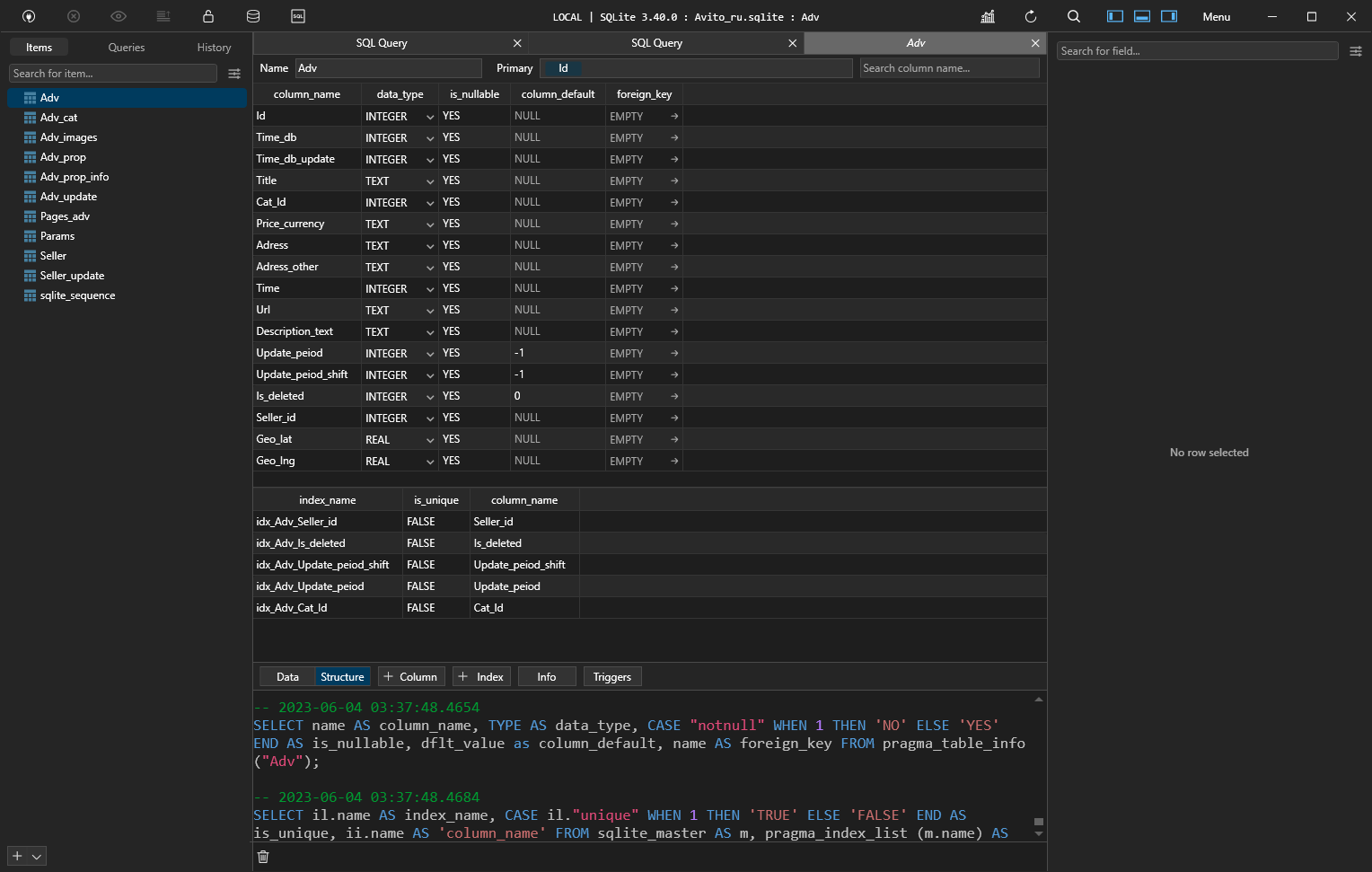
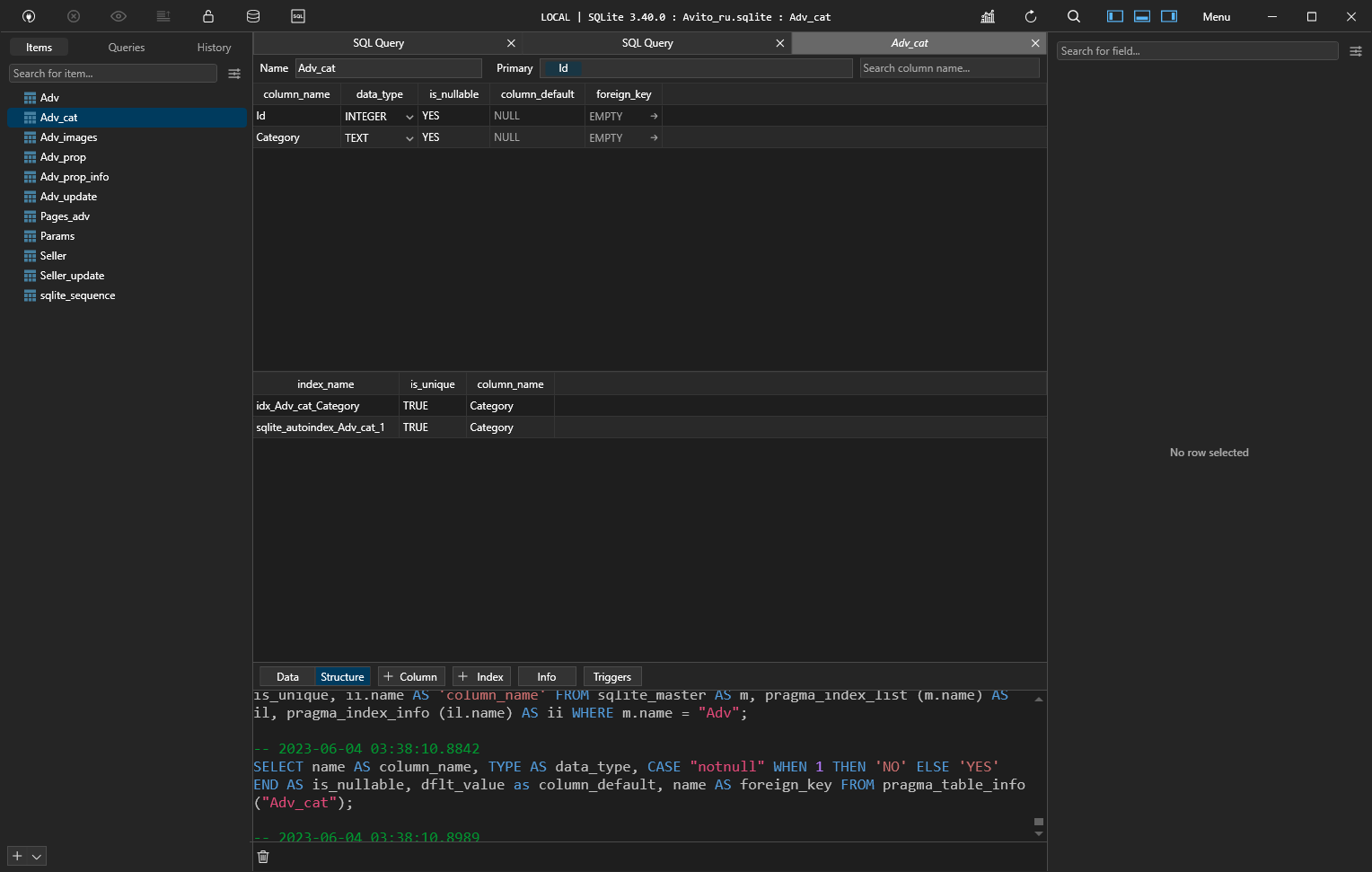
SQLite, медленные запрсы
Пожалуйста:

Так быстро работает:
SELECT DISTINCT Name FROM Adv_prop;
Количество строк в исходной таблице более 1 700 000
Если базовые индексы есть, следующий шаг - с помощью EXPLAIN смотрите план выполнения: https://www.sqlite.org/eqp.html
А вообще LIKE запросы на больших таблицах очень нежелательны. Лучше их заменить на четкие условия.Вот, без удаления дубликатов:
4 0 0 SCAN Adv_prop 6 0 0 SEARCH Adv USING INTEGER PRIMARY KEY (rowid=?) 9 0 0 SEARCH Adv_cat USING INTEGER PRIMARY KEY (rowid=?)
С удалением дубликатов:
6 0 0 SCAN Adv_prop USING INDEX idx_Adv_prop_Name 9 0 0 SEARCH Adv USING INTEGER PRIMARY KEY (rowid=?) 12 0 0 SEARCH Adv_cat USING INTEGER PRIMARY KEY (rowid=?)
Столбцы:
id, parent, notused, detail
Если базовые индексы есть, следующий шаг - с помощью EXPLAIN смотрите план выполнения: https://www.sqlite.org/eqp.html
А вообще LIKE запросы на больших таблицах очень нежелательны. Лучше их заменить на четкие условия.Убрал LIKE, заменил на поиск по индексу путём добавления столбца с указанием родительской категории, всего 1.5 секунды скинул:
WITH dc(idm) AS (
SELECT
Id
FROM
Adv_cat
WHERE
Category = 'Транспорт|Грузовики и спецтехника|Автобусы|Междугородний / Пригородный'
OR Category = 'Транспорт|Грузовики и спецтехника|Автобусы|Троллейбус'
UNION
SELECT
adv_c.Id
FROM
Adv_cat adv_p
JOIN Adv_cat adv_c ON adv_c.Parent = adv_p.Id
WHERE
adv_p.Category = 'Транспорт|Грузовики и спецтехника|Автобусы|Междугородний / Пригородный'
OR adv_p.Category = 'Транспорт|Грузовики и спецтехника|Автобусы|Троллейбус'
UNION
SELECT
Id
FROM
Adv_cat
JOIN dc ON Adv_cat.Parent = dc.idm
)
SELECT
DISTINCT Name
FROM
dc
JOIN Adv ON dc.idm = Adv.Cat_Id
JOIN Adv_prop ON Adv_prop.Adv_Id = Adv.Id; Удаление повторов из 3649 строк не может занимать 9 секунд, тут явно какие-то особенности работы БД
Без удаления время 0.8 с
С удалением 10 с
План выполнения уже такой:
С удалением дубликатов
3 0 0 MATERIALIZE dc 8 3 0 SETUP 9 8 0 COMPOUND QUERY 10 9 0 LEFT-MOST SUBQUERY 13 10 0 SEARCH Adv_cat USING COVERING INDEX idx_Adv_cat_Category (Category=?) 36 9 0 UNION USING TEMP B-TREE 39 36 0 SEARCH adv_p USING COVERING INDEX idx_Adv_cat_Category (Category=?) 57 36 0 SEARCH adv_c USING COVERING INDEX idx_Adv_cat_Parent (Parent=?) 84 3 0 RECURSIVE STEP 86 84 0 SCAN dc 87 84 0 SEARCH Adv_cat USING COVERING INDEX idx_Adv_cat_Parent (Parent=?) 106 0 0 SCAN Adv_prop USING INDEX idx_Adv_prop_Name 109 0 0 SEARCH Adv USING INTEGER PRIMARY KEY (rowid=?) 124 0 0 SEARCH dc USING AUTOMATIC COVERING INDEX (idm=?)
Без
3 0 0 MATERIALIZE dc 8 3 0 SETUP 9 8 0 COMPOUND QUERY 10 9 0 LEFT-MOST SUBQUERY 13 10 0 SEARCH Adv_cat USING COVERING INDEX idx_Adv_cat_Category (Category=?) 36 9 0 UNION USING TEMP B-TREE 39 36 0 SEARCH adv_p USING COVERING INDEX idx_Adv_cat_Category (Category=?) 57 36 0 SEARCH adv_c USING COVERING INDEX idx_Adv_cat_Parent (Parent=?) 84 3 0 RECURSIVE STEP 86 84 0 SCAN dc 87 84 0 SEARCH Adv_cat USING COVERING INDEX idx_Adv_cat_Parent (Parent=?) 104 0 0 SCAN Adv_prop 106 0 0 SEARCH Adv USING INTEGER PRIMARY KEY (rowid=?) 121 0 0 SEARCH dc USING AUTOMATIC COVERING INDEX (idm=?)
Разобрался, нашёл причину медленной работы. Столбец Adv_prop.Name имел очень много повторных значений, удалил индекс и всё стало работать очень быстро 4 мс
А не быстрей было бы сразу писать только уникальные значения и проставлять индексы их в общую таблицу с объявлением? Тогда поиск был на уникальность только при формировании таблицы.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Размер БД более 1 Гб.
Так вполне нормально, время выполнений 1.5 секунд
В результате у нас 3649 строк, совсем немного
А так запрос выполняется 11.4 секунд
Надо получить уникальные строки Adv_prop.Name
SELECT DISTINCT Adv_prop.Name FROM Adv_cat JOIN Adv ON Adv.Cat_Id = Adv_cat.Id, Adv_prop ON Adv_prop.Adv_Id = Adv.Id WHERE Category LIKE 'Транспорт|Грузовики и спецтехника|Автобусы|Междугородний / Пригородный|%' OR Category LIKE 'Транспорт|Грузовики и спецтехника|Автобусы|Троллейбус|%';Так тоже долго:
SELECT Adv_prop.Name FROM Adv_cat JOIN Adv ON Adv.Cat_Id = Adv_cat.Id, Adv_prop ON Adv_prop.Adv_Id = Adv.Id WHERE Category LIKE 'Транспорт|Грузовики и спецтехника|Автобусы|Междугородний / Пригородный|%' OR Category LIKE 'Транспорт|Грузовики и спецтехника|Автобусы|Троллейбус|%' ORDER BY Name;Почему так происходит и как этого можно избежать?
Кстати, с долгими запросами MetaEditor не справляется, циклическое обновление таблицы с зависанием. Для работы с базой использовал программу TablePlus