
Rede neural na prática: O primeiro neurônio

Introdução
Talvez você esteja pensando: Mas que falha é esta da qual você está falando? Não consegui perceber nada de errado. O neurônio funcionou perfeitamente nos testes que fiz. Bem, vamos voltar um pouco, nesta mesma série sobre redes neurais, para que você possa entender do que estou falando.
Nos primeiros artigos sobre rede neural. Mostrei como, poderíamos forçar a máquina a criar uma equação de reta. Inicialmente a equação estava pressa a origem nos eixos cartesianos. Ou seja, a reta obrigatoriamente passava pelo ponto (0, 0). Isto por que o valor da constante <b> na equação vista abaixo era zero.
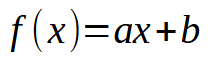
Apesar de usamos o mínimo quadrado, para tentar encontrar uma equação adequada. Isto para que o conjunto de dados, ou conhecimento prévio, contido no banco de dados, pudesse ser adequadamente representado, na forma de uma equação matemática. Aquela modelagem, não conseguiria forçar a procura de uma equação de fato adequada. Isto por que, dependendo dos dados presentes no banco de conhecimento, precisaríamos que o valor da constante <b>, fosse diferente de zero.
Se você estudar com calma aqueles artigos anteriores, irá notar que foi preciso criar um certo malabarismo matemático. Isto para que o melhor valor possível fosse definido tanto para a constante <a> que é o coeficiente angular, como para a constante <b> que é o ponto de intersecção. Tais manobras, permitiam que a equação de reta mais adequada fosse encontrada. Sendo mostradas duas forma de fazer isto. Uma via cálculos de derivadas e outro via cálculos matriciais.
No entanto, para o que precisamos fazer aqui, deste momento em diante. Tais cálculos não nos serão de utilidade. Visto que precisamos modelar uma outra forma de encontrar as constantes, da equação de reta. No artigo anterior, mostrei como poderíamos fazer para encontrar a constante que representa o coeficiente angular. Espero que você tenha se divertido, e brincado bastante com aquele código. Pois agora vamos fazer algo um pouco mais complicado. Porém, apesar de ser só um pouco mais complicado, irá de fato abrir as portas para um monte de outras coisas. Literalmente, este talvez venha a ser o artigo mais interessante que você verá nesta série sobre redes neurais. Já que depois dele, tudo será muito mais simples e prático.
Por que gostam tanto de complicar as coisas
Muito bem meu caro leitor, antes de vermos a parte do código em si. Gostaria de tentar lhe ajudar a entender algumas coisas. Normalmente quando você procurar estudar sobre redes neurais, irá ver um monte de termos. Literalmente é uma avalanche de termos. Não sei por que, as pessoas que querem explicar sobre redes neurais gostam tanto de complicar algo, que é simples. Ao meu ver não existe motivo para tal coisa. Mas não estou aqui para julgar ou fazer pouco caso. Estou aqui, para lhe explicar como as coisas funcionam por debaixo dos panos.
Para simplificar ao máximo a coisa, vou focar em alguns termos que vira e mexe alguém diz sobre redes neurais. Vamos ao primeiro: Pesos. Este termo pesos, nada mais é do que o coeficiente angular da equação de reta. Não importa o que queiram dizer. O termo peso, simplesmente diz respeito ao coeficiente angular. Outro termo também muito divulgado: Viés. Bem este termo, que você pode ouvir como sendo: Bias. Não é uma coisa de outro mundo. Ou restrito apenas a redes neurais ou inteligência artificial. Nada disto. Este termo, nada mais é do que o ponto de intersecção. Lembrando que estamos lidando com uma reta secante. Por favor não confunda as coisas.
Estou dizendo isto, pois tem muita gente que adora complicar as coisas.
Eles pegam algo simples, e começam a inventar uma série de coisas e penduricalhos, a fim de apenas complicar algo que qualquer um pode entender. Quando o assunto é programação, ou ciências exatas. Quanto mais simples melhor. Quando a coisa começa a ficar cheia de penduricalhos, enfeites ou coisas para desviar a nossa atenção. É bom parar, remover toda aquela palhaçada e maquiagem. Para assim conseguir enxergar a verdadeira realidade. Muitos vão dizer que a coisa é complicada. Que é preciso ser um expert na área para conseguir entender ou implementar uma rede neural. Que só dá para fazer usando, esta ou aquela linguagem. Com este ou aquele recurso. Mas até o momento, você, meu caro e estimado leitor, deve ter notado que, uma rede neural não é complicada. Ela é simples e não tem motivo para pânico ou histeria, como muitos gostam de querer provocar nas redes sociais.
O nascimento do primeiro neurônio
Para que o nosso primeiro neurônio venha a surgir. E uma vez que ele surgir, não precisaremos mais mexer nele, como você verá depois. Precisamos primeiro entender o que temos em mãos. Nosso neurônio atual, se comporta como a animação abaixo.
Esta é a mesma animação vista lá no artigo Rede neural na prática: Reta Secante. Ou seja, acabamos de dar o primeiro passo para construir um neurônio que consiga executar algo que antes era feito por nos. Usando as teclas de direção. Porém, você deve ter notado que isto não é o suficiente. Precisamos de fato incluir a constante de intersecção. Para que a equação obtida fique ainda melhor. Você pode estar achando que para fazer isto será algo extremamente complicado. Mas não. De fato fazer isto é tão, mas tão simples que chega a ser sem graça. Veja como adicionamos a constante de intersecção ao neurônio. Isto pode ser apreciado olhando primeiro o fragmento logo abaixo.
01. //+------------------------------------------------------------------+ 02. double Cost(const double w, const double b) 03. { 04. double err, fx, x; 05. 06. err = 0; 07. for (uint c = 0; c < nTrain; c++) 08. { 09. x = Train[c][0]; 10. fx = a * w + b; 11. err += MathPow(fx - Train[c][1], 2); 12. } 13. 14. return err / nTrain; 15. } 16. //+------------------------------------------------------------------+
Estou fazendo questão, de dividir o código em fragmentos, para que você, meu caro leitor, entenda de forma detalhada o que está sendo feito. E depois me responda: Se é ou não complicado. Ou se precisa de toda aquela complicação que muitos gostam de adicionar quando falam de redes neurais.
Preste muita atenção, pois o nível de complexidade chega a beira do absurdo. ( RISOS ). Na linha nove pegamos no nosso valor de treinamento, e colocamos na variável X. Já na linha dez, fazemos a fatoração. Puxa vida, que conta mais complicada. Mas espere um pouco. Esta não é justamente a equação mostrada no começo? A tal equação da reta. Cara você tá de brincadeira. Esta coisa não vai funcionar como um neurônio, usado em programas de inteligência artificial.
Calma meu caro leitor. Você verá que isto vai sim funcionar. Da mesma forma que todo e qualquer programa de inteligência artificial ou redes neurais. Não importa o qual complicado queiram lhe explicar sobre o assunto. Você verá que isto daqui, é exatamente a mesma coisa que é implementada, em toda e qualquer tipo de rede neural. O que muda é o próximo passo que veremos em breve. Mas a mudança não é assim tão grande como você pode já deve estar pensando. Calma, vamos ver as coisas com calma.
Uma vez que o cálculo de erro, ou custo, tenha sido atualizado. Podemos atualizar o fragmento que irá ajustar estes dois parâmetros na função de custo. Isto será feito aos poucos, para que você entenda alguns detalhes envolvidos. Assim, a primeira coisa a fazer, é modificar o código original, presente no artigo anterior, para um novo código visto abaixo.
01. //+------------------------------------------------------------------+ 02. void OnStart() 03. { 04. double weight, ew, eb, e1, bias; 05. int f = FileOpen("Cost.csv", FILE_COMMON | FILE_WRITE | FILE_CSV); 06. 07. Print("The first neuron..."); 08. MathSrand(512); 09. weight = (double)macroRandom; 10. bias = (double)macroRandom; 11. 12. for(ulong c = 0; (c < ULONG_MAX) && ((e1 = Cost(weight, bias)) > eps); c++) 13. { 14. ew = (Cost(weight + eps, bias) - e1) / eps; 15. eb = (Cost(weight, bias + eps) - e1) / eps; 16. weight -= (ew * eps); 17. bias -= (eb * eps); 18. if (f != INVALID_HANDLE) 19. FileWriteString(f, StringFormat("%I64u;%f;%f;%f;%f;%f\n", c, weight, ew, bias, eb, e1)); 20. } 21. if (f != INVALID_HANDLE) 22. FileClose(f); 23. Print("Weight: ", weight, " Bias: ", bias); 24. Print("Error Weight: ", ew); 25. Print("Error Bias: ", eb); 26. Print("Error: ", e1); 27. } 28. //+------------------------------------------------------------------+
Ao executar o script depois destas modificações, você verá algo parecido com a imagem abaixo.
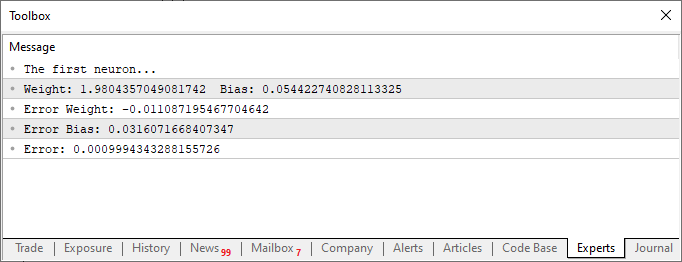
Agora vamos observar apenas e somente este segundo fragmento de código. Na linha quatro, adicionamos e modificamos algumas variáveis. Algo bem simples. Já na linha dez, dizemos para a aplicação definir um valor aleatório para o tal viés, ou nossa constante de intersecção. Agora veja, que precisaremos passar este valor também para a função Cost. Isto é feito, nas linhas 12, 14 e 15. Porém, a parte interessante é que estaremos gerando dois tipos de erros agregados. Uma para o valor de peso e outro para o valor do viés. Você deve entender, que apesar de ambos fazerem parte da mesma equação, eles deverão ser ajustados de maneira diferente. Assim precisamos saber qual o erro que cada um representa dentro do sistema geral.
Sabendo isto, podemos nas linhas 16 e 17, ajustar de forma adequada os valores para uma próxima interação do laço for. Agora, da mesma maneira que foi feito no artigo anterior, temos também o lançamento dos valores para dentro de um arquivo CSV. Isto nos permitirá gerar um gráfico para estudar como estes valores estão sendo ajustados.
Bem, neste ponto, nosso primeiro neurônio se encontra completamente construído. Mas existem alguns detalhes dos quais você já poderá entender, se observar o código completo deste neurônio. O código na íntegra é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. //+------------------------------------------------------------------+ 06. double Train[][2] { 07. {0, 0}, 08. {1, 2}, 09. {2, 4}, 10. {3, 6}, 11. {4, 8}, 12. }; 13. //+------------------------------------------------------------------+ 14. const uint nTrain = Train.Size() / 2; 15. const double eps = 1e-3; 16. //+------------------------------------------------------------------+ 17. double Cost(const double w, const double b) 18. { 19. double err, fx, a; 20. 21. err = 0; 22. for (uint c = 0; c < nTrain; c++) 23. { 24. a = Train[c][0]; 25. fx = a * w + b; 26. err += MathPow(fx - Train[c][1], 2); 27. } 28. 29. return err / nTrain; 30. } 31. //+------------------------------------------------------------------+ 32. void OnStart() 33. { 34. double weight, ew, eb, e1, bias; 35. int f = FileOpen("Cost.csv", FILE_COMMON | FILE_WRITE | FILE_CSV); 36. 37. Print("The first neuron..."); 38. MathSrand(512); 39. weight = (double)macroRandom; 40. bias = (double)macroRandom; 41. 42. for(ulong c = 0; (c < ULONG_MAX) && ((e1 = Cost(weight, bias)) > eps); c++) 43. { 44. ew = (Cost(weight + eps, bias) - e1) / eps; 45. eb = (Cost(weight, bias + eps) - e1) / eps; 46. weight -= (ew * eps); 47. bias -= (eb * eps); 48. if (f != INVALID_HANDLE) 49. FileWriteString(f, StringFormat("%I64u;%f;%f;%f;%f;%f\n", c, weight, ew, bias, eb, e1)); 50. } 51. if (f != INVALID_HANDLE) 52. FileClose(f); 53. Print("Weight: ", weight, " Bias: ", bias); 54. Print("Error Weight: ", ew); 55. Print("Error Bias: ", eb); 56. Print("Error: ", e1); 57. } 58. //+------------------------------------------------------------------+
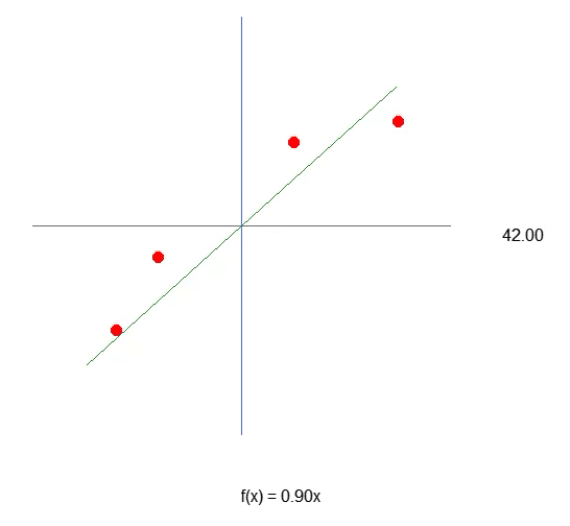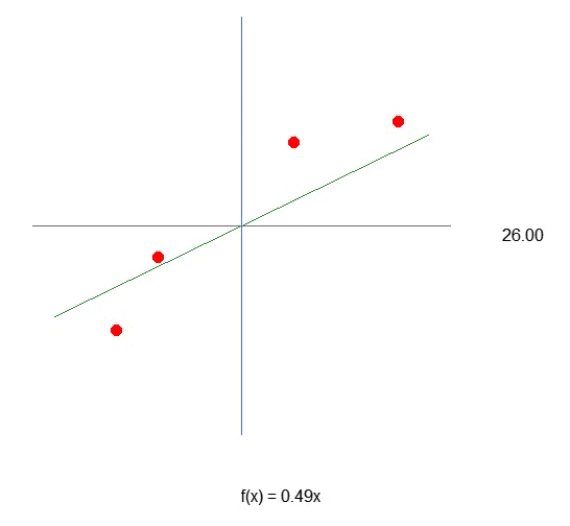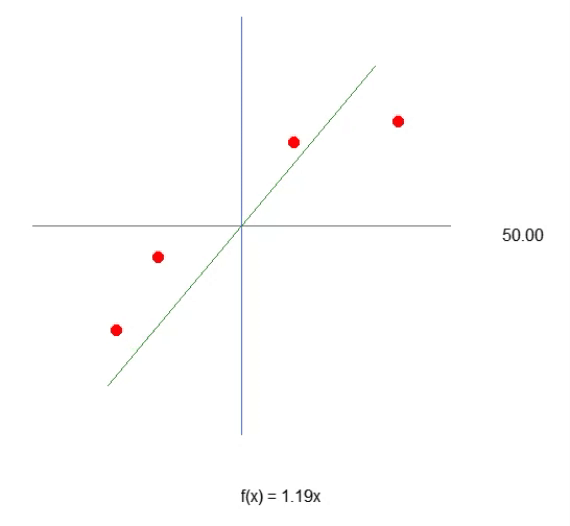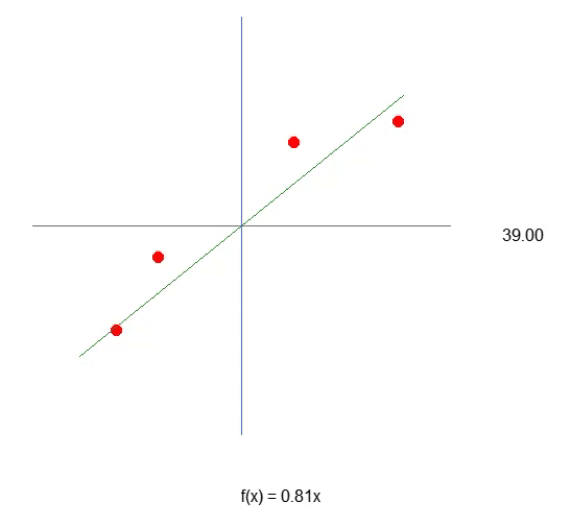
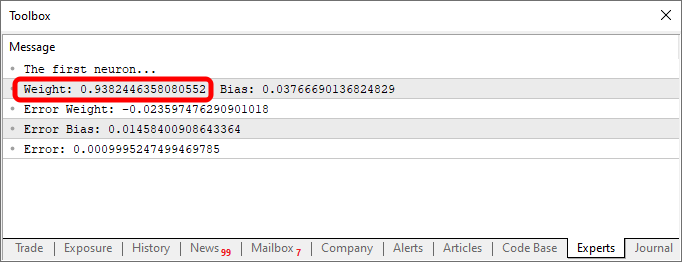
Repare uma coisa interessante, tanto no código como no resultado visto na imagem acima. Na linha seis, estão os valores usados para treinar o neurônio. Claramente você nota que o valor usado na multiplicação é dois. Porém o neurônio nos diz que ele é: 1.9804357049081742. E nitidamente podemos também perceber que o ponto de intersecção seria zero. Mas no neurônio nos diz que ele seria: 0.054422740828113325. Ok, considerando o fato de que na linha 15 estamos aceitando que o erro possa ser de: 0.001 até que não está tão mal assim. Isto por que o erro final informado pelo neurônio foi de: 0.0009994343288155726. Ou seja, abaixo do erro que dissemos ser o adequado.
Estas diferenças nas quais você claramente consegue notar, é que são o tal índice de probabilidade, da informação está correta. Normalmente isto é representado em termos de porcentagem. Mas você nunca os verá como sendo 100%. O número pode ser bem próximo dos 100%, mas nunca será 100%, devido a justamente esta falha de aproximação com o resultado correto.
Apesar disto, este índice de probabilidade, não é o índice de certeza sobre uma informação. Ainda não estamos trabalhando de forma gerar este segundo índice. Apenas estamos treinado e checando se o neurônio, está conseguindo estabelecer uma correlação entre os dados de treinamento. Mas você já deve estar pensando o seguinte: Esta coisa de neurônio é inútil. Já que da forma como você a está criando, ela não serve para mais nada. Apenas servirá para procurar um número que todos já sabemos qual é. O que eu quero mesmo é um sistema que consiga me dizer as coisas. Consiga escrever um texto, ou mesmo um código. Quem sabe, até mesmo um programa que consiga operar no mercado financeiro e me dar algum dinheiro, sempre que eu precisar.
Certo. Você realmente tem grandes interesses em mente. Mas se você, meu caro leitor, pensa e está procurando saber sobre redes neurais, ou inteligência artificial para tentar ganhar dinheiro. Sinto lhe informar, mas você não vai conseguir fazer isto. As únicas pessoas que realmente vão ganhar dinheiro com esta coisa, são as pessoas que vender os tais sistemas de redes neurais ou inteligência artificial. Isto ao conseguir convencer todos demais, de que a inteligência artificial, ou rede neural, consegue superar um bom profissional. Fora estas pessoas, que vão tirar todo o dinheiro das demais, ao vender tais coisas. Ninguém mais ganhará dinheiro com isto. Se fosse assim, por que eu haveria de escrever estes artigos explicando como funciona. Ou mesmo, por que algumas pessoas igualmente conhecedoras do funcionamento de tais mecanismos. Explicariam como eles trabalham? Não faz sentido. Elas poderiam simplesmente ficar caladas. Ganhando dinheiro com uma rede neural bem treinada e pronto. Mas não é assim que as coisas funcionam na prática. Por isto esqueça esta de que vai criar uma rede neural, e sem nenhum conhecimento, vai conseguir ganhar dinheiro. Apenas pegando fragmentos de código aqui e ali.
Mas nada impede, que você, meu estimado leitor, consiga criar uma pequena rede neural, cujo objetivo seja lhe ajudar na tomada de decisões. Seja para compra, venda ou mesmo, para lhe ajudar a visualizar certas coisas no mercado de capitais. É possível fazer isto? Sim. De fato, estudando tudo que for necessário. Você, mesmo de forma lenta e com muito esforço e dedicação, conseguirá treinar uma rede neural para isto. Mas como acabei de dizer. Você precisará se esforçar para conseguir fazer isto. Mas é perfeitamente possível.
Muito bem. Já temos então o nosso primeiro neurônio. Mas antes que você se empolgue e comece a pensar em formas de usá-lo. Vamos ver um pouco melhor como ele está esquematizado. Para facilitar a visualização. Veja a imagem abaixo.
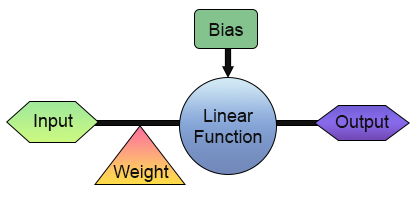
Nesta imagem acima, podemos ver o que está implementado no nosso neurônio. Veja que ele conta com uma entrada e uma saída. Sendo que esta única entrada recebe um peso nela. Bem isto talvez não seja tão útil afinal. Já que qual o sentido de termos uma entrada e uma saída? Tudo bem. Compreendo o seu descredito para isto que acabamos de criar. Mas talvez você não saiba, pois isto depende do quanto você conhece sobre diferentes assuntos. Mas na eletrônica digital, existe um circuito que tem uma entrada e uma saída. Na verdade seriam dois. Um é o inversor e ou outro é um buffer. Ambos são partes integrantes de diversos componentes ainda mais complexos. E este neurônio consegue aprender como ambos circuitos funcionam. Basta que você o treine para isto. Para o treinar para isto, tudo que seria necessário fazer seria mudar a matriz de treinamento para as mostradas abaixo.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ double Train[][2] { {0, 1}, {1, 0}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 2; const double eps = 1e-3; //+------------------------------------------------------------------+
Ao usar este fragmento no código, você receberia algo parecido com o mostrado na imagem abaixo:
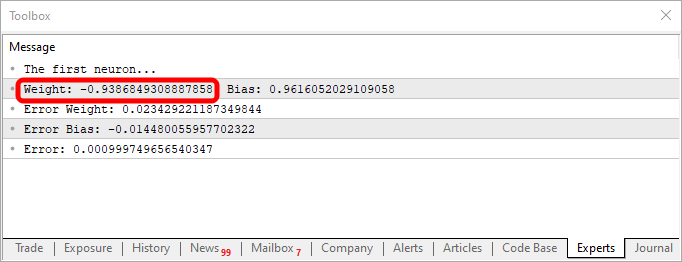
Perceba que o valor de weight está negativo. Isto implica que estaremos invertendo o valor que estiver entrando. Ou seja, temos um inversor. Já usando o fragmento que é visto logo a seguir, teríamos uma outra saída.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ double Train[][2] { {0, 0}, {1, 1}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 2; const double eps = 1e-3; //+------------------------------------------------------------------+
A saída no caso, é vista na imagem abaixo.
O simples fato de mudarmos as informações do banco de conhecimento, ou banco de dados. Que no nosso caso é um array de duas dimensões. Já permite que o mesmo código, consiga criar uma equação para representar as coisas. E é por isto que todos, absolutamente todos que se interessam por programação, gostam de brincar com redes neurais. Elas são muito divertidas de se trabalhar.
Função sigmoide
A partir deste momento, qualquer coisa que eu vier a mostrar, será apenas a ponta do topo do iceberg. Não importa o quanto possa parecer legal, divertido, complicado ou emocionante de ser programado. Tudo, absolutamente tudo, de agora em diante, será apenas um pequeno deslumbre de tudo que podemos fazer. Então meu caro leitor, deste momento em diante, você deve começar a estudar a coisa de uma forma um pouco mais independente. Apenas quero lhe guiar por um caminho, que lhe sirva de inspiração para novas descobertas. Sinta-se inteiramente a vontade para brincar e se divertir com o que será mostrado. Pois como foi dito a pouco, o único fator limitante será a sua imaginação.
Para que nosso único neurônio, consiga aprender, tendo mais entradas disponíveis. Você apenas precisará entender um pequeno e simples detalhe. Este pode ser visto na imagem abaixo.
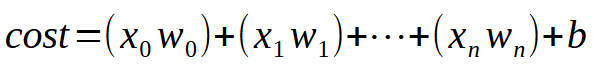
Ou da forma mais resumida, a mesma equação é mostrada logo a seguir.
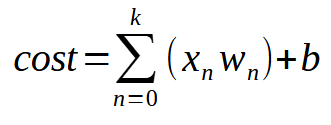
O valor <k> é o número de entradas que o nosso neurônio poderá vir a ter. Então veja que não importa, quantas entradas são necessárias. Tudo que precisamos fazer, é apenas adicionar a quantidade necessária de entradas, para que o neurônio aprenda como lidar com cada nova situação. Porém, a partir da segunda entrada, a função deixa se ser uma equação de reta e passa a ser uma equação com qualquer formato possível. Isto para que o neurônio, consiga encontrar a melhor forma de lidar com diferentes tipos de treinamento.
Agora a coisa realmente ficou séria. Pois podemos fazer com que um único neurônio, consiga aprender diversas coisas diferentes. Porém existe um pequeno problema no fato de deixarmos de lidar com uma equação de reta. Para entender isto, vamos modificar o programa de forma que ele fique como mostrado abaixo:
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ double Train[][3] { {0, 0, 0}, {0, 1, 1}, {1, 0, 1}, {1, 1, 1}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 3; const double eps = 1e-3; //+------------------------------------------------------------------+ double Cost(const double w0, const double w1, const double b) { double err; err = 0; for (uint c = 0; c < nTrain; c++) err += MathPow(((Train[c][0] * w0) + (Train[c][1] * w1) + b) - Train[c][2], 2); return err / nTrain; } //+------------------------------------------------------------------+ void OnStart() { double w0, w1, err, ew0, ew1, eb, bias; Print("The Mini Neuron..."); MathSrand(512); w0 = (double)macroRandom; w1 = (double)macroRandom; bias = (double)macroRandom; for (ulong c = 0; (c < 3000) && ((err = Cost(w0, w1, bias)) > eps); c++) { ew0 = (Cost(w0 + eps, w1, bias) - err) / eps; ew1 = (Cost(w0, w1 + eps, bias) - err) / eps; eb = (Cost(w0, w1, bias + eps) - err) / eps; w0 -= (ew0 * eps); w1 -= (ew1 * eps); bias -= (eb * eps); PrintFormat("%I64u > w0: %.4f %.4f || w1: %.4f %.4f || b: %.4f %.4f || %.4f", c, w0, ew0, w1, ew1, bias, eb, err); } Print("w0 = ", w0, " || w1 = ", w1, " || Bias = ", bias); Print("Error Weight 0: ", ew0); Print("Error Weight 1: ", ew1); Print("Error Bias: ", eb); Print("Error: ", err); } //+------------------------------------------------------------------+
Quando você executar este código terá um resultado parecido com a imagem abaixo:
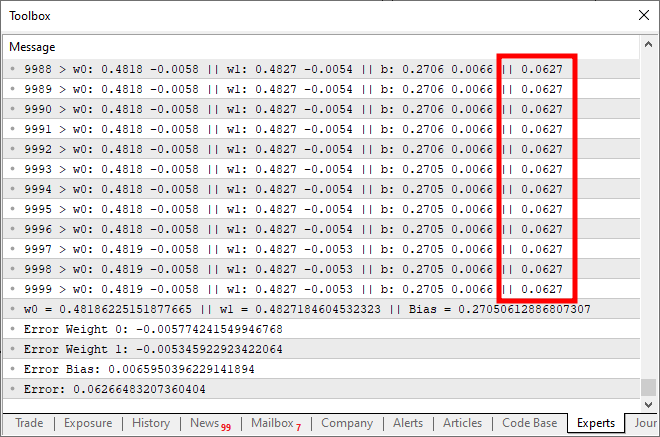
Bem, o que está errado aqui. Veja que no código apenas adicionamos a possibilidade de novas entradas. E isto está correto da forma como foi feita. Mas observe uma coisa aqui. Note que perto de dez mil interações, o custo simplesmente parou de cair, ou se tiver caindo está fazendo isto muito devagar. Mas por que disto acontecer? O motivo é que está faltando uma coisa no neurônio. Algo que para uma única entrada não se fazia necessário. Mas que se torna necessário no momento em que desejamos adicionar novas entradas. Além de ser utilizado quando estivemos usando camadas de neurônios. Que é algo usando em aprendizado profundo. Mas isto será visto em outro momento. Por hora vamos nos concentrar na questão principal. Veja que o neurônio está chegando em um ponto de estagnação, onde ele simplesmente não consegue reduzir ainda mais o custo. Este problema é resolvido adicionando bem na saída, uma função de ativação. A função e a forma como as coisas irão acontecer aqui. Depende muito do tipo de coisa que queremos fazer. Não existe apenas uma forma de resolver está parte, podemos usar diversas outras funções para ativação. Mas normalmente se usa uma sigmoide. E o motivo é simples. Esta função nos permite trazer valores que vão de mais infinito até menos infinito para dentro de um range que fica entre 0 e 1. Mas em alguns casos a modificamos de forma que este mesmo range fique entre 1 e -1. Mas aqui vamos usar a forma básica. Esta função sigmoide é apresentada com a seguinte fórmula:
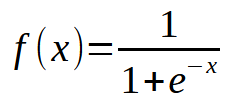
Ok, mas então como vamos aplicar isto no nosso código? Parece ser algo muito complicado. Na verdade meu caro leitor, é bem simples do que parece. No mesmo código visto acima. Será preciso mudar muito pouco, como você pode ver logo abaixo:
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) #define macroSigmoid(a) (1.0 / (1 + MathExp(-a))) //+------------------------------------------------------------------+ double Train[][3] { {0, 0, 0}, {0, 1, 1}, {1, 0, 1}, {1, 1, 1}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 3; const double eps = 1e-3; //+------------------------------------------------------------------+ double Cost(const double w0, const double w1, const double b) { double err; err = 0; for (uint c = 0; c < nTrain; c++) err += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * w1) + b) - Train[c][2]), 2); return err / nTrain; } //+------------------------------------------------------------------+ void OnStart() { double w0, w1, err, ew0, ew1, eb, bias; Print("The Mini Neuron..."); MathSrand(512); w0 = (double)macroRandom; w1 = (double)macroRandom; bias = (double)macroRandom; for (ulong c = 0; (c < ULONG_MAX) && ((err = Cost(w0, w1, bias)) > eps); c++) { ew0 = (Cost(w0 + eps, w1, bias) - err) / eps; ew1 = (Cost(w0, w1 + eps, bias) - err) / eps; eb = (Cost(w0, w1, bias + eps) - err) / eps; w0 -= (ew0 * eps); w1 -= (ew1 * eps); bias -= (eb * eps); PrintFormat("%I64u > w0: %.4f %.4f || w1: %.4f %.4f || b: %.4f %.4f || %.4f", c, w0, ew0, w1, ew1, bias, eb, err); } Print("w0 = ", w0, " || w1 = ", w1, " || Bias = ", bias); Print("Error Weight 0: ", ew0); Print("Error Weight 1: ", ew1); Print("Error Bias: ", eb); Print("Error: ", err); } //+------------------------------------------------------------------+
E ao executar este código mostrado acima, o resultado será algo parecido como o visto na imagem abaixo.
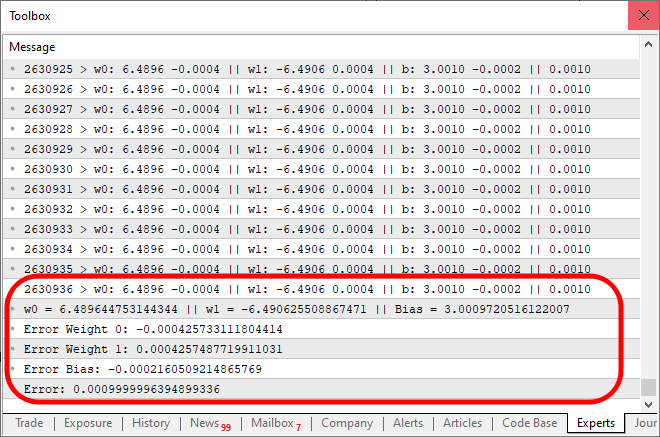
Note que foram necessárias 2630936 interações, para que o resultado dentro do erro esperado, fosse alcançado. O que não é nada mal. Você pode ter a impressão de que o programa começa a ficar um pouco lento. Isto usando apenas a CPU. Mas esta impressão se dá justamente pelo fato de que estamos imprimindo uma mensagem a cada interação do código. Podemos deixar o código um pouco mais rápido se substituirmos esta forma de apresentar as coisas por uma nova maneira. Ao mesmo tempo. Vamos também adicionar um pequeno código para testar a capacidade do neurônio. Assim o código final é o que você observa logo abaixo.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) #define macroSigmoid(a) (1.0 / (1 + MathExp(-a))) //+------------------------------------------------------------------+ double Train[][3] { {0, 0, 0}, {0, 1, 1}, {1, 0, 1}, {1, 1, 1}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 3; const double eps = 1e-3; //+------------------------------------------------------------------+ double Cost(const double w0, const double w1, const double b) { double err; err = 0; for (uint c = 0; c < nTrain; c++) err += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * w1) + b) - Train[c][2]), 2); return err / nTrain; } //+------------------------------------------------------------------+ void OnStart() { double w0, w1, err, ew0, ew1, eb, bias; ulong count; Print("The Mini Neuron..."); MathSrand(512); w0 = (double)macroRandom; w1 = (double)macroRandom; bias = (double)macroRandom; for (count = 0; (count < ULONG_MAX) && ((err = Cost(w0, w1, bias)) > eps); count++) { ew0 = (Cost(w0 + eps, w1, bias) - err) / eps; ew1 = (Cost(w0, w1 + eps, bias) - err) / eps; eb = (Cost(w0, w1, bias + eps) - err) / eps; w0 -= (ew0 * eps); w1 -= (ew1 * eps); bias -= (eb * eps); } PrintFormat("%I64u > w0: %.4f %.4f || w1: %.4f %.4f || b: %.4f %.4f || %.4f", count, w0, ew0, w1, ew1, bias, eb, err); Print("w0 = ", w0, " || w1 = ", w1, " || Bias = ", bias); Print("Error Weight 0: ", ew0); Print("Error Weight 1: ", ew1); Print("Error Bias: ", eb); Print("Error: ", err); Print("Testing the neuron..."); for (uchar p0 = 0; p0 < 2; p0++) for (uchar p1 = 0; p1 < 2; p1++) PrintFormat("%d OR %d IS %f", p0, p1, macroSigmoid((p0 * w0) + (p1 * w1) + bias)); } //+------------------------------------------------------------------+
Ao executar este código, você poderá vir a observar a seguinte mensagem, vista na imagem abaixo, sendo mostrada no terminal.
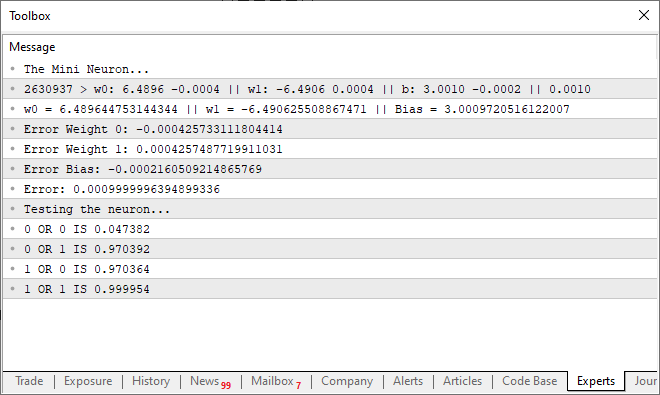
Ou seja, conseguimos fazer com que o nosso singelo neurônio, pudesse entender como uma PORTA OR funciona. Agora estamos entrando em um caminho sem volta. Já que nosso único neurônio, já começa a conseguir aprender coisas um pouco mais complexas. Do que simplesmente saber se algo está ou não relacionado entre si.
Considerações finais
Neste artigo começamos a de fato criar algo que muitos ficam admirados em ver funcionando. Pois este simples e singelo neurônio que conseguimos programar com muito pouco código em MQL5. Muitos dizem que precisamos de mil e uma coisas para fazer o que foi feito aqui. Mas espero que você, meu caro leitor, tenha conseguido entender como a coisa vai se desenvolvendo. Em poucos artigos, fiz um resumo de muito tempo que foi gasto por diversos pesquisadores. Note que apesar de ser algo relativamente muito simples. Bolar a forma como as coisas deveriam ser implementadas demorou um bom tempo. Tanto que, ainda existem pesquisas tentando fazer com que todos estes cálculos, sejam executados de forma mais fluida. Ou melhor dizendo, que as coisas passem a ser feitas de forma mais rápida. Aqui estamos usando apenas um único neurônio com duas entradas, cinco parâmetros e uma saída. E mesmo assim note que o sistema gasta um pouco de tempo, para conseguir encontrar a equação correta.
Claro que poderíamos usar OpenCL para começar a acelerar as coisas via GPU. Mas ao meu ver ainda é cedo para começar a pensar em tal solução. Podemos avançar um pouco mais antes de começar a de fato precisar da GPU para os cálculos. Mas de qualquer forma, se você realmente deseja se aprofundar no assunto de redes neurais. Sugiro fortemente que você pense em comprar uma GPU. Isto por que ela irá agilizar e muito certos tipos de atividades da rede neural.
 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso