
MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 10). Die unkonventionelle RBM
Einführung

Restriktive Boltzmann-Maschinen (RBMs) sind eine Form von neuronalen Netzen, die in ihrer Struktur recht einfach sind, aber in bestimmten Kreisen dennoch verehrt werden, wenn es darum geht, versteckte Eigenschaften und Merkmale in Datensätzen aufzudecken. Dies geschieht durch das Lernen der Gewichte in einer kleineren Dimension aus größer dimensionierten Eingabedaten, wobei diese Gewichte oft als Wahrscheinlichkeitsverteilungen bezeichnet werden. Wie immer können weitere Informationen von hier abgerufen werden, aber in der Regel lässt sich ihre Struktur anhand der nachstehenden Abbildung veranschaulichen:
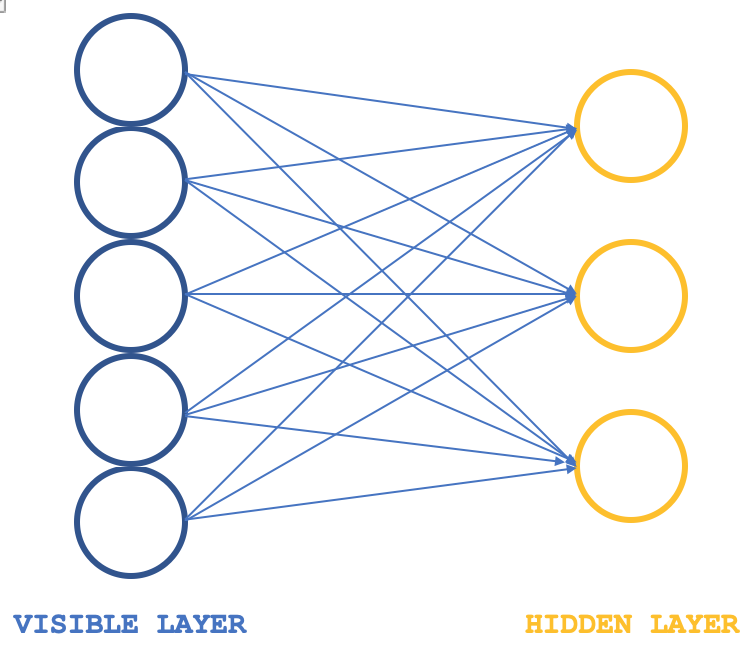
Typischerweise bestehen RBMs aus zwei Schichten (ich sage typischerweise, weil es einige Netze gibt, die sie zu Transformatoren stapeln), einer sichtbaren Schicht und einer verborgenen Schicht, wobei die sichtbare Schicht größer ist (mehr Neuronen hat) als die verborgene Schicht. Jedes Neuron in der sichtbaren Schicht ist mit jedem Neuron in der verborgenen Schicht während der so genannten positiven Phase verbunden, sodass während dieser Phase, wie bei den meisten neuronalen Netzen üblich, die Eingabewerte in der sichtbaren Schicht mit den Gewichtswerten in den Verbindungsneuronen multipliziert werden und die Summe dieser Produkte zu einer Vorspannung addiert wird, um die Werte in den jeweiligen verborgenen Neuronen zu bestimmen. Es folgt die negative Phase, die die Umkehrung dieses Prozesses darstellt und durch verschiedene Neuronenverbindungen darauf abzielt, die Eingabedaten ausgehend von den berechneten Werten in der verborgenen Schicht in ihren ursprünglichen Zustand zurückzuführen.
Bei den frühen Zyklen stimmen die rekonstruierten Eingabedaten also erwartungsgemäß nicht mit den ursprünglichen Eingaben überein, da das RBM häufig mit zufälligen Gewichten initialisiert wird. Dies bedeutet, dass die Gewichte angepasst werden müssen, um die rekonstruierte Ausgabe näher an die Eingabedaten heranzuführen, und dies ist die zusätzliche Phase, die jedem Zyklus folgen würde. Das Endergebnis und Ziel dieses Zyklus - eine positive Phase, gefolgt von einer negativen Phase und der Anpassung der Gewichte - besteht darin, die Gewichte der Verbindungsneuronen zu ermitteln, die, wenn sie auf die Eingabedaten angewandt werden, „intuitive“ Neuronenwerte in der verborgenen Schicht liefern können. Diese Neuronenwerte in der versteckten Schicht sind die so genannte Wahrscheinlichkeitsverteilung der Eingabedaten über die versteckten Neuronen.
Die positive und die negative Phase eines RBM-Zyklus werden häufig unter dem Begriff Gibbs Sampling zusammengefasst. Und um zu Verbindungsgewichten zu gelangen, die die Wahrscheinlichkeitsverteilung der Daten genau abbilden, werden die Verbindungsgewichte durch die so genannte Contrastive Divergenz angepasst. Wenn wir also eine einfache Klasse haben, die dies in MQL5 veranschaulicht, dann könnte unsere Schnittstelle wie folgt aussehen:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Crbm { protected: ... public: bool init; matrix weights_v_to_h; matrix weights_h_to_v; vector bias_v_to_h; vector bias_h_to_v; matrix old_visible; matrix old_hidden; matrix new_hidden; matrix new_visible; matrix output; void GibbsSample(matrix &Input); void ContrastiveDivergence(); Crbm(int Visible, int Hidden, int Sample, double LearningRate, ENUM_LOSS_FUNCTION Loss); ~Crbm(); };
Die bemerkenswerten Variablen hier sind die Matrizen, die die Gewichte protokollieren, wenn sie sich von der sichtbaren Schicht zur verborgenen Schicht fortpflanzen und auch wenn sie sich in umgekehrter Richtung fortpflanzen, diese werden treffend „weights_v_to_h“ bzw. „weights_h_to_v“ genannt. Außerdem sollten die Vektoren enthalten sein, die die Verzerrungen protokollieren, und vor allem die 4 Neuronengruppen, die beim Gibbs-Sampling verwendet werden, um die Neuronenwerte bei jedem Sampling zu speichern; 2 für die sichtbare Schicht und 2 für die versteckte Schicht. Die Funktion des Gibbs Sampling für die positive und negative Phase könnte wie folgt definiert werden:
//+------------------------------------------------------------------+ //| Feed through network using Gibbs Sampling | //+------------------------------------------------------------------+ void Crbm::GibbsSample(matrix &Input) { old_visible.Fill(0.0); old_visible.Copy(Input); //old_hidden = old_visible * weights_v_to_h; //new_hidden = Sigmoid(old_hidden) + bias_v_to_h; for (int GibbsStep = 0; GibbsStep < sample; GibbsStep++) { // Positive phase... Upward pass with biases for (int j = 0; j < hidden; j++) { old_hidden[GibbsStep][j] = 0.0; for (int i = 0; i < visible; i++) { old_hidden[GibbsStep][j] += (old_visible[GibbsStep][i] * weights_v_to_h[i][j]); } new_hidden[GibbsStep][j] = 1.0 / (1.0 + exp(-(old_hidden[GibbsStep][j] + bias_v_to_h[j]))); } } //new_visible = new_hidden * weights_h_to_v; //output = Sigmoid(new_visible) + bias_v_to_h; for (int GibbsStep = 0; GibbsStep < sample; GibbsStep++) { // Negative phase... Downward pass with biases for (int i = 0; i < visible; i++) { new_visible[GibbsStep][i] = 0.0; for (int j = 0; j < hidden; j++) { new_visible[GibbsStep][i] += (new_hidden[GibbsStep][j] * weights_h_to_v[j][i]); } output[GibbsStep][i] = 1.0 / (1.0 + exp(-(new_visible[GibbsStep][i] + bias_h_to_v[i]))); } } }
In ähnlicher Weise könnte die Aktualisierung der Neuronengewichte und Verzerrungen mit der folgenden Funktion realisiert werden:
//+------------------------------------------------------------------+ //| Update weights using Contrastive Divergence | //+------------------------------------------------------------------+ void Crbm::ContrastiveDivergence() { // Update weights based on the difference between positive and negative phase matrix _weights_v_to_h_update; _weights_v_to_h_update.Init(visible, hidden); _weights_v_to_h_update.Fill(0.0); matrix _weights_h_to_v_update; _weights_h_to_v_update.Init(hidden, visible); _weights_h_to_v_update.Fill(0.0); for (int i = 0; i < visible; i++) { for (int j = 0; j < hidden; j++) { _weights_v_to_h_update[i][j] = learning_rate * ( (old_visible[0][i] * weights_v_to_h[i][j]) - old_hidden[0][j] ); _weights_h_to_v_update[j][i] = learning_rate * ( (new_hidden[0][j] * weights_h_to_v[j][i]) - new_visible[0][i] ); } } // Apply weight updates for (int i = 0; i < visible; i++) { for (int j = 0; j < hidden; j++) { weights_v_to_h[i][j] += _weights_v_to_h_update[i][j]; weights_h_to_v[j][i] += _weights_h_to_v_update[j][i]; } } // Bias updates vector _bias_v_to_h_update; _bias_v_to_h_update.Init(hidden); vector _bias_h_to_v_update; _bias_h_to_v_update.Init(visible); // Compute bias updates for (int j = 0; j < hidden; j++) { _bias_v_to_h_update[j] = learning_rate * ((old_hidden[0][j] + bias_v_to_h[j]) - new_hidden[0][j]); } for (int i = 0; i < visible; i++) { _bias_h_to_v_update[i] = learning_rate * ((new_visible[0][i] + bias_h_to_v[i]) - output[0][i]); } // Apply bias updates for (int i = 0; i < visible; ++i) { bias_h_to_v[i] += _bias_h_to_v_update[i]; } for (int j = 0; j < hidden; ++j) { bias_v_to_h[j] += _bias_v_to_h_update[j]; } }
Mit der alten RBM-Struktur, obwohl schematisch nur 2 Schichten in der Illustration gezeigt werden, hat der Code Neuronenwerte für 5 Schichten, weil negative und positive Phasenneuronenwerte nach jedem Produkt und auch nach jeder Aktivierung protokolliert werden. Die alte sichtbare Schicht protokolliert also die rohen Eingabedaten, die alte verborgene Schicht protokolliert das erste Produkt aus Eingaben und Gewichten, die neue verborgene Schicht protokolliert dann die sigmoid-aktivierten Werte dieses Produkts. Die neue sichtbare Schicht protokolliert das zweite Produkt zwischen der neuen versteckten Schicht und den negativen Phasengewichten und schließlich protokolliert die „Output“-Schicht die Aktivierung dieses Produkts.
Dieser orthodoxe Ansatz bei RBMs wird hier nur zu Sondierungszwecken vorgestellt, da er zusammengestellt, aber nicht getestet wird, da sich dieser Artikel auf einen alternativen Ansatz bei der Gestaltung und Schulung von RBMs konzentriert. Für Analysezwecke wäre die wichtigste Ausgabe der Gibbs-Sampling-Funktion jedoch die Neuronenwerte in der ersten und zweiten „versteckten Schicht“. Die doppelten Werte dieser beiden Gruppen von Neuronen würden die Eigenschaften der Eingabedaten erfassen, nachdem das Netz ausreichend trainiert wurde.
Welches unkonventionelle RBM können wir also in Betracht ziehen, das die Grundprinzipien beibehält, aber eine andere Struktur aufweist? Ein dreischichtiges Perzeptron, bei dem die Eingabeschicht und die Ausgabeschicht gleich groß sind und die einzelne verborgene Schicht kleiner als die beiden äußeren Schichten ist. Wie kann man sicherstellen, dass das Training immer noch unbeaufsichtigt ist, da Perceptrons typischerweise überwachtes Lernen haben? Dadurch, dass jede Eingabedatenzeile auch als Zielausgabe dient, was im Wesentlichen das ist, was Gibbs Sampling in jeder Schleife durchführt, kann unser Ziel, Gewichte für alle Verbindungen zur verborgenen Schicht zu erhalten, so erreicht werden, wie man es üblicherweise über Backpropagation erreichen würde. Die Struktur unserer RBM würde daher der nachstehenden Abbildung entsprechen:
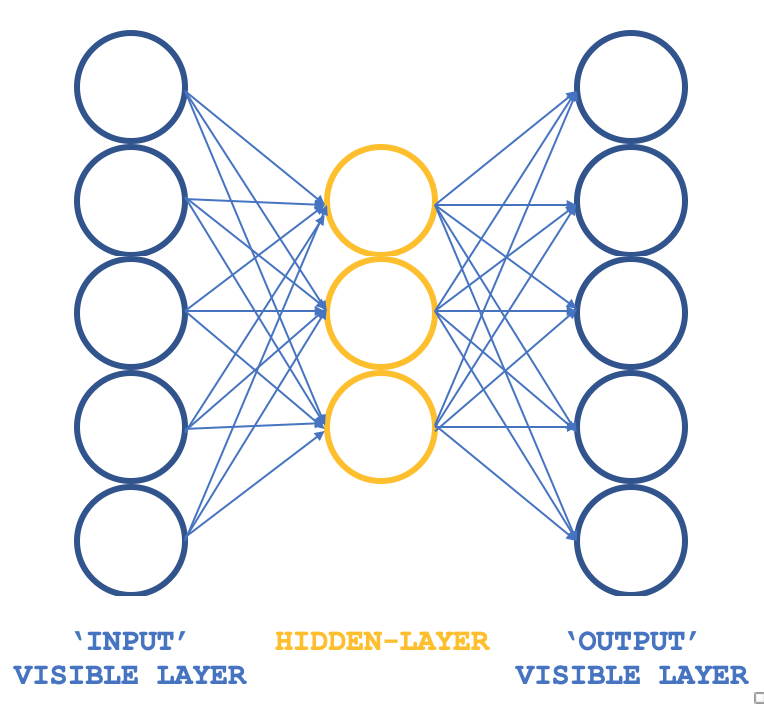
Dieser Ansatz bietet in Verbindung mit ALGLIB-Klassen einen kompakten und effizienten Ansatz für das Testen von RBMs, anstatt alles von Grund auf neu zu programmieren, was das Thema dieser Serie ist. Wenn man erst einmal brauchbare Ideen hat, kann man über eine Anpassung und vielleicht eine Neukodierung nachdenken.
Das Trainingsziel besteht darin, Netzwerkgewichte zu erhalten, die die Merkmale der Eingabedaten in der verborgenen Schicht genau abbilden können. Diese werden in der nächsten Phase des Modells extrahiert und verwendet und können für unsere Zwecke als ein normalisiertes Format der Eingabedaten betrachtet werden.
Die Entstehung von RBM
In Anlehnung an einen Artikel auf deeplearning.net, der leider nicht mehr hochgeladen ist, werden RBMs oft als energy-basedmodels definiert, da sie in der Lage sind, jeder Konfiguration eines Datensatzes von Interesse eine skalare Energie zuzuordnen. Das Lernen erfolgt, indem diese Energiefunktion so verändert wird, dass ihre Form die gewünschten Eigenschaften aufweist. Die „Energiefunktion“ ist eine umgangssprachliche Bezeichnung für die Funktion, die bei der Umwandlung des Eingabedatensatzes in ein anderes (Transit-)Format und schließlich zurück in die Eingabedaten involviert ist, sodass die „Energie“ die Differenz zwischen dem Eingabedatensatz und den Ausgabedaten ist. Der Sinn des Trainings von RBMs besteht also darin, wünschenswerte Konfigurationen mit „niedriger Energie“ zu erhalten, bei denen die Differenz zwischen den anfänglichen Eingaben und den endgültigen Ausgaben minimiert wird. Auf Energie basierende probabilistische Modelle würden eine Wahrscheinlichkeitsverteilung definieren, die über diese Energiefunktion erhalten wird, als den versteckten Neuronenvektor als einen Bruchteil der Summe der versteckten Neuronenwerte für alle abgetasteten Eingabedaten.
Im Allgemeinen werden energiebasierte Modelle trainiert, indem ein (stochastischer) Gradientenabstieg auf der empirischen „negative log-likelihood“ der Trainingsdaten durchgeführt wird. Und allgemeine Boltzmann-Maschinen haben keine verborgenen Schichten und alle Neuronen sind miteinander verbunden.
Der erste Schritt, um diese Berechnung nachvollziehbar zu machen, besteht daher darin, den Erwartungswert mit einer festen Anzahl von Modellstichproben zu schätzen. Die zur Schätzung des positiven Phasengradienten verwendeten Stichproben werden als Gewichte bezeichnet, und ein Produkt dieser Matrixgewichte und des Vektors des Eingabedatensatzes sollte einen Vektor der Neuronenwerte ergeben. (z. B. bei der Durchführung eines Monte-Carlo-Verfahrens). Damit hätten wir quasi einen praktischen, stochastischen Algorithmus zum Erlernen eines EBM. Das einzige, was noch fehlt, ist die Frage, wie man diese Gewichte extrahiert. Während es in der statistischen Literatur eine Fülle von Stichprobenverfahren gibt, eignen sich die Markov-Chain-Monte-Carlo-Methoden besonders gut für Modelle wie die Boltzmann-Maschinen (BM), eine spezielle Art der EBM.
Boltzmann-Maschinen (BMs) sind eine besondere Form des log-linearen Markov-Random-Fields (MRF), d.h. die Energiefunktion ist linear in ihren freien Parametern. Um sie leistungsfähig genug zu machen, um komplizierte Verteilungen darzustellen (d. h. von der begrenzten parametrischen Einstellung zu einer nichtparametrischen überzugehen), gehen wir davon aus, dass einige der Variablen nie beobachtet werden (sie werden, wie oben erwähnt, versteckt genannt). Durch mehr versteckte Variablen (auch versteckte Einheiten genannt) können wir die Modellierungskapazität der Boltzmann-Maschine (BM) erhöhen. Eingeschränkte Boltzmann-Maschinen, eine Ableitung davon, beschränken die BMs weiter auf solche ohne sichtbar-sichtbare und versteckt-versteckte Verbindungen, wie in der einleitenden Abbildung oben dargestellt.
In der Praxis ist es daher eine Selbstverständlichkeit, dass nicht alle Aspekte eines Datensatzes ohne weiteres „sichtbar“ sind, oder wir müssen einige nicht beobachtete Variablen einführen, um die Aussagekraft eines Modells zu erhöhen. Dies kann als Annahme verstanden werden, dass es Aspekte des Eingabedatensatzes gibt, die unbekannt sind und daher untersucht werden müssen. Diese Annahme impliziert daher einen Gradienten zu diesen Unbekannten, wobei der Gradient die Veränderung oder Differenz zwischen den bekannten Daten und den unbekannten, auch „verborgenen“ Daten ist.
Der Gradient würde zwei Phasen enthalten, die als positive und negative Phase bezeichnet werden. Die Begriffe positiv und negativ spiegeln ihre Auswirkungen auf die Wahrscheinlichkeitsdichte oder die abgebildeten Unbekannten wider, die durch das Modell definiert werden. Die positive Phase, oder auch erste Phase, erhöht die Wahrscheinlichkeit von Trainingsdaten (durch Verringerung der entsprechenden freien Energie), während die zweite Phase die Wahrscheinlichkeit von Proben, die durch das Modell generiert werden, um auf den gesampelten Datensatz zurückzukehren, verringert.
Wenn also die Größe der bekannten und verborgenen Datensätze unbestimmt ist, wie bei nicht eingeschränkten Boltzmann-Maschinen, ist es in der Regel schwierig, diesen Gradienten analytisch zu bestimmen, da dies mit einem hohen Rechenaufwand verbunden ist. Aus diesem Grund können RBMs durch Vorgabe der Anzahl von bekannten und unbekannten Daten die Wahrscheinlichkeitsverteilung bestimmen.
Netzarchitektur und Ausbildung
Unsere oben dargestellte 3-Schichten-Struktur wird mit einer Eingangs- und Ausgangsschicht von 5 und einer versteckten Schicht von 3 implementiert. Die Eingaben für die 5 Neuronenwerte sind aktuelle Indikatorwerte. Diese können vom Leser ersetzt werden, da alle Quellen beigefügt sind, aber für diesen Artikel verwenden wir Indikatorwerte für den gleitenden Durchschnitt, den MACD, den Stochastik-Oszillator, die Williams Percent Range und den Relative Vigor Index. Die normalisierte Ausgabe, wie oben erwähnt, erfasst die Neuronenwerte der ersten und zweiten versteckten Schicht, was bedeutet, dass die Größe dieses Ausgabevektors doppelt so groß ist wie die Größe unserer versteckten Schicht.
Alle Gewichtsprodukte und Aktivierungen werden von den ALGLIB-Klassen gehandhabt, und diese sind für jedes einzelne Neuron anpassbar; der entsprechende Code wurde in einem früheren Artikel vorgestellt. Für diesen Artikel verwenden wir die Standardwerte, die sicherlich angepasst werden müssen, wenn wir einen Schritt weiter gehen, aber für den Moment kann es dazu dienen, den Abruf der Wahrscheinlichkeitsverteilung von Daten zu veranschaulichen.
Die Verbindungen in diesem Netz ähneln also eher einem Schmetterling als einem Pfeil, wie im obigen Diagramm dargestellt.
Die Backpropagation in einem herkömmlichen neuronalen Netz passt die Verbindungsgewichte durch Gradientenabstieg über die multivariate Kettenregel an. Dies ist nicht vergleichbar mit der kontrastiven Divergenz, und es ist nicht nur rechenintensiver, sondern könnte auch zu drastisch anderen Gewichtungen (Wahrscheinlichkeitsverteilungen) führen, als man sie in einem normalen RBM erhalten würde. Wir verwenden sie für Testläufe in diesem Artikel, und da der vollständige Quellcode freigegeben ist, können Änderungen an dieser Phase angepasst werden.
Wie bereits erwähnt, ist Backpropagation in der Regel überwacht, da man Zielwerte benötigt, um die Gradienten zu erhalten. Da in unserem Fall die Eingabe als Ziel dient, würde ich behaupten, dass unser modifiziertes RBM immer noch als unbeaufsichtigt eingestuft werden kann.
Beim Training werden die Gewichte unseres Netzes so angepasst, dass die Ausgabe so nah wie möglich an der Eingabe liegt. Auf diese Weise liefert jeder neue Datensatz, der dem Netz zugeführt wird, den Neuronen der versteckten Schicht wichtige Informationen. Diese von den Neuronen stammenden Informationen liegen erwartungsgemäß in einem Array-Format vor. Die Größe dieses Feldes ist jedoch doppelt so groß wie die Anzahl der Neuronen in der versteckten Schicht. In dem Format, das wir für das Testen anpassen, sind die Neuronen in der versteckten Schicht drei, was bedeutet, dass unser Ausgabe-Array, das die Eigenschaften der 5 gesuchten Indikatoren erfasst, die Größe 6 hat.
Diese Werte der versteckten Neuronen können als Normalisierungsformat für die 5 Indikatorwerte verwendet werden. In diesem Fall gibt es keine Dimensionalitätsreduzierung, da der Eigenschaftsvektor eine Größe von 6 hat und wir 5 Eingangsindikatorwerte verwendet haben. Würden wir jedoch mehr Indikatoren, z. B. 8, verwenden und die Anzahl der Neuronen auf der versteckten Schicht bei 3 belassen, hätten wir eine Reduzierung.
Wie verwenden wir also diese Werte? Wenn wir an der Auffassung festhalten, dass es sich lediglich um eine Normalisierung der Indikatorwerte handelt, können sie als Klassifizierungsvektor dienen, der für einen Vergleich nützlich sein könnte, wenn wir sie nun in einem anderen Modell verwenden, in dem wir eine Überwachung in Form einer eventuellen Preisänderung nach jedem Satz von Indikatorwerten hinzufügen. Wir vergleichen also lediglich den Vektor der aktuellen Werte, deren eventuelle Preisänderung unbekannt ist, mit anderen Vektoren, deren Änderungen bekannt sind, und ein gewichteter Durchschnitt, bei dem die Kosinusähnlichkeit zwischen diesen Vektoren als Gewicht dienen kann, würde die durchschnittliche Prognose für die nächste Änderung liefern.
Codierung des Netzwerks in MQL5
Die Schnittstelle zur Implementierung unserer seltsamen RBM könnte wie folgt aussehen:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Crbm { protected: int visible; int hidden; int sample; double loss; string file; public: bool init; ... CArrayDouble losses; void Train(matrix &W); void Process(matrix &W, matrix &XY, bool Compare = false); bool ReadWeights(); bool WriteWeights(); bool Writer(); Crbm(int Visible, int Hidden, int Sample, double Loss, string File); ~Crbm(); };
In der Schnittstelle deklarieren und verwenden wir die grundlegenden Mindestklassen, die wir zum Betrieb eines Perzeptrons benötigen, wie wir es in früheren Artikeln getan haben. Die einzige bemerkenswerte Ergänzung ist das ‚double‘-Array „losses“, das uns hilft, die Differenz zwischen der Eingabeschicht und der Ausgabeschicht zu verfolgen und im Prozess zu steuern, welche Netze ihre exportierbaren Parameter in eine Datei geschrieben bekommen, weil, wie in der Vergangenheit betont wurde, Perceptrons mit der Fähigkeit getestet werden sollten, abstimmbare Parameter zu exportieren, sodass beim Einsatz oder der Verlagerung des Experten in eine Produktionsumgebung die gelernten Gewichte ohne weiteres verwendet werden können, anstatt jedes Mal von den anfänglichen Zufallsgewichten neu zu trainieren.
Das Verlustfeld zeichnet also einfach die Kosinusähnlichkeit zwischen dem Eingabedatensatz und dem Ausgabedatensatz für jede Datenzeile auf jedem Preisbalken auf. Am Ende eines Testlaufs werden die Gewichte oder exportierbaren Parameter der Netze in eine Datei geschrieben, wenn die Anzahl der Kosinusähnlichkeiten unterhalb eines Eingabeschwellenwerts (der Standardwert hierfür ist 0,9, kann aber angepasst werden) geringer ist als der Wert, der bei der letzten Protokollierung der Datei geschrieben wurde. Dieser Schwellenwertparameter wird als „Verlust“ bezeichnet.
Die Syntax für die Multiplikation von Gewichten und Eingabewerten ist wahrscheinlich komplizierter, als sie sein sollte, wenn man bedenkt, dass ‚Matrix‘ und ‚Vektor‘ jetzt eingebettete Datentypen in MQL5 sind. Eine einfache Multiplikation dieser Assoziation während der Überwachung und der jeweiligen Zeilen- und Spaltengrößen könnte das gleiche Ergebnis mit weniger Speicher und somit weniger Rechenressourcen erzielen.
Die Netzfunktion verwendet ALGLIB-Klassen, um Datensätze zu initiieren, zu trainieren und zu verarbeiten. Darüber hinausgehende Anpassungen mit einem eigenen, fest kodierten Perzeptron könnten zu einer besseren Effizienz beim Testen und bei der Bereitstellung führen, da der Code der ALGLIB ziemlich komplex und „verworren“ ist, weil er als Bibliothek für eine größere Vielfalt von Szenarien geeignet ist. Aber auch bei der Standardimplementierung können einige grundlegende Anpassungen vorgenommen werden, z. B. bei der Aktivierung und den Verzerrungen, die einen erheblichen Einfluss auf die Leistung des Netzes haben können. Dies kann für eine erste Testphase, die wir hier untersuchen, sehr hilfreich sein.
Mit diesem Testaufbau trainieren wir also unser unkonventionelles RBM bei jedem neuen Balken oder immer dann, wenn wir einen neuen Preispunkt erhalten, was bedeutet, dass die Gewichte, auf die wir uns bei der Klassifizierung der einzelnen Eingabedatenpunkte verlassen, bei jedem Durchgang verfeinert und angepasst werden. Es könnten auch alternative Ansätze für die Anpassung der Gewichte erforscht werden, z. B. die Anpassung der Gewichte einmal im Quartal oder zweimal im Jahr, vorausgesetzt natürlich, dass vor der Verwendung des Netzes eine angemessene Anzahl von Jahren trainiert wurde. Diese werden in diesem Artikel nicht berücksichtigt, sondern als mögliche Wege genannt, die der Leser verfolgen könnte. Die Ausbildungs- und Prozessfunktionen sind wie unten angegeben definiert:
//+------------------------------------------------------------------+ //| Train Data Matrix | //+------------------------------------------------------------------+ void Crbm::Train(matrix &W) { for(int s = 0; s < sample; s++) { for(int i = 0; i < visible; i++) { xy.Set(s, i, W[s][i]); xy.Set(s, i + visible, W[s][i]); } } train.MLPTrainLM(model, xy, sample, 0.001, 2, info, report); }
Sie ist recht rudimentär, da die ALGLIB-Klassen die Kodierung übernehmen. Die Prozessfunktion ist wie folgt kodiert:
//+------------------------------------------------------------------+ //| Process New Vector | //+------------------------------------------------------------------+ void Crbm::Process(matrix &W, matrix &XY, bool Compare = false) { for(int w = 0; w < int(W.Rows()); w++) { CRowDouble _x = CRowDouble(W.Row(w)), _y; base.MLPProcess(model, _x, _y); for(int i = 6; i < visible + 7; i++) { XY[w][i - 6] = model.m_neurons[i]; } //Comparison vector _input = _x.ToVector(); vector _output = _y.ToVector(); if(Compare) { for(int i = 0; i < int(_input.Size()); i++) { printf(__FUNCSIG__ + " at: " + IntegerToString(i) + " we've input: " + DoubleToString(_input[i]) + " & y: " + DoubleToString(_y[i]) ); } //Loss printf(__FUNCSIG__ + " loss is: " + DoubleToString(_output.Loss(_input, LOSS_COSINE)) ); } losses.Add(_output.Loss(_input, LOSS_COSINE)); } }
Diese Funktion stellt in gewisser Weise die „geheime Soße“ des Algorithmus dar, da sie zeigt, wie wir die Werte der versteckten Neuronen für jeden Eingabedatenwert aus dem Perzeptron abrufen. Bei jedem Balken werden diese Gewichte als eine Art Stichprobe abgerufen. Wir geben sie daher in einem Matrixformat aus, wobei die Zeile der Eingabedaten einen Vektor der Gewichte darstellt.
Die Gewichte, die für jeden Eingabedatenpunkt extrahiert werden, dienen als normalisierte Formen der 5 Indikatorwerte und der oben erwähnte gewichtete Vektorvergleich kann wie folgt realisiert werden:
//+------------------------------------------------------------------+ //| RBM Output. | //+------------------------------------------------------------------+ double CSignalRBM::GetOutput(void) { m_close.Refresh(-1); MA.Refresh(-1); MACD.Refresh(-1); STOCH.Refresh(-1); WPR.Refresh(-1); RVI.Refresh(-1); double _output = 0.0; int _i=StartIndex(); matrix _w; _w.Init(m_sample,__VISIBLE); matrix _xy; _xy.Init(m_sample,7); if(RBM.init) { for(int s=0;s<m_sample;s++) { for(int i=0;i<5;i++) { if(i==0){ _w[s][i] = MA.GetData(0,_i+s); } else if(i==1){ _w[s][i] = MACD.GetData(0,_i+s); } else if(i==2){ _w[s][i] = WPR.GetData(0,_i+s); } else if(i==3){ _w[s][i] = STOCH.GetData(0,_i+s); } else if(i==4){ _w[s][i] = RVI.GetData(0,_i+s); } } if(s>0){ _xy[s][2*__HIDDEN] = m_close.GetData(_i+s)-m_close.GetData(_i+s+1); } } RBM.Train(_w); RBM.Process(_w,_xy); double _w=0.0,_w_sum=0.0; vector _x0=_xy.Row(0); _x0.Resize(6); for(int s=1;s<m_sample;s++) { vector _x=_xy.Row(s); _x.Resize(6); double _weight=fabs(1.0+_x.Loss(_x0,LOSS_COSINE)); _w+=(_weight*_xy[s][6]); _w_sum+=_weight; } if(_w_sum>0.0){ _w/=_w_sum; } _output=_w; } return(_output); }
Mit der letzten for-Schleife erhalten wir die durchschnittliche wahrscheinliche Vorhersage auf der Grundlage der Kosinus-Ähnlichkeitsgewichtung mit anderen Datenpunkten, die ein bekanntes Y (eventuelle Preisänderung) haben.
Wir haben diese angepasste Instanz der Experten-Signalklasse für das Symbol GBPUSD auf dem 4-Stunden-Zeitrahmen vom 2023.07.01 bis zum 2023.10.01 mit einem Walk-Forward-Test vom 2023.10.01 bis zum 2023.12.25 optimiert und die folgenden Berichte erhalten.


Nach diesen ersten Eindrücken könnte es vielversprechend sein. Das Testen erfolgt wie üblich idealerweise mit den echten Ticks des Brokers, mit dem Sie handeln möchten. Und dies idealerweise, nachdem entsprechende Änderungen und Anpassungen nicht nur an den Eingabedatenquellen, sondern wahrscheinlich auch am Design und der Effizienz des Perzeptrons vorgenommen wurden. Der letzte Punkt ist wichtig, denn zuverlässige Testergebnisse sollten sich über längere Zeiträume von Verlaufsdaten erstrecken, was bei der ALGLIB-Quelle eine Herausforderung sein könnte.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass wir die traditionelle Definition eines RBM-Netzes betrachtet haben und wie dieses in MQL5 skriptiert werden könnte. Noch wichtiger ist jedoch, dass wir untersucht haben, wie eine ungewöhnliche Variante dieses Netzes, die ähnlich wie ein einfaches mehrschichtiges Perzeptron strukturiert und trainiert ist, und ob die „Wahrscheinlichkeitsverteilung“, die wir als Ausgangsgewichte bezeichnet haben, für den Aufbau einer weiteren benutzerdefinierten Instanz der Klasse der Expertensignale genutzt werden kann. Die Ergebnisse der Vorwärts- und Rückwärtstests deuten darauf hin, dass das System ein gewisses Potenzial haben könnte, wenn es noch ausführlicher getestet und die Wahl der Dateneingabe möglicherweise noch feiner abgestimmt wird.
Hinweis
Der beigefügte Code kann verwendet werden, sobald er mit dem MQL5-Assistenten zusammengestellt wurde. Ich habe in früheren Artikeln dieser Reihe gezeigt, wie das geht, aber dieser Artikel kann auch als Leitfaden für diejenigen dienen, die neu im Assistenten sind.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/13988
 Deep Learning, Vorhersage und Aufträge mit Python, dem MetaTrader5 Python-Paket und ONNX-Modelldatei
Deep Learning, Vorhersage und Aufträge mit Python, dem MetaTrader5 Python-Paket und ONNX-Modelldatei
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.