
Algoritmos de otimização populacionais: Otimização de ervas invasivas (IWO)

Conteúdo
1. Introdução
2. Descrição do algoritmo
3. Resultado dos testes
1. Introdução
O algoritmo metaheurístico de ervas invasivas (Invasive Weed Optimization, IWO) é um método de otimização baseado em populações que busca o ótimo global da função a ser otimizada, simulando a competição e a aleatoriedade de uma colônia de ervas daninhas.
Esse algoritmo de otimização se inspira em fenômenos naturais e reflete o comportamento das ervas daninhas em uma área restrita, lutando pela sobrevivência em um período de tempo limitado.
As ervas daninhas são plantas vigorosas que, com seu crescimento agressivo, representam uma ameaça significativa às culturas agrícolas. Elas se mostraram extremamente resistentes e adaptáveis às mudanças ambientais. Logo, considerando suas características, temos um algoritmo de otimização eficiente. Este método busca imitar a robustez, adaptabilidade e aleatoriedade das comunidades de ervas daninhas na natureza.
Mas o que torna as ervas daninhas tão especiais a ponto de lhes conferir uma vantagem? Elas tendem a ser pioneiras no processo de colonização, espalhando-se rapidamente por meio de diversos mecanismos. Dessa forma, raramente se encontram na categoria de espécies ameaçadas de extinção.
Em resumo, as oito principais formas pelas quais as ervas daninhas se adaptam e sobrevivem na natureza são:
1. Genótipo universal. Estudos mostraram que as ervas daninhas reagem às mudanças climáticas, muitas vezes apresentando alterações evolutivas nas plantas. Estratégias de ciclo de vida e fertilidade.
2. Estratégias de ciclo de vida e fertilidade. As ervas daninhas apresentam uma vasta gama de estratégias de ciclo de vida, tornando-se mais resilientes à medida que os sistemas de manejo de cultivo evoluem. Por exemplo, sistemas de cultivo reduzido favorecem particularmente o desenvolvimento de ervas daninhas perenes com distintas estratégias de ciclo de vida. Adicionalmente, as mudanças climáticas estão criando novos nichos para espécies ou genótipos de ervas daninhas cujas histórias de vida são mais adaptáveis às novas condições. Em resposta ao aumento das emissões de dióxido de carbono, as ervas daninhas crescem mais altas, maiores e mais resistentes, o que implica na produção de mais sementes e maior capacidade de dispersão devido às propriedades aerodinâmicas. A fecundidade das ervas daninhas é notável, como exemplificado pelo cardo-do-campo, que pode gerar até 19.000 sementes.
3. Evolução acelerada (germinação, crescimento adaptável, competitividade, sistema reprodutivo, características de produção e distribuição de sementes). O aumento da capacidade de dispersão de sementes e o crescimento adaptável proporcionam oportunidades de sobrevivência. As ervas daninhas são bastante tolerantes às condições do solo, resistindo firmemente a grandes variações de temperatura e umidade.
4. Epigenética. Além da evolução acelerada, muitas plantas invasoras conseguem responder rapidamente às mudanças nos fatores ambientais, alterando sua expressão gênica. Em um ambiente em constante transformação, as plantas precisam ser flexíveis para enfrentar estresses como variações de luz, temperatura, disponibilidade de água e teores de sal no solo. Para alcançar essa flexibilidade, as plantas são capazes de sofrer modificações epigenéticas por si mesmas.
5. Hibridização. As espécies híbridas de ervas daninhas geralmente apresentam vigor híbrido, também conhecido como heterose, no qual a descendência exibe uma função biológica aprimorada em comparação com ambas as espécies parentais. Com frequência, um híbrido apresentará um crescimento mais vigoroso, além de uma capacidade superior de se expandir para novos territórios e competir em áreas invadidas.
6. Resistência e tolerância a herbicidas. Nas últimas décadas, observou-se um aumento expressivo na resistência a herbicidas por parte da maioria das ervas daninhas.
7. Coevolução de plantas daninhas relacionadas às atividades humanas. Através das práticas de controle de ervas daninhas, como a aplicação de herbicidas e a capina, as plantas daninhas desenvolveram mecanismos de resistência. Estas sofrem menos danos externos durante o cultivo, em comparação com as plantas cultivadas. Além disso, esses danos muitas vezes contribuem para a propagação de ervas daninhas que se reproduzem vegetativamente (por exemplo, partes das raízes, rizomas).
8. As mudanças climáticas cada vez mais frequentes proporcionam uma vantagem às ervas daninhas em relação às plantas cultivadas em ambiente protegido. As ervas daninhas causam prejuízos significativos à agricultura. Sendo menos exigentes em relação às condições de cultivo, elas se desenvolvem e crescem mais rapidamente que as plantas cultivadas. A absorção de umidade, nutrientes e luz solar pelas ervas daninhas reduz drasticamente a produtividade das lavouras, dificulta a colheita, a debulha e compromete a qualidade dos produtos agrícolas.
2. Descrição do algoritmo
O algoritmo de ervas invasivas (Invasive Weed Optimization, IWO) é inspirado no processo de crescimento das ervas daninhas na natureza. Este método foi proposto por Mehrabian e Lucas em 2006. Naturalmente, as ervas daninhas apresentam um crescimento vigoroso, representando uma séria ameaça às plantas benéficas. Uma característica importante das ervas daninhas é a sua resistência e alta adaptabilidade na natureza, o que fundamenta a otimização do algoritmo IWO Este algoritmo pode ser empregado como base para abordagens eficientes de otimização.
O IWO é um algoritmo numérico estocástico contínuo que simula o comportamento colonizador das ervas daninhas. Inicialmente, a população de sementes é distribuída aleatoriamente por todo o espaço de busca. Essas ervas daninhas, eventualmente, crescerão e executarão as etapas subsequentes do algoritmo. O algoritmo é composto por sete etapas, que podem ser representadas como pseudocódigo:
1. Espalhar sementes aleatoriamente;
2. Calcular a Função de Adaptação (FF);
3. Semear sementes a partir das ervas daninhas;
4. Calcular a Função de Adaptação (FF);
5. Combinar ervas daninhas filhas com as progenitoras;
6. Classificar todas as ervas daninhas;
7. Repetir a etapa 3, até que a condição de parada seja satisfeita.
O fluxograma representa a operação do algoritmo em uma iteração. O IWO começa seu trabalho com o processo de inicialização das sementes, que são espalhadas pelo "campo" do espaço de busca de maneira aleatória e uniforme. Após isso, supomos que as sementes germinaram e originaram plantas adultas, que devem ser avaliadas pela função de adaptação (fitness).
Na etapa seguinte, conhecendo a adaptação de cada planta, podemos permitir que as ervas daninhas se reproduzam através de sementes, em que a quantidade de sementes é proporcional à adaptação. Posteriormente, unimos as sementes germinadas às plantas progenitoras e as ordenamos. De modo geral, o algoritmo ervas invasivas pode ser considerado simples de programar, modificar e aplicar em conjunto com softwares de terceiros.

Figura 1. Fluxograma do algoritmo IWO.
Vamos analisar as características do algoritmo de ervas daninhas. Muitas das habilidades extremas de adaptação e sobrevivência das ervas daninhas são implementadas no algoritmo. Um aspecto diferenciador da colônia de ervas daninhas, em comparação com algoritmos como o genético, o de abelhas e outros, é a garantia de semeadura de sementes por todas as plantas da colônia, sem exceção. Isso possibilita gerar descendentes até mesmo para as plantas menos adaptadas, já que sempre existe uma probabilidade diferente de zero de que a planta com pior desempenho esteja mais próxima do extremo global.
Como mencionado, cada uma das ervas daninhas deixará sementes em uma quantidade variando do mínimo ao máximo possível (parâmetros externos do algoritmo). Naturalmente, nessas condições, quando cada planta deixar no mínimo uma ou mais sementes, haverá um maior número de plantas descendentes do que plantas progenitoras. Esse recurso é implementado de maneira interessante no código e será abordado posteriormente. De modo geral, o algoritmo é representado visualmente na Figura 2. As plantas progenitoras espalham sementes de maneira proporcional à sua adaptação.
Assim, a planta com melhor desempenho, número 1, semeou 6 sementes, enquanto a planta número 6 semeou apenas uma semente (uma garantida). As sementes germinadas originam plantas que são, posteriormente, classificadas junto com as plantas progenitoras, simulando a sobrevivência. De todo o grupo classificado, novas plantas progenitoras serão selecionadas e o ciclo de vida se repetirá na próxima iteração. Como há um número máximo e mínimo de sementes permitidas para cada planta, o algoritmo conta com um mecanismo para solucionar o problema de "superpopulação" ou de não aproveitamento completo do potencial de semeadura das sementes.
Por exemplo, consideremos que o número de sementes, um dos parâmetros do algoritmo, é igual a 50, e o número de plantas progenitoras é 5, sendo o mínimo de sementes 1 e o máximo 6. Nesse caso, 5 * 6 = 30, que é menor que 50. Como pode ser observado nesse exemplo, as possibilidades de semeadura não são totalmente aproveitadas. Nessa situação, o direito de gerar descendentes passa para a próxima planta na lista, até que a quantidade máxima permitida de descendentes seja alcançada por todas as plantas progenitoras. Quando o fim da lista é alcançado, o direito retorna ao primeiro da lista, e ainda será permitido gerar um número de descendentes superior ao limite inicialmente estabelecido.

Figura 2. Funcionamento do algoritmo IWO, com o número de descendentes sendo proporcional à adaptação dos pais.
O próximo aspecto a ser considerado é a dispersão da semeadura. A dispersão no algoritmo é uma função linear decrescente, proporcional ao número de iterações. Os parâmetros externos de dispersão são os limites inferior e superior da distribuição das sementes. Dessa forma, à medida que as iterações aumentam, o raio de semeadura diminui e os extremos encontrados são refinados. De acordo com a recomendação dos autores do algoritmo, a distribuição da semeadura deve ser normal, porém simplifiquei os cálculos e apliquei a função cúbica. A função de dispersão em relação ao número de iterações pode ser visualizada na Figura 3.

Figura 3. A dependência da dispersão no número de iterações, onde 3 é o limite máximo e 2 é o mínimo.
Passemos para o código do algoritmo de otimização de ervas invasivas (IWO). O código é simples e rápido de executar.
A unidade (agente) mais básica do algoritmo é a "erva daninha", que também descreverá as sementes dessa erva daninha, permitindo-nos usar o mesmo tipo de dados para a classificação posterior. A estrutura consiste em um vetor de coordenadas, uma variável para armazenar o valor da função de adaptação e um contador para o número de sementes (descendentes). Esse contador nos permitirá controlar o número mínimo e máximo de sementes permitidas para cada planta.
//—————————————————————————————————————————————————————————————————————————————— struct S_Weed { double c []; //coordinates double f; //fitness int s; //number of seeds }; //——————————————————————————————————————————————————————————————————————————————
Precisamos de uma estrutura que permita ter a função de probabilidade para escolher os pais com base em sua adaptação. Para isso, aplicamos o princípio da roleta, que já conhecemos do algoritmo da colônia de abelhas. As variáveis start e end são responsáveis por determinar o intervalo de probabilidade.
//—————————————————————————————————————————————————————————————————————————————— struct S_WeedFitness { double start; double end; }; //——————————————————————————————————————————————————————————————————————————————
Vamos criar uma classe para o algoritmo de ervas daninhas. Dentro dela, declaramos todas as variáveis que iremos utilizar. Aqui, incluiremos, como de costume, os limites e o incremento dos parâmetros que estão sendo otimizados, um array que descreve as ervas daninhas, bem como um array de sementes, um array para armazenar as melhores coordenadas globais encontradas e o melhor valor de adaptação alcançado pelo algoritmo. Também precisaremos de um sinalizador de semeadura para indicar primeira iteração de semeadura e das variáveis constantes para os parâmetros do algoritmo.
//—————————————————————————————————————————————————————————————————————————————— class C_AO_IWO { //============================================================================ public: double rangeMax []; //maximum search range public: double rangeMin []; //manimum search range public: double rangeStep []; //step search public: S_Weed weeds []; //weeds public: S_Weed weedsT []; //temp weeds public: S_Weed seeds []; //seeds public: double cB []; //best coordinates public: double fB; //fitness of the best coordinates public: void Init (const int coordinatesP, //Number of coordinates const int numberSeedsP, //Number of seeds const int numberWeedsP, //Number of weeds const int maxNumberSeedsP, //Maximum number of seeds per weed const int minNumberSeedsP, //Minimum number of seeds per weed const double maxDispersionP, //Maximum dispersion const double minDispersionP, //Minimum dispersion const int maxIterationP); //Maximum iterations public: void Sowing (int iter); public: void Germination (); //============================================================================ private: void Sorting (); private: double SeInDiSp (double In, double InMin, double InMax, double Step); private: double RNDfromCI (double Min, double Max); private: double Scale (double In, double InMIN, double InMAX, double OutMIN, double OutMAX, bool Revers); private: double vec []; //Vector private: int ind []; private: double val []; private: S_WeedFitness wf []; //Weed fitness private: bool sowing; //Sowing private: int coordinates; //Coordinates number private: int numberSeeds; //Number of seeds private: int numberWeeds; //Number of weeds private: int totalNumWeeds; //Total number of weeds private: int maxNumberSeeds; //Maximum number of seeds private: int minNumberSeeds; //Minimum number of seeds private: double maxDispersion; //Maximum dispersion private: double minDispersion; //Minimum dispersion private: int maxIteration; //Maximum iterations }; //——————————————————————————————————————————————————————————————————————————————
No método da função de inicialização, atribuímos valores às variáveis constantes, verificamos os parâmetros de entrada do algoritmo para garantir que estejam dentro das faixas válidas. Por exemplo, o produto entre o número de plantas-mãe e o valor mínimo possível de sementes não pode exceder o número total de sementes disponíveis. A soma das plantas-mãe e sementes será utilizada para definir uma matriz para realizar a classificação.
//—————————————————————————————————————————————————————————————————————————————— void C_AO_IWO::Init (const int coordinatesP, //Number of coordinates const int numberSeedsP, //Number of seeds const int numberWeedsP, //Number of weeds const int maxNumberSeedsP, //Maximum number of seeds per weed const int minNumberSeedsP, //Minimum number of seeds per weed const double maxDispersionP, //Maximum dispersion const double minDispersionP, //Minimum dispersion const int maxIterationP) //Maximum iterations { MathSrand (GetTickCount ()); sowing = false; fB = -DBL_MAX; coordinates = coordinatesP; numberSeeds = numberSeedsP; numberWeeds = numberWeedsP; maxNumberSeeds = maxNumberSeedsP; minNumberSeeds = minNumberSeedsP; maxDispersion = maxDispersionP; minDispersion = minDispersionP; maxIteration = maxIterationP; if (minNumberSeeds < 1) minNumberSeeds = 1; if (numberWeeds * minNumberSeeds > numberSeeds) numberWeeds = numberSeeds / minNumberSeeds; else numberWeeds = numberWeedsP; totalNumWeeds = numberWeeds + numberSeeds; ArrayResize (rangeMax, coordinates); ArrayResize (rangeMin, coordinates); ArrayResize (rangeStep, coordinates); ArrayResize (vec, coordinates); ArrayResize (cB, coordinates); ArrayResize (weeds, totalNumWeeds); ArrayResize (weedsT, totalNumWeeds); ArrayResize (seeds, numberSeeds); for (int i = 0; i < numberWeeds; i++) { ArrayResize (weeds [i].c, coordinates); ArrayResize (weedsT [i].c, coordinates); weeds [i].f = -DBL_MAX; weeds [i].s = 0; } for (int i = 0; i < numberSeeds; i++) { ArrayResize (seeds [i].c, coordinates); seeds [i].s = 0; } ArrayResize (ind, totalNumWeeds); ArrayResize (val, totalNumWeeds); ArrayResize (wf, numberWeeds); } //——————————————————————————————————————————————————————————————————————————————
O primeiro método público chamado em cada iteração de Sowing (). Ele contém a lógica principal do algoritmo. Para facilitar a compreensão do conteúdo do artigo, dividiremos o método em várias partes para análise separada.
Quando o algoritmo está na primeira iteração, é necessário semear em todo o espaço de busca. Isso geralmente é feito de forma aleatória e uniforme. Após gerar números aleatórios dentro da faixa de valores aceitáveis para os parâmetros otimizados, verificamos se os valores obtidos estão além da faixa e definimos a granularidade estabelecida pelos parâmetros do algoritmo. Aqui também atribuímos um vetor de distribuição, que será necessário ao semear as sementes posteriormente no código. Inicializamos os valores de adaptação das sementes com o valor mínimo double e zeramos o contador de sementes (as sementes se tornarão plantas que usarão o contador de sementes).
//the first sowing of seeds--------------------------------------------------- if (!sowing) { fB = -DBL_MAX; for (int s = 0; s < numberSeeds; s++) { for (int c = 0; c < coordinates; c++) { seeds [s].c [c] = RNDfromCI (rangeMin [c], rangeMax [c]); seeds [s].c [c] = SeInDiSp (seeds [s].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); vec [c] = rangeMax [c] - rangeMin [c]; } seeds [s].f = -DBL_MAX; seeds [s].s = 0; } sowing = true; return; }
Nesta seção do código, estamos calculando a dispersão com base na iteração atual. É neste ponto do código que implementamos o número mínimo garantido de sementes para cada planta mãe, mencionado anteriormente. A garantia do número mínimo de sementes é obtida através de dois laços. No primeiro, iteramos pelas plantas mães, e no segundo, geramos efetivamente novas sementes, sem esquecer de incrementar o contador de sementes. Como pode ser observado, a criação de uma nova descendência consiste em adicionar um número aleatório à coordenada pai, seguindo uma distribuição cúbica com a dispersão calculada anteriormente. O valor resultante da nova coordenada é verificado em relação aos valores admissíveis e, em seguida, é atribuída a discretização necessária.
//guaranteed sowing of seeds by each weed------------------------------------- int pos = 0; double r = 0.0; double dispersion = ((maxIteration - iter) / (double)maxIteration) * (maxDispersion - minDispersion) + minDispersion; for (int w = 0; w < numberWeeds; w++) { weeds [w].s = 0; for (int s = 0; s < minNumberSeeds; s++) { for (int c = 0; c < coordinates; c++) { r = RNDfromCI (-1.0, 1.0); r = r * r * r; seeds [pos].c [c] = weeds [w].c [c] + r * vec [c] * dispersion; seeds [pos].c [c] = SeInDiSp (seeds [pos].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); } pos++; weeds [w].s++; } }
Com este código, estamos criando campos de probabilidade para cada uma das plantas-mãe proporcionalmente à sua adaptabilidade, seguindo o princípio da roleta. Enquanto o código anterior garantia um número fixo de sementes para cada planta, aqui a quantidade de sementes segue uma distribuição aleatória. Portanto, quanto mais adaptada for a planta daninha, maior será a sua capacidade de produzir sementes, e, inversamente, quanto menos adaptada a planta for, menor será a quantidade de sementes que ela produzirá.
//============================================================================ //sowing seeds in proportion to the fitness of weeds-------------------------- //the distribution of the probability field is proportional to the fitness of weeds wf [0].start = weeds [0].f; wf [0].end = wf [0].start + (weeds [0].f - weeds [numberWeeds - 1].f); for (int f = 1; f < numberWeeds; f++) { if (f != numberWeeds - 1) { wf [f].start = wf [f - 1].end; wf [f].end = wf [f].start + (weeds [f].f - weeds [numberWeeds - 1].f); } else { wf [f].start = wf [f - 1].end; wf [f].end = wf [f].start + (weeds [f - 1].f - weeds [f].f) * 0.1; } }
Com base nos campos de probabilidade obtidos, selecionamos a planta-mãe que terá o direito de produzir um descendente. Se o contador de sementes atingir o valor máximo permitido, o direito passará para a próxima planta na lista ordenada. Se chegarmos ao final da lista, o direito não passará para a próxima planta, mas será atribuído à primeira planta da lista. Em seguida, a planta filha é formada seguindo a regra descrita anteriormente, levando em consideração a dispersão calculada.
bool seedingLimit = false; int weedsPos = 0; for (int s = pos; s < numberSeeds; s++) { r = RNDfromCI (wf [0].start, wf [numberWeeds - 1].end); for (int f = 0; f < numberWeeds; f++) { if (wf [f].start <= r && r < wf [f].end) { weedsPos = f; break; } } if (weeds [weedsPos].s >= maxNumberSeeds) { seedingLimit = false; while (!seedingLimit) { weedsPos++; if (weedsPos >= numberWeeds) { weedsPos = 0; seedingLimit = true; } else { if (weeds [weedsPos].s < maxNumberSeeds) { seedingLimit = true; } } } } for (int c = 0; c < coordinates; c++) { r = RNDfromCI (-1.0, 1.0); r = r * r * r; seeds [s].c [c] = weeds [weedsPos].c [c] + r * vec [c] * dispersion; seeds [s].c [c] = SeInDiSp (seeds [s].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); } seeds [s].s = 0; weeds [weedsPos].s++; }
O segundo método aberto é necessário e deve ser executado em cada iteração, logo após o cálculo da função de adaptação para cada erva daninha descendente. Antes de aplicarmos a classificação, colocamos as sementes germinadas em um array compartilhado com as plantas-mãe, no final da lista. Isso substitui a geração anterior, na qual podem estar presentes tanto descendentes quanto pais da iteração anterior. Assim, ocorre a eliminação de ervas daninhas pouco adaptadas, como ocorre na natureza. Em seguida, aplicamos a classificação, e a primeira erva daninha na lista resultante será considerada para atualizar a melhor solução globalmente alcançada, desde que seja realmente superior.
//—————————————————————————————————————————————————————————————————————————————— void C_AO_IWO::Germination () { for (int s = 0; s < numberSeeds; s++) { weeds [numberWeeds + s] = seeds [s]; } Sorting (); if (weeds [0].f > fB) fB = weeds [0].f; } //——————————————————————————————————————————————————————————————————————————————
3. Resultado dos testes
Impressão da bancada de teste:
2023.01.13 18:12:29.880 Test_AO_IWO (EURUSD,M1) C_AO_IWO:50;12;5;2;0.2;0.01
2023.01.13 18:12:29.880 Test_AO_IWO (EURUSD,M1) =============================
2023.01.13 18:12:32.251 Test_AO_IWO (EURUSD,M1) 5 Rastrigin's; Func runs 10000 result: 79.71791976868334
2023.01.13 18:12:32.251 Test_AO_IWO (EURUSD,M1) Score: 0.98775
2023.01.13 18:12:36.564 Test_AO_IWO (EURUSD,M1) 25 Rastrigin's; Func runs 10000 result: 66.60305588198622
2023.01.13 18:12:36.564 Test_AO_IWO (EURUSD,M1) Score: 0.82525
2023.01.13 18:13:14.024 Test_AO_IWO (EURUSD,M1) 500 Rastrigin's; Func runs 10000 result: 45.4191288396659
2023.01.13 18:13:14.024 Test_AO_IWO (EURUSD,M1) Score: 0.56277
2023.01.13 18:13:14.024 Test_AO_IWO (EURUSD,M1) =============================
2023.01.13 18:13:16.678 Test_AO_IWO (EURUSD,M1) 5 Forest's; Func runs 10000 result: 1.302934874807614
2023.01.13 18:13:16.678 Test_AO_IWO (EURUSD,M1) Score: 0.73701
2023.01.13 18:13:22.113 Test_AO_IWO (EURUSD,M1) 25 Forest's; Func runs 10000 result: 0.5630336066477166
2023.01.13 18:13:22.113 Test_AO_IWO (EURUSD,M1) Score: 0.31848
2023.01.13 18:14:05.092 Test_AO_IWO (EURUSD,M1) 500 Forest's; Func runs 10000 result: 0.11082098547471195
2023.01.13 18:14:05.092 Test_AO_IWO (EURUSD,M1) Score: 0.06269
2023.01.13 18:14:05.092 Test_AO_IWO (EURUSD,M1) =============================
2023.01.13 18:14:09.102 Test_AO_IWO (EURUSD,M1) 5 Megacity's; Func runs 10000 result: 6.640000000000001
2023.01.13 18:14:09.102 Test_AO_IWO (EURUSD,M1) Score: 0.55333
2023.01.13 18:14:15.191 Test_AO_IWO (EURUSD,M1) 25 Megacity's; Func runs 10000 result: 2.6
2023.01.13 18:14:15.191 Test_AO_IWO (EURUSD,M1) Score: 0.21667
2023.01.13 18:14:55.886 Test_AO_IWO (EURUSD,M1) 500 Megacity's; Func runs 10000 result: 0.5668
2023.01.13 18:14:55.886 Test_AO_IWO (EURUSD,M1) Score: 0.04723
Basta uma rápida análise para percebermos os resultados excelentes do algoritmo nas funções de teste. É notável a preferência em trabalhar com funções suaves, embora até o momento nenhum dos algoritmos analisados tenha apresentado uma convergência melhor em funções discretas do que em funções suaves, o que se explica pela complexidade das funções Forest e Megacity para todos os algoritmos, sem exceção. É possível, embora improvável, que no futuro surja algum algoritmo que resolva funções discretas melhor do que funções suaves em testes.

IWO na função de teste Rastrigin.

IWO na função de teste Forest.

IWO na função de teste Megacity.
O algoritmo de ervas invasivas demonstrou resultados impressionantes na maioria dos testes, especialmente na função suave de Rastrigin com 10 e 50 parâmetros, nos quais o desempenho caiu apenas ligeiramente no teste com 1000 parâmetros. Isso indica uma boa capacidade de lidar com funções suaves, o que torna o algoritmo de ervas daninhas invasivas uma recomendação para trabalhar com funções suaves complexas e também com redes neurais. Em relação às funções Forest, o algoritmo teve um desempenho ligeiramente diferente no primeiro teste com 10 parâmetros, mas ainda apresentou resultados médios. No caso da função discreta Megacity, o algoritmo de ervas invasivas demonstrou resultados acima da média, especialmente com uma excelente escalabilidade no teste com 1000 variáveis, perdendo apenas para o algoritmo de pirilampos, mas superando-o significativamente nos testes com 10 e 50 parâmetros.
Embora o algoritmo de ervas invasivas tenha um número considerável de parâmetros, isso não deve ser considerado uma desvantagem, pois os parâmetros são intuitivos e sua configuração não é uma tarefa difícil. Além disso, a afinação precisa do algoritmo geralmente afeta apenas os resultados dos testes com funções discretas, mantendo resultados satisfatórios nas funções suaves.
Nas visualizações das funções de teste, é perceptível a habilidade do algoritmo em identificar e explorar regiões específicas do espaço de busca, semelhante ao que ocorre no algoritmo de colônia de abelhas e em alguns outros. No entanto, em várias publicações, encontrei opiniões de que o algoritmo é propenso a ficar preso em mínimos locais e apresenta recursos de pesquisa limitados. Mesmo sem uma referência para o extremo global e a ausência de mecanismos para escapar de armadilhas locais, o IWO consegue funcionar de forma satisfatória em funções complexas, como Forest e Megacity. Além disso, ao trabalhar com funções discretas, observa-se que quanto mais parâmetros são otimizados, mais estáveis são os resultados.
Conforme a dispersão das sementes diminui linearmente a cada iteração, o refinamento dos extremos é intensificado no final da otimização. Na minha opinião, isso não é totalmente ideal, pois as capacidades exploratórias do algoritmo são distribuídas de forma desigual ao longo do tempo, como pode ser observado na visualização das funções de teste, resultando em ruído branco na maioria das vezes. Além disso, a irregularidade da pesquisa pode ser avaliada pelos gráficos de convergência na parte direita da janela do teste. Alguma aceleração da convergência é observada no início da otimização, o que é comum em quase todos os algoritmos. Após um início rápido, a convergência desacelera durante a maior parte da otimização. Somente próximo ao fim, observamos uma aceleração significativa da convergência. Com base nisso, concluo que a mudança dinâmica na dispersão é motivo para estudos e experimentos mais detalhados. É evidente que a convergência poderia continuar ocorrendo se o número de iterações fosse maior. No entanto, existem limitações para realizar testes comparativos, a fim de manter a objetividade e a validade prática.
Vamos analisar a tabela de classificação final. Nela, fica evidente que o IWO é o líder absoluto no momento deste artigo. O algoritmo obteve os melhores resultados em dois dos nove testes e, nos demais, seus resultados excepcionais são muito superiores à média. Por isso, o IWO alcança a pontuação máxima de 100 pontos. Na segunda posição da classificação encontra-se o ACOm, uma versão modificada do algoritmo de colônia de formigas, que se destaca como o melhor em 5 dos 9 testes.
| AO | Description | Rastrigin | Rastrigin final | Forest | Forest final | Megacity (discrete) | Megacity final | Final result | ||||||
| 10 params (5 F) | 50 params (25 F) | 1000 params (500 F) | 10 params (5 F) | 50 params (25 F) | 1000 params (500 F) | 10 params (5 F) | 50 params (25 F) | 1000 params (500 F) | ||||||
| IWO | otimização invasiva de ervas daninhas | 1,00000 | 1,00000 | 0,33519 | 2,33519 | 0,79937 | 0,46349 | 0,41071 | 1,67357 | 0,75912 | 0,44903 | 0,94088 | 2,14903 | 100,000 |
| ACOm | otimização de colônia de formigas M | 0,36118 | 0,26810 | 0,17991 | 0,80919 | 1,00000 | 1,00000 | 1,00000 | 3,00000 | 1,00000 | 1,00000 | 0,10959 | 2,10959 | 95,996 |
| COAm | algoritmo de otimização de cuco M | 0,96423 | 0,69756 | 0,28892 | 1,95071 | 0,64504 | 0,34034 | 0,21362 | 1,19900 | 0,67153 | 0,34273 | 0,45422 | 1,46848 | 74,204 |
| FAm | algoritmo de vaga-lumes M | 0,62430 | 0,50653 | 0,18102 | 1,31185 | 0,55408 | 0,42299 | 0,64360 | 1,62067 | 0,21167 | 0,28416 | 1,00000 | 1,49583 | 71,024 |
| BA | algoritmo do morcego | 0,42290 | 0,95047 | 1,00000 | 2,37337 | 0,17768 | 0,17477 | 0,33595 | 0,68840 | 0,15329 | 0,07158 | 0,46287 | 0,68774 | 59,650 |
| ABC | colônia artificial de abelhas | 0,81573 | 0,48767 | 0,22588 | 1,52928 | 0,58850 | 0,21455 | 0,17249 | 0,97554 | 0,47444 | 0,26681 | 0,35941 | 1,10066 | 57,237 |
| FSS | busca por cardume de peixes | 0,48850 | 0,37769 | 0,11006 | 0,97625 | 0,07806 | 0,05013 | 0,08423 | 0,21242 | 0,00000 | 0,01084 | 0,18998 | 0,20082 | 20,109 |
| PSO | otimização de enxame de partículas | 0,21339 | 0,12224 | 0,05966 | 0,39529 | 0,15345 | 0,10486 | 0,28099 | 0,53930 | 0,08028 | 0,02385 | 0,00000 | 0,10413 | 14,232 |
| RND | aleatório | 0,17559 | 0,14524 | 0,07011 | 0,39094 | 0,08623 | 0,04810 | 0,06094 | 0,19527 | 0,00000 | 0,00000 | 0,08904 | 0,08904 | 8,142 |
| GWO | otimizador lobo-cinzento | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,18977 | 0,04119 | 0,01802 | 0,24898 | 1,000 |
O algoritmo das ervas invasivas é excelente para busca global. Este algoritmo demonstra um bom desempenho, apesar de não utilizar o melhor membro da população e não possuir mecanismos para evitar possíveis aprisionamentos em extremos locais. A falta de equilíbrio entre exploração e pesquisa no algoritmo não afetou negativamente sua precisão e velocidade. No entanto, o algoritmo apresenta outras desvantagens. A busca desigual ao longo da otimização indica que o desempenho do IWO poderia ser potencialmente maior se os problemas mencionados anteriormente fossem resolvidos.
O histograma dos resultados do teste de algoritmo são apresentados na Figura 4.
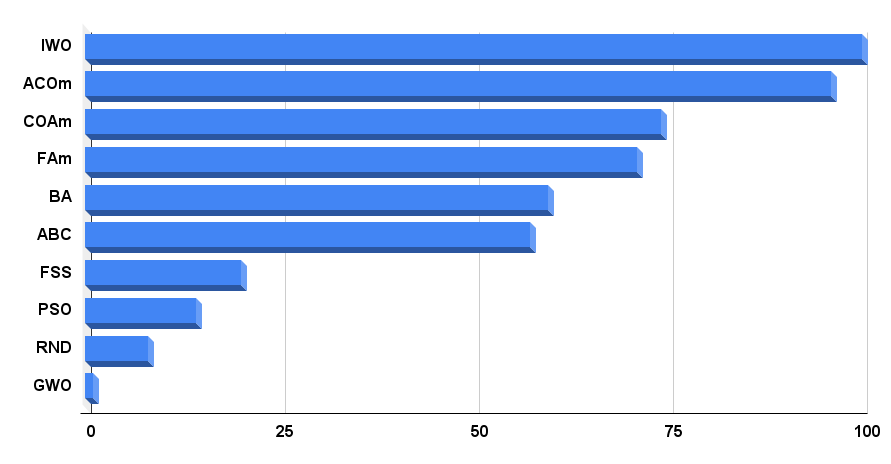
Figura 4. Histograma dos resultados finais dos testes dos algoritmos.
Conclusões sobre as propriedades do algoritmo de ervas invasivas (Invasive Weed Optimization , IWO):
Prós:
1. Rápido.
2. Funciona bem com vários tipos de funções, tanto suaves como discretas.
3. Boa escalabilidade.
Contras:
1. Muitas configurações (embora os parâmetros sejam intuitivos, um grande número de parâmetros ainda é uma desvantagem).
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/11990
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso