
Redes neuronales: así de sencillo (Parte 20): Autocodificadores

Contenido
- Introducción
- 1. Arquitectura del autocodificador
- 2. Tareas clásicas resueltas por los autocodificadores
- 3. Comparación del autocodificador con el ACP
- 4. Posibles usos de los autocodificadores en el trading
- 5. Experimentos prácticos
- Conclusión
- Enlaces
- Programas usados en el artículo.
Introducción
Continuamos analizando los algoritmos de aprendizaje no supervisado. En artículos anteriores ya nos familiarizamos con los algoritmos de clusterización, compresión de datos y recuperación de reglas asociativas. Pero los algoritmos de aprendizaje no supervisado de los que hemos hablado antes no usan redes neuronales. En este artículo, retornaremos al uso de las redes neuronales. Y quiero presentarles el funcionamiento de los autocodificadores.
1. Arquitectura del autocodificador
Antes de pasar a describir la arquitectura del autocodificador, vamos a recordar cómo entrenábamos las redes neuronales en nuestro estudio de los algoritmos de aprendizaje supervisado. Para ello tomábamos pares de datos marcados del patrón y del resultado objetivo y luego optimizábamos los pesos para minimizar el error entre el resultado de la red neuronal y el valor objetivo.
Vamos a pensar entonces qué puede aprender una red neuronal en este caso. Aprenderá exactamente lo que le pidamos, concretamente, a encontrar las características de las que depende el resultado objetivo. Al hacerlo, anulará el impacto de las características que no afectan al resultado objetivo estudiado o cuyo impacto no es significativo. Es decir, el entrenamiento del modelo está estrechamente enfocado, y no hay nada malo en ello. El modelo hace muy bien lo que le pedimos.
Sin embargo, existe la otra cara de la moneda. Aunque todavía no lo hemos utilizado, ya hemos mencionado el concepto de Transfer Learning, es decir, el uso de un modelo preentrenado para resolver nuevos problemas. Nuevamente, solo obtendremos buenos resultados si los valores objetivo anteriores y los nuevos dependen de las mismas características. De lo contrario, podríamos pasar por alto las características cuyo impacto ha sido anulado por el modelo en la fase de aprendizaje anterior.
¿Cómo influirá esto en nuestros objetivos? Recordemos que nuestro mundo no es estático, los cambios en él son constantes. En el futuro, los impulsores del mercado actual pueden pasar a un segundo plano, y el mercado se verá impulsado por otros motores. Como consecuencia, esto limitará la vida útil de nuestro modelo. Obviamente, esto no es un secreto para nadie. Los tráders llevan mucho tiempo revisando sus estrategias a intervalos regulares. Esto también lo confirma la rentabilidad de los asesores algorítmicos construidos con métodos clásicos de descripción de estrategias comerciales.
Cuando empezamos a estudiar las redes neuronales, creíamos con razón que el uso de la inteligencia artificial prolongaría la vida del modelo, y que el entrenamiento periódico nos ayudaría a sacarle el máximo partido durante el mayor tiempo posible.
Para minimizar los riesgos relacionados con la propiedad anterior, recurriremos al aprendizaje de características o de representación (representation learning), uno de los ámbitos del aprendizaje no supervisado. El aprendizaje de características combina un conjunto de algoritmos que permiten la extracción automática de características a partir de datos de origen. En particular, los algoritmos de clusterización y reducción de la dimensionalidad que hemos analizado también están relacionados con el aprendizaje de características. En ellos hemos usado transformaciones lineales. Los autocodificadores se usan para explorar formas más complejas.
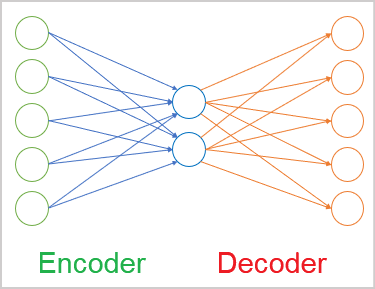
En general, podemos definir los autocodificadores como redes neuronales compuestas por 2 bloques de codificación y decodificación. La capa de datos de origen del codificador y la capa de resultados del decodificador contienen el mismo número de elementos. Entre el codificador y el decodificador hay una capa oculta que suele ser más pequeña que los datos de origen. Durante el aprendizaje, las neuronas de esta capa forman un estado latente (oculto) capaz de describir los datos de origen de forma concisa.
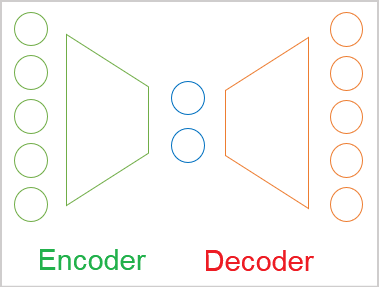
Este recuerda al problema de compresión de datos que resolvimos con el método de componentes principales. Pero hablaremos de la diferencia de enfoque un poco más tarde.
Como ya hemos dicho, el autocodificador es una red neuronal y se entrena usando el método de propagación hacia atrás del error que ya conocemos. El truco consiste en que, como estamos usando datos no etiquetados, entrenaremos el modelo para que primero comprima los datos con un codificador hasta el tamaño del estado latente. A continuación, restauraremos los datos a su estado original en el decodificador con una pérdida mínima de información.
Así, enseñaremos al autocodificador el método ya conocido de propagación hacia atrás del error. Como resultado objetivo, utilizaremos la propia muestra de entrenamiento.
La arquitectura de las propias capas neuronales puede variar. En el caso más simple, pueden ser capas completamente conectadas. Los modelos convolucionales se usan ampliamente para identificar las características de las imágenes.
Asimismo, se pueden utilizar modelos de recurrencia y algoritmos de atención para tratar las secuencias. Abordaremos este tipo de investigaciones en futuros artículos.
2. Tareas clásicas resueltas por los autocodificadores
A pesar de que el enfoque del entrenamiento de autocodificadores no es estándar, su uso puede encontrarse en una gran variedad de aplicaciones. Lo primero y más importante, como ya hemos mencionado, es la compresión y el preprocesamiento de datos.
Podemos clasificar los algoritmos de compresión de datos en dos tipos:
- compresión con pérdidas;
- compresión sin pérdidas.
Un ejemplo de compresión de datos con pérdidas sería el método de componentes principales (ACP) que hemos analizado anteriormente. Recuerde que, al seleccionar el número de componentes, nos fijaremos en el nivel máximo de pérdida de información.
Un ejemplo de compresión de datos sin pérdidas serían varios archivadores. No queremos perder ninguna parte de los datos de origen después de descomprimirlos.
En teoría, podemos entrenar el autocodificador con cualquier dato, y luego usar el codificador para comprimir los datos y el decodificador para recuperarlos. Al hacerlo, transmitiremos solo el estado latente. Dependiendo del nivel de sofisticación del modelo de autocodificación, la compresión de datos podrá tener o no pérdidas. Obviamente, necesitaremos modelos más complejos para organizar la compresión de datos sin pérdidas. No obstante, se utiliza ampliamente en las telecomunicaciones para mejorar la calidad de la transmisión de los datos, además de reducir el tamaño del tráfico usado. Esto aumenta la capacidad de las redes usadas.
La compresión va acompañada del preprocesamiento de los datos de origen. Así, la compresión de datos mediante autocodificadores se usa para combatir la llamada maldición de la dimensión. Además, muchos métodos de aprendizaje automático funcionan mejor y más rápido con datos de menor dimensionalidad. Las mismas redes neuronales, con dimensionalidades de datos de entrada más pequeñas, contendrán menos pesos de entrenamiento. Lo que significa que aprenderán y trabajarán más rápido con menos tendencia al sobreentrenamiento.
La siguiente tarea que resuelven los autocodificadores es limpiar de ruido los datos de origen. Hay dos enfoques para resolver este problema. La primera opción, al igual que con el ACP, es la compresión de datos con pérdida. Al hacerlo, esperaremos que el "ruido" se pierda en la compresión.
El segundo enfoque, se usa ampliamente en el procesamiento de imágenes. Para ello, se toman imágenes originales de buena calidad (sin ruido) y se les añaden diversas distorsiones (artefactos, ruido, etcétera). Las imágenes distorsionadas se introducen en la entrada del autocodificador. A continuación, el modelo se entrena para acercarse lo más posible a la imagen original de buena calidad. Conviene tener mucho cuidado al seleccionar las distorsiones a añadir. Estas deberían ser comparables al "ruido natural". De lo contrario, resulta muy probable que el modelo no funcione correctamente en condiciones reales.
Además, el uso de autocodificadores no solo elimina el ruido de las imágenes, también elimina o añade objetos a la imagen. En particular, si tomamos 2 imágenes que difieren solo en un objeto y las suministramos a la entrada del codificador, el vector de diferencia entre los estados latentes de las dos imágenes se corresponderá con un objeto que solo estará en una imagen. Así, añadiendo el vector resultante al estado latente de cualquier otra imagen, podremos añadir un objeto a la imagen. De la misma forma, al alejar el vector del estado latente eliminaremos el objeto de la imagen.
Las técnicas de entrenamiento del autocodificador permiten separar el estado latente en el contenido y el estilo de la imagen. El intercambio de contenido con conservación del estilo produce una nueva imagen a la salida del decodificador, combinando el contenido de una imagen con el estilo de la otra. El desarrollo de estos experimentos permite usar autocodificadores entrenados para generar imágenes.
Como podemos ver, la gama de tareas que resuelven los codificadores automáticos es bastante amplia, y no todas ellas tienen utilidad en el trading. Al menos, no veo ahora mismo cómo se puede usar la capacidad de generar algo. Quizá usted tenga algunas ideas poco convencionales y sea capaz de ponerlas en práctica.
3. Comparación del autocodificador con el ACP
Como hemos mencionado anteriormente, las tareas que resuelven los autocodificadores se solapan en parte con los algoritmos ya comentados. En particular, los autocodificadores y los métodos de componentes principales son capaces de comprimir los datos (reducción de la dimensionalidad) y eliminar el ruido de los datos de origen. Entonces, ¿por qué necesitamos otra herramienta para las mismas tareas? Vayamos a aclarar en qué se diferencian sus enfoques y resultados.
En primer lugar, debemos recordar el algoritmo del método de componentes principales. Se trata de un método puramente matemático de extracción de componentes principales, basado en fórmulas matemáticas estrictas. Y cuando usamos el método con los mismos datos de origen, tenemos la garantía de obtener el mismo resultado. No podemos decir lo mismo de los autocodificadores.
El autocodificador es una red neuronal que se inicializa con pesos aleatorios y se entrena iterativamente usando el método de descenso de gradiente. Sí, se utilizan las mismas fórmulas matemáticas en el entrenamiento, pero, por una serie de razones, es probable que varios entrenamientos del mismo modelo, incluso con la misma muestra de entrenamiento, produzcan resultados completamente diferentes. Pueden ofrecer la misma precisión y seguir siendo completamente distintos.
El segundo aspecto es el tipo de transformación. En el ACP se utilizan transformaciones lineales en forma de multiplicación de matrices. Al mismo tiempo, en las redes neuronales solemos usar funciones de activación no lineales. Esto significa que las transformaciones en el autocodificador serán más complejas.
Sí, podemos comparar el método de componentes principales con un autocodificador de tres capas sin utilizar una función de activación, pero incluso entonces, aunque el número de elementos de la capa oculta sea igual al número de componentes principales, no existe garantía de que vayamos a obtener el mismo resultado. Más bien lo contrario; en tal caso, el ACP nos garantizará un mejor resultado.
Además, el cálculo de componentes principales será mucho más rápido que el entrenamiento de un modelo de autocodificador. Por lo tanto, si sus datos tienen una clara relación lineal, lo mejor será utilizar el método de componentes principales para comprimirlos. Para tareas más exigentes, el autocodificador resultará más adecuado.
4. Posibles usos de los autocodificadores en el trading
Una vez que nos hemos familiarizado con la parte teórica del funcionamiento de los algoritmos de autocodificación, vamos a pensar en cómo podemos utilizar sus capacidades en nuestras estrategias comerciales. Lo primero que me viene a la mente, por supuesto, es el preprocesamiento de los datos, es decir, comprimirlos y eliminar el "ruido". Ya hemos realizado experimentos similares con el método de componentes principales. Así que podremos hacer un análisis comparativo.
Me resulta difícil ver cómo se podrían usar las capacidades generativas del autocodificador en este momento. Además, el valor de los gráficos falsos es cuestionable, aunque, por supuesto, podríamos intentar entrenar el autocodificador con los resultados del decodificador ligeramente adelantados en el tiempo. Esto, por supuesto, no sería muy diferente de los métodos de aprendizaje supervisado que hemos discutido anteriormente, pero el valor de este enfoque solo puede evaluarse experimentalmente.
También podemos intentar evaluar la dinámica de la situación del mercado. Aunque suene a tópico, el trading en general consiste en vigilar los movimientos del mercado e intentar predecir los movimientos futuros. Más arriba, ya hemos descrito un enfoque en el que el trabajo con el estado latente añade o elimina un objeto de una imagen. ¿Por qué no aprovechar esta propiedad? Lo único que cambiará es que no distorsionaremos la situación del mercado en la salida del decodificador. Solo intentaremos valorar la dinámica del mercado a partir del vector de diferencia entre dos estados latentes sucesivos.
Y, por supuesto, no deberemos olvidarnos del Transfer Learning. Aquí es donde comenzó nuestro artículo. Gracias a la tecnología de aprendizaje del autocodificador, podemos entrenar el modelo para que extraiga características de los datos de origen. Y después, tomaremos solo el codificador. Para resolver nuestros problemas, añadiremos algunas capas de toma de decisiones y terminaremos de entrenar el modelo de forma supervisada. Hay que recordar que, al entrenar un autocodificador, el estado latente contiene todas las características de los datos de origen. Por lo tanto, una vez entrenado, podemos usar el codificador para realizar toda una variedad de distintas aplicaciones. Por supuesto, si usamos los mismos datos de origen.
De esta forma, ya hemos definido un conjunto de tareas para nuestros experimentos. Permítanme decir de entrada que el volumen de dichas tareas quedará fuera del alcance de un solo artículo. Pero no nos asustan las dificultades, así que vamos a comenzar nuestra parte práctica.
5. Experimentos prácticos
Bien, ha llegado el momento de dedicar algo de tiempo a los experimentos prácticos. En primer lugar, crearemos y entrenaremos un autocodificador simple usando capas completamente conectadas. Para construir nuestro modelo de autocodificador, utilizaremos nuestra biblioteca de capas neuronales construida durante el estudio de los métodos de aprendizaje supervisado.
Pero antes de pasar a crear el código, tenemos que pensar en qué y cómo vamos a enseñar a nuestro autocodificador. Ya hemos hablado más arriba de los autocodificadores. Y también de que estos están capacitados para devolver los datos de origen. De hecho, cuando hablamos de datos homogéneos, todo está claro. Tomamos un modelo y lo entrenamos para producir los datos de origen. Sin embargo, nuestros datos de origen no son exactamente homogéneos. Podemos introducir en el modelo tanto datos de precio como lecturas de indicadores. Sin embargo, las lecturas de los distintos indicadores varían mucho. Hemos hablado de esto más de una vez al enseñar modelos de aprendizaje supervisado. A continuación, señalaremos que distintas amplitudes de datos tienen efectos diferentes en el resultado del modelo. Pero ahora las cosas son aún más complicadas porque debemos especificar una función de activación en la capa de resultados del decodificador, y esta función de activación deberá ser capaz de devolver toda la gama de valores iniciales distintos.
Mi solución era la misma que para el aprendizaje supervisado: normalizar los datos de origen. Esto puede suponer un proceso aparte o el uso de una capa de normalización por lotes.
La primera capa oculta de nuestro autocodificador será la capa de normalización por lotes, y después entrenaremos el autocodificador para que el decodificador devuelva los datos normalizados. Para la capa de resultados del decodificador, usaremos como función de activación la tangente hiperbólica, lo cual nos permitirá normalizar los resultados entre -1 y 1.
Bien, ya hemos encontrado la solución teórica, pero para aplicarla en la práctica, necesitaremos tener acceso a los resultados de la primera capa oculta de nuestro modelo en cada iteración del entrenamiento del mismo, y aún no hemos mirado dentro de nuestros modelos. Los estados ocultos de nuestras redes neuronales siempre han sido una caja negra, y para organizar el proceso de aprendizaje, tendremos que abrirla. Para ello, añadiremos a nuestra clase de organización del funcionamiento de la red neuronal CNet el método GetLayerOutput para obtener los valores de búfer de los resultados de cualquier capa oculta.
En los parámetros de nuestro nuevo método, transmitiremos el número ordinal de la capa deseada y un puntero al búfer donde se escribirán los resultados.
En el cuerpo del método, como es habitual, organizaremos un pequeño bloque para comprobar los datos obtenidos. En este caso, comprobaremos que el búfer de capas de nuestro modelo esté actualizado. Asimismo, comprobaremos que el número ordinal especificado de la capa neuronal que buscamos está dentro del rango de capas neuronales de nuestro modelo. Por favor, tenga en cuenta que no comprobaremos la posibilidad de indicar por error un número ordinal de capa negativo. En su lugar, usaremos una variable entera sin signo para obtener el parámetro. Por lo tanto, su valor siempre será no negativo. Esto significa que solo tendremos que comprobar el límite superior del número de capas neuronales del modelo en el bloque de control.
Después de pasar con éxito el bloque de controles, obtendremos el puntero a la capa neuronal especificada en la variable local, y comprobaremos directamente la validez del puntero resultante.
En el siguiente paso de nuestro método, comprobaremos la validez del puntero al búfer de resultados obtenido en los parámetros, y, de ser necesario, iniciaremos la creación de un nuevo búfer de datos.
A continuación, consultaremos los valores del búfer de resultados de la capa neuronal correspondiente. Y, por supuesto, no olvidaremos comprobar el resultado de cada paso.
bool CNet::GetLayerOutput(uint layer, CBufferDouble *&result) { if(!layers || layers.Total() <= (int)layer) return false; CLayer *Layer = layers.At(layer); if(!Layer) return false; //--- if(!result) { result = new CBufferDouble(); if(!result) return false; } //--- CNeuronBaseOCL *temp = Layer.At(0); if(!temp || temp.getOutputVal(result) <= 0) return false; //--- return true; }
Con esto concluiremos el trabajo preparatorio y podremos empezar a construir nuestro primer autocodificador. Para implementarlo, crearemos el asesor "ae.mq5", que se basará en la plantilla de EA de los modelos de aprendizaje supervisado.
Usaremos como datos de origen las cotizaciones de los precios y los datos de 4 indicadores: RSI, CCI, ATR y MACD. Estos mismos datos fueron usados para probar todos los modelos anteriores. Todos los parámetros del indicador se especificarán en los parámetros externos del asesor. En la función OnInit, inicializaremos ejemplares del objeto para trabajar con los indicadores.
int OnInit() { //--- Symb = new CSymbolInfo(); if(CheckPointer(Symb) == POINTER_INVALID || !Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- RSI = new CiRSI(); if(CheckPointer(RSI) == POINTER_INVALID || !RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- CCI = new CiCCI(); if(CheckPointer(CCI) == POINTER_INVALID || !CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- ATR = new CiATR(); if(CheckPointer(ATR) == POINTER_INVALID || !ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- MACD = new CiMACD(); if(CheckPointer(MACD) == POINTER_INVALID || !MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED;
A continuación, tendremos que especificar la arquitectura de nuestro autocodificador. El algoritmo y los principios de la red neuronal son totalmente coherentes con los utilizados al construir los modelos para el aprendizaje supervisado. La única diferencia reside en la arquitectura de la propia red neuronal.
Permítame recordarle que para transmitir la arquitectura de la red neuronal al método de inicialización de nuestro modelo, crearemos el array dinámico de objetos CArrayObj. Cada objeto de este array describirá una sola capa neuronal. Y su secuencia en el array se corresponderá con la secuencia de capas neuronales en el modelo. Para describir la arquitectura de la capa neuronal, utilizaremos varios objetos CLayerDescription especialmente creados con tal propósito.
class CLayerDescription : public CObject { public: /** Constructor */ CLayerDescription(void); /** Destructor */~CLayerDescription(void) {}; //--- int type; ///< Type of neurons in layer (\ref ObjectTypes) int count; ///< Number of neurons int window; ///< Size of input window int window_out; ///< Size of output window int step; ///< Step size int layers; ///< Layers count int batch; ///< Batch Size ENUM_ACTIVATION activation; ///< Type of activation function (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Type of optimization method (#ENUM_OPTIMIZATION) double probability; ///< Probability of neurons shutdown, only Dropout used };
La primera capa, como siempre, será la capa de datos de origen, que declararemos como una capa totalmente conectada. Necesitaremos 12 elementos para la descripción de cada vela, por lo tanto, el tamaño de la capa será 12 veces la profundidad histórica de un solo patrón. Para la capa de datos de origen, no utilizaremos la función de activación.
Net = new CNet(NULL); ResetLastError(); double temp1, temp2; if(CheckPointer(Net) == POINTER_INVALID || !Net.Load(FileName + ".nnw", dError, temp1, temp2, dtStudied, false)) { printf("%s - %d -> Error of read %s prev Net %d", __FUNCTION__, __LINE__, FileName + ".nnw", GetLastError()); CArrayObj *Topology = new CArrayObj(); if(CheckPointer(Topology) == POINTER_INVALID) return INIT_FAILED; //--- 0 CLayerDescription *desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; int prev = desc.count = (int)HistoryBars * 12; desc.type = defNeuronBaseOCL; desc.activation = None; if(!Topology.Add(desc)) return INIT_FAILED;
Después de describir la arquitectura de la capa neuronal, añadiremos esta a un array dinámico que describirá la arquitectura del modelo.
La siguiente capa que tenemos es la capa de normalización por lotes. Como recordará, ya hemos hablado un poco más arriba de la necesidad de esta. El número de elementos de la capa de normalización por lotes será igual al número de neuronas de la capa anterior. Aquí tampoco usaremos la función de activación: indicaremos un tamaño del paquete de normalización igual a 1000 elementos y el método de optimización de los parámetros a entrenar. Asimismo, añadiremos otra descripción de la capa neuronal a nuestro array dinámico de descripciones de la arquitectura del modelo.
//--- 1 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; desc.count = prev; desc.batch = 1000; desc.type = defNeuronBatchNormOCL; desc.activation = None; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED;
Asegúrese de recordar el índice de la capa de normalización en nuestra arquitectura de autocodificación.
Después, empezaremos a construir el codificador de nuestro autocodificador. En él, reduciremos gradualmente el tamaño de las capas neuronales a 2 elementos de estado latente. Su arquitectura quizá le recuerde a un embudo.
Todas las capas neuronales del codificador usarán la tangente hiperbólica como función de activación. Para activar el estado latente, yo he utilizado un sigmoide.
Hay que decir que no existen requisitos especiales en cuanto al número de capas neuronales o las funciones de activación que se deben utilizar al construir un autocodificador. Aquí se usan los mismos principios que en la construcción de cualquier modelo de red neuronal. Por lo tanto, le sugiero que experimente con diferentes arquitecturas al construir su modelo de autocodificador.
//--- 2 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; prev = desc.count = (int)HistoryBars; desc.type = defNeuronBaseOCL; desc.activation = TANH; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 3 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; prev = desc.count = prev / 2; desc.type = defNeuronBaseOCL; desc.activation = TANH; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 4 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; prev = desc.count = prev / 2; desc.type = defNeuronBaseOCL; desc.activation = TANH; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 5 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; desc.count = 2; desc.type = defNeuronBaseOCL; desc.activation = SIGMOID; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED;
A continuación, deberemos especificar la arquitectura del descodificador. A diferencia del codificador, aquí aumentaremos gradualmente el número de elementos en las capas neuronales. Con frecuencia, podemos observar que la arquitectura del decodificador es una imagen especular del codificador. Así que he decidido cambiar el número de capas neuronales y las neuronas que contienen. Para ello, deberemos asegurarnos de que el número de neuronas de la capa de normalización por lotes y de la capa de resultados del descodificador es igual.
//--- 6 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; desc.count = (int) HistoryBars; desc.type = defNeuronBaseOCL; desc.activation = TANH; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 7 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; desc.count = (int) HistoryBars * 4; desc.type = defNeuronBaseOCL; desc.activation = TANH; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 8 desc = new CLayerDescription(); if(CheckPointer(desc) == POINTER_INVALID) return INIT_FAILED; desc.count = (int) HistoryBars * 12; desc.type = defNeuronBaseOCL; desc.activation = TANH; desc.optimization = ADAM; if(!Topology.Add(desc)) return INIT_FAILED;
Después de crear la descripción de la arquitectura del modelo, crearemos nuestra red neuronal del autocodificador. Para ello, crearemos un nuevo ejemplar del objeto de red neuronal transmitiendo una descripción de nuestro autocodificador a su constructor.
delete Net; Net = new CNet(Topology); delete Topology; if(CheckPointer(Net) == POINTER_INVALID) return INIT_FAILED; dError = DBL_MAX; }
Y antes de completar la función de inicialización del asesor, crearemos un búfer de datos temporal y un evento para activar el entrenamiento del modelo.
TempData = new CBufferDouble(); if(CheckPointer(TempData) == POINTER_INVALID) return INIT_FAILED; //--- bEventStudy = EventChartCustom(ChartID(), 1, (long)MathMax(0, MathMin(iTime(Symb.Name(), PERIOD_CURRENT, (int)(100 * Net.recentAverageSmoothingFactor * 10)), dtStudied)), 0, "Init"); //--- return(INIT_SUCCEEDED); }
Podrá encontrar el código completo de todos los métodos y funciones en el archivo adjunto.
Y, obviamente, una vez creado nuestro autocodificador, tendremos que entrenarlo. El entrenamiento de los modelos en nuestra plantilla de asesor se realiza en la función Train. La función obtiene la fecha de inicio del periodo de entrenamiento en los parámetros. En el cuerpo de la función, crearemos las variables locales y definiremos el periodo de entrenamiento.
void Train(datetime StartTrainBar = 0) { int count = 0; //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time); dtStudied = MathMax(StartTrainBar, st_time); ulong last_tick = 0; double prev_er = DBL_MAX; datetime bar_time = 0; bool stop = IsStopped(); CArrayDouble *loss = new CArrayDouble(); MqlDateTime sTime;
A continuación, cargaremos los datos históricos para entrenar el modelo.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); prev_er = dError; //--- if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } RSI.Refresh(OBJ_ALL_PERIODS); CCI.Refresh(OBJ_ALL_PERIODS); ATR.Refresh(OBJ_ALL_PERIODS); MACD.Refresh(OBJ_ALL_PERIODS);
El entrenamiento directo del modelo se realiza en un sistema de ciclos anidados. El ciclo externo contará las épocas de aprendizaje, mientras que el ciclo interno recorrerá los datos históricos dentro de la época de entrenamiento.
En el cuerpo del ciclo externo, almacenaremos el valor del error después de la época de entrenamiento anterior. Dicho error se utilizará para controlar la dinámica de entrenamiento. Si la dinámica del cambio de error tras finalizar la siguiente época de entrenamiento no es significativo, el proceso de entrenamiento se interrumpirá, y comprobaremos la bandera de interrupción del programa por parte del usuario. Después de ello, crearemos un ciclo anidado.
int total = (int)(bars - MathMax(HistoryBars, 0)); do { //--- stop = IsStopped(); prev_er = dError; for(int it = total - 1; it >= 0 && !stop; it--) { int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (total)); if((GetTickCount64() - last_tick) >= 250) { com = StringFormat("Study -> Era %d -> %.6f\n %d of %d -> %.2f%% \nError %.5f", count, prev_er, bars - it + 1, bars, (double)(bars - it + 1.0) / bars * 100, Net.getRecentAverageError()); Comment(com); last_tick = GetTickCount64(); }
En el cuerpo del ciclo anidado, primero mostraremos la información sobre el proceso de entrenamiento en el gráfico en forma de comentarios, y luego determinaremos al azar el siguiente patrón para entrenar el modelo. A continuación, rellenaremos el búfer temporal con datos históricos.
TempData.Clear(); int r = i + (int)HistoryBars; if(r > bars) continue; //--- for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; double open = Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); double rsi = RSI.Main(bar_t); double cci = CCI.Main(bar_t); double atr = ATR.Main(bar_t); double macd = MACD.Main(bar_t); double sign = MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!TempData.Add(Rates[bar_t].close - open) || !TempData.Add(Rates[bar_t].high - open) || !TempData.Add(Rates[bar_t].low - open) || !TempData.Add((double)Rates[bar_t].tick_volume / 1000.0) || !TempData.Add(sTime.hour) || !TempData.Add(sTime.day_of_week) || !TempData.Add(sTime.mon) || !TempData.Add(rsi) || !TempData.Add(cci) || !TempData.Add(atr) || !TempData.Add(macd) || !TempData.Add(sign)) break; } if(TempData.Total() < (int)HistoryBars * 12) continue;
Después de recopilar los datos históricos, llamaremos al método de pasada directa de nuestro autocodificador. Al hacerlo, transmitiremos en los parámetros del método los datos históricos recopilados.
Net.feedForward(TempData, 12, true); TempData.Clear();
En el siguiente paso, tendremos que llamar al método de pasada hacia atrás del modelo para entrenarlo. En los parámetros de este método, transmitiremos previamente el búfer de resultados objetivo. Ahora, como ya hemos comentado, el resultado objetivo de nuestro autocodificador serán los datos de origen normalizados. Para ello, primero obtendremos los resultados de nuestra capa de normalización por lotes y luego transmitiremos estos al método de pasada hacia atrás. Recordemos que el índice de la capa de normalización por lotes en nuestro modelo es "1".
if(!Net.GetLayerOutput(1, TempData)) break; Net.backProp(TempData); stop = IsStopped(); }
Una vez completado el método de pasada hacia atrás, marcaremos la bandera de interrupción de la ejecución del programa por parte del usuario y pasaremos a la siguiente iteración del ciclo anidado.
Cuando termine la siguiente época de entrenamiento, guardaremos el resultado actual del entrenamiento del modelo, mientras que el valor del error del modelo actual se registrará para informar al usuario y se almacenará en el búfer de dinámica del proceso de entrenamiento.
Y antes de iniciar una nueva época de entrenamiento, comprobaremos la conveniencia de seguir entrenando el modelo.
if(!stop) { dError = Net.getRecentAverageError(); Net.Save(FileName + ".nnw", dError, 0, 0, dtStudied, false); printf("Era %d -> error %.5f %%", count, dError); loss.Add(dError); count++; } } while(!(dError < 0.01 && (prev_er - dError) < 0.01) && !stop);
Una vez finalizado el proceso de aprendizaje, guardaremos en un archivo la dinámica de errores de todo el proceso de aprendizaje del modelo y llamaremos a la función para forzar la finalización de nuestro asesor de entrenamiento del modelo.
Comment("Write dinamic of error"); int handle = FileOpen("ae_loss.csv", FILE_WRITE | FILE_CSV | FILE_ANSI, ",", CP_UTF8); if(handle == INVALID_HANDLE) { PrintFormat("Error of open loss file: %d", GetLastError()); delete loss; return; } for(int i = 0; i < loss.Total(); i++) if(FileWrite(handle, loss.At(i)) <= 0) break; FileClose(handle); PrintFormat("The dynamics of the error change is saved to a file %s\\%s", TerminalInfoString(TERMINAL_DATA_PATH), "ae_loss.csv"); delete loss; Comment(""); ExpertRemove(); }
Debo decir que en la versión mostrada uso la función ExpertRemove para finalizar el Asesor Experto, ya que su tarea consistía en entrenar el modelo. Sin embargo, si su asesor tiene otras tareas que realizar, debería eliminar esta función del código, o bien trasladarla a un lugar en el que su asesor realice todas las tareas que se le asignen.
El código completo del asesor y todas las clases utilizadas se encuentran en el archivo adjunto.
Una vez creado el asesor, podemos ponerlo a prueba con datos reales. Hemos entrenado el autocodificador con el instrumento EURUSD y el marco temporal H1 en un segmento histórico que abarca los últimos 15 años. Así, el entrenamiento del autocodificador se ha realizado con una muestra de entrenamiento de más de 92 000 patrones de 40 velas. En el siguiente gráfico, le mostramos la evolución del error durante el entrenamiento.
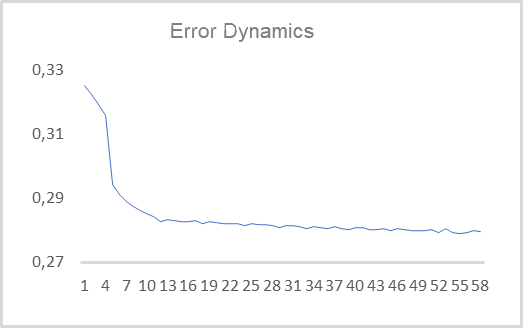
Como podemos ver en el gráfico, en solo 10 épocas, el error medio cuadrático ha disminuido a 0,28 y luego ha continuado un lento descenso. Es decir, el autocodificador es capaz de comprimir hasta 2 elementos del estado latente de la información de 480 características (40 velas * 12 características por vela) con un 78% de conservación de la información. Hay que decir que algo menos del 25% de los datos similares se conserva en los 2 primeros componentes al usar el ACP.
No hemos tomado el tamaño del estado latente de 2 elementos por casualidad. Esto nos permite visualizarlo y compararlo con una representación similar obtenida usando el método de componentes principales. Para preparar estos datos, modificaremos ligeramente el asesor creado anteriormente. Los principales cambios se darán en la función de entrenamiento del modelo Train. El inicio de la función, que implica el proceso de creación de la muestra de entrenamiento, no cambia.
Inmediatamente después de crear la muestra de entrenamiento, añadiremos el entrenamiento del objeto del método de componentes principales.
void Train(datetime StartTrainBar = 0) { //--- The process of creating a training sample has not changed //--- if(!PCA.Study(data)) { printf("Runtime error %d", GetLastError()); return; }
Después, en el asesor anteriormente analizado, creábamos un sistema de 2 ciclos anidados para entrenar el modelo. Ahora no volveremos a entrenar el autocodificador, sino que utilizaremos un modelo previamente entrenado. Por consiguiente, ya no necesitaremos un sistema de ciclos anidados. Aquí nos bastará con un ciclo de iteración de elementos en la muestra de entrenamiento. También debemos decir que no visualizaremos el estado latente de los 92 000 patrones. Semejante cantidad solo dificultaría la percepción de la información. Así que hemos decidido representar solo 1 000 patrones. Sin embargo, el lector podrá repetir mis experimentos con su propio número de patrones para la visualización.
Como he elegido no visualizar toda la muestra, he seleccionado al azar un patrón de la muestra de entrenamiento para visualizarlo, y luego he rellenado el búfer temporal con las características del patrón seleccionado.
{
//---
stop = IsStopped();
bool add_loop = false;
for(int it = 0; i < 1000 && !stop; i++)
{
if((GetTickCount64() - last_tick) >= 250)
{
com = StringFormat("Calculation -> %d of %d -> %.2f%%", it + 1, 1000, (double)(it + 1.0) / 1000 * 100);
Comment(com);
last_tick = GetTickCount64();
}
int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (total));
TempData.Clear();
int r = i + (int)HistoryBars;
if(r > bars)
continue;
//---
for(int b = 0; b < (int)HistoryBars; b++)
{
int bar_t = r - b;
double open = Rates[bar_t].open;
TimeToStruct(Rates[bar_t].time, sTime);
double rsi = RSI.Main(bar_t);
double cci = CCI.Main(bar_t);
double atr = ATR.Main(bar_t);
double macd = MACD.Main(bar_t);
double sign = MACD.Signal(bar_t);
if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE)
continue;
//---
if(!TempData.Add(Rates[bar_t].close - open) || !TempData.Add(Rates[bar_t].high - open) ||
!TempData.Add(Rates[bar_t].low - open) || !TempData.Add((double)Rates[bar_t].tick_volume / 1000.0) ||
!TempData.Add(sTime.hour) || !TempData.Add(sTime.day_of_week) || !TempData.Add(sTime.mon) ||
!TempData.Add(rsi) || !TempData.Add(cci) || !TempData.Add(atr) || !TempData.Add(macd) || !TempData.Add(sign))
break;
}
if(TempData.Total() < (int)HistoryBars * 12)
continue;
Una vez tengamos información sobre el patrón a visualizar, llamaremos al método de pasada directa de nuestro autocodificador y comprimiremos la información aquí usando el método de componentes principales. Luego obtendremos los valores del búfer de resultados de estado latente de nuestro autocodificador.
Net.feedForward(TempData, 12, true); data = PCA.ReduceM(TempData); TempData.Clear(); if(!Net.GetLayerOutput(5, TempData)) break;
Me gustaría recordar que antes, al probar todos los modelos analizados, comprobábamos su capacidad para predecir la formación de un fractal. Ahora, para separar visualmente los patrones, haremos una separación por colores de los patrones en el gráfico. Por lo tanto, debemos especificar a qué tipo pertenece el patrón visualizado. Para entenderlo, comprobaremos la formación de un fractal tras el patrón,
bool sell = (Rates[i - 1].high <= Rates[i].high && Rates[i + 1].high < Rates[i].high); bool buy = (Rates[i - 1].low >= Rates[i].low && Rates[i + 1].low > Rates[i].low); if(buy && sell) buy = sell = false;
y guardaremos los datos resultantes en un archivo para su posterior visualización. Luego pasaremos al siguiente patrón.
FileWrite(handle, (buy ? DoubleToString(TempData.At(0)) : " "), (buy ? DoubleToString(TempData.At(1)) : " "), (sell ? DoubleToString(TempData.At(0)) : " "), (sell ? DoubleToString(TempData.At(1)) : " "), (!(buy || sell) ? DoubleToString(TempData.At(0)) : " "), (!(buy || sell) ? DoubleToString(TempData.At(1)) : " "), (buy ? DoubleToString(data[0, 0]) : " "), (buy ? DoubleToString(data[0, 1]) : " "), (sell ? DoubleToString(data[0, 0]) : " "), (sell ? DoubleToString(data[0, 1]) : " "), (!(buy || sell) ? DoubleToString(data[0, 0]) : " "), (!(buy || sell) ? DoubleToString(data[0, 1]) : " ")); stop = IsStopped(); } }
Una vez completadas todas las iteraciones del ciclo, borraremos el cuadro de comentarios en el gráfico y finalizaremos el asesor.
Comment(""); ExpertRemove(); }
Podrá encontrar el código completo del asesor en el archivo adjunto.
Como resultado del trabajo del asesor, se ha creado el archivo "AE_latent.csv", en el que se han recopilado los datos del estado latente del autocodificador y los dos primeros componentes para los patrones correspondientes. Los dos gráficos a continuación han sido elaborados a partir de los datos del archivo.


Como podemos ver, en los dos gráficos presentados no existe una división clara de los patrones en los grupos buscados. Sin embargo, los datos del estado latente del autocodificador se acercan a un valor de 0,5 en ambos ejes. Me gustaría recordar que para la capa neuronal de estado latente, usamos un sigmoide como función de activación, y este retorna valores entre 0 y 1. Así, el centro de la distribución resultante se hallará cerca del centro del rango de valores de la función.
Al mismo tiempo, la compresión de los datos de los componentes principales producirá valores bastante grandes. En este caso, los valores en los ejes difieren entre 6 y 7 veces, y el centro de la distribución se encuentra aproximadamente en [18000, 130000]. Además, cabe destacar los pronunciados límites lineales superior e inferior del rango.
Según el análisis de los gráficos presentados, yo seleccionaría el autocodificador como instrumento para el preprocesamiento de los datos antes de pasarlos a la entrada de la red neuronal de toma de decisiones.
Conclusión
En este artículo, nos hemos familiarizado con los autocodificadores, que son ampliamente utilizados para una amplia variedad de aplicaciones. Asimismo, hemos construido nuestro primer autocodificador usando capas completamente conectadas y hemos comparado su rendimiento con el método de componentes principales. Los resultados de las pruebas han mostrado las ventajas de usar un autocodificador para los problemas no lineales, pero el tema de la organización y el uso de los autocodificadores es bastante amplio y supera el marco de un solo artículo. En el siguiente artículo, realizaremos diversos estudios para mejorar la eficiencia de los autocodificadores.
Estaré encantado de responder a cualquier pregunta que decida plantear en el hilo del foro dedicado a este artículo.
Enlaces
- Redes neuronales: así de sencillo (Parte 14): Clusterización de datos
- Redes neuronales: así de sencillo (Parte 15): Clusterización de datos usando MQL5
- Redes neuronales: así de sencillo (Parte 16): Uso práctico de la clusterización
- Redes neuronales: así de sencillo (Parte 17): Reducción de la dimensionalidad
- Redes neuronales: así de sencillo (Parte 18): Reglas asociativas
-
Redes neuronales: así de sencillo (Parte 19): Reglas asociativas usando MQL5
Programas usados en el artículo.
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | ae.mq5 | Asesor | Asesor para el entrenamiento del autocodificador |
| 2 | ae2.mq5 | Asesor | Asesor para preparar los datos para la visualización |
| 2 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 3 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/11172
 Desarrollo de un EA comercial desde cero (Parte 31): Rumbo al futuro (IV)
Desarrollo de un EA comercial desde cero (Parte 31): Rumbo al futuro (IV)
 Redes neuronales: así de sencillo (Parte 21): Autocodificadores variacionales (VAE)
Redes neuronales: así de sencillo (Parte 21): Autocodificadores variacionales (VAE)
 Desarrollo de un EA comercial desde cero (Parte 30): ¿¡El CHART TRADE ahora como indicador?!
Desarrollo de un EA comercial desde cero (Parte 30): ¿¡El CHART TRADE ahora como indicador?!
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso