Ticarette makine öğrenimi: teori, pratik, ticaret ve daha fazlası - sayfa 3009
Alım-satım fırsatlarını kaçırıyorsunuz:
- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Kayıt
Giriş yap
Gizlilik ve Veri Koruma Politikasını ve MQL5.com Kullanım Şartlarını kabul edersiniz
Hesabınız yoksa, lütfen kaydolun
Ancak en önemlisi, mevcut özelliklerin tahmin gücünün gelecekte değişmediğine veya zayıf bir şekilde değiştiğine dair teorik bir kanıt olmalıdır. Buharlı silindirin tamamında en önemli şey budur.
Ne yazık ki kimse bunu bulamadı, aksi takdirde burada değil tropik adalarda olurdu))))
Evet. 1 ağaç veya regresyon bile, eğer varsa ve değişmiyorsa bir örüntü bulabilir.
1. 20'den daha az sınıflandırma hatası olan bir öğretmen-özellik çiftine sahip olan başka biri var mı?
Çok kolay. Düzinelerce veri kümesini oluşturabilirim. Şu anda TP=50 ve SL=500'ü araştırıyorum. Öğretmenin işaretlemesinde ortalama %10 hata var. 20 olursa erik modeli olur.
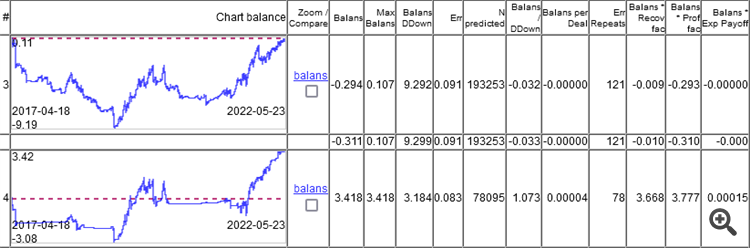
Yani mesele sınıflandırma hatasında değil, tüm kar ve zararların toplanması sonucu ortaya çıkan sonuçta.
Gördüğünüz gibi, en iyi model %9,1'lik bir hataya sahip ve %8,3'lük bir hata ile bir şeyler kazanabilirsiniz.
Grafikler sadece haftada bir yeniden eğitim ile Walking Forward tarafından elde edilen OOS'u göstermektedir, 5 yıl boyunca toplam 264 yeniden eğitim.
Modelin %9,1'lik bir sınıflandırma hatası ile 0'da çalışması ilginçtir ve 50/500 = 0,1, yani %10 olmalıdır. Görünüşe göre %1 spread'i yedi (çubuk başına minimum, gerçek olan daha büyük olacaktır).
Öncelikle modelin içinin çöplerle dolu olduğunu fark etmelisiniz...
Eğer eğitimli bir ahşap modeli içindeki kurallara ve bu kuralların istatistiklerine ayırırsanız.
:
ve kural hatasının örneklemde ortaya çıkma sıklığına bağımlılığını analiz ederseniz.
elde ederiz
O zaman bu alanla ilgileniyoruz
Kuralların çok iyi işlediği, ancak o kadar nadir görülürler ki, bunlara ilişkin istatistiklerin gerçekliğinden şüphe etmek mantıklıdır, çünkü 10-30 gözlem istatistik değildir
Öncelikle modelin içinin çöplerle dolu olduğunu fark etmelisiniz...
Eğitimli bir ahşap modeli, içindeki kurallara ve bu kurallara ilişkin istatistiklere ayrıştırırsanız.
gibi:
ve err kuralının hatasının örneklemde meydana gelme sıklığına olan bağımlılığını analiz edin
elde ederiz
Son gönderilerin karanlığında sadece bir güneş ışığı
eğer varsa, bununla ilgili bir makale olacak.
Eğer varsa, bununla ilgili bir makale olacak.
Norm, son makalem de aynı şey hakkındaydı. Ama sizin yönteminiz daha hızlıysa, bu bir artı.
Ne demek daha hızlı?
Ne demek daha hızlı?
Hız açısından.
5 km'lik bir örnekte yaklaşık 5-15 saniye
5 km'lik bir örnekte yaklaşık 5-15 saniye.
Başlangıçtan TC'yi almaya kadar olan tüm süreci kastediyorum.
Birkaç kez yeniden eğitilen 2 modelim var, bu yüzden çok hızlı değil, ama kabul edilebilir.
Ve sonunda tam olarak neyi elediklerini bilmiyorum.
Yani, başlangıçtan TC'yi almaya kadar olan tüm süreç.
Birkaç kez yeniden eğitilen 2 modelim var, bu yüzden çok hızlı değil ama kabul edilebilir
ve sonunda, tam olarak neyi taradıklarını bilmiyorum.
5 bin tren.
Geçerli 60k.
model eğitimi - 1-3 saniye
kural çıkarma - 5-10 saniye
her kuralın (20-30 bin kural) geçerliliğini kontrol etmek 60k 1-2 dakika
Elbette her şey yaklaşıktır ve özelliklerin ve verilerin sayısına bağlıdır