交易中的机器学习:理论、模型、实践和算法交易 - 页 1929 1...192219231924192519261927192819291930193119321933193419351936...3399 新评论 Vladimir Perervenko 2020.07.28 17:47 #19281 mytarmailS: 为促进个人谈话您的选择普通版正如你所看到的,这些值是完全不同的,你可以自己检查一下在我的模型中。因此只有一列,但这并不重要。===================UPD伙计,你每次运行 umap_tranform 时它们都是不同的,它不应该是这样的 没有注意到。已经有很长一段时间了... Forester 2020.07.28 18:50 #19282 mytarmailS: 为促进个人谈话您的选择普通版正如你所看到的,这些值是完全不同的,你可以自己检查一下在我的模型中。因此只有一列,但这并不重要。===================UPD伙计,你每次运行 umap_tranform 时,它们都是不同的,它不应该是这样的 通常情况下,(内置RNG的)种子被设置为某个值,以保证可重复性。如果没有,则使用随机。这个包可能也有一个 "种子"--检查一下。 mytarmailS 2020.07.28 19:10 #19283 elibrarius: 通常为了重复性,你将(内置HSS的)种子值设置为某个值。如果没有,则使用随机。也许这个包里也有种子--看看吧。 我想是的,但问题是,如果没有RMS,它应该总是一样的,在 "umap "模拟包中,结果总是一样的。 mytarmailS 2020.07.28 19:16 #19284 阿列克谢-维亚兹米 金。 对你来说,只有一个希望,就是你能学会r-ku)install.packages("TTR","uwot") clos <- d$X.CLOSE. get.ind <- function(x,n=5){ all_to.all_colums <- function(x,names){ cb <- combn(ncol(x),2) res <- matrix(ncol = 0,nrow = nrow(x)) for(i in 1:ncol(cb)){ j1 <- cb[1,i] j2 <- cb[2,i] res <- cbind(res, x[,j1] - x[,j2] ) colnames(res) <- paste0(names, 1:ncol(res)) } return(res)} library(TTR) aroon <- aroon(x,n) BBands <- BBands(x,n) ; BBands <- all_to.all_colums( BBands, names = "BBands") CCI <- CCI(x,n) CMO <- CMO(x,n) DEMA <- diff(c(0,DEMA(x,n))) Donchian <- DonchianChannel(x,n) ; Donchian <- all_to.all_colums( Donchian, names = "Donchian") MACD <- MACD(x,n) moment <- momentum(x,n) PBands <- PBands(x,n) ; PBands <- all_to.all_colums( PBands, names = "PBands") RSI <- RSI(x,n) SAR <- diff(c(0,SAR(cbind(x,x,n)))) SMA <- diff(c(0,SMA(x,n))) stoch <- stoch(x,n) TDI <- TDI(x,n) VHF <- VHF(x,n) WPR <- WPR(x,n) ind <- cbind.data.frame(aroon,BBands,CCI,CMO,DEMA,Donchian, MACD,moment,PBands, RSI,SAR,SMA,stoch,TDI,VHF,WPR) return(ind) } get.target <- function(x, change){ zz <- TTR::ZigZag(x,change = change,percent = F) zz <- c(diff(zz),0) ; zz[zz>=0] <- 1 ; zz[zz<0] <- -1 return(zz) } X <- get.ind(clos) Y <- as.factor(get.target(clos,change = 0.001)) library(uwot) train.idx <- 100:8000 test.idx <- 8001:10000 UM <- umap(X = X[train.idx,], y = Y[train.idx], approx_pow = TRUE, n_components = 3, ret_model = TRUE, n_threads = 4 L, scale = T) predict.train <- umap_transform(X = X[train.idx,], model = UM, n_threads = 4 L, verbose = TRUE) predict.test <- umap_transform(X = X[test.idx,], model = UM, n_threads = 4 L, verbose = TRUE) library(car) scatter3d(x = predict.train[,1], y = predict.train[,2], z = predict.train[,3], groups = Y[train.idx], grid = F, surface = F, ellipsoid = F, bg.col = "black",surface.col = c(2,3)) 有两个功能get.indиget.target第一个创建了一套日期指标,第二个是 "之 "字形的目标。你需要做的就是加载收盘价 为10k的数据,并将其写入变量close 中。并获得你的umap与目标 https://github.com/jlmelville/uwot Aleksey Vyazmikin 2020.07.28 20:51 #19285 mytarmailS: 对你来说,只有一个希望,就是你能学会P)有两个功能и第一个创建了一套日期指标,第二个创建了一个 "之 "字形的目标。你需要做的就是加载收盘价 为10k的数据,并将其写入变量close 中。并得到你的umap与目标 https://github.com/jlmelville/uwot 非常高兴见到你,谢谢 我希望有更多的评论 :) 这里的问题是,如何将文件中的预测器与产生的目标同步? mytarmailS 2020.07.28 20:59 #19286 Aleksey Vyazmikin: 非常高兴见到你,谢谢你我希望有更多的评论 :)这里的问题是如何将文件中的预测器与目标同步? 那么,由于目标是用价格建立的,它已经是同步的,如果预测器是用同样的场景建立的,那就意味着它们也是同步的) 或者我不明白这个问题。 我试着给变量命名,以便在没有注释的情况下,它们可以被理解。 fxsaber 2020.07.28 21:10 #19287 一个书呆子的问题。 有三个变量A、B、C。某种条件是由他们手写的。比如说。 (A > B) && (A - B < C) && (A + 3 * C > 2 * B) 我想自动重现这个条件。我不需要找到它,因为我已经知道它。但我需要有例如几十个权重系数,这些系数的组合可以高概率地达到这个条件,当我在那里设置A、B、C(多项式或HC - 我不知道,因为我知道零)并得到原始条件。 我感兴趣的是,所需的函数有什么样的输入权重,有多少输入权重,这样的原始条件可以通过权重来重现? Aleksey Vyazmikin 2020.07.28 21:25 #19288 所以,这些树是如何被训练成集群的,我告诉你,也给你看。 我们得到了以下类别识别的模型 历史上有一个相当准确的0.9196756的精确度--也就是说,集群的逻辑是相当可重复的。 然后我为每个群组训练了一个模型 第1组 第2组 第3组 第4组 所有集群的准确率都在0.53左右。 这就是模型在没有分裂成群的情况下的样子 准确度为0.5293815,与聚类的准确度基本相同。 如果我们比较集群的模型和整个样本的一个树状模型,我们看到集群树有更多的叶子,有目标1和-1的广义样本信息,这在理论上是好的。 让我们看看测试结果如何--首先让我们看一下训练期的情况 没有集群划分的模型。 具有划分集群的模型。 我们看到,没有聚类的模型准确度更高,但与聚类的模型交易更多,这使得财务表现更好。 现在我们来看看训练之外的样本。 而这里是我们的集群。 而没有集群的模型。 这里的情况似乎是相反的--当市场从4月开始抽搐时,大量的交易产生了不利的影响。 我决定在降序直方图上单独看一下集群模型的叶子,如果没有集群的话。 一共有6片无利可图的叶子(零目标删除--这是禁止进入的),原来我们的集群不对? Aleksey Vyazmikin 2020.07.28 21:29 #19289 mytarmailS: 那么,由于目标是基于价格的,它已经是同步的了,如果预测器是基于同一场景的,它们也是同步的)或者我不明白这个问题。我试着给变量命名,以便在没有注释的情况下,它们可以被理解。 如何将一个带有预测因子和收盘价 的数据集加载到带有收盘价的列中,而不是使用R中生成指标的变量? 按照我的理解,既然目标是ZZ顶,那么带有预测器的部分样本应该被过滤掉,这里,所以为了给预测器提供信息,也应该过滤掉带有预测器的表格,还是什么? Maxim Dmitrievsky 2020.07.28 21:45 #19290 fxsaber: 一个书呆子的问题。有三个变量A、B、C。某种条件是由他们手写的。比如说。我想自动重现这个条件。我不需要找到它,因为我已经知道它。但我需要有例如几十个权重系数,这些系数的组合可以高概率地达到这个条件,当我在那里设置A、B、C(多项式或HC - 我不知道,因为我知道零)并得到原始条件。我感兴趣的是,所需的函数有什么样的,有多少输入权重,这样的原始条件可以通过权重再现?或者(A > B) && (A - B < C) && (A + 3 * C > 2 * B)NS的输入是数值A,B,C的n次方(比方说,1000),输出是你对这些数值的公式的答案为0;1。试试吧。并查看分类误差以及模型对条件的再现程度。如果你想看看到底是什么种类,并对其进行解释,你可以通过树木来进行。 变体2(如果第一个变体效果不好)--A、B、A-B、C、A+3*C、2B--变量,都和第一个变体中的变量一样,放在树上。你可以看到它的结构就像上面Alexey的图片一样 1...192219231924192519261927192819291930193119321933193419351936...3399 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
为促进个人谈话
您的选择
普通版
正如你所看到的,这些值是完全不同的,你可以自己检查一下
在我的模型中。
因此只有一列,但这并不重要。
===================UPD
伙计,你每次运行 umap_tranform 时它们都是不同的,它不应该是这样的
没有注意到。已经有很长一段时间了...
为促进个人谈话
您的选择
普通版
正如你所看到的,这些值是完全不同的,你可以自己检查一下
在我的模型中。
因此只有一列,但这并不重要。
===================UPD
伙计,你每次运行 umap_tranform 时,它们都是不同的,它不应该是这样的
通常为了重复性,你将(内置HSS的)种子值设置为某个值。如果没有,则使用随机。也许这个包里也有种子--看看吧。
我想是的,但问题是,如果没有RMS,它应该总是一样的,在 "umap "模拟包中,结果总是一样的。
对你来说,只有一个希望,就是你能学会r-ku)
有两个功能
get.indи
get.target第一个创建了一套日期指标,第二个是 "之 "字形的目标。
你需要做的就是加载收盘价 为10k的数据,并将其写入变量close 中。
并获得你的umap与目标
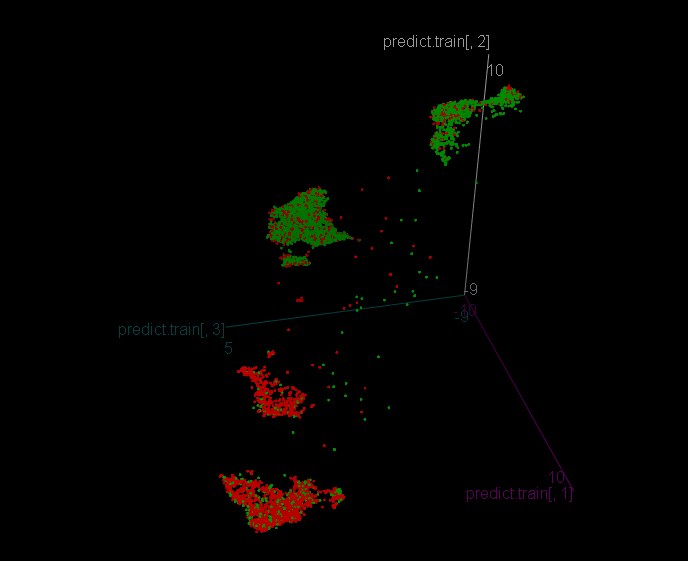
https://github.com/jlmelville/uwot对你来说,只有一个希望,就是你能学会P)
有两个功能
и
第一个创建了一套日期指标,第二个创建了一个 "之 "字形的目标。
你需要做的就是加载收盘价 为10k的数据,并将其写入变量close 中。
并得到你的umap与目标
https://github.com/jlmelville/uwot非常高兴见到你,谢谢
我希望有更多的评论 :)
这里的问题是,如何将文件中的预测器与产生的目标同步?
非常高兴见到你,谢谢你
我希望有更多的评论 :)
这里的问题是如何将文件中的预测器与目标同步?
那么,由于目标是用价格建立的,它已经是同步的,如果预测器是用同样的场景建立的,那就意味着它们也是同步的)
或者我不明白这个问题。
我试着给变量命名,以便在没有注释的情况下,它们可以被理解。
一个书呆子的问题。
有三个变量A、B、C。某种条件是由他们手写的。比如说。
我想自动重现这个条件。我不需要找到它,因为我已经知道它。但我需要有例如几十个权重系数,这些系数的组合可以高概率地达到这个条件,当我在那里设置A、B、C(多项式或HC - 我不知道,因为我知道零)并得到原始条件。
我感兴趣的是,所需的函数有什么样的输入权重,有多少输入权重,这样的原始条件可以通过权重来重现?
所以,这些树是如何被训练成集群的,我告诉你,也给你看。
我们得到了以下类别识别的模型
历史上有一个相当准确的0.9196756的精确度--也就是说,集群的逻辑是相当可重复的。
然后我为每个群组训练了一个模型
第1组
第2组
第3组
第4组
所有集群的准确率都在0.53左右。
这就是模型在没有分裂成群的情况下的样子
准确度为0.5293815,与聚类的准确度基本相同。
如果我们比较集群的模型和整个样本的一个树状模型,我们看到集群树有更多的叶子,有目标1和-1的广义样本信息,这在理论上是好的。
让我们看看测试结果如何--首先让我们看一下训练期的情况
没有集群划分的模型。
具有划分集群的模型。
我们看到,没有聚类的模型准确度更高,但与聚类的模型交易更多,这使得财务表现更好。
现在我们来看看训练之外的样本。
而这里是我们的集群。
而没有集群的模型。
这里的情况似乎是相反的--当市场从4月开始抽搐时,大量的交易产生了不利的影响。
我决定在降序直方图上单独看一下集群模型的叶子,如果没有集群的话。
一共有6片无利可图的叶子(零目标删除--这是禁止进入的),原来我们的集群不对?
那么,由于目标是基于价格的,它已经是同步的了,如果预测器是基于同一场景的,它们也是同步的)
或者我不明白这个问题。
我试着给变量命名,以便在没有注释的情况下,它们可以被理解。
如何将一个带有预测因子和收盘价 的数据集加载到带有收盘价的列中,而不是使用R中生成指标的变量?
按照我的理解,既然目标是ZZ顶,那么带有预测器的部分样本应该被过滤掉,这里,所以为了给预测器提供信息,也应该过滤掉带有预测器的表格,还是什么?
一个书呆子的问题。
有三个变量A、B、C。某种条件是由他们手写的。比如说。
我想自动重现这个条件。我不需要找到它,因为我已经知道它。但我需要有例如几十个权重系数,这些系数的组合可以高概率地达到这个条件,当我在那里设置A、B、C(多项式或HC - 我不知道,因为我知道零)并得到原始条件。
我感兴趣的是,所需的函数有什么样的,有多少输入权重,这样的原始条件可以通过权重再现?
或者
NS的输入是数值A,B,C的n次方(比方说,1000),输出是你对这些数值的公式的答案为0;1。试试吧。并查看分类误差以及模型对条件的再现程度。
如果你想看看到底是什么种类,并对其进行解释,你可以通过树木来进行。
变体2(如果第一个变体效果不好)--A、B、A-B、C、A+3*C、2B--变量,都和第一个变体中的变量一样,放在树上。你可以看到它的结构就像上面Alexey的图片一样