In mathematics, the term chaos game, as coined by Michael Barnsley,1 originally referred to a method of creating a fractal, using a polygon and an initial point selected at random inside it.2 The fractal is created by iteratively creating a sequence of points, starting with the initial random point, in which each point in the sequence is a...
...
--
512を作って見てください。プログラムをパクることを怖がらないでください。:)出来上がったら、ここに投稿してください。
よっしゃー512パス、144000バーの場合。
まあ、そして60が最適なら、一般的にクールだ。
//---
つまり、このスレッドで紹介されている最弱のノートパソコンでは、このような結果になるのです。だから、とても期待できる。
//---
残念ながら、jooの 記事やニューラルネットワークにも手をつけておらず、一方でOpenCLも掘り下げて いないため、自由に論じることができません。コードの一行一行を理解しないと、あれもこれも使えない。すべてを知りたい。)))トレーディングプログラムのエンジンはまだ完成していません。やることが多すぎて、もう頭がグルグルしています。)))
CountBarsを30倍(4,320,000)に増やし、石の負荷に対する耐性をテストすることにしました。
どうでもいいことですが、動作して、暖かくなっても、あまり汗をかかない。温度は徐々に上昇しているが、すでに飽和状態に達している。
赤い線が温度、緑の線がコアの負荷です。
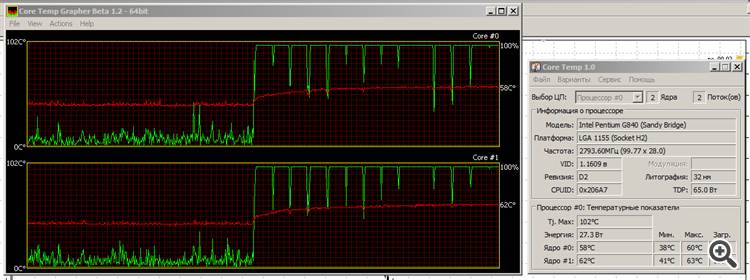
だからこそ、私はインテルのSandy Bridge仕様が大好きなのです。「グリーン」なのです。確かにグラフィックはイマイチですが、Ivy Bridgeがどうなるかは...。...
だから、私はインテルのSandy Bridgeモデルが大好きなのです。「グリーン」なのです。ああ、グラフィックはイマイチだけど、Ivy Bridgeが どうなるか......。ああ(苦笑)。これが本当のストレステストです。:)私のは今頃死んでいるかもしれませんね。
その後、なんとHaswell、そして少し遅れてRockwellが...。)))
OpenCLによるバーンズリー・シダの実装例。
計算はカオスゲームアルゴリズム(例)に基づき、スレッドIDに依存する生成基数を持つ乱数生成器を用い、get_global_id(0) を返すことでユニークな軌跡を生成している。
スケールを大きくすると、画質を維持するために必要な点数は2次関数的に増加するため、この実装では、各カーネルインスタンスが可視領域内に収まる固定数の点を描画することを想定しています。
推定スレッド数は191行目で指定されています。
は、233 行目にある点数です。
アップデイト
IFS-fern.mq5 - CPUアナログ
scale=1000の場合。
16x7x3層のニューロンを作りました。 実は一昨日作って今日デバッグしました。 その前にCPUでチェックすると結果が合わなかったのですが、その理由は少なくとも今は眠いので書きません 。:)
時間的特性:
明日は、このグリッドのオプティマイザーを作り、実データをロードして、MT5-testerで検証可能なリアルな計算でテスターを仕上げ、グリッドのMLP+cl-codeを生成して、最適化に取り組む予定です。
欲張りなのでソースコードは掲載しませんが、手持ちのハードウェアでテストしたい方のためにex5を同梱しています。
プーチン政権下と同じように安定しています。
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
ちなみに、CPUランタイムでは、あなたのシステムと私のシステム(Pentium G840ベース)の差はそれほど大きくありません。
あなたのRAMは速いですか?私は1333MHzです。
もうひとつ、計算時にCPUの両コアに 負荷がかかるのは面白いですね。最後に負荷が急激に下がるのは、計算が終わった後です。それはどういうことでしょうか?
プーチン政権下並みの安定感です。
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
1.ところで、あなたのシステムと私のシステム(Pentium G840ベース)のCPU実行 時間の違いに注目してください。
2.RAMは高速ですか?私は1333MHzです。
1.暇つぶしにオーバークロックの復旧をしているのですが、以前、本当にひどいクラッシュ(後でドライブの電源コードが抜けていたことが判明)があり、奇跡を求めてマザーボードの「メモリーOK」ボタンを押しました。その後、やはり動作せず、CMOSの設定だけがデフォルトにリセットされました。 今は、プロセッサを再び3840MHzにオーバークロックしたので、よりスマートに動作するようになりました。
2.まだ、解明できない。:)特に、レナトがリンクを示したベンチマークでは、1600MHzと表示されている。メモリ自体は2GHzなのに、Windowsは1033MHzとまで表示される :)))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))1866まで引っ張る母
もうひとつ、CPUで計算するときに両方のコアに 負荷がかかっているのが面白いですね。最後に負荷が急激に下がるのは、計算が終わった後です。それはどういうことでしょうか。
ということは、GPUには全く関係ないのでは? ドライバはアップしていますが。私の唯一の説明は、計算がCPU-OpenCLで行われ、もちろん利用可能なすべてのコアで、ベクトルSSE命令を使用しているだけだということです。:)
2つ目のバリエーションは、CPUと同時にカウントするというものです。 この(CPU-LPU)対応がドライバでどのように実装されているかは分かりませんが、原理的にはopentCL処理の起動もこのようなバリエーションを排除するものではありません。
これはどちらかというと、私の憶測です。あるいは、今流行の「IMHO」と書いてもいいかもしれません。;)
そうでしょうか。特に私は2コアしか持っていないので。では、25倍の利益はどこから来るのでしょうか?
Intel MathKernel LibraryやIntel Performance Primitives(ダウンロードしてません)があれば可能ですが......。場合によってはでも、何百メガの重さがあるので、ありえないですよね。
Googleがどう言い出すか見ものですね。
数学: また、面白いことに、私のCPUの計算では、両方のコアが ロードされています。
いや、OpenCLを使わない純粋なCPUの計算という意味です。各コアが同程度の負荷値を持つ100%弱の負荷である。しかし、OpenCLのコードを実行すると100%になり、これはGPUの動作で簡単に説明できます。