交易中的机器学习:理论、模型、实践和算法交易 - 页 851 1...844845846847848849850851852853854855856857858...3399 新评论 СанСаныч Фоменко 2018.04.21 17:16 #8501 elibrarius: 2个类 加载了1个核心 设置 , rfeControl = rfeControl(number = 1,repeats = 1) - 将时间减少到10-15分钟。结果的变化--2对预测因子被调换,但总体上与默认的情况相似。好了,你去吧,你的10分钟一个核心是我的2对4,还有2分钟我记不清了。 我从不为某件事情等上几个小时,如果10-15分钟没有效果,那就是出了问题,所以花更多时间也没有用。在建立一个持续数小时的模型时,任何优化都是对建模思想的完全失败,因为建模思想认为,模型应该尽可能的粗糙,在任何情况下都应该尽可能的精确。 现在,关于预测器的选择。 你为什么要这样做,为什么?你想解决什么问题? 选拔工作中最重要的是努力解决再培训的问题。你的模型是否训练过度? 如果不是,那么选择可以通过减少预测因子的数量来加速学习。但通过隔离主成分,减少数量要有效得多。它们不会影响任何东西,但它们可以将预测因子的数量减少一个数量级,从而提高模型拟合的速度。 所以要先说:你为什么需要它? Forester 2018.04.21 17:22 #8502 交易员博士。我发现了另一个有趣的包,用于筛选出预测因素。它被称为FSelector。它提供了大约十几种筛除预测因子的方法,包括熵值。 我从https://www.mql5.com/ru/forum/86386/page6#comment_2534058,得到了带有预测器和目标的文件。 每种方法对预测器的评价我都在最后的图表中显示。 蓝色是好的,红色是坏的(对于corrplot结果被缩放为[-1:1],对于确切的评价,见cfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable)等的结果。) 你可以看到,X3、X4、X5、X19、X20几乎被所有的方法评估得很好,你可以从它们开始,然后再尝试增加/删除更多。 然而,在Rat_DF2上使用这5个预测因子时, rattle中的模型没有通过测试,奇迹再次没有发生。也就是说,即使有剩余的预测因子,你也必须调整模型参数,做交叉验证,自己添加/删除预测因子。我使用弗拉基米尔文章中的数据对CORElearn做了同样的事情。 我计算了各列的平均数(最下面一行是平均数),并按其排序。这样更容易觉察到总的重要性。 花了1.6分钟--那是37个算法的工作。 速度比Caret(16分钟)好得多,结果相似。 Mihail Marchukajtes 2018.04.21 17:50 #8503 elibrarius。我使用弗拉基米尔文章中的数据对CORElearn做了同样的事情。 我按列计算了平均数(最下面一行的平均数),并按它进行了排序。这样更容易觉察到总的重要性。 它花了1.6分钟,用了37种算法。那么,底线是什么?你到底有没有回答关于预测器的重要性的问题,因为我对这些图片有点不理解。 对我来说,现在建立和选择模型时完全没有问题,我选择预测器,然后在其上建立10个模型,然后相互信息选择效果最好的一个。你知道怎么做吗?这是一个精神上的挑战!!!。好吧,谁解决了这个问题,谁就是最好的!!!!!。 我设法得到了一套模型。而实际上vporez:哪些模式是有效的,为什么??????? 或者说它们都能工作,但只有一个能拨号。并解释为什么? Forester 2018.04.21 18:08 #8504 Mihail Marchukajtes: 那么,底线是什么?你到底有没有回答关于预测器的重要性的问题,因为我对这些图片有点不理解。对我来说,现在建立和选择模型时完全没有问题,我选择预测器,然后在其上建立10个模型,然后相互信息选择效果最好的一个。你知道怎么做吗?这是一个精神上的挑战!!!。好吧,谁解决了这个问题,谁就是最好的!!!!!。我设法得到了一套模型。而实际上vporez:哪些模式是有效的,为什么???????或者说它们都能工作,但只有一个能拨号。并解释为什么?Vtreat对预测因素的排序非常相似(重要的先) 5 1 7 11 4 10 3 9 6 2 12 8 下面是在CORElearn中按平均值排序的情况 5 1 7 11 9 4 3 6 10 2 8 12 我想我不会再去管更多的预测器选择 包了。 所以Vtreat就足够了。除了没有考虑到预测因素的相互作用。可能也是。 Maxim Dmitrievsky 2018.04.21 18:16 #8505 当我看到你不断地挑起预测者对市场历史的某些部分的重要性时,我的眼泪就会流下来。为什么? 这是对统计方法的亵渎。 Forester 2018.04.21 18:22 #8506 马克西姆-德米特里耶夫斯基。 当我看到你不断挑起预测者对市场历史的一些片段的重要性时,我泪流满面。为什么? 这是对统计方法的亵渎。 我在实践中检查过,如果你把2号预测器输入NS--误差从30%上升到几乎50%。 Maxim Dmitrievsky 2018.04.21 18:23 #8507 elibrarius。 在实践中检查,如果将2号预测器送入NS--误差从30%上升到几乎50%。而在OOS上,错误是如何变化的? Forester 2018.04.21 18:30 #8508 马克西姆-德米特里耶夫斯基。OOS上的错误是如何变化的? 类似地。正如弗拉基米尔的文章一样--数据来自那里。 Maxim Dmitrievsky 2018.04.21 18:31 #8509 elibrarius。 类似地。正如弗拉基米尔的文章一样--数据来自那里。如果它是在不同的OOS上呢? Yuriy Asaulenko 2018.04.21 18:32 #8510 elibrarius: 在实践中,我检查过,如果你把2号预测器送入NS,误差从30%上升到几乎50%。吐出预测因子,并将归一化的时间序列 送入NS。NS将找到预测器本身--+1-2层,就这样了 1...844845846847848849850851852853854855856857858...3399 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
2个类
加载了1个核心
设置 , rfeControl = rfeControl(number = 1,repeats = 1) - 将时间减少到10-15分钟。结果的变化--2对预测因子被调换,但总体上与默认的情况相似。
好了,你去吧,你的10分钟一个核心是我的2对4,还有2分钟我记不清了。
我从不为某件事情等上几个小时,如果10-15分钟没有效果,那就是出了问题,所以花更多时间也没有用。在建立一个持续数小时的模型时,任何优化都是对建模思想的完全失败,因为建模思想认为,模型应该尽可能的粗糙,在任何情况下都应该尽可能的精确。
现在,关于预测器的选择。
你为什么要这样做,为什么?你想解决什么问题?
选拔工作中最重要的是努力解决再培训的问题。你的模型是否训练过度? 如果不是,那么选择可以通过减少预测因子的数量来加速学习。但通过隔离主成分,减少数量要有效得多。它们不会影响任何东西,但它们可以将预测因子的数量减少一个数量级,从而提高模型拟合的速度。
所以要先说:你为什么需要它?
我发现了另一个有趣的包,用于筛选出预测因素。它被称为FSelector。它提供了大约十几种筛除预测因子的方法,包括熵值。
我从https://www.mql5.com/ru/forum/86386/page6#comment_2534058,得到了带有预测器和目标的文件。
每种方法对预测器的评价我都在最后的图表中显示。
蓝色是好的,红色是坏的(对于corrplot结果被缩放为[-1:1],对于确切的评价,见cfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable)等的结果。)
你可以看到,X3、X4、X5、X19、X20几乎被所有的方法评估得很好,你可以从它们开始,然后再尝试增加/删除更多。
然而,在Rat_DF2上使用这5个预测因子时, rattle中的模型没有通过测试,奇迹再次没有发生。也就是说,即使有剩余的预测因子,你也必须调整模型参数,做交叉验证,自己添加/删除预测因子。
我使用弗拉基米尔文章中的数据对CORElearn做了同样的事情。
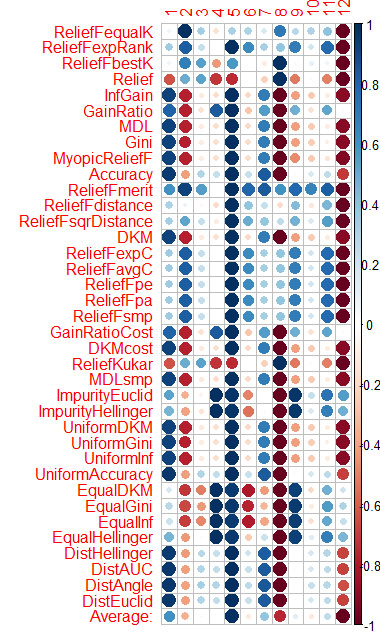
我计算了各列的平均数(最下面一行是平均数),并按其排序。这样更容易觉察到总的重要性。
花了1.6分钟--那是37个算法的工作。 速度比Caret(16分钟)好得多,结果相似。
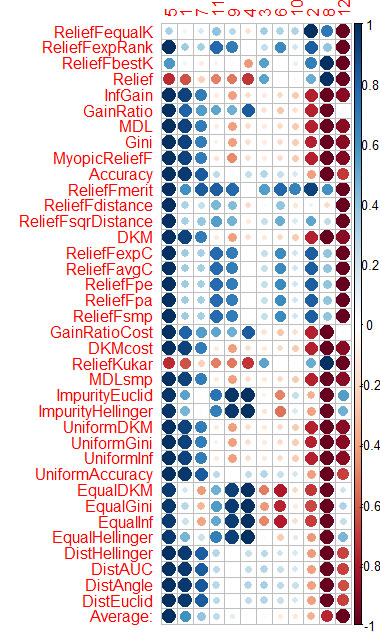
我使用弗拉基米尔文章中的数据对CORElearn做了同样的事情。
我按列计算了平均数(最下面一行的平均数),并按它进行了排序。这样更容易觉察到总的重要性。
它花了1.6分钟,用了37种算法。
那么,底线是什么?你到底有没有回答关于预测器的重要性的问题,因为我对这些图片有点不理解。
对我来说,现在建立和选择模型时完全没有问题,我选择预测器,然后在其上建立10个模型,然后相互信息选择效果最好的一个。你知道怎么做吗?这是一个精神上的挑战!!!。好吧,谁解决了这个问题,谁就是最好的!!!!!。
我设法得到了一套模型。而实际上vporez:哪些模式是有效的,为什么???????
或者说它们都能工作,但只有一个能拨号。并解释为什么?
那么,底线是什么?你到底有没有回答关于预测器的重要性的问题,因为我对这些图片有点不理解。
对我来说,现在建立和选择模型时完全没有问题,我选择预测器,然后在其上建立10个模型,然后相互信息选择效果最好的一个。你知道怎么做吗?这是一个精神上的挑战!!!。好吧,谁解决了这个问题,谁就是最好的!!!!!。
我设法得到了一套模型。而实际上vporez:哪些模式是有效的,为什么???????
或者说它们都能工作,但只有一个能拨号。并解释为什么?
Vtreat对预测因素的排序非常相似(重要的先)
5 1 7 11 4 10 3 9 6 2 12 8
下面是在CORElearn中按平均值排序的情况
5 1 7 11 9 4 3 6 10 2 8 12
我想我不会再去管更多的预测器选择 包了。
所以Vtreat就足够了。除了没有考虑到预测因素的相互作用。可能也是。
当我看到你不断挑起预测者对市场历史的一些片段的重要性时,我泪流满面。为什么? 这是对统计方法的亵渎。
在实践中检查,如果将2号预测器送入NS--误差从30%上升到几乎50%。
而在OOS上,错误是如何变化的?
OOS上的错误是如何变化的?
类似地。正如弗拉基米尔的文章一样--数据来自那里。
如果它是在不同的OOS上呢?
在实践中,我检查过,如果你把2号预测器送入NS,误差从30%上升到几乎50%。
吐出预测因子,并将归一化的时间序列 送入NS。NS将找到预测器本身--+1-2层,就这样了