"新神经 "是MetaTrader 5平台的一个开源神经网络引擎项目。 - 页 56 1...495051525354555657585960616263...100 新评论 Ilyas 2011.11.17 17:23 #551 Urain。是的,这正是我想知道的。对mql5 SZ 目前主要关注的是,是否需要将数据复制到特殊的CPU数组中,或者是否支持将数组作为参数在普通函数中传递。这个问题可能从根本上改变整个项目。ZZY 你能回答在你的计划中只是给OpenCL API,还是你计划用你自己的包装器来包装它? 1) 如果你指的是GPU内存,是的,将有特殊的功能来复制用户数组(输入/输出)。 2)将有一个封装器,只支持HW GPU(支持OpenCL 1.1)。 多个GPU的选择,如果有的话,将只能通过终端设置来实现。 OpenCL将被同步使用。 Andrey Dik 2011.11.17 17:31 #552 Urain。是的,这正是我想知道的。对mql5 SZ 目前主要关注的是,是否需要将数据复制到特殊的CPU数组中,或者是否支持将数组作为参数在普通函数中传递。这个问题可能从根本上改变整个项目。ZZZY 你能回答一下,你是打算只提供OpenCL的API,还是打算用你自己的包装器来包装它?判断的依据。mql5: 事实上,你将能够直接使用OpenCL.dll库函数,而不需要插入第三方DLL。OpenCL.dll函数将像本地MQL5函数一样可用,而编译器将自己重定向调用。由此可以得出结论,OpenCL.dll的功能现在已经可以布置了(假调用)。Renat和 mql5,我对 "环境 "的理解是否正确? Ilyas 2011.11.17 17:41 #553 joo:判断的依据。OpenCL.dll函数可以像本地MQL5函数 一样使用,而且编译器本身会重定向调用。由此可以得出结论,OpenCL.dll的功能现在已经可以布置了(假调用)。Renat和 mql5,我的 "情况 "对吗? 在开发中与OpenCL合作。与直接使用OpenCL.dll会有区别。 Mykola Demko 2011.11.17 19:29 #554 到目前为止,这就是项目的计划。 对象是矩形,方法是椭圆。 Mykola Demko 2011.11.17 20:10 #555 处理方法分为4类。метод параллельных расчётов метод последовательных расчётов метод расчётов активатора метод расчётов операторов задержки 这四个方法描述了所有层的整个处理过程,这些方法通过方法对象导入到 处理过程中,这些方法从基类继承,并根据神经元的类型根据需要重载。 TheXpert 2011.11.17 22:43 #556 Urain。尼古拉,你知道这句话 -- 过早优化是万恶之源。暂时忘掉OpenCL吧,没有它,你也要做一些像样的事情。你总是会有时间来换位思考,特别是在还没有的情况下。 Mykola Demko 2011.11.18 00:39 #557 TheXpert。尼古拉,你知道这样一句流行语--过早优化是万恶之源。暂时忘掉OpenCL吧;没有它你也能写出像样的东西。你可以随时切换。 此外,现在还没有内部功能。是的,这是一个流行的说法,我上次也几乎同意它,但经过分析,我意识到我不能只是计划,然后为GPU重新设计,它有非常具体的需求。如果我们计划不使用GPU,那么做一个神经元对象将是合乎逻辑的,它将负责神经元内部的操作,并将计算数据分配到所需的存储单元中,通过从共同的祖先继承一个类,我们可以很容易地连接所需的神经元类型,等等。 但是,在对我的大脑进行了一番研究后,我立即明白,这种方法会完全破坏GPU的计算,未出生的孩子注定要爬行。但我怀疑我上面的帖子把你弄糊涂了。 那里的 "并行计算方法 "我指的是相当具体的输入与*wg中的权重相乘的操作,连续计算方法我指的是sum+=a[i]等等。只是为了将来更好地兼容GPU,我建议从神经元中派生出操作,并将其合并为一个层对象中的单一移动,而神经元将只提供从哪里取哪里放的信息。 Vladimir 2011.11.19 22:51 #558 讲座1在此进行https://www.mql5.com/ru/forum/4956/page23 这里的讲座2https://www.mql5.com/ru/forum/4956/page34 第3次讲座在此举行https://www.mql5.com/ru/forum/4956/page36 第4讲在这里https://www.mql5.com/ru/forum/4956/page46 第5讲(最后一讲)。稀疏编码 这个主题是最有趣的。 我将逐步写这个讲座。因此,不要忘记不时地查看这个帖子。 一般来说,我们的任务是将过去N个柱子的价格报价(向量x)线性分解为基础函数(矩阵A 系列)。 其中s 是我们要找到的线性变换的系数,并将其作为神经网络下一层的输入(如SVM)。在大多数情况下,我们知道基函数A ,也就是说,我们事先选择了它们。它们可以是不同频率的正弦和余弦(我们得到傅里叶变换)、Gabor函数、Hammotons、小波、curlets、多项式或任何其他函数。如果这些函数是我们事先知道的,那么稀疏编码就简化为找到一个系数矢量s ,使这些系数大部分为零(稀疏矢量)。这个想法是,大多数信息信号的结构是由少于信号样本数的基函数描述的。这些包含在信号稀疏描述中的基函数是其必要的特征,可用于信号分类。 寻找原始信息的排出的线性变换的问题被称为压缩感知(http://ru.wikipedia.org/wiki/Compressive_sensing)。一般来说,问题的表述如下。 在As=x的条件下,s的L0准则最小。 其中L0规范等于矢量s 的非零值的数量。解决这个问题最常用的方法是用L1规范代替L0规范,这构成了基数追求法(https://en.wikipedia.org/wiki/Basis_pursuit) 的基础。 在As=x的条件下,最小化s的L1准则。 其中L1准则的计算方法是|s_1|+|s_2|+...+|s_L|。这个问题可以简化为线性优化 另一种流行的寻找稀疏向量s 的方法是匹配追求法(https://en.wikipedia.org/wiki/Matching_pursuit)。这种方法的实质是寻找给定矩阵A 的第一个基函数a_i,使其与其他基函数相比,以最大的系数s_i适合输入向量x。在从输入矢量中减去a_i*s_i 后,我们将下一个基函数加到所产生的残余物上,以此类推,直到达到给定的误差。匹配追求法的一个例子是以下指标,它在输入矢量中以最小的残差刻下一个又一个正弦:https://www.mql5.com/ru/code/130。 如果我们事先不知道基函数A(字典),我们需要用统称为字典学习的方法从输入数据x 中找到它们。 这是稀疏编码方法中最困难的部分(对我来说也是最有趣的)。在我之前的讲座中,我展示了这些函数是如何,例如,通过Ogi规则找到的,它使这些函数成为输入引数的主向量。不幸的是,这种基函数并不能导致对输入数据的不连续描述(即矢量s 是不稀疏的)。 现有的词典学习方法导致了不相干的线性转换,分为 概率性的 集群 在线 寻找基础函数的概率方法 被简化为最大似然。 在A上最大化P(x|A)。 通常情况下,近似误差被假定为具有高斯分布,这导致我们要解决以下优化问题。 (1) 。 分两步解决:(1-稀疏编码步骤)在固定基础函数A 的情况下,括号内的表达式相对于向量s 最小化;(2-字典更新步骤)找到的向量s 是固定的,括号内的表达式相对于基础函数A 使用梯度下降法最小化。 (2) 其中上标中的(n+1)和(n)表示迭代数。这两个步骤(稀疏编码步骤和字典学习步骤)被重复进行,直到达到局部最小值。这种寻找基础函数的概率性方法被用于例如 Olshausen, B.A., & Field, D.J.(1996).通过学习自然图像的稀疏代码,出现了简单细胞的接受场特性。自然》, 381(6583), 607-609. Lewicki, M. S., & Sejnowski, T. J. (1999)。学习超完整表征。Neural Comput., 12(2), 337-365. 最佳方向法(MOD)使用同样的两个优化步骤(稀疏编码步骤和字典学习步骤),但在第二个优化步骤(字典更新步骤)中,通过将括号(1)中的表达式相对于A 的导数等效为零来计算基函数。 , 其中我们得到 (3) 。 其中s+ 是一个伪逆矩阵。这是比梯度下降法(2)更精确的基矩阵计算。这里对MOD方法进行了更详细的描述。 K.Engan, S.O.Aase, and J.H.哈肯-胡索伊。框架设计的最佳方向方法。IEEE国际声学、语音和信号处理会议。5, pp. 2443-2446, 1999. 计算伪逆矩阵是很麻烦的,k-SVD方法可以避免这样做。 我还没有想出办法。你可以在这里读到它。 M.Aharon, M. Elad, A. Bruckstein.K-SVD: 一种设计稀疏表征的超完整字典的算法.IEEE Trans.信号处理,54(11),2006年11月。 我也还没有搞清楚聚类和在线查找字典的方法。有兴趣的读者可以参考下一份调查报告。 R.Rubinstein, A. M. Bruckstein, and M. Elad, "Dictionaries for sparse representation modeling,"Proc. of IEEE , 98(6), pp. 1045-1057, June 2010. 这里有一些关于这个主题的有趣视频讲座。 http://videolectures.net/mlss09us_candes_ocsssrl1m/ http://videolectures.net/mlss09us_sapiro_ldias/ http://videolectures.net/nips09_bach_smm/ http://videolectures.net/icml09_mairal_odlsc/ 暂时就这些了。我将在今后的帖子中对这个话题进行扩展,因为我有能力,而且本论坛的访问者也有兴趣。 "New Neural" is an Renat Fatkhullin 2011.11.19 23:23 #559 TheXpert: 尼古拉,你知道那句流行语--过早优化是一切罪恶的根源。这是开发人员掩盖其无用性的一个常见短语,每次使用它都会被打上一巴掌。如果我们谈论的是具有长生命周期和直接面向高速和高负荷的高质量软件的开发,那么这句话从根本上说是有害的,也是绝对错误的。在我多年的项目管理 实践中,我已经多次验证了这一点。 TheXpert 2011.11.19 23:43 #560 雷纳特。这是一个用来掩盖开发者的错误的常见短语,每次使用它都会被打一巴掌。所以你必须考虑到一些不知道什么时候会出现的功能,谁也不知道什么界面,因为它能给你带来性能上的提升?在我多年的项目管理实践中,我已经测试过很多次。 那么你为什么不运用你多年的经验呢?同时,你要表现出榜样和专业精神,而不是傲慢的语气。 1...495051525354555657585960616263...100 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
是的,这正是我想知道的。
对mql5
SZ 目前主要关注的是,是否需要将数据复制到特殊的CPU数组中,或者是否支持将数组作为参数在普通函数中传递。这个问题可能从根本上改变整个项目。
ZZY 你能回答在你的计划中只是给OpenCL API,还是你计划用你自己的包装器来包装它?
2)将有一个封装器,只支持HW GPU(支持OpenCL 1.1)。
多个GPU的选择,如果有的话,将只能通过终端设置来实现。
OpenCL将被同步使用。
是的,这正是我想知道的。
对mql5
SZ 目前主要关注的是,是否需要将数据复制到特殊的CPU数组中,或者是否支持将数组作为参数在普通函数中传递。这个问题可能从根本上改变整个项目。
ZZZY 你能回答一下,你是打算只提供OpenCL的API,还是打算用你自己的包装器来包装它?
判断的依据。
mql5:
事实上,你将能够直接使用OpenCL.dll库函数,而不需要插入第三方DLL。
OpenCL.dll函数将像本地MQL5函数一样可用,而编译器将自己重定向调用。
由此可以得出结论,OpenCL.dll的功能现在已经可以布置了(假调用)。
Renat和 mql5,我对 "环境 "的理解是否正确?
判断的依据。
OpenCL.dll函数可以像本地MQL5函数 一样使用,而且编译器本身会重定向调用。
由此可以得出结论,OpenCL.dll的功能现在已经可以布置了(假调用)。
Renat和 mql5,我的 "情况 "对吗?
到目前为止,这就是项目的计划。
对象是矩形,方法是椭圆。处理方法分为4类。
这四个方法描述了所有层的整个处理过程,这些方法通过方法对象导入到 处理过程中,这些方法从基类继承,并根据神经元的类型根据需要重载。
尼古拉,你知道这句话 -- 过早优化是万恶之源。
暂时忘掉OpenCL吧,没有它,你也要做一些像样的事情。你总是会有时间来换位思考,特别是在还没有的情况下。
尼古拉,你知道这样一句流行语--过早优化是万恶之源。
暂时忘掉OpenCL吧;没有它你也能写出像样的东西。你可以随时切换。 此外,现在还没有内部功能。
是的,这是一个流行的说法,我上次也几乎同意它,但经过分析,我意识到我不能只是计划,然后为GPU重新设计,它有非常具体的需求。
如果我们计划不使用GPU,那么做一个神经元对象将是合乎逻辑的,它将负责神经元内部的操作,并将计算数据分配到所需的存储单元中,通过从共同的祖先继承一个类,我们可以很容易地连接所需的神经元类型,等等。
但是,在对我的大脑进行了一番研究后,我立即明白,这种方法会完全破坏GPU的计算,未出生的孩子注定要爬行。
但我怀疑我上面的帖子把你弄糊涂了。 那里的 "并行计算方法 "我指的是相当具体的输入与*wg中的权重相乘的操作,连续计算方法我指的是sum+=a[i]等等。
只是为了将来更好地兼容GPU,我建议从神经元中派生出操作,并将其合并为一个层对象中的单一移动,而神经元将只提供从哪里取哪里放的信息。
讲座1在此进行https://www.mql5.com/ru/forum/4956/page23
这里的讲座2https://www.mql5.com/ru/forum/4956/page34
第3次讲座在此举行https://www.mql5.com/ru/forum/4956/page36
第4讲在这里https://www.mql5.com/ru/forum/4956/page46
第5讲(最后一讲)。稀疏编码
这个主题是最有趣的。 我将逐步写这个讲座。因此,不要忘记不时地查看这个帖子。
一般来说,我们的任务是将过去N个柱子的价格报价(向量x)线性分解为基础函数(矩阵A 系列)。
其中s 是我们要找到的线性变换的系数,并将其作为神经网络下一层的输入(如SVM)。在大多数情况下,我们知道基函数A ,也就是说,我们事先选择了它们。它们可以是不同频率的正弦和余弦(我们得到傅里叶变换)、Gabor函数、Hammotons、小波、curlets、多项式或任何其他函数。如果这些函数是我们事先知道的,那么稀疏编码就简化为找到一个系数矢量s ,使这些系数大部分为零(稀疏矢量)。这个想法是,大多数信息信号的结构是由少于信号样本数的基函数描述的。这些包含在信号稀疏描述中的基函数是其必要的特征,可用于信号分类。
寻找原始信息的排出的线性变换的问题被称为压缩感知(http://ru.wikipedia.org/wiki/Compressive_sensing)。一般来说,问题的表述如下。
在As=x的条件下,s的L0准则最小。
其中L0规范等于矢量s 的非零值的数量。解决这个问题最常用的方法是用L1规范代替L0规范,这构成了基数追求法(https://en.wikipedia.org/wiki/Basis_pursuit) 的基础。
在As=x的条件下,最小化s的L1准则。
其中L1准则的计算方法是|s_1|+|s_2|+...+|s_L|。这个问题可以简化为线性优化
另一种流行的寻找稀疏向量s 的方法是匹配追求法(https://en.wikipedia.org/wiki/Matching_pursuit)。这种方法的实质是寻找给定矩阵A 的第一个基函数a_i,使其与其他基函数相比,以最大的系数s_i适合输入向量x。在从输入矢量中减去a_i*s_i 后,我们将下一个基函数加到所产生的残余物上,以此类推,直到达到给定的误差。匹配追求法的一个例子是以下指标,它在输入矢量中以最小的残差刻下一个又一个正弦:https://www.mql5.com/ru/code/130。
如果我们事先不知道基函数A(字典),我们需要用统称为字典学习的方法从输入数据x 中找到它们。 这是稀疏编码方法中最困难的部分(对我来说也是最有趣的)。在我之前的讲座中,我展示了这些函数是如何,例如,通过Ogi规则找到的,它使这些函数成为输入引数的主向量。不幸的是,这种基函数并不能导致对输入数据的不连续描述(即矢量s 是不稀疏的)。
现有的词典学习方法导致了不相干的线性转换,分为
寻找基础函数的概率方法 被简化为最大似然。
在A上最大化P(x|A)。
通常情况下,近似误差被假定为具有高斯分布,这导致我们要解决以下优化问题。
(1)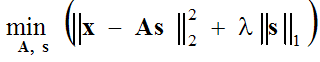 。
。
分两步解决:(1-稀疏编码步骤)在固定基础函数A 的情况下,括号内的表达式相对于向量s 最小化;(2-字典更新步骤)找到的向量s 是固定的,括号内的表达式相对于基础函数A 使用梯度下降法最小化。
(2)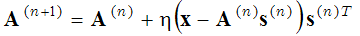
其中上标中的(n+1)和(n)表示迭代数。这两个步骤(稀疏编码步骤和字典学习步骤)被重复进行,直到达到局部最小值。这种寻找基础函数的概率性方法被用于例如
Olshausen, B.A., & Field, D.J.(1996).通过学习自然图像的稀疏代码,出现了简单细胞的接受场特性。自然》, 381(6583), 607-609.
Lewicki, M. S., & Sejnowski, T. J. (1999)。学习超完整表征。Neural Comput., 12(2), 337-365.
最佳方向法(MOD)使用同样的两个优化步骤(稀疏编码步骤和字典学习步骤),但在第二个优化步骤(字典更新步骤)中,通过将括号(1)中的表达式相对于A 的导数等效为零来计算基函数。
其中我们得到
(3)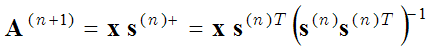 。
。
其中s+ 是一个伪逆矩阵。这是比梯度下降法(2)更精确的基矩阵计算。这里对MOD方法进行了更详细的描述。
K.Engan, S.O.Aase, and J.H.哈肯-胡索伊。框架设计的最佳方向方法。IEEE国际声学、语音和信号处理会议。5, pp. 2443-2446, 1999.
计算伪逆矩阵是很麻烦的,k-SVD方法可以避免这样做。 我还没有想出办法。你可以在这里读到它。
M.Aharon, M. Elad, A. Bruckstein.K-SVD: 一种设计稀疏表征的超完整字典的算法.IEEE Trans.信号处理,54(11),2006年11月。
我也还没有搞清楚聚类和在线查找字典的方法。有兴趣的读者可以参考下一份调查报告。
R.Rubinstein, A. M. Bruckstein, and M. Elad, "Dictionaries for sparse representation modeling,"Proc. of IEEE , 98(6), pp. 1045-1057, June 2010.
这里有一些关于这个主题的有趣视频讲座。
http://videolectures.net/mlss09us_candes_ocsssrl1m/
http://videolectures.net/mlss09us_sapiro_ldias/
http://videolectures.net/nips09_bach_smm/
http://videolectures.net/icml09_mairal_odlsc/
暂时就这些了。我将在今后的帖子中对这个话题进行扩展,因为我有能力,而且本论坛的访问者也有兴趣。
尼古拉,你知道那句流行语--过早优化是一切罪恶的根源。
这是开发人员掩盖其无用性的一个常见短语,每次使用它都会被打上一巴掌。
如果我们谈论的是具有长生命周期和直接面向高速和高负荷的高质量软件的开发,那么这句话从根本上说是有害的,也是绝对错误的。
在我多年的项目管理 实践中,我已经多次验证了这一点。
这是一个用来掩盖开发者的错误的常见短语,每次使用它都会被打一巴掌。
所以你必须考虑到一些不知道什么时候会出现的功能,谁也不知道什么界面,因为它能给你带来性能上的提升?
在我多年的项目管理实践中,我已经测试过很多次。