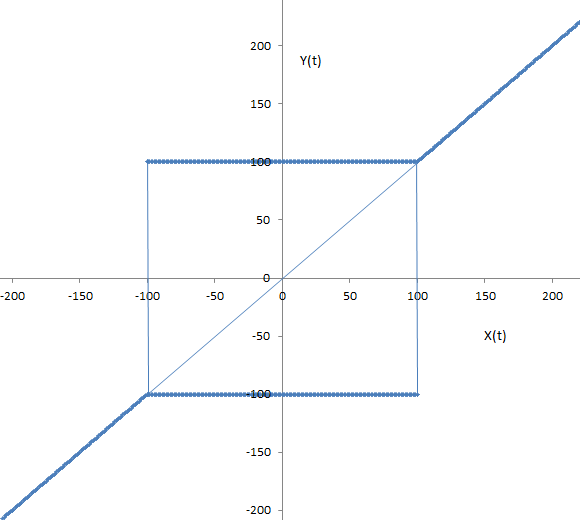
7.3. 9개 상태 및 81개 이벤트 연속 변형 템플릿
Y는 1부터 9까지의 자동 입력 상태입니다. Y 값은 지정된 하위 프로그램 외부의 EA에서 생성됩니다. MEGASTATUS 는 Y의 과거 상태입니다.
int MEGASTATUS=0; // at the beginning of the program we globally assign //---------------------------------------------------------------------// void A0(int Y) // automaton template { switch(MEGASTATUS) { case 0: // start MEGASTATUS=Y; break; case 1: // it was the past // it became current, repeating if(Y=1) { /*set of actions in this situation, calls of other nested automata A2, A3, ... */ } // Loop// // new current if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 2: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } //Loop// if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } // e.g. if the transition from 2 to 6 is in essence impossible or does not exist, do not write anything if(Y=6) { /* set of actions in this situation */ } // the automaton will then be reduced but the automaton template shall be complete to count in everything if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 3: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } //Loop// if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 4: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } //Loop// if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 5: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } //Loop// if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 6: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } //Loop// if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 7: // it was the past //it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } //Loop// if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 8: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } //Loop// if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 9: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } //Loop// // logging transitions and actions when the condition is met. break; } MEGASTATUS=Y; }
7.4. 오디오 플레이어 자동화
심플 오디오 플레이어를 검토해 보겠습니다.
이 장치는 다음 6개 상태에 있을 수 있습니다:
- 준비;
- 트랙 없음;
- 재생중;
- 빨리 감기;
- 되감기;
- 멈춤.
오디오 플레이어 제어 시스템은 자동으로 표시됩니다. 버튼을 누르면 자동화에 영향을 미치는 이벤트로 간주됩니다. 트랙 간 전환, 재생, 디스플레이 제어 등은 출력 동작입니다.
switch(STATUS) { case 0: //--- "Ready" if(Event == 3) { STATUS = 3; } //«>>» button pressed if(Event == 6) { STATUS = 1; } //Audio file not found if(Event == 1) { STATUS = 2; } //«PLAY» button pressed z1(); // Set the indicator to the initial state break; case 1: //--- "No Track" z6(); // Give the «No Track» message break; case 2: //--- "Playing" if(Event == 4) { STATUS = 4; } //«<<» button pressed if(Event == 5) { STATUS = 5; } //«PAUSE»( | | ) button pressed if(Event == 3) { STATUS = 3; } //«>>» button pressed if(Event == 2) { STATUS = 0; } //«STOP» button pressed z2(); // Playing break; case 3: //--- "Fast-Forward" z3(); // Next track { STATUS=2; } break; case 4: //--- "Rewind" z4(); // Previous track { STATUS=2; } break; case 5: //--- "Pause" if(Event == 5) { STATUS = 2; } //«PAUSE» button pressed if(Event == 1) { STATUS = 2; } //«PLAY» button pressed if(Event == 2) { STATUS = 0; } //«STOP» button pressed if(Event == 3) { STATUS = 3; } //«>>» button pressed if(Event == 4) { STATUS = 4; } //«<<» button pressed z5(); //Pause break; }
이론적으로 이 자동화는 36가지 전환 변형을 포함할 수 있지만, 실제 존재하는 것은 15가지뿐이며 모든 세부 사항은 저자가 제공한 설명에서 찾을 수 있습니다.
8. А.А. 프로젝트 실행에 대한 샬리토(Shalyto)의 권고 사항
프로젝트 문서를 준비하고 작성하는 방법에 대한 전체 정보는 http://project.ifmo.ru/books/3에서 확인할 수 있으며, 이 기사에서는 간단한 발췌만 제공합니다:
- 책 А.А. Shalyto "로직 컨트롤. 하드웨어 및 소프트웨어 알고리즘 구현 방법 SPb.: Nauka, 2000", "책" 섹션의 지정된 웹 사이트에서 사용할 수 있으며 프로토타입으로 사용할 수 있습니다". 러시아에서 가장 오래되고 평판이 좋은 출판사에서 출판한 정보로서 적절한 프레젠테이션을 구현하고 있습니다.
- 서론은 선택한 과목의 관련성에 대한 근거를 제시해야 하며, 고려 중인 문제를 간략하게 기술하고 프로젝트에 사용되는 프로그래밍 언어와 운영 체제를 명시해야 합니다.
- 당면한 문제에 대한 자세한 구두 설명은 "문제 설명" 섹션에 기술된 문제를 명확히 하는 그림, 다이어그램 및 스크린샷과 함께 제공되어야 합니다.
- 객체 지향 프로그래밍을 사용할 때 "디자인" 섹션에는 클래스 다이어그램이 포함되어야 합니다. 주요 클래스는 주의 깊게 설명되어야 합니다. "클래스의 블록 다이어그램"은 자동 데이터 기반 방법 표시와 함께 사용되는 인터페이스 및 방법을 제시하는 것을 목표로 각 항목에 대해 작성되는 것이 좋습니다.
- "자동화" 섹션의 모든 자동화에 대해 구두 설명, 자동 링크 다이어그램 및 전환 그래프의 세 가지 문서가 제공되어야 합니다.
- 구두 설명은 상당히 상세해야 하지만 복잡한 자동화의 행동을 명확하게 설명하기 어렵다는 점을 감안할 때, 일반적으로 "의향 선언"을 나타냅니다.
- 자동 링크 다이어그램은 인터페이스에 대한 자세한 설명을 제공합니다. 다이어그램의 왼쪽 부분에 다음과 같은 특징이 있어야 합니다:
- 데이터 원본;
- 모든 입력 변수의 풀네임;
- 모든 이벤트의 풀네임;
- 정된 자동에서 입력 작업으로 사용되는 다른 자동 데이터의 상태 번호를 사용하여 술어를 나타냅니다. E.g. the Y8 == 6 술어는 여덟 번째 자동 전환이 여섯 번째 상태로 전환되면 동일한 값으로 사용될 수 있습니다;
- 입력 변수는 관련 지수와 함께 x로 표시됩니다;
- 관련 지수로 표시된 이벤트입니다;
- 숫자 N (YN으로 표시됨)을 사용하여 자동 상태를 저장하기 위한 변수입니다.
다이어그램의 오른쪽 부분에 다음과 같은 특징이 있어야 합니다:- 관련 지수를 사용하여 z로 표시된 출력 변수입니다;
- 모든 출력 변수의 풀네임;
- 지정된 자동화(있는 경우)에 의해 발생한 이벤트;
- 생성된 모든 이벤트의 풀네임;
- 데이터 수신기.
- 노드 또는 전환에서 복잡한 계산 알고리즘을 사용하는 경우 "전산 알고리즘" 섹션은 알고리즘의 선택 사항을 설명하고 해당 설명(수학 설명 포함)을 제공합니다. 이러한 알고리즘은 입력 또는 출력에서 계산되는지 여부에 따라 변수 x와 z로 지정됩니다.
- 프로그램 구현의 특징은 "구현" 섹션에 명시되어 있어야 합니다. 특히 자동화의 공식적이고 동형적인 구현을 위한 템플릿을 제시해야 합니다. 여기에 자동 데이터 구현도 제공되어야 합니다.
- "결론"에서는 완료된 프로젝트의 이점과 단점을 다룹니다. 또한 프로젝트를 개선할 수 있는 방법을 제공할 수 있습니다.
9. 결론
여러분 모두 다음과 같이 하십시오:
- 프로그래밍에 대한 새로운 접근 방식을 살펴보십시오.
- 아이디어를 프로그래밍하고 거래 전략을 수립하는 완전히 새롭고 매우 흥미로운 접근 방식을 구현하십시오.
저는 자동 데이터 기반 프로그래밍이 다음과 같기를 바랍니다:
- 시간이 지남에 따라 모든 거래자와 심지어 MetaQuotes Language 개발자에게 프로그래밍과 디자인의 표준이 되었습니다.
- EA를 설계할 때 복잡한 의사결정의 기초가 됩니다.
- 미래에는 자동화 기반 프로그래밍 접근 방식을 지원하는 새로운 언어(MetaQuotes Language 6)와 새로운 플랫폼(MetaTrader 6)으로 발전합니다.
모든 거래 개발자가 이러한 프로그래밍 방식을 따를 경우 무손실 EA를 만들 수 있습니다. 이 첫 번째 기사는 새로운 발명과 발견에 대한 충동으로 자동차 기반 설계 및 프로그래밍 분야에서 창의성과 연구의 완전히 새로운 배출구를 보여주기 위한 시도입니다.
그리고 한 가지 더 - 저자의 기사에 전적으로 동의하며 간략한 형식으로 제공하는 것이 중요하다고 생각합니다. (여기 전체 기사를 확인하세요. http://is.ifmo.ru/works/open_doc/):
소스 코드가 프로그램을 이해하는 데 해결책이 되지 않는 이유
실용적인 프로그래밍의 중심 이슈는 프로그램 코드의 이해 문제입니다. 소스 코드를 가지고 있는 것이 항상 유익하지만, 문제는 이것이 종종 충분하지 않다는 것입니다. 그리고 각각의 프로그램을 이해하려면 보통 추가 문서가 필요합니다. 이러한 요구는 코드 양이 증가함에 따라 기하급수적으로 증가합니다.
개발자의 설계 결정 원상복구 및 프로그램 이해를 목적으로 하는 프로그램 코드 분석은 프로그램 이해에 대한 소스 코드의 부족과 함께 그 존재가 함께 하는 프로그래밍 기술의 두 가지 중요한 분야입니다.
주요 소프트웨어 재구성 프로젝트에 참여한 모든 사람은 잘못 작성된 소스 코드들을 처음 볼 때 나타나는 무력감과 곤혹스러움을 항상 기억할 것입니다. 주요 개발자에 대한 액세스가 없는 경우 소스 코드의 가용성은 큰 도움이 되지 않습니다. 프로그램이 비교적 낮은 수준의 언어로 작성되고 추가로 잘못 문서화된 경우, 모든 주요 설계 결정은 일반적으로 프로그래밍 세부사항에 분산되어 재구성이 필요합니다. 이와 같은 경우 인터페이스 사양 및 아키텍처 설명과 같은 상위 수준의 문서의 가치가 소스 코드 자체의 가치를 초과할 수 있습니다.
소스 코드가 프로그램을 이해하기에 불충분하다는 사실을 깨닫게 되면서 코드와 상위 수준의 문서를 결합하려는 시도가 생겼습니다.
프로젝트의 초기 단계를 놓칠 경우, 높은 수준의 문서가 없다는 전제 하에 복잡성과 작업량이 소스 코드를 사실상 '잠금' 상태로 만듭니다. 프로젝트를 처음 작업한 개발자가 없는 경우 또는 관련 아키텍처 결정을 분류할 수 있는 적절한 문서가 없는 경우 "선사적" 코드를 이해하는 것은 프로그래머들이 직면하는 가장 어려운 과제 중 하나일 것입니다.
프로그램에 설계가 부족한 이유
따라서 소스 코드의 부재는 좋지 않을 수 있지만, 소스 코드의 가용성은 마찬가지로 좋지 않을 수 있습니다. "평생 행복하게" 사는 데 아직도 부족한 게 뭐가 있을까요? 답은 간단합니다. 프로그램 설명서를 구성 요소 중 하나로 포함하는 상세하고 정확한 설계 문서입니다.
교량, 도로 및 고층건물은 서류 없이는 일반적으로 건설할 수 없습니다. 이는 프로그램에 대한 사실이 아닙니다.
프로그래밍에서 발생하는 상황은 다음과 같이 정의할 수 있습니다: "건축가들이 프로그래머들이 프로그램을 쓰는 방식으로 건물을 지으면, 최초의 딱따구리는 문명을 파괴할 것입니다."
하드웨어에 대해 상세하고 명확한 설계 문서가 많이 발행되고 발행된 지 몇 년이 지난 후에도 일반 전문가가 비교적 쉽게 이해하고 수정할 수 있는 이유는 무엇입니까? 그러나 이러한 문서는 소프트웨어에 존재하지 않거나 순전히 형식적인 방식으로 작성되었으며, 그것을 수정하기 위해 고도로 숙련된 전문가가 더 많이 필요한 이유는 무엇입니까(그러한 개발자가 없다면)?
이러한 상황은 다음과 같이 설명할 수 있습니다. 첫째, 하드웨어 개발과 제조는 서로 다른 조직에서 수행하는 두 가지 프로세스입니다. 따라서, 문서의 질이 좋지 않을 경우 개발 엔지니어는 평생을 '공장'에서 일하게 될 것입니다. 이는 분명히 그가 바라지 않을 것입니다. 소프트웨어 개발에 관한 한, 이 경우 소프트웨어 개발자와 제조업체 모두 일반적으로 동일한 회사이므로, 문서 목록과 상관없이, 이들의 콘텐츠는 매우 피상적입니다.
둘째, 하드웨어는 '하드'이고 소프트웨어는 '소프트'입니다. 프로그램을 쉽게 수정할 수 있지만 설계 문서를 함께 발행하지 않을 수 있는 근거가 되지는 않습니다. 대부분의 프로그래머는 병적으로 읽기를 꺼리고 문서화를 쓰는 것을 꺼리는 것으로 알려져 있습니다.
이러한 경험을 통해 새로 자격을 갖춘 프로그래머들, 심지어 가장 똑똑한 프로그래머들조차도 설계 문서를 준비할 수 없다는 것을 알 수 있습니다. 그리고 그들 중 다수가 길고 복잡한 수학 과목을 이수하고 통과했음에도 불구하고, 그것은 그들의 논리학이나 문서 작성의 엄격함에 거의 영향을 미치지 않습니다. 이들은 전체 문서(크기에 상관없이)에 동일한 하나와 동일한 것에 대해 서로 다른 표기법을 사용할 수 있으므로 전구, 불빛전구, 램프 또는 대문자 램프라고 부르며 원할 때마다 작은 문자나 대문자로 씁니다. 그들이 그들의 모든 것을 보여줄 때 어떤 일이 일어나는지 상상해 보세요!
분명히, 프로그래밍할 때 컴파일러는 아무런 프롬프트 없이 설계 문서를 작성하는 동안 불일치에 플래그를 지정하기 때문에 발생합니다.
소프트웨어 문서의 품질 문제는 사회적 중요성이 증가하는 문제로 대두되고 있습니다. 소프트웨어 개발은 강한 수익 동기로 쇼 비즈니스와 점차 비슷해지고 있습니다. 앞으로 제품이 어떻게 될지 생각하지 않고 모든 것이 미친 듯이 서둘러 이루어집니다. 쇼 비즈니스와 마찬가지로 프로그래밍은 "좋은 일 나쁜 일"보다는 "손익"의 관점에서 모든 것을 측정합니다. 대부분의 경우 좋은 기술은 실제로 좋은 것이 아니라 돈을 지불하는 것입니다.
설계 문서를 작성하기를 꺼리는 것은 아마도 프로젝트가 제한적일수록(문서화되지 않은), 설계 문서는 더 필수적이라는 사실과 관련이 있을 것입니다.
이러한 작업 동작은 유감스럽게도 매우 중요한 시스템용 소프트웨어 개발로까지 확대됩니다. 프로그램은 대부분 작성되고 설계되지 않은 것이 큰 원인입니다. "설계할 때 어떤 기술도 CRC cards보다 더 복잡하고, 또는 사례 다이어그램을 사용하는 것은 너무 복잡한 것으로 간주되어 사용되지 않습니다. 프로그래머는 상사에게 마감일을 맞추지 못할 수 있다고 보고함으로써 주어진 기술 적용을 언제든지 거부할 수 있습니다."
이로 인해 "사용자도 소프트웨어의 오류를 비정상적인 것으로 간주하지 않는" 상황이 발생합니다.
현재 소프트웨어가 아닌 대형 건축에 대해서는 설계와 적절한 문서가 마련되어야 한다고 널리 생각되고 있습니다.
결론적으로, 그러한 상황은 프로그래밍에 존재하지 않았다는 점에 유의해야 합니다. 초기 대규모 컴퓨터가 사용되던 시절에는 오류가 발생한 경우처럼 프로그램을 매우 신중하게 설계하거나 개발했으며, 다음 시도는 보통 하루 안에 이루어집니다. Th따라서 기술적인 발전으로 인해 프로그래밍의 신중성이 떨어졌습니다.
참고 자료
유감스럽게도 Shalyto의 연구소 홈페이지에서는 우리의 문제와 우려를 추적할 수 없습니다. Shalyto가 일하는 곳입니다. 그들은 그들만의 문제와 목표가 있고 우리의 개념과 정의를 전혀 모르고 전혀 알지 못하기 때문에 우리의 주제와 관련된 예는 없습니다.
주요 서적/교과서 A.A. Shalyto:
- 자동화 기반 프로그래밍. http://is.ifmo.ru/books/_book.pdf
- 로직 제어 알고리즘 구현에서 플로우 그래프 및 전환 그래프의 사용. http://is.ifmo.ru/download/gsgp.pdf
- 자동화 기반 프로그래밍. http://is.ifmo.ru/works/_2010_09_08_automata_progr.pdf
- 반복 알고리즘을 자동 데이터 기반 알고리즘으로 변환하기. http://is.ifmo.ru/download/iter.pdf
- 스위치-기술: 대응형 시스템용 소프트웨어 개발을 위한 자동 데이터 기반 접근 방식. http://is.ifmo.ru/download/switch.pdf
- 자동 데이터 기반 프로그램 설계. 로직 제어 문제의 알고리즘화 및 프로그래밍 http://is.ifmo.ru/download/app-aplu.pdf
- 유전자 알고리즘을 사용하여 단순화된 헬리콥터 모델의 자동 조종 설계. http://is.ifmo.ru/works/2008/Vestnik/53/05-genetic-helicopter.pdf
- 명시적 상태 기반 프로그래밍. http://is.ifmo.ru/download/mirpk1.pdf
- 로직 제어 및 반응 시스템을 위한 알고리즘 및 프로그래밍. http://is.ifmo.ru/download/arew.pdf
- 자동 데이터 기반 프로그래밍에 대한 객체 지향 접근 방식. http://is.ifmo.ru/works/ooaut.pdf
- 자동화 기반 클래스의 전달을 위한 그래픽 표기법. http://is.ifmo.ru/works/_12_12_2007_shopyrin.pdf
- 프로그래밍 시작... 1분. http://is.ifmo.ru/progeny/1minute/?i0=progeny&i1=1minute
프로젝트:
- ATMs 모델링 작동. http://is.ifmo.ru/unimod-projects/bankomat/
- 원자로 제어 프로세스 모델링. http://is.ifmo.ru/projects/reactor/
- 엘리베이터 제어 시스템. http://is.ifmo.ru/projects/elevator/
- 커피 메이커 제어 시스템의 자동화 기반 개발. http://is.ifmo.ru/projects/coffee2/
- 주행용 자동화의 설계 및 연구. http://is.ifmo.ru/projects/novohatko/
- 자동화 기반 프로그래밍을 사용한 디지털 카메라를 모델링. http://project.ifmo.ru/shared/files/200906/5_80.pdf
- 자동 데이터 기반 프로그래밍을 사용한 무인 차량용 멀티 에이전트 시스템 모델링. http://project.ifmo.ru/shared/files/200906/5_41.pdf
- Visual Rubik의 큐브 솔루션 시스템. http://is.ifmo.ru/projects/rubik/
그리고 기타 흥미로운 기사와 프로젝트: http://project.ifmo.ru/projects/, http://is.ifmo.ru/projects_en/ 및 http://is.ifmo.ru/articles_en/.
P.S.
루빅 큐브(Rubik's Cube)에서 발생할 수 있는 다른 이벤트의 수는 (8! × 38−1) × (12! × 212−1)/2 = 43 252 003 274 489 856 000. 그러나 이 숫자는 중심 스퀘어의 방향이 다를 수 있다는 점을 고려하지 않습니다.
따라서, 중심 면의 방향을 고려할 때 사건 횟수는 2048 회, 즉, 88 580 102 706 155 225 088 000 이 됩니다.
Forex 시장 및 거래소는 이벤트 연속이 그리 많지 않지만 이와 관련된 문제는 이 프로그래밍 패러다임을 사용하여 100~200단계로 쉽게 해결할 수 있습니다. 사실입니다! 시장과 EA는 끊임없이 경쟁하고 있습니다. 마치 (우리처럼) 상대의 앞으로의 움직임을 아무도 모르는 체스를 두는 것과 같습니다. 그러나 알파-베타 푸루닝(가지치기) 알고리즘을 기반으로 설계된 Rybka(매우 강력한 체스 엔진)과 같은 인상적인 컴퓨터 프로그램이 있습니다.
프로그래밍의 다른 분야에서 다른 이들의 성공이 여러분에게 에너지와 일에 대한 헌신을 줄 수 있기를 기원합니다! 하지만, 우리 모두는 아무것도 모른다는 걸 알고 있어요.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/446
 가장 활동적인 MQL5. 커뮤니티 구성원에게 iPhone이 수여되었습니다!
가장 활동적인 MQL5. 커뮤니티 구성원에게 iPhone이 수여되었습니다!
 최후의 성전
최후의 성전